Chapter 15. Core Practice: Small, Simple Pieces
A successful system tends to grow over time. More people use it, more people work on it, more things are added to it. As the system grows, changes become riskier and more complex. This often leads to more complicated and time-consuming processes for managing changes. Overhead for making changes makes it harder to fix and improve the system, allowing technical debt to grow, eroding the quality of the system.
This is the negative version of the cycle of speed of change driving better quality, and better quality enabling faster speed of change described in Chapter 1.
Applying the three core practices of Infrastructure as Code—defining everything as code, continuously testing and delivering, and building small pieces (“Three Core Practices for Infrastructure as Code”)—enables the positive version of the cycle.
This chapter focuses on the third practice, composing your system from smaller pieces so that you can maintain a faster rate of change while improving quality even as your system grows. Most infrastructure coding tools and languages have features that support modules, libraries, and other types of components. But infrastructure design thinking and practice hasn’t yet reached the level of maturity of software design.
So this chapter draws on design principles for modularity learned from decades of software design, considering them from the point of view of code-driven infrastructure. It then looks at different types of components in an infrastructure system, with an eye to how we can leverage them for better modularity. Building on this, we can look at different considerations for drawing boundaries between infrastructure components.
Designing for Modularity
The goal of modularity is to make it easier and safer to make changes to a system. There are several ways modularity supports this goal. One is to remove duplication of implementations, to reduce the number of code changes you need to make to deliver a particular change. Another is to simplify implementation by providing components that can be assembled in different ways for different uses.
A third way to make changes easier and safer is to design the system so that you can make changes to a smaller component without needing to change other parts of the system. Smaller pieces are easier, safer, and faster to change than larger pieces.
Most design rules for modularity have a tension. Followed carelessly, they can actually make a system more brittle and harder to change. The four key metrics from “The Four Key Metrics” are a useful lens for considering the effectiveness of modularizing your system.
Characteristics of Well-Designed Components
Designing components is the art of deciding which elements of your system to group together, and which to separate. Doing this well involves understanding the relationships and dependencies between the elements. Two important design characteristics of a component are coupling and cohesion. The goal of a good design is to create low coupling and high cohesion.
Coupling describes how often a change to one component requires a change to another component. Zero coupling isn’t a realistic goal for two parts of a system. Zero coupling probably means they aren’t a part of the same system at all. Instead, we aim for low, or loose coupling.
A stack and a server image are coupled, because you may need to increase the memory allocated to the server instance in the stack when you upgrade software on the server. But you shouldn’t need to change code in the stack every time you update the server image. Low coupling makes it easier to change a component with little risk of breaking other parts of the system.
Cohesion describes the relationship between the elements within a component. As with coupling, the concept of cohesion relates to patterns of change. Changes to a resource defined in a stack with low cohesion are often not relevant to other resources in the stack.
An infrastructure stack that defines separate networking structures for servers provisioned by two other stacks has low cohesion. Components with high cohesion are easier to change because they are smaller, simpler, and cleaner, with a lower blast radius (Blast Radius), than components that include a mash of loosely related things.
Four Rules of Simple Design
Kent Beck, the creator of XP and TDD, often cites four rules for making the design of a component simple. According to his rules, simple code should:
-
Pass its tests (do what it is supposed to do)
-
Reveal its intention (be clear and easy to understand)
-
Have no duplication
-
Include the fewest elements
Rules for Designing Components
Software architecture and design includes many principles and guidelines for designing components with low coupling and high cohesion.
Avoid duplication
The DRY (Don’t Repeat Yourself) principle says, “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.”1 Duplication forces people to make a change in multiple places.
For example, all of ShopSpinner’s stacks use a provisioner user account to apply configuration to server instances. Originally, the login details for the account are specified in every stack as well as the code that builds their base server image. When someone needs to change the login details for the user account, they need to find and change it in all of these locations in the codebase. So the team moves the login details in a central location, and each stack, plus the server image builder, refers to that
location.
Duplication Considered Useful
The DRY principle discourages duplicating the implementation of a concept, which is not the same as duplicating literal lines of code. Having multiple components depend on shared code can create tight coupling, making it hard to change.
I’ve seen teams insist on centralizing any code that looks similar; for example, having all virtual servers created using a single module. In practice, servers created for different purposes, such as application servers, web servers, and build servers, usually need to be defined differently. A module that needs to create all of these different types of servers can become overly complicated.
When considering whether code is duplicated and should be centralized, consider whether the code truly represents the same concept. Does changing one instance of the code always mean the other instance should change as well?
Also consider whether it’s a good idea to lock the two instances of code together into the same change cycle. Forcing every application server in the organization to upgrade at the same time may be unrealistic.
Reuse increases coupling. So a good rule of thumb for reuse is to be DRY within a component, and wet across components.
Rule of composition
To make a composable system, make independent pieces. It should be easy to replace one side of a dependency relationship without disturbing the other.2
The ShopSpinner team starts with a single Linux application server image that they provision from different stacks. Later they add a Windows application server image. They design the code that provisions server images from any given stack so that they can easily switch between these two server images as needed for a given application.
Single responsibility principle
The single responsibility principle (SRP) says that any given component should have responsibility for one thing. The idea is to keep each component focused, so that its contents are cohesive.3
An infrastructure component, whether it’s a server, configuration library, stack component, or a stack, should be organized with a single purpose in mind. That purpose may be layered. Providing the infrastructure for an application is a single purpose that can be fulfilled by an infrastructure stack. You could break that purpose down into secure traffic routing for an application, implemented in a stack library; an application server, implemented by a server image; and a database instance, implemented by a stack module. Each component, at each level, has a single, easily understood purpose.
Design components around domain concepts, not technical ones
People are often tempted to build components around technical concepts. For example, it might seem like a good idea to create a component for defining a server, and reuse that in any stack that needs a server. In practice, any shared component couples all of the code it uses.
A better approach is to build components around a domain concept. An application server is a domain concept that you may want to reuse for multiple applications. A build server is another domain concept, which you may want to reuse to give different teams their own instance. So these make better components than servers, which are probably used in different ways.
Law of Demeter
Also called the principle of least knowledge, the Law of Demeter says that a component should not have knowledge of how other components are implemented. This rules pushes for clear, simple interfaces between components.
The ShopSpinner team initially violates this rule by having a stack that defines an application server cluster, and a shared networking stack that defines a load balancer and firewall rules for that cluster. The shared networking stack has too much detailed knowledge of the application server stack.
Providers and Consumers
In a dependency relationship between components a provider component creates or defines a resource that a consumer component uses.
A shared networking stack may be a provider, creating networking address blocks such as subnets. An application infrastructure stack may be a consumer of the shared networking stack, provisioning servers and load balancers within the subnets managed by the provider.
A key topic of this chapter is defining and implementing interfaces between infrastructure components.
No circular dependencies
As you trace relationships from a component that provides resources to consumers, you should never find a loop (or cycle). In other words, a provider component should never consume resources from one of its own direct or indirect consumers.
The ShopSpinner example of a shared network stack has a circular dependency. The application server stack assigns the servers in its cluster to network structures in the shared networking stack. The shared networking stack creates load balancer and firewall rules for the specific server clusters in the application server stack.
The ShopSpinner team can fix the circular dependencies, and reduce the knowledge the networking stack has of other components, by moving the networking elements that are specific to the application server stack into that stack. This also improves cohesion and coupling, since the networking stack no longer contains elements that are most closely related to the elements of another stack.
Use Testing to Drive Design Decisions
Chapters 8 and 9 describe practices for continuously testing infrastructure code as people work on changes. This heavy focus on testing makes testability an essential design consideration for infrastructure components.
Your change delivery system needs to be able to create and test infrastructure code at every level, from a server configuration module that installs a monitoring agent, to stack code that builds a container cluster. Pipeline stages must be able to quickly create an instance of each component in isolation. This level of testing is impossible with a spaghetti codebase with tangled dependencies, or with large components that take half an hour to provision.
These challenges derail many initiatives to introduce effective automated testing regimes for infrastructure code. It’s hard to write and run automated tests for a poorly designed system.
And this is the secret benefit of automated testing: it drives better design. The only way to continuously test and deliver code is to implement and maintain clean system designs with loose coupling and high cohesion.
It’s easier to implement automated testing for server configuration modules that are loosely coupled. It’s easier to build and use mocks for a module with cleaner, simpler interfaces (see “Using Test Fixtures to Handle Dependencies”). You can provision and test a small, well-defined stack in a pipeline more quickly.
Modularizing Infrastructure
An infrastructure system involves different types of components, as described in Chapter 3, each of which can be composed of different parts. A server instance may be built from an image, using a server configuration role that references a set of server configuration modules, which in turn may import code libraries. An infrastructure stack may be composed of server instances, and may use stack code modules or libraries. And multiple stacks may combine to comprise a larger environment or estate.
Stack Components Versus Stacks as Components
The infrastructure stack, as defined in Chapter 5, is the core deployable unit of infrastructure. The stack is an example of an Architectural Quantum, which Ford, Parsons, and Kua define as, “an independently deployable component with high functional cohesion, which includes all the structural elements required for the system to function correctly.”4 In other words, a stack is a component that you can push into production on its own.
As mentioned previously, a stack can be composed of components, and a stack may itself be a component. Servers are one potential component of a stack, which are involved enough to drill into later in this chapter. Most stack management tools also support putting stack code into modules, or using libraries to generate elements of the stack.
Figure 15-1 shows two stacks, the imaginatively named StackA and StackB, which use a shared code module that defines a networking structure.
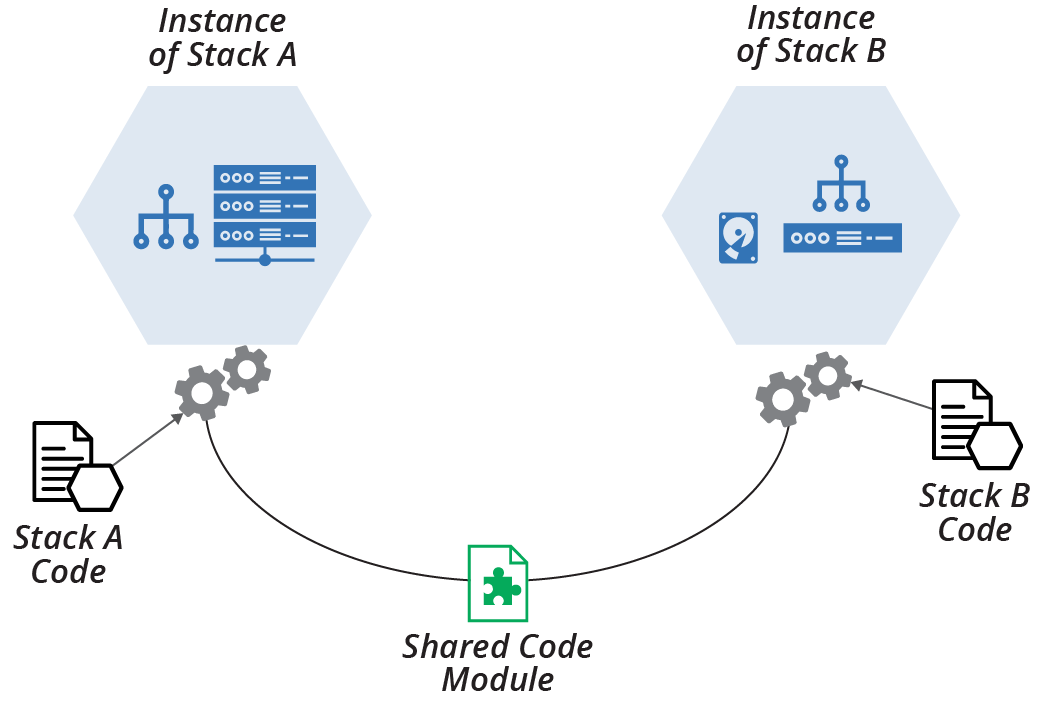
Figure 15-1. Shared code module used by two stacks
Chapter 16 describes some patterns and antipatterns for using stack code modules and libraries.
Stack modules and libraries are useful for reusing code. However, they are less helpful for making stacks easy to change. I’ve seen teams try to improve a monolithic stack (see “Antipattern: Monolithic Stack”) by breaking the code into modules. While modules made the code easier to follow, each stack instance was just as large and complex as before.
Figure 15-2 shows that code separated into separate modules are combined into the stack instance.
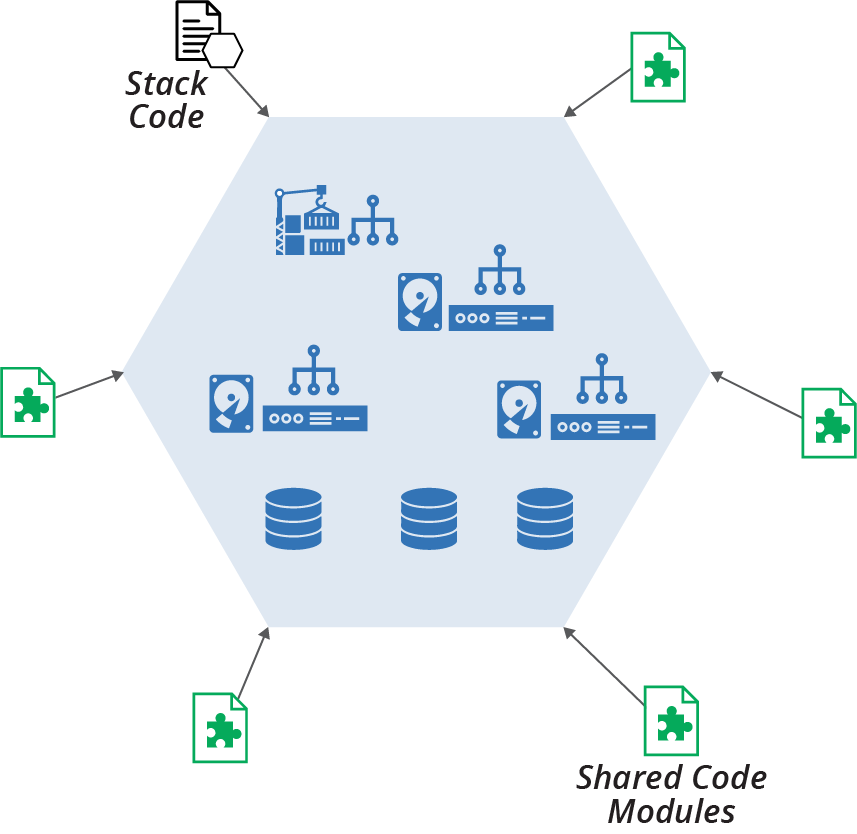
Figure 15-2. Stack modules add complexity to the stack instance
In addition to adding to the elements with each stack instance, a module that is also used by other stacks creates coupling between those stacks. Changing the module to accommodate a requirement in one stack may affect other stacks that use the module. This coupling may add friction for making changes.
A more fruitful approach to making a large stack more manageable is to break it into multiple stacks, each of which can be provisioned, managed, and changed independently of others. “Patterns and Antipatterns for Structuring Stacks” lists a few patterns for considering the size and contents of a stack. Chapter 17 goes into more detail of managing the dependencies between stacks.
Using a Server in a Stack
Servers are a common type of stack component. Chapter 11 explained the various components of a server and its life cycle. Stack code normally incorporates servers through some combination of server images (see Chapter 13) and server configuration modules (see “Server Configuration Code”), often by specifying a role (see “Server Roles”).
The ShopSpinner team’s codebase includes an example of using a server image as a component of a stack. It has a stack called cluster_of_host_nodes, which builds a cluster of servers to act as container host nodes, as shown in Figure 15-3.
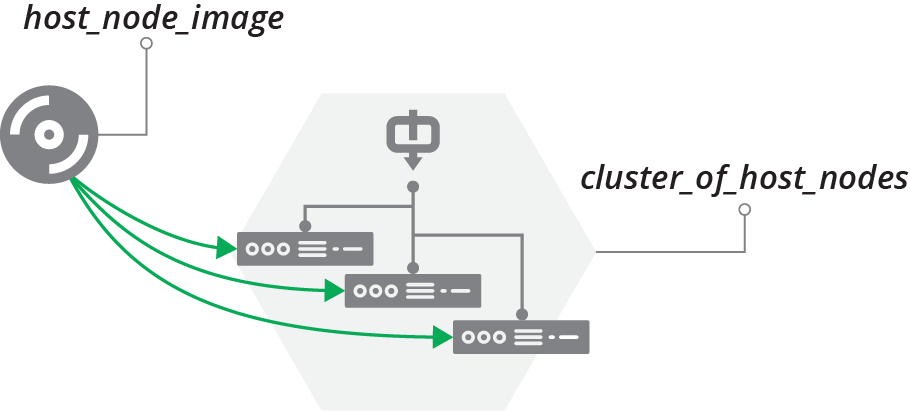
Figure 15-3. Server image as a provider to a stack
The code that defines the server cluster specifies the name of the server image, host_node_image:
server_cluster:name:"cluster_of_host_nodes"min_size:1max_size:3each_server_node:source_image:host_node_imagememory:8GB
The team uses a pipeline to build and test changes to the server image. Another pipeline tests changes to cluster_of_host_nodes, integrating it with the latest version of host_node_image that has passed its tests (see Figure 15-4).
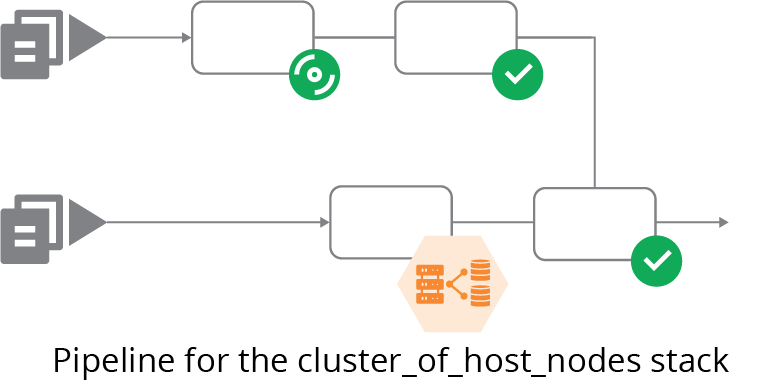
Figure 15-4. Pipeline to integrate the server image and its consumer stack
“Infrastructure Delivery Pipelines” explained how pipelines can work for infrastructure.
This example has a slight issue, however. The first pipeline stage for the
cluster_of_host_nodes stack doesn’t use the host_node_image. But the stack code example includes the name of the server image, so it can’t be run as an online test stage (“Online Testing Stages for Stacks”). Testing the stack code without the image might be useful, so the team can find problems with the stack code without having to also provision the full host node servers, which are heavy.
The ShopSpinner team addresses the problem by extracting the hardcoded host_node_image out of the stack code, using a stack parameter instead (Chapter 7). This code is more testable:
server_cluster:name:"cluster_of_host_nodes"min_size:1max_size:3each_server_node:source_image:${HOST_NODE_SERVER_IMAGE}memory:8GB
The online test stage for the cluster_of_host_nodes stack can set the HOST_NODE_SERVER_IMAGE parameter with the ID for a stripped-down server image. The team can run tests in this stage to validate that the server cluster works correctly, scaling up and down and recovering failed instances. The stripped-down server image is an example of a test double (see “Using Test Fixtures to Handle Dependencies”).
The simple change of replacing the hardcoded reference to the server image with a parameter reduces coupling. It also follows the rule of composition (see “Rule of composition”). The team can easily create instances of
cluster_of_host_nodes using a different server image, which would come in handy if people on the team want to test and incrementally roll out a different operating system for their clusters.
Drawing Boundaries Between Components
To divide infrastructure, as with any system, you should look for seams. A seam is a place where you can alter behavior in your system without editing in that place.5 The idea is to find natural places to draw boundaries between parts of your systems, where you can create simple, clean integration points.
Each of the following strategies groups infrastructure elements based on a specific concern: patterns of change, organizational structures, security and governance, and resilience and scaling. These strategies, as with most architectural principles and practices, come down to optimizing for change. It’s a quest to design components so that you can make changes to your system more easily, safely, and quickly.
Align Boundaries with Natural Change Patterns
The most basic approach to optimizing component boundaries for change is to understand their natural patterns of change. This is the idea behind finding seams—a seam is a natural boundary.
With an existing system, you may learn about which things typically change together by examining historical changes. Finer-grained changes, like code commits, give the most useful insight. The most effective teams optimize for frequent commits, fully integrating and testing each one. By understanding what components tend to change together as part of a single commit, or closely related commits across components, you can find patterns that suggest how to refactor your code for more cohesion and less coupling.
Examining higher levels of work, such as tickets, stories, or projects, can help you to understand what parts of the system are often involved in a set of changes. But you should optimize for small, frequent changes. So be sure to drill down to understand what changes can be made independently of one another, to enable incremental changes within the context of larger change initiatives.
Align Boundaries with Component Life Cycles
Different parts of an infrastructure may have different life cycles. For example, servers in a cluster (see “Compute Resources”) are created and destroyed dynamically, perhaps many times a day. A database storage volume changes less frequently.
Organizing infrastructure resources into deployable components, particularly infrastructure stacks, according to their life cycle can simplify management. Consider a ShopSpinner application server infrastructure stack composed of networking routes, a server cluster, and a database instance.
The servers in this stack are updated at least every week, rebuilt using new server images with the latest operating system patches (as discussed in Chapter 13). The database storage device is rarely changed, although new instances may be built to recover or replicate instances of the application. The team occasionally changes networking in other stacks, which requires updating the application-specific routing in this stack.
Defining these elements in a single stack can create some risk. An update to the application server image may fail. Fixing the issue might require rebuilding the entire stack, including the database storage device, which in turn requires backing up the data to restore to the new instance (see “Data Continuity in a Changing System”). Although it’s possible to manage this within a single stack, it would be simpler if the database storage was defined in a separate stack, as shown in Figure 15-6.
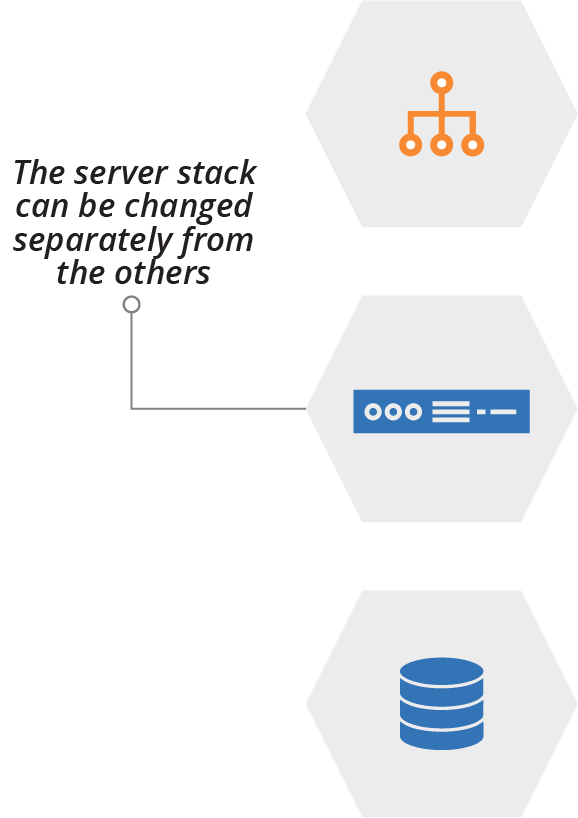
Figure 15-6. Different stacks have different life cycles
Changes are made to any of these micro stacks (see “Pattern: Micro Stack”) without directly affecting the others. This approach can enable stack-specific management events. For instance, any change to the database storage stack might trigger a data backup, which would probably be too expensive to trigger with every change to the other elements of the first, combined stack.
Optimizing stack boundaries for life cycles is particularly useful for automated testing in pipelines. Pipeline stages often run multiple times every day while people are working on infrastructure changes, so they need to be optimized to give fast feedback and keep a good working rhythm. Organizing infrastructure elements into separate stacks based on their life cycle can reduce the time taken to apply changes for testing.
For example, when working on the infrastructure code for the application servers, some pipeline stages might rebuild the stack each time (see “Pattern: Ephemeral Test Stack”). Rebuilding networking structures or large data storage devices can be slow, and may not be needed for many of the changes involved in the work. In this case, the micro-stack design shown earlier (Figure 15-6) can streamline the testing and delivery process.
A third use case for separating stacks by life cycle is cost management. Shutting down or destroying and rebuilding infrastructure that isn’t needed in quiet periods is a common way to manage public cloud costs. But some elements, such as data storage, may be more challenging to rebuild. You can split these into their own stacks and leave them running while other stacks are destroyed to reduce costs.
Align Boundaries with Organizational Structures
Conway’s Law says that systems tend to reflect the structure of the organization that creates it.6 One team usually finds it easier to integrate software and infrastructure that it owns wholly, and the team will naturally create harder boundaries with parts of the system owned by other teams.
Conway’s Law has two general implications for designing systems that include infrastructure. One is to avoid designing components that multiple teams need to make changes to. The other is to consider structuring teams to reflect the architectural boundaries you want, according to the “Inverse Conway Maneuver”.
Legacy Silos Create Disjointed Infrastructure
Legacy organizational structures that put build and run into separate teams often create inconsistent infrastructure across the path to production, increasing the time, cost, and risk of delivering changes. At one organization I worked with, the application development team and operations team used different configuration tools to build servers. They wasted several weeks for every software release getting the applications to deploy and run correctly in the production environments.
For infrastructure, in particular, it’s worth considering how to align design with the structure of the teams that use the infrastructure. In most organizations these are product or service lines and applications. Even with infrastructure used by multiple teams, such as a DBaaS service (see “Storage Resources”), you may design your infrastructure so you can manage separate instances for each team.
Aligning infrastructure instances with the teams that use them makes changes less disruptive. Rather than needing to negotiate a single change window with all of the teams using a shared instance, you can negotiate separate windows for each team.
Create Boundaries That Support Resilience
When something fails in your system, you can rebuild an independently deployable component like an infrastructure stack. You can repair or rebuild elements within a stack manually, conducting infrastructure surgery. Infrastructure surgery requires someone with a deep understanding of the infrastructure to carefully intervene. A simple mistake can make the situation far worse.
Some people take pride in infrastructure surgery, but it’s a fallback to compensate for gaps in your infrastructure management systems.
An alternative to infrastructure surgery is rebuilding components using well-defined processes and tooling. You should be able to rebuild any stack instance by triggering the same automated process you use to apply changes and updates. If you can do this, you don’t need to wake your most brilliant infrastructure surgeon when something fails in the middle of the night. In many cases, you can automatically trigger a recovery.
Infrastructure components need to be designed to make it possible to quickly rebuild and recover them. If you organize resources into components based on their life cycle (“Align Boundaries with Component Life Cycles”), then you can also take rebuild and recovery use cases into account.
The earlier example of splitting infrastructure that includes persistent data (Figure 15-6) does this. The process to rebuild the data storage should include steps that automatically save and load data, which will come in handy in a disaster recovery scenario. See “Data Continuity in a Changing System” for more on this.
Dividing infrastructure into components based on their rebuild process helps to simplify and optimize recovery. Another approach to resilience is running multiple instances of parts of your infrastructure. Strategies for redundancy can also help with scaling.
Create Boundaries That Support Scaling
A common strategy for scaling systems is to create additional instances of some of its components. You may add instances in periods of higher demand, and you might also consider deploying instances in different geographical regions.
Most people are aware that most cloud platforms can automatically scale server clusters (see “Compute Resources”) up and down as load changes. A key benefit of FaaS serverless (see “Infrastructure for FaaS Serverless”) is that it only executes instances of code when needed.
However, other elements of your infrastructure, such as databases, message queues, and storage devices, can become bottlenecks when compute scales up. And different parts of your software system may become bottlenecks, even aside from the infrastructure.
For example, the ShopSpinner team can deploy multiple instances of the product browsing service stack to cope with higher load, because most user traffic hits that part of the system at peak times. The team keeps a single instance of its frontend traffic routing stack, and a single instance of the database stack that the application server instances connect to (see Figure 15-7).
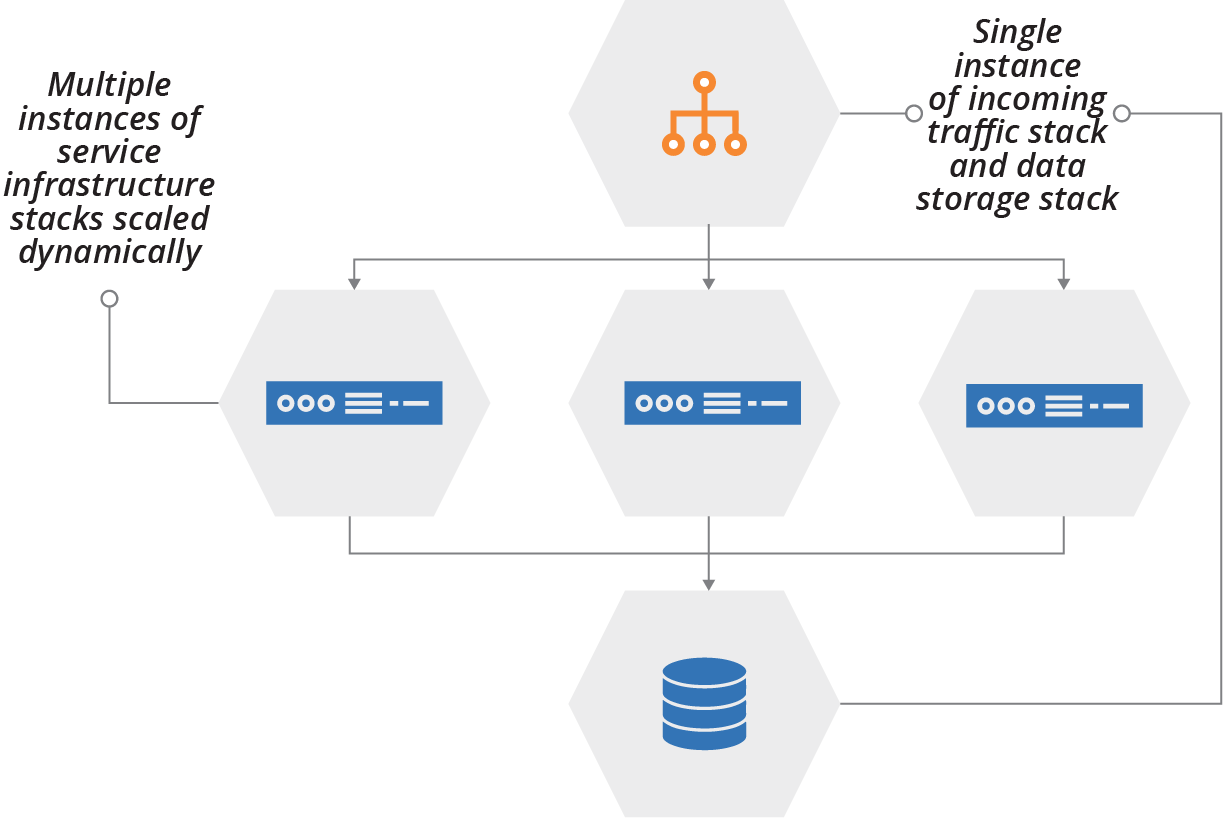
Figure 15-7. Scaling the number of instances of different stacks
Other parts of the system, such as order checkout and customer profile management services, probably don’t need to scale together with the product browsing service. Splitting those services into different stacks helps the team to scale them more quickly. It reduces the waste that replicating everything would create.
Align Boundaries to Security and Governance Concerns
Security, compliance, and governance protect data, transactions, and service availability. Different parts of a system will have different rules. For example, the PCI security standard imposes requirements on parts of a system that handle credit card numbers or payment processing. Personal data of customers and employees often needs to be handled with stricter controls.
Many organizations divide their infrastructure according to the regulations and policies that apply to the services and data it hosts. Doing this creates clarity for assessing what measures need to be taken with a given infrastructure component. The process for delivering changes can be tailored to the governance requirements. For example, the process can enforce and record reviews and approvals and generate change reports that simplify auditing.
Network Boundaries Are Not Infrastructure Stack Boundaries
People often divide infrastructure into networking security zones. Systems running in a frontend zone are directly accessible from the public internet, protected by firewalls and other mechanisms. Other zones, for application hosting and databases, for example, are only accessible from certain other zones, with additional layers of security.
While these boundaries are important for protecting against network-based attacks, they are usually not appropriate for organizing infrastructure code into deployable units. Putting the code for web servers and load balancers into a “frontend” stack doesn’t create a layer of defense against malicious changes to code for application servers or databases. The threat model for exploiting infrastructure code and tools is different from the threat model for network attacks.
By all means, do use your infrastructure code to create layered network boundaries.7 But don’t assume that it’s a good idea to apply the networking security model to structuring infrastructure code.
Conclusion
This chapter started the conversation of how to manage larger, more complex infrastructure defined as code by breaking it into smaller pieces. It built on the previous content of the book, including the organizational units of infrastructure (stacks and servers), and the other core practices of defining things as code and continuously testing.
1 The DRY principle, and others, can be found in The Pragmatic Programmer: From Journeyman to Master by Andrew Hunt and David Thomas (Addison-Wesley).
2 The rule of composition is one of the basic rules of the Unix philosophy.
3 My colleague James Lewis applies the SRP to the question of how big a microservice should be. His advice is that a component should fit in your head, conceptually, which applies to infrastructure as well as software components.
4 See chapter 4 of Building Evolutionary Architectures by Neal Ford, Rebecca Parsons, and Patrick Kua (O’Reilly).
5 Michael Feathers introduced the term seam in his book Working Effectively with Legacy Code (Addison-Wesley). More information is also available online.
6 The complete definition is, “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
7 Although you should consider a zero-trust model over pure perimeter-based security models, as mentioned in “Zero-Trust Security Model with SDN”.