Chapter 8. Core Practice: Continuously Test and Deliver
Continuous testing and delivery is the second of the three core practices of Infrastructure as Code, which also include defining everything as code and building small pieces. Testing is a cornerstone of Agile software engineering. Extreme Programming (XP) emphasizes writing tests first with TDD, and frequently integrating code with CI.1 CD extends this to testing the full production readiness of code as developers work on it, rather than waiting until they finish working on a release.2
If a strong focus on testing creates good results when writing application code, it’s reasonable to expect it to be useful for infrastructure code as well. This chapter explores strategies for testing and delivering infrastructure. It draws heavily on Agile engineering approaches to quality, including TDD, CI, and CD. These practices all build quality into a system by embedding testing into the code-writing process, rather than leaving it to be done later.
This chapter focuses on fundamental challenges and approaches for testing infrastructure. The next chapter (Chapter 9) builds on this one with specific guidance on testing infrastructure stack code, while Chapter 11 discusses testing server configuration code (see “Testing Server Code”).
Why Continuously Test Infrastructure Code?
Testing changes to your infrastructure is clearly a good idea. But the need to build and maintain a suite of test automation code may not be as clear. We often think of building infrastructure as a one-off activity: build it, test it, then use it. Why spend the effort to create an automated test suite for something you build once?
Creating an automated test suite is hard work, especially when you consider the work needed to implement the delivery and testing tools and services—CI servers, pipelines, test runners, test scaffolding, and various types of scanning and validation tools. When getting started with Infrastructure as Code, building all of these things may seem like more work than building the systems you’ll run on them.
In “Use Infrastructure as Code to Optimize for Change”, I explained the rationale for implementing systems for delivering changes to infrastructure. To recap, you’ll make far more changes to your infrastructure after you build it than you might expect. Once any nontrivial system is live, you need to patch, upgrade, fix, and improve it.
A key benefit of CD is removing the classic, Iron Age distinction between the “build” and “run” phases of a system’s life cycle.3 Design and implement the delivery systems, including automated testing and code promotion, together with the system itself. Use this system to incrementally build your infrastructure, and to incrementally improve it throughout its operational lifetime. Going “live” is almost an arbitrary event, a change of who is using the system, but not how the system is managed.
What Continuous Testing Means
One of the cornerstones of Agile engineering is testing as you work—build quality in. The earlier you can find out whether each line of code you write is ready for production, the faster you can work, and the sooner you can deliver value. Finding problems more quickly also means spending less time going back to investigate problems and less time fixing and rewriting code. Fixing problems continuously avoids accumulating technical debt.
Most people get the importance of fast feedback. But what differentiates genuinely high-performing teams is how aggressively they pursue truly continuous feedback.
Traditional approaches involve testing after the team has implemented the system’s complete functionality. Timeboxed methodologies take this further. The team tests periodically during development, such as at the end of a sprint. Teams following Lean or Kanban test each story as they complete it.4
Truly continuous testing involves testing even more frequently than this. People write and run tests as they code, even before finishing a story. They frequently push their code into a centralized, automated build system—ideally at least once a day.5
People need to get feedback as soon as possible when they push their code so that they can respond to it with as little interruption to their flow of work as possible. Tight feedback loops are the essence of continuous testing.
What Should We Test with Infrastructure?
The essence of CI is to test every change someone makes as soon as possible. The essence of CD is to maximize the scope of that testing. As Jez Humble says, “We achieve all this by ensuring our code is always in a deployable state.”6
Quality assurance is about managing the risks of applying code to your system. Will the code break when applied? Does it create the right infrastructure? Does the infrastructure work the way it should? Does it meet operational criteria for performance, reliability, and security? Does it comply with regulatory and governance rules?
CD is about broadening the scope of risks that are immediately tested when pushing a change to the codebase, rather than waiting for eventual testing days, weeks, or even months afterwards. So on every push, a pipeline applies the code to realistic test environments and runs comprehensive tests. Ideally, once the code has run through the automated stages of the pipeline, it’s fully proven as production-ready.
Teams should identify the risks that come from making changes to their infrastructure code, and create a repeatable process for testing any given change against those risks. This process takes the form of automated test suites and manual tests. A test suite is a collection of automated tests that are run as a group.
When people think about automated testing, they generally think about functional tests like unit tests and UI-driven journey tests. But the scope of risks is broader than functional defects, so the scope of validation is broader as well. Constraints and requirements beyond the purely functional are often called Non-Functional Requirements (NFRs) or Cross-Functional Requirements (CFRs).7 Examples of things that you may want to validate, whether automatically or manually, include:
- Code quality
-
Is the code readable and maintainable? Does it follow the team’s standards for how to format and structure code? Depending on the tools and languages you’re using, some tools can scan code for syntax errors and compliance with formatting rules, and run a complexity analysis. Depending on how long they’ve been around, and how popular they are, infrastructure languages may not have many (or any!) of these tools. Manual review methods include gated code review processes, code showcase sessions, and pair programming.
- Functionality
-
Does it do what it should? Ultimately, functionality is tested by deploying the applications onto the infrastructure and checking that they run correctly. Doing this indirectly tests that the infrastructure is correct, but you can often catch issues before deploying applications. An example of this for infrastructure is network routing. Can an HTTPS connection be made from the public internet to the web servers? You may be able to test this kind of thing using a subset of the entire infrastructure.
- Security
-
You can test security at a variety of levels, from code scanning to unit testing to integration testing and production monitoring. There are some tools specific to security testing, such as vulnerability scanners. It may also be useful to write security tests into standard test suites. For example, unit tests can make assertions about open ports, user account handling, or access permissions.
- Compliance
-
Systems may need to comply with laws, regulations, industry standards, contractual obligations, or organizational policies. Ensuring and proving compliance can be time-consuming for infrastructure and operations teams. Automated testing can be enormously useful with this, both to catch violations quickly and to provide evidence for auditors. As with security, you can do this at multiple levels of validation, from code-level to production testing. See “Governance in a Pipeline-based Workflow” for a broader look at doing this.
- Performance
-
Automated tools can test how quickly specific actions complete. Testing the speed of a network connection from point A to point B can surface issues with the network configuration or the cloud platform if run before you even deploy an application. Finding performance issues on a subset of your system is another example of how you can get faster feedback.
- Scalability
-
Automated tests can prove that scaling works correctly; for example, checking that an auto-scaled cluster adds nodes when it should. Tests can also check whether scaling gives you the outcomes that you expect. For example, perhaps adding nodes to the cluster doesn’t improve capacity, due to a bottleneck somewhere else in the system. Having these tests run frequently means you’ll discover quickly if a change to your infrastructure breaks your scaling.
- Availability
-
Similarly, automated testing can prove that your system would be available in the face of potential outages. Your tests can destroy resources, such as nodes of a cluster, and verify that the cluster automatically replaces them. You can also test that scenarios that aren’t automatically resolved are handled gracefully; for example, showing an error page and avoiding data corruption.
- Operability
-
You can automatically test any other system requirements needed for operations. Teams can test monitoring (inject errors and prove that monitoring detects and reports them), logging, and automated maintenance activities.
Each of these types of validations can be applied at more than one level of scope, from server configuration to stack code to the fully integrated system. I’ll discuss this in “Progressive Testing”. But first I’d like to address the things that make infrastructure especially difficult to test.
Challenges with Testing Infrastructure Code
Most of the teams I encounter that work with Infrastructure as Code struggle to implement the same level of automated testing and delivery for their infrastructure code as they have for their application code. And many teams without a background in Agile software engineering find it even more difficult.
The premise of Infrastructure as Code is that we can apply software engineering practices such as Agile testing to infrastructure. But there are significant differences between infrastructure code and application code. So we need to adapt some of the techniques and mindsets from application testing to make them practical for infrastructure.
The following are a few challenges that arise from the differences between infrastructure code and application code.
Challenge: Tests for Declarative Code Often Have Low Value
As mentioned in Chapter 4 (“Declarative Infrastructure Languages”), many infrastructure tools use declarative languages rather than imperative languages. Declarative code typically declares the desired state for some infrastructure, such as this code that defines a networking subnet:
Example 8-1.
subnet:name:private_Aaddress_range:192.168.0.0/16
A test for this would simply restate the code:
assert:subnet("private_A").existsassert:subnet("private_A").address_range is("192.168.0.0/16")
A suite of low-level tests of declarative code can become a bookkeeping exercise. Every time you change the infrastructure code, you change the test to match. What value do these tests provide? Well, testing is about managing risks, so let’s consider what risks the preceding test can uncover:
-
The infrastructure code was never applied.
-
The infrastructure code was applied, but the tool failed to apply it correctly, without returning an error.
-
Someone changed the infrastructure code but forgot to change the test to match.
The first risk may be a real one, but it doesn’t require a test for every single declaration. Assuming you have code that does multiple things on a server, a single test would be enough to reveal that, for whatever reason, the code wasn’t applied.
The second risk boils down to protecting yourself against a bug in the tool you’re using. The tool developers should fix that bug or your team should switch to a more reliable tool. I’ve seen teams use tests like this in cases where they found a specific bug, and wanted to protect themselves against it. Testing for this is okay to cover a known issue, but it is wasteful to blanket your code with detailed tests just in case your tool has a bug.
The last risk is circular logic. Removing the test would remove the risk it addresses, and also remove work for the team.
Declarative Tests
The Given, When, Then format is useful for writing tests.8 A declarative test omits the “When” part, having a format more like “Given a thing, Then it has these characteristics.” Tests written like this suggest that the code you’re testing doesn’t create variable outcomes. Declarative tests, like declarative code, have a place in many infrastructure codebases, but be aware that many tools and practices for testing dynamic code may not be appropriate.
There are some situations when it’s useful to test declarative code. Two that come to mind are when the declarative code can create different results, and when you combine multiple declarations.
Testing variable declarative code
The previous example of declarative code is simple—the values are hardcoded, so the result of applying the code is clear. Variables introduce the possibility of creating different results, which may create risks that make testing more useful. Variables don’t always create variation that needs testing. What if we add some simple variables to the earlier example?
subnet:name:${MY_APP}-${MY_ENVIRONMENT}address_range:${SUBNET_IP_RANGE}
There isn’t much risk in this code that isn’t already managed by the tool that applies it. If someone sets the variables to invalid values, the tool should fail with an error.
The code becomes riskier when there are more possible outcomes. Let’s add some conditional code to the example:
subnet:name:${MY_APP}-${MY_ENVIRONMENT}address_range:get_networking_subrange(get_vpc(${MY_ENVIRONMENT}),data_centers.howmany,data_centers.howmany++)
This code has some logic that might be worth testing. It calls two functions, get_networking_subrange and get_vpc, either of which might fail or return a result that interacts in unexpected ways with the other function.
The outcome of applying this code varies based on inputs and context, which makes it worth writing tests.
Note
Imagine that instead of calling these functions, you wrote the code to select a subset of the address range as a part of this declaration for your subnet. This is an example of mixing declarative and imperative code (as discussed in “Separate Declarative and Imperative Code”). The tests for the subnet code would need to include various edge cases of the imperative code—for example, what happens if the parent range is smaller than the range needed?
If your declarative code is complex enough that it needs complex testing, it is a sign that you should pull some of the logic out of your declarations and into a library written in a procedural language. You can then write clearly separate tests for that function, and simplify the test for the subnet declaration.
Testing combinations of declarative code
Another situation where testing is more valuable is when you have multiple declarations for infrastructure that combine into more complicated structures. For example, you may have code that defines multiple networking structures—an address block, load balancer, routing rules, and gateway. Each piece of code would probably be simple enough that tests would be unnecessary. But the combination of these produces an outcome that is worth testing—that someone can make a network connection from point A to point B.
Testing that the tool created the things declared in code is usually less valuable than testing that they enable the outcomes you want.
Challenge: Testing Infrastructure Code Is Slow
To test infrastructure code, you need to apply it to relevant infrastructure. And provisioning an instance of infrastructure is often slow, especially when you need to create it on a cloud platform. Most teams that struggle to implement automated infrastructure testing find that the time to create test infrastructure is a barrier for fast feedback.
The solution is usually a combination of strategies:
- Divide infrastructure into more tractable pieces
-
It’s useful to include testability as a factor in designing a system’s structure, as it’s one of the key ways to make the system easy to maintain, extend, and evolve. Making pieces smaller is one tactic, as smaller pieces are usually faster to provision and test. It’s easier to write and maintain tests for smaller, more loosely coupled pieces since they are simpler and have less surface area of risk. Chapter 15 discusses this topic in more depth.
- Clarify, minimize, and isolate dependencies
-
Each element of your system may have dependencies on other parts of your system, on platform services, and on services and systems that are external to your team, department, or organization. These impact testing, especially if you need to rely on someone else to provide instances to support your test. They may be slow, expensive, unreliable, or have inconsistent test data, especially if other users share them. Test doubles are a useful way to isolate a component so that you can test it quickly. You may use test doubles as part of a progressive testing strategy—first testing your component with test doubles, and later testing it integrated with other components and services. See “Using Test Fixtures to Handle Dependencies” for more about test doubles.
- Progressive testing
-
You’ll usually have multiple test suites to test different aspects of the system. You can run faster tests first, to get quicker feedback if they fail, and only run slower, broader-scoped tests after those have passed. I’ll delve into this in “Progressive Testing”.
- Choice of ephemeral or persistent instances
-
You may create and destroy an instance of the infrastructure each time you test it (an ephemeral instance), or you may leave an instance running in between runs (persistent instances). Using ephemeral instances can make tests significantly slower, but are cleaner and give more consistent results. Keeping persistent instances cuts the time needed to run tests, but may leave changes and accumulate inconsistencies over time. Choose the appropriate strategy for a given set of tests, and revisit the decision based on how well it’s working. I provide more concrete examples of implementing ephemeral and persistent instances in “Pattern: Ephemeral Test Stack”.
- Online and offline tests
-
Some types of tests run online, requiring you to provision infrastructure on the “real” cloud platform. Others can run offline on your laptop or a build agent. Tests that you can run offline include code syntax checking and tests that run in a virtual machine or container instance. Consider the nature of your various tests, and be aware of which ones can run where. Offline testing is usually much faster, so you’ll tend to run them earlier. You can use test doubles to emulate your cloud API offline for some tests. See “Offline Testing Stages for Stacks” and “Online Testing Stages for Stacks” for more detail on offline and online testing for stacks.
With any of these strategies, you should regularly assess how well they are working. If tests are unreliable, either failing to run correctly or returning inconsistent results, then you should drill into the reasons for this and either fix them or replace them with something else. If tests rarely fail, or if the same tests almost always fail together, you may be able to strip them out to simplify your test suite. If you spend more time finding and fixing problems that originate in your tests rather than in the code you’re testing, look for ways to simplify and improve them.
Challenge: Dependencies Complicate Testing Infrastructure
The time needed to set up other infrastructure that your code depends on makes testing even slower. A useful technique for addressing this is to replace dependencies with test doubles.
Mocks, fakes, and stubs are all types of test doubles. A test double replaces a dependency needed by a component so you can test it in isolation. These terms tend to be used in different ways by different people, but I’ve found the definitions used by Gerard Meszaros in his book xUnit Test Patterns (Addison-Wesley) to be useful.9
In the context of infrastructure, there is a growing number of tools that allow you to mock the APIs of cloud vendors.10 You can apply your infrastructure code to a local mocked cloud to test some aspects of the code. These won’t tell you whether your networking structures work correctly, but they should tell you whether they’re roughly valid.
It’s often more useful to use test doubles for other infrastructure components than for the infrastructure platform itself. Chapter 9 gives examples of using test doubles and other test fixtures for testing infrastructure stacks (see “Using Test Fixtures to Handle Dependencies”). Later chapters in Part IV describe breaking infrastructure into smaller pieces and integrating them. Test fixtures are a key tool for keeping components loosely coupled.
Progressive Testing
Most nontrivial systems use multiple suites of tests to validate changes. Different suites may test different things (as listed in “What Should We Test with Infrastructure?”). One suite may test one concern offline, such as checking for security vulnerabilities by scanning code syntax. Another suite may run online checks for the same concern, for example by probing a running instance of an infrastructure stack for security vulnerabilities.
Progressive testing involves running test suites in a sequence. The sequence builds up, starting with simpler tests that run more quickly over a smaller scope of code, then building up to more comprehensive tests over a broader set of integrated components and services. Models like the test pyramid and Swiss cheese testing help you think about how to structure validation activities across your test suites.
The guiding principle for a progressive feedback strategy is to get fast, accurate feedback. As a rule, this means running faster tests with a narrower scope and fewer dependencies first and then running tests that progressively add more components and integration points (Figure 8-1). This way, small errors are quickly made visible so they can be quickly fixed and retested.
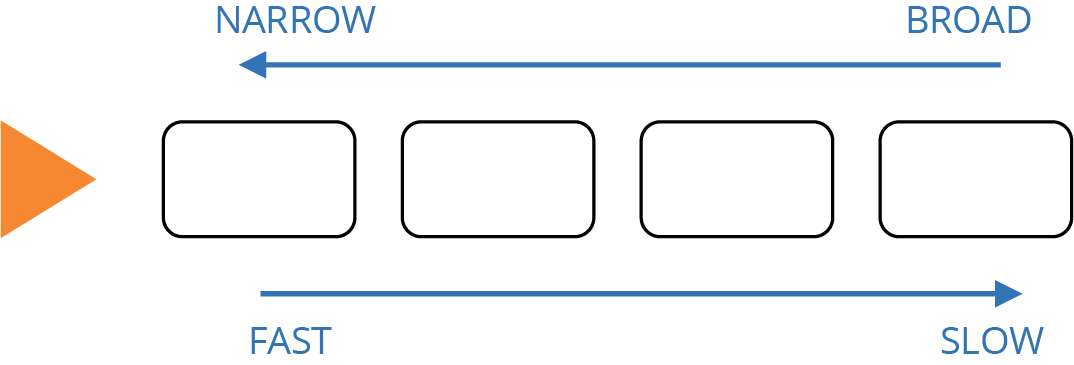
Figure 8-1. Scope versus speed of progressive testing
When a broadly scoped test fails, you have a large surface area of components and dependencies to investigate. So you should try to find any potential area at the earliest point, with the smallest scope that you can.
Another goal of a test strategy is to keep the overall test suite manageable. Avoid duplicating tests at different levels. For example, you may test that your application server configuration code sets the correct directory permissions on the log folder. This test would run in an earlier stage that explicitly tests the server configuration. You should not have a test that checks file permissions in the stage that tests the full infrastructure stack provisioned in the cloud.
Test Pyramid
The test pyramid is a well-known model for software testing.11 The key idea of the test pyramid is that you should have more tests at the lower layers, which are the earlier stages in your progression, and fewer tests in the later stages (see Figure 8-2).
The pyramid was devised for application software development. The lower level of the pyramid is composed of unit tests, each of which tests a small piece of code and runs very quickly.12 The middle layer is integration tests, each of which covers a collection of components assembled together. The higher stages are journey tests, driven through the user interface, which test the application as a whole.
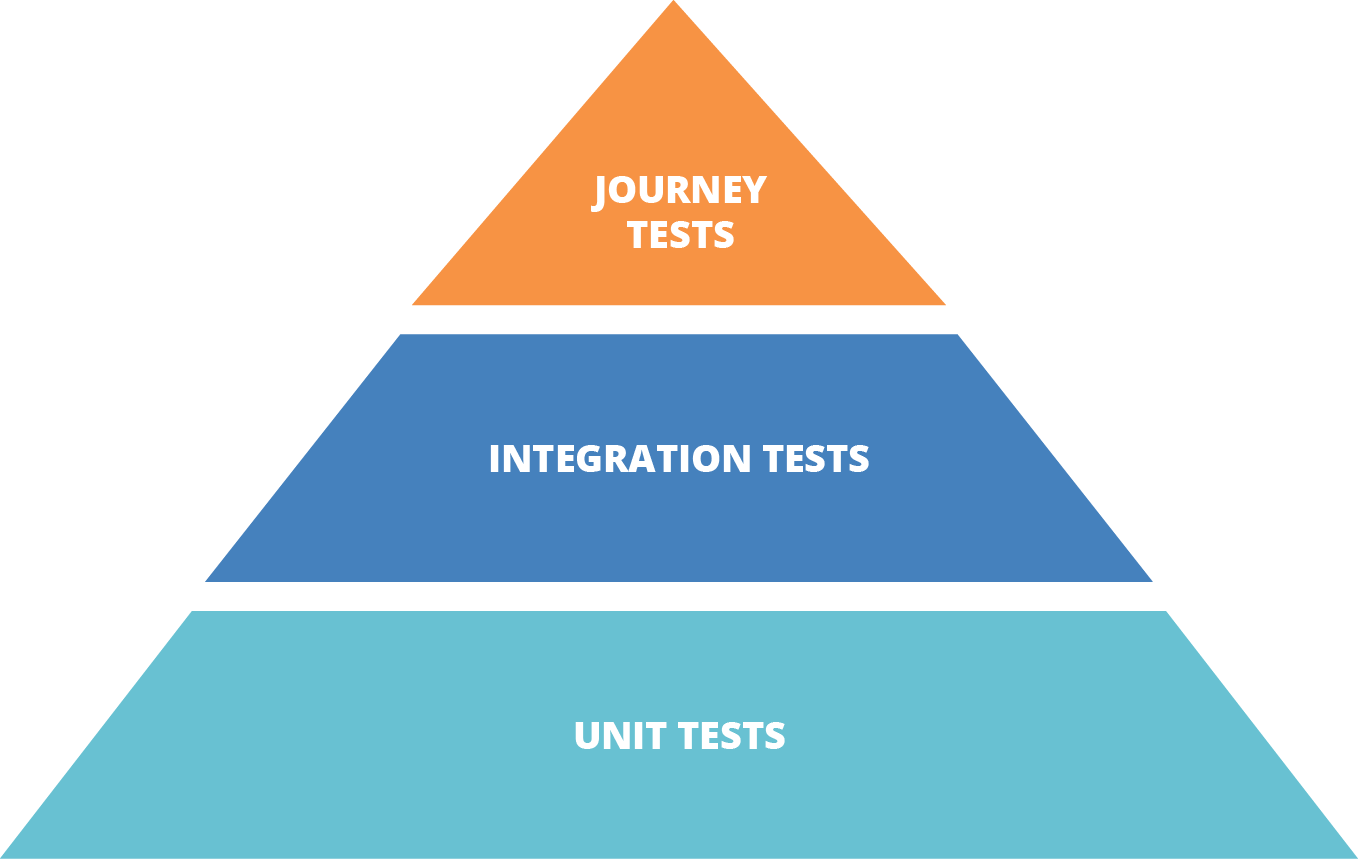
Figure 8-2. The classic test pyramid
The tests in higher levels of the pyramid cover the same scope already covered in lower levels. This means they can be less comprehensive—they only need to test functionality that emerges from the integration of components, rather than proving the behavior of lower-level components.
The testing pyramid is less valuable with declarative infrastructure codebases. Most low-level declarative stack code (see “Low-Level Infrastructure Languages”) written for tools like Terraform and CloudFormation is too large for unit testing, and depends on the infrastructure platform. Declarative modules (see “Reuse Declarative Code with Modules”) are difficult to test in a useful way, both because of the lower value of testing declarative code (see “Challenge: Tests for Declarative Code Often Have Low Value”) and because there is usually not much that can be usefully tested without the infrastructure.
This means that, although you’ll almost certainly have low-level infrastructure tests, there may not be as many as the pyramid model suggests. So, an infrastructure test suite for declarative infrastructure may end up looking more like a diamond, as shown in Figure 8-3.
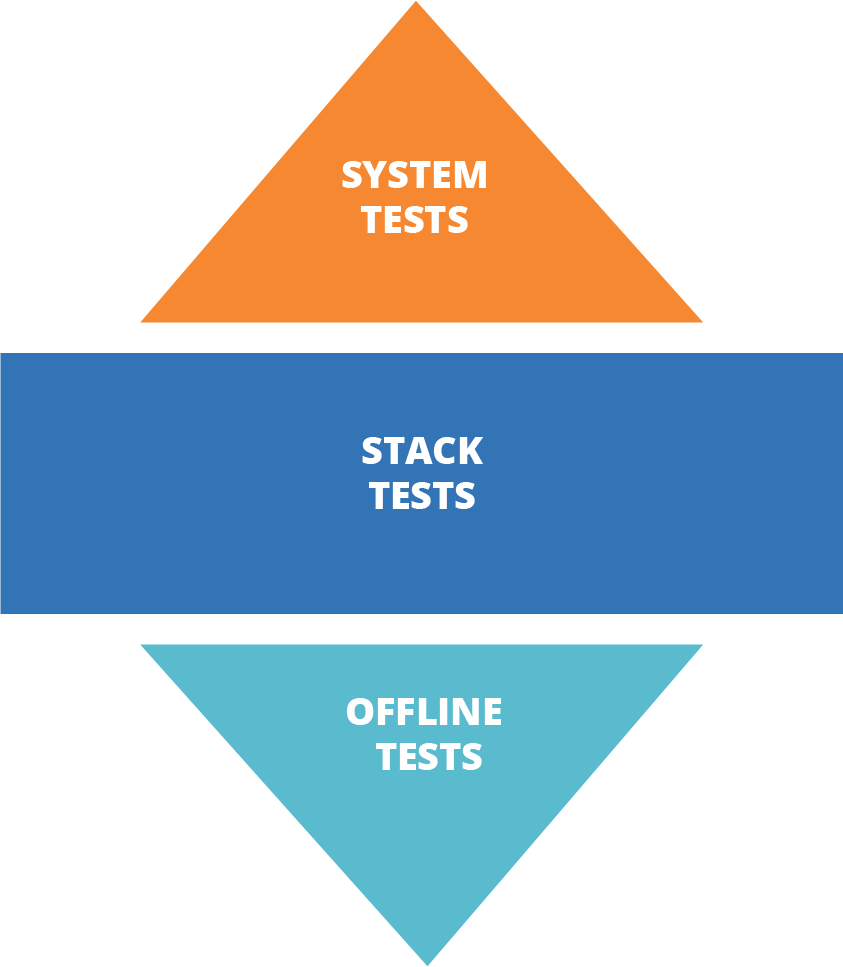
Figure 8-3. The infrastructure test diamond
The pyramid may be more relevant with an infrastructure codebase that makes heavier use of dynamic libraries (see “Dynamically Create Stack Elements with Libraries”) written in imperative languages (see “Programmable, Imperative Infrastructure Languages”). These codebases have more small components that produce variable results, so there is more to test.
Swiss Cheese Testing Model
Another way to think about how to organize progressive tests is the Swiss cheese model. This concept for risk management comes from outside the software industry. The idea is that a given layer of testing may have holes, like one slice of Swiss cheese, that can miss a defect or risk. But when you combine multiple layers, it looks more like a block of Swiss cheese, where no hole goes all the way through.
The point of using the Swiss cheese model when thinking about infrastructure testing is that you focus on where to catch any given risk (see Figure 8-4). You still want to catch issues in the earliest layer where it is feasible to do so, but the important thing is that it is tested somewhere in the overall model.
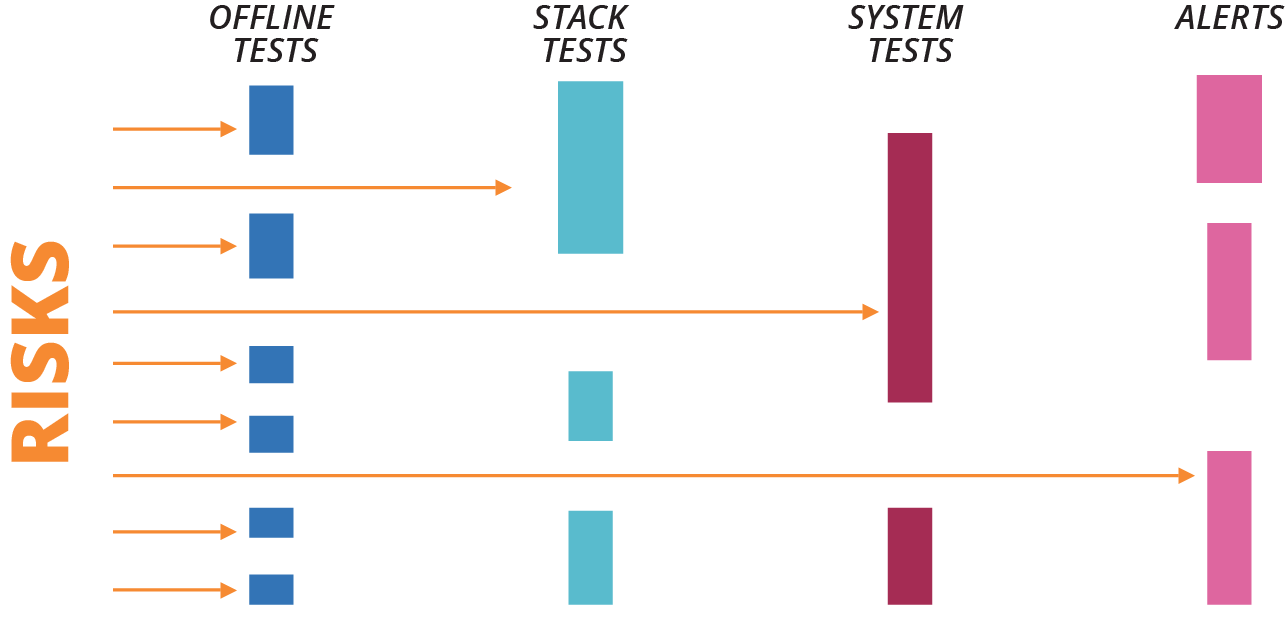
Figure 8-4. Swiss cheese testing model
The key takeaway is to test based on risk rather than based on fitting a formula.
Infrastructure Delivery Pipelines
A CD pipeline combines the implementation of progressive testing with the delivery of code across environments in the path to production.13 Chapter 19 drills into details of how pipelines can package, integrate, and apply code to environments. This section explains how to design a pipeline for progressive testing.
When someone pushes a code change to the source control repository, the team uses a central system to progress the change through a series of stages to test and deliver the change. This process is automated, although people may be involved to trigger or approve activities.
A pipeline automates processes involved in packaging, promoting, and applying code and tests. Humans may review changes, and even conduct exploratory testing on environments. But they should not run commands by hand to deploy and apply changes. They also shouldn’t select configuration options or make other decisions on the fly. These actions should be defined as code and executed by the system.
Automating the process ensures it is carried out consistently every time, for every stage. Doing this improves the reliability of your tests, and creates consistency between instances of the infrastructure.
Every change should be pushed from the start of the pipeline. If you find an error in a “downstream” (later) stage in a pipeline, don’t fix it in that stage and continue through the rest of the pipeline. Instead, fix the code in the repository and push the new change from the start of the pipeline, as shown in Figure 8-5. This practice ensures that every change is fully tested.

Figure 8-5. Start a new pipeline run to correct a failure
In the figure, one change successfully passes through the pipeline. The second change fails in the middle of the pipeline. A fix is made and pushed through to production in the third run of the pipeline.
Pipeline Stages
Each stage of the pipeline may do different things and may trigger in different ways. Some of the characteristics of a given pipeline stage include:
- Trigger
-
An event that causes the stage to start running. It may automatically run when a change is pushed to the code repository, or on the successful execution of the stage before it in the pipeline. Or someone may trigger the stage manually, as when a tester or release manager decides to apply a code change to a given environment.
- Activity
-
What happens when the stage runs. Multiple actions could execute for a stage. For example, a stage might apply code to provision an infrastructure stack, run tests, and then destroy the stack.
- Approval
-
How the stage is marked as passing or failing. The system could automatically mark the stage as passing (often referred to as “green”) when commands run without errors, and automated tests all pass. Or a human may need to mark the stage as approved. For example, a tester may approve the stage after carrying out exploratory testing on the change. You can also use manual approval stages to support governance sign-offs.
- Output
-
Artifacts or other material produced by the stage. Typical outputs include an infrastructure code package or a test report.
Scope of Components Tested in a Stage
In a progressive testing strategy, earlier stages validate individual components, while later stages integrate components and test them together. Figure 8-6 shows an example of progressively testing the components that lead to a web server running as part of a larger stack.
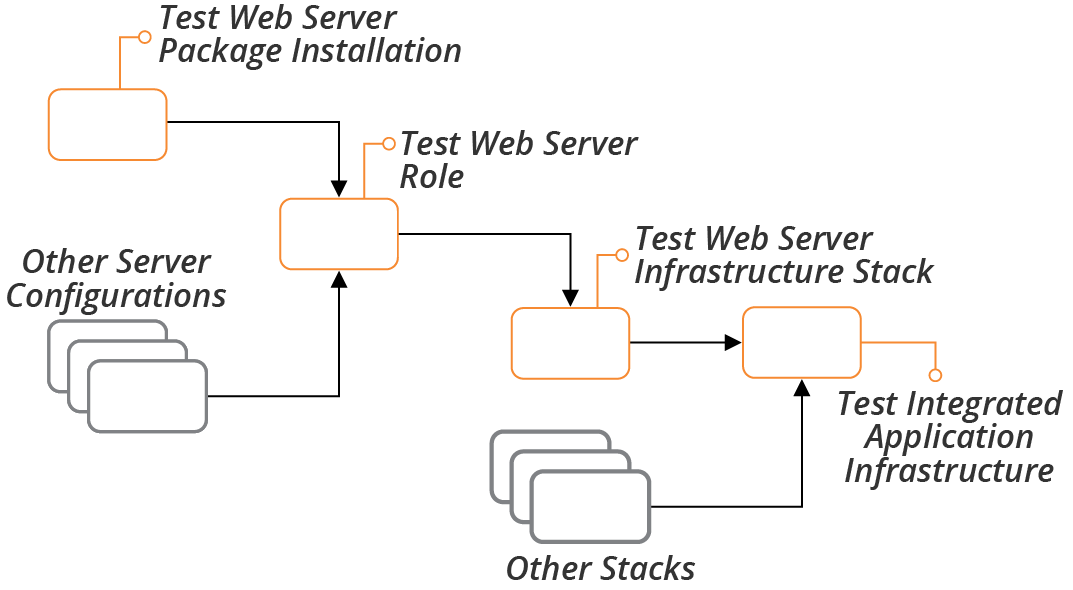
Figure 8-6. Progressive integration and testing of components
One stage might run tests for multiple components, such as a suite of unit tests. Or, different components may each have a separate test stage. Chapter 17 outlines different strategies for when to integrate different components, in the context of infrastructure stacks (see “Integrating Projects”).
Scope of Dependencies Used for a Stage
Many elements of a system depend on other services. An application server stack might connect to an identity management service to handle user authentication. To progressively test this, you might first run a stage that tests the application server without the identity management service, perhaps using a mock service to stand in for it. A later stage would run additional tests on the application server integrated with a test instance of the identity management service, and the production stage would integrate with the production instance (see Figure 8-7).
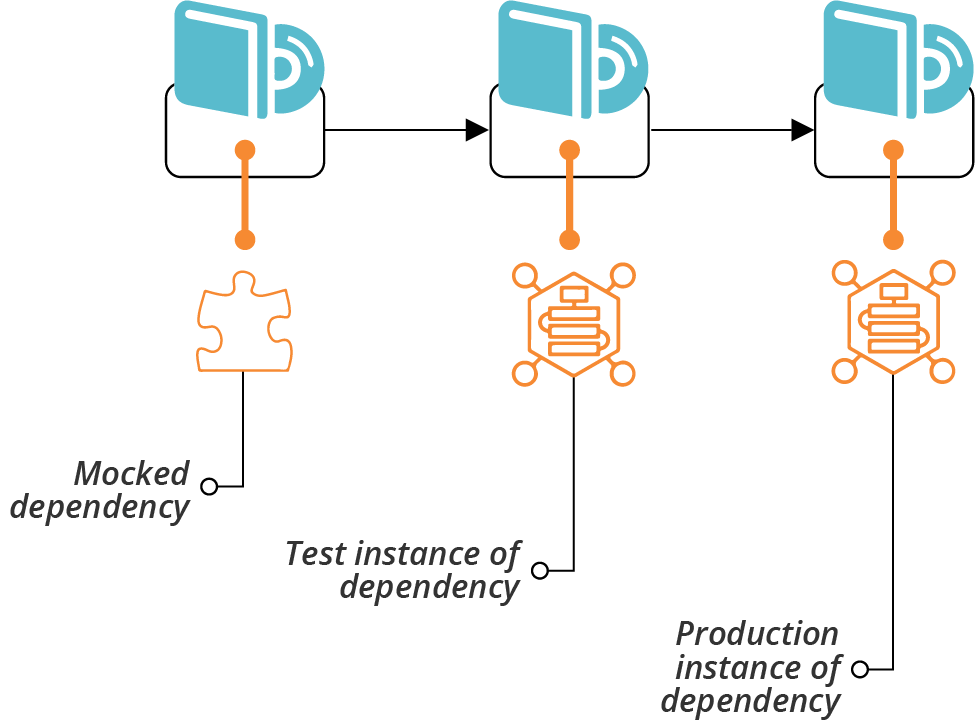
Figure 8-7. Progressive integration with dependencies
Only Include Stages That Add Value
Avoid creating unnecessary stages in your pipeline, as each stage adds time and cost to your delivery process. So, don’t create separate stages for each component and integration just for completeness. Split testing into stages this way only when it adds enough value to be worth the overhead. Some reasons that may drive you to do this include speed, reliability, cost, and control.
Platform Elements Needed for a Stage
Platform services are a particular type of dependency for your system. Your system may ultimately run on your infrastructure platform, but you may be able to usefully run and test parts of it offline.
For example, code that defines networking structures needs to provision those structures on the cloud platform for meaningful tests. But you may be able to test code that installs an application server package in a local virtual machine, or even in a container, rather than needing to stand up a virtual machine on your cloud platform.
So earlier test stages may be able to run without using the full cloud platform for some components (see Figure 8-8).
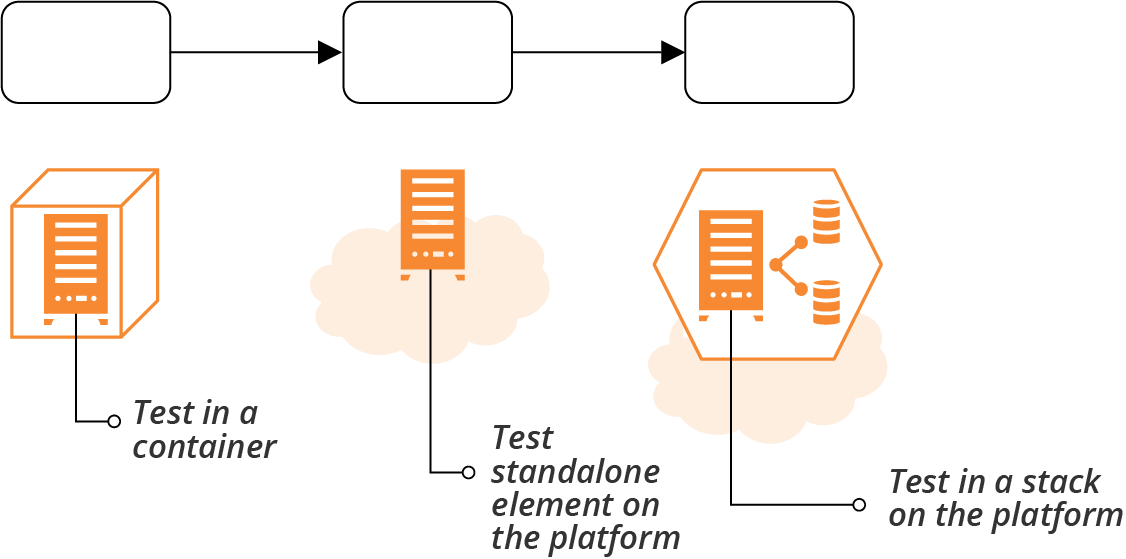
Figure 8-8. Progressive use of platform elements
Delivery Pipeline Software and Services
You need software or a hosted service to build a pipeline. A pipeline system needs to do a few things:
-
Give you a way to configure the pipeline stages.
-
Trigger stages from different actions, including automated events and manual triggers. The tool should support more complex relationships such as fanning in (one stage with multiple input stages) and fanning out (one stage with multiple output stages).
-
Support any actions you may need for your stages, including applying infrastructure code and running tests. You should be able to create custom activities rather than having a fixed set of supported ones.
-
Handle artifacts and other outputs of stages, including being able to pass them from one stage to the next.
-
Help you trace and correlate specific versions and instances of code, artifacts, outputs, and infrastructure.
There are a few options for a pipeline system:
- Build server
-
Many teams use a build server such as Jenkins, Team City, Bamboo, or GitHub Actions to create pipelines. These are often “job-oriented” rather than “stream-oriented.” The core design doesn’t inherently correlate versions of code, artifacts, and runs across multiple jobs. Most of these products have added support for pipelines as an overlay in their UI and configuration.
- CD software
-
CD software is built around the pipeline concept. You define each stage as part of a pipeline, and code versions and artifacts are associated with the pipeline so you can trace them forward and backward. CD tools include GoCD,14 ConcourseCI,15 and BuildKite.
- SaaS services
-
Hosted CI and CD services include CircleCI, TravisCI, AppVeyor, Drone, and BoxFuse.
- Cloud platform services
-
Most cloud vendors include CI and CD services, including AWS CodeBuild (CI) and AWS CodePipeline (CD), and Azure Pipelines.
- Source code repository services
-
Many source code repository products and vendors have added CI support that you can use to create pipelines. Two prominent examples are GitHub Actions, and GitLab CI and CD.
The products I mentioned here were all designed with application software in mind. You can use most of them to build pipelines for infrastructure, although they may need extra work.
A few products and services designed for Infrastructure as Code are emerging as I write. This is a rapidly changing area, so I suspect that what I have to say about these tools will be out of date by the time you read this, and missing newer tools. But it’s worth looking at what exists now, to give context for evaluating tools as they emerge and evolve:
-
Atlantis is a product that helps you to manage pull requests for Terraform projects, and to run
planandapplyfor a single instance. It doesn’t run tests, but you can use it to create a limited pipeline that handles code reviews and approvals for infrastructure changes. -
Terraform Cloud is evolving rapidly. It is Terraform-specific, and it includes more features (such as a module registry) than CI and pipelines. You can use Terraform cloud to create a limited pipeline that plans and applies a project’s code to multiple environments. But it doesn’t run tests other than policy validations with HashiCorp’s own Sentinel product.
-
WeaveWorks makes products and services for managing Kubernetes clusters. These include tools for managing the delivery of changes to cluster configuration as well as applications using pipelines based around Git branches, an approach it calls GitOps. Even if you don’t use WeaveWorks’s tools, it’s an emerging model that’s worth watching. I’ll touch on it a bit more in “GitOps”.
Testing in Production
Testing releases and changes before applying them to production is a big focus in our industry. At one client, I counted eight groups that needed to review and approve releases, even apart from the various technical teams who had to carry out tasks to install and configure various parts of the system.16
As systems increase in complexity and scale, the scope of risks that you can practically check for outside of production shrinks. This isn’t to say that there is no value in testing changes before applying them to production. But believing that prerelease testing can comprehensively cover your risks leads to:
Going Deeper on Testing in Production
For more on testing in production, I recommend watching Charity Majors’ talk, “Yes, I Test in Production (And So Should You)”, which is a key source of my thinking on this topic.
What You Can’t Replicate Outside Production
There are several characteristics of production environments that you can’t realistically replicate outside of production:
- Data
-
Your production system may have larger data sets than you can replicate, and will undoubtedly have unexpected data values and combinations, thanks to your users.
- Users
-
Due to their sheer numbers, your users are far more creative at doing strange things than your testing staff.
- Traffic
-
If your system has a nontrivial level of traffic, you can’t replicate the number and types of activities it will regularly experience. A week-long soak test is trivial compared to a year of running in production.
- Concurrency
-
Testing tools can emulate multiple users using the system at the same time, but they can’t replicate the unusual combinations of things that your users do concurrently.
The two challenges that come from these characteristics are that they create risks that you can’t predict, and they create conditions that you can’t replicate well enough to test anywhere other than production.
By running tests in production, you take advantage of the conditions that exist there—large natural data sets and unpredictable concurrent activity.
Why Test Anywhere Other Than Production?
Obviously, testing in production is not a substitute for testing changes before you apply them to production. It helps to be clear on what you realistically can (and should!) test beforehand:
-
Does it work?
-
Does my code run?
-
Does it fail in ways I can predict?
-
Does it fail in the ways it has failed before?
Testing changes before production addresses the known unknowns, the things that you know might go wrong. Testing changes in production addresses the unknown unknowns, the more unpredictable risks.
Managing the Risks of Testing in Production
Testing in production creates new risks. There are a few things that help manage these risks:
- Monitoring
-
Effective monitoring gives confidence that you can detect problems caused by your tests so you can stop them quickly. This includes detecting when tests are causing issues so you can stop them quickly.
- Observability
-
Observability gives you visibility into what’s happening within the system at a level of detail that helps you to investigate and fix problems quickly, as well as improving the quality of what you can test.17
- Zero-downtime deployment
-
Being able to deploy and roll back changes quickly and seamlessly helps mitigate the risk of errors (see “Changing Live Infrastructure”).
- Progressive deployment
-
If you can run different versions of components concurrently, or have different configurations for different sets of users, you can test changes in production conditions before exposing them to users (see “Changing Live Infrastructure”).
- Data management
-
Your production tests shouldn’t make inappropriate changes to data or expose sensitive data. You can maintain test data records, such as users and credit card numbers, that won’t trigger real-world actions.
- Chaos engineering
-
Lower risk in production environments by deliberately injecting known types of failures to prove that your mitigation systems work correctly (see “Chaos Engineering”).
Monitoring as Testing
Monitoring can be seen as passive testing in production. It’s not true testing, in that you aren’t taking an action and checking the result. Instead, you’re observing the natural activity of your users and watching for undesirable outcomes.
Monitoring should form a part of the testing strategy, because it is a part of the mix of things you do to manage risks to your system.
Conclusion
This chapter has discussed general challenges and approaches for testing infrastructure. I’ve avoided going very deeply into the subjects of testing, quality, and risk management. If these aren’t areas you have much experience with, this chapter may give you enough to get started. I encourage you to read more, as testing and QA are fundamental to Infrastructure as Code.
1 See “Continuous Integration” by Martin Fowler.
2 Jez Humble and David Farley’s book Continuous Delivery (Addison-Wesley) defined the principles and practices for CD, raising it from an obscure phrase in the Agile Manifesto to a widespread practice among software delivery teams.
3 As described in “From the Iron Age to the Cloud Age”.
4 See the Mountain Goat Software site for an explanation of Agile stories.
5 The Accelerate research published in the annual State of DevOps Report finds that teams where everyone merges their code at least daily tend to be more effective than those who do so less often. In the most effective teams I’ve seen, developers push their code multiple times a day, sometimes as often as every hour or so.
6 See Jez Humble’s website for more on CD patterns.
7 My colleague Sarah Taraporewalla coined the term CFR to emphasize that people should not consider these to be separate from development work, but applicable to all of the work. See her website.
8 See Perryn Fowler’s post for an explanation of writing Given, When, Then tests.
9 Martin Fowler’s bliki “Mocks Aren’t Stubs” is a useful reference for test doubles.
10 Examples of cloud mocking tools and libraries include Localstack and moto. Do Better As Code maintains a current list of this kind of tool.
11 “The Practical Test Pyramid” by Ham Vocke is a thorough reference.
12 See the ExtremeProgramming.org definition of unit tests. Martin Fowler’s bliki definition of UnitTest discusses a few ways of thinking of unit tests.
13 Sam Newman described the concept of build pipelines in several blog posts starting in 2005, which he recaps in a 2009 blog post, “A Brief and Incomplete History of Build Pipelines”. Jez Humble and Dave Farley’s Continuous Delivery book (referenced earlier in this chapter) popularized pipelines. Jez has documented the deployment pipeline pattern on his website.
14 In the interest of full disclosure, my employer, ThoughtWorks, created GoCD. It was previously a commercial product, but it is now fully open source.
15 In spite of its name, ConcourseCI is designed around pipelines rather than CI jobs.
16 These groups were: change management, information security, risk management, service management, transition management, system integration testing, user acceptance, and the technical governance board.
17 Although it’s often conflated with monitoring, observability is about giving people ways to understand what’s going on inside your system. See Honeycomb’s “Introduction to Observability”.