Chapter 5. Building Infrastructure Stacks as Code
This chapter combines Chapters 3 and 4 by describing ways to use code to manage infrastructure resources provided from an infrastructure platform.
The concept that I use to talk about doing this is the infrastructure stack. A stack is a collection of infrastructure resources defined and changed together. The resources in a stack are provisioned together to create a stack instance, using a stack management tool. Changes are made to stack code and applied to an instance using the same tool.
This chapter describes patterns for grouping infrastructure resources in stacks.
What Is an Infrastructure Stack?
An infrastructure stack is a collection of infrastructure resources that you define, provision, and update as a unit (Figure 5-1).
You write source code to define the elements of a stack, which are resources and services that your infrastructure platform provides. For example, your stack may include a virtual machine (“Compute Resources”), disk volume (“Storage Resources”), and a subnet (“Network Resources”).
You run a stack management tool, which reads your stack source code and uses the cloud platform’s API to assemble the elements defined in the code to provision an instance of your stack.
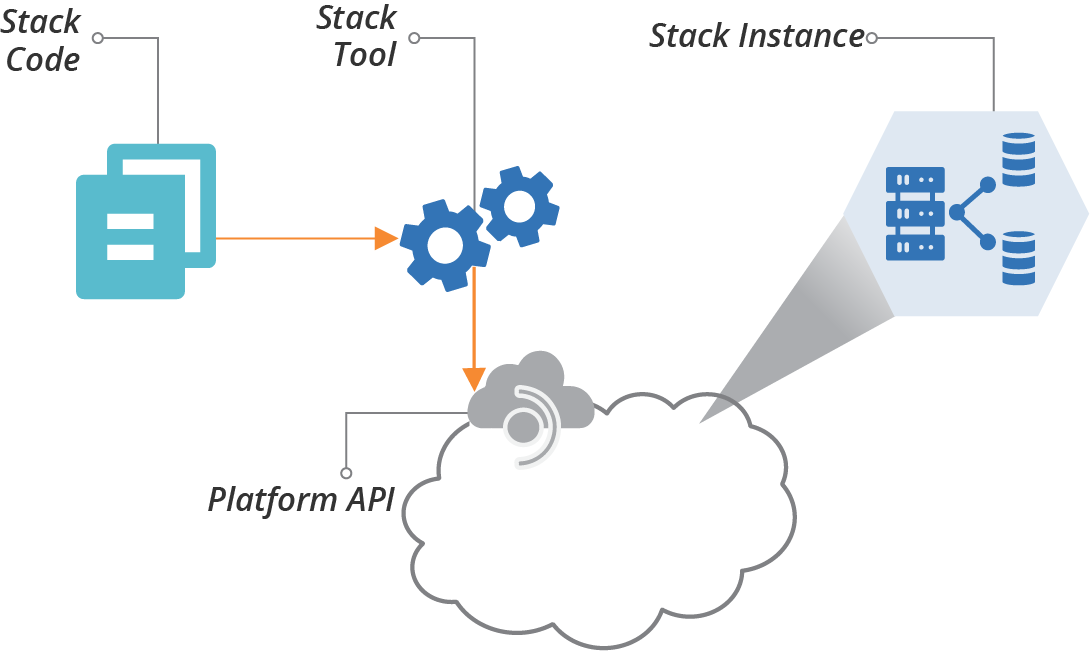
Figure 5-1. An infrastructure stack is a collection of infrastructure elements managed as a group
Examples of stack management tools include:
Some server configuration tools (which I’ll talk about much more in Chapter 11) have extensions to work with infrastructure stacks. Examples of these are Ansible Cloud Modules, Chef Provisioning (now end-of-lifed), Puppet Cloud Management, and Salt Cloud.
“Stack” as a Term
Most stack management tools don’t call themselves stack management tools. Each tool has its own terminology to describe the unit of infrastructure that it manages. In this book, I’m describing patterns and practices that should be relevant for any of these tools.
I’ve chosen to use the word stack.
Various people have told me there is a far better term for this concept. Each of these people had a completely different word in mind. As of this writing, there is no agreement in the industry as to what to call this thing. So until there is, I’ll continue to use the word stack.
Stack Code
Each stack is defined by source code that declares what infrastructure elements it should include. Terraform code (.tf files) and CloudFormation templates are both examples of infrastructure stack code. A stack project contains the source code that defines the infrastructure for a stack.
Example 5-1 shows the folder structure for a stack source code project for the fictional Stackmaker tool.
Example 5-1. Project folder structure of a stack project using a fictitious tool
stack-project/├── src/│ ├── dns.infra│ ├── load_balancers.infra│ ├── networking.infra│ └── webserver.infra└── test/
Stack Instance
You can use a single stack project to provision more than one stack instance. When you run the stack tool for the project, it uses the platform API to ensure the stack instance exists, and to make it match the project code. If the stack instance doesn’t exist, the tool creates it. If the stack instance exists but doesn’t exactly match the code, then the tool modifies the instance to make it match.
I often describe this process as “applying” the code to an instance.
If you change the code and rerun the tool, it changes the stack instance to match your changes. If you run the tool one more time without making any changes to the code, then it should leave the stack instance as it was.
Configuring Servers in a Stack
Infrastructure codebases for systems that aren’t fully container-based or serverless application architecture tend to include much code to provision and configure servers. Even container-based systems need to build host servers to run containers. The first mainstream Infrastructure as Code tools, like CFEngine, Puppet, and Chef, were used to configure servers.
You should decouple code that builds servers from code that builds stacks. Doing this makes the code easier to understand, simplifies changes by decoupling them, and supports reusing and testing server code.
Stack code typically specifies what servers to create, and passes information about the environment they will run in, by calling a server configuration tool. Example 5-2 is an example of a stack definition that calls the fictitious servermaker tool to configure a server.
Example 5-2. Example of a stack definition calling a server configuration tool
virtual_machine:name:appserver-waterworks-${environment}source_image:shopspinner-base-appservermemory:4GBprovision:tool:servermakerparameters:maker_server:maker.shopspinner.xyzrole:appserverenvironment:${environment}
This stack defines an application server instance, created from a server image called shopspinner-appserver, with 4 GB of RAM. The definition includes a clause to trigger a provisioning process that runs Servermaker. The code also passes several parameters for the Servermaker tool to use. These parameters include the address of a configuration server (maker_server), which hosts configuration files; and a role,
appserver, which Servermaker uses to decide which configurations to apply to this particular server. It also passes the name of the environment, which the configurations can use to customize the server.
Low-Level Infrastructure Languages
Most of the popular stack management tool languages are low-level infrastructure languages. That is, the language directly exposes the infrastructure resources provided by the infrastructure platform you’re working with (the types of resources listed in “Infrastructure Resources”).
It’s your job, as the infrastructure coder, to write the code that wires these resources together into something useful, such as Example 5-3.
Example 5-3. Example of low-level infrastructure stack code
address_block:name:application_network_tieraddress_range:10.1.0.0/24"vlans:-appserver_vlan_Aaddress_range:10.1.0.0/16virtual_machine:name:shopspinner_appserver_Avlan:application_network_tier.appserver_vlan_Agateway:name:public_internet_gatewayaddress_block:application_network_tierinbound_route:gateway:public_internet_gatewaypublic_ip:192.168.99.99incoming_port:443destination:virtual_machine:shopspinner_appserver_Aport:8443
This contrived and simplified pseudocode example defines a virtual machine, an address block and VLAN, and an internet gateway. It then wires them together and defines an inbound connection that routes connections coming into https://192.168.99.99 to port 8443 on the virtual machine.1
The platform may itself provide a higher layer of abstraction; for example, providing an application hosting cluster. The cluster element provided by the platform might automatically provision server instances and network routes. But low-level infrastructure code maps directly to the resources and options exposed by the platform API.
High-Level Infrastructure Languages
A high-level infrastructure language defines entities that don’t directly map to resources provided by the underlying platform. For example, a high-level code version of Example 5-3 might declare the basics of the application server, as shown in Example 5-4.
Example 5-4. Example of high-level infrastructure stack code
application_server:public_ip:192.168.99.99
In this example, applying the code either provisions the networking and server resources from the previous example, or it discovers existing resources to use. The tool or library that this code invokes decides what values to use for the network ports and VLAN, and how to build the virtual server.
Many application hosting solutions, such as a PaaS platform or packaged cluster (see “Packaged Cluster Distribution”), provide this level of abstraction. You write a deployment descriptor for your application, and the platform allocates the infrastructure resources to deploy it onto.
In other cases, you may build your own abstraction layer by writing libraries or modules. See Chapter 16 for more on this.
Patterns and Antipatterns for Structuring Stacks
One challenge with infrastructure design is deciding how to size and structure stacks. You could create a single stack code project to manage your entire system. But this becomes unwieldy as your system grows. In this section, I’ll describe patterns and antipatterns for structuring infrastructure stacks.
The following patterns all describe ways of grouping the pieces of a system into one or more stacks. You can view them as a continuum:
-
A monolithic stack puts an entire system into one stack.
-
An application group stack groups multiple, related pieces of a system into stacks.
-
A service stack puts all of the infrastructure for a single application into a single stack.
-
A micro stack breaks the infrastructure for a given application or service into multiple stacks.
Antipattern: Monolithic Stack
A monolithic stack is an infrastructure stack that includes too many elements, making it difficult to maintain (see Figure 5-2).
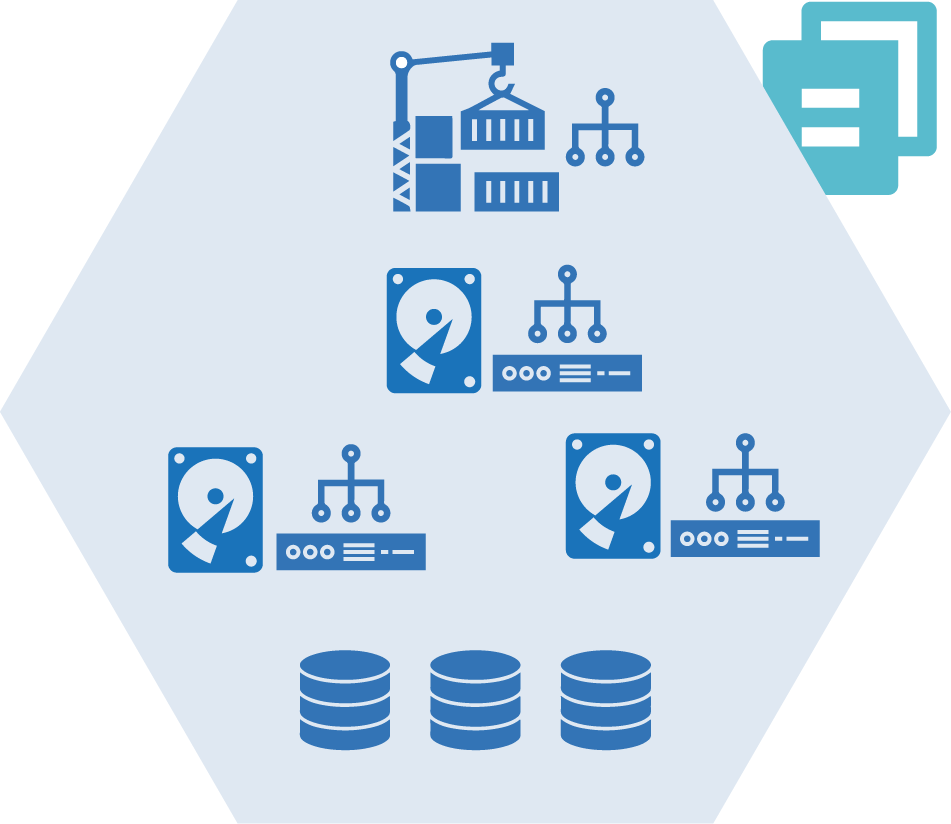
Figure 5-2. A monolithic stack is an infrastructure stack that includes too many elements, making it difficult to maintain
What distinguishes a monolithic stack from other patterns is that the number or relationship of infrastructure elements within the stack is difficult to manage well.
Motivation
People build monolithic stacks because the simplest way to add a new element to a system is to add it to the existing project. Each new stack adds more moving parts, which may need to be orchestrated, integrated, and tested.
A single stack is simpler to manage. For a modestly sized collection of infrastructure elements, a monolithic stack might make sense. But more often, a monolithic stack organically grows out of control.
Applicability
A monolithic stack may be appropriate when your system is small and simple. It’s not appropriate when your system grows, taking longer to provision and update.
Consequences
Changing a large stack is riskier than changing a smaller stack. More things can go wrong—it has a larger blast radius. The impact of a failed change may be broader since there are more services and applications within the stack. Larger stacks are also slower to provision and change, which makes them harder to manage.
As a result of the speed and risk of changing a monolithic stack, people tend to make changes less frequently and take longer to do it. This added friction can lead to higher levels of technical debt.
Blast Radius
The immediate blast radius is the scope of code that the command to apply your change includes.2 For example, when you run
terraform apply, the direct blast radius includes all of the code in your project. The indirect blast radius includes other elements of the system that depend on the resources in your direct blast radius, and which might be affected by breaking those resources.
Implementation
You build a monolithic stack by creating an infrastructure stack project and then continuously adding code, rather than splitting it into multiple stacks.
Related patterns
The opposite of a monolithic stack is a micro stack (see “Pattern: Micro Stack”), which aims to keep stacks small so that they are easier to maintain and improve. A monolithic stack may be an application group stack (see “Pattern: Application Group Stack”) that has grown out of control.
Pattern: Application Group Stack
An application group stack includes the infrastructure for multiple related applications or services. The infrastructure for all of these applications is provisioned and managed as a group, as shown in Figure 5-3.
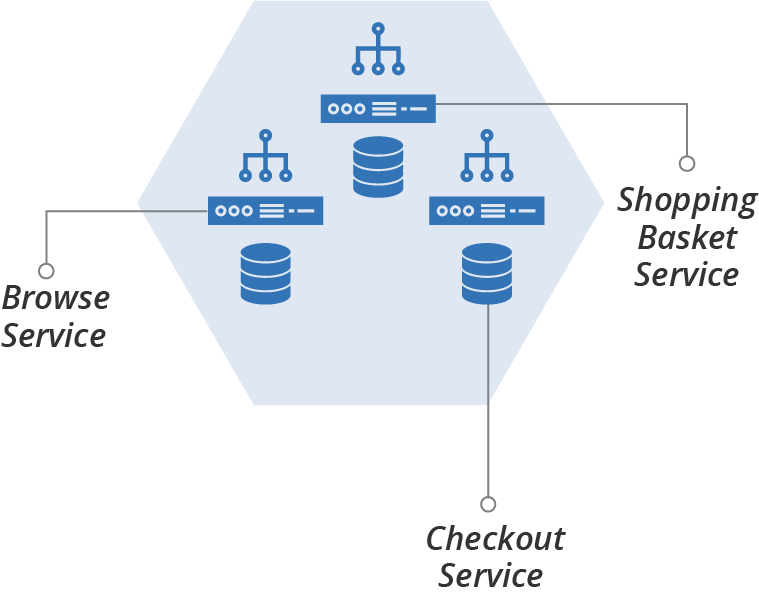
Figure 5-3. An application group stack hosts multiple processes in a single instance of the stack
For example, ShopSpinner’s product application stack includes separate services for browsing products, searching for products, and managing a shopping basket. The servers and other infrastructure for all of these are combined in a single stack instance.
Motivation
Defining the infrastructure for multiple related services together can make it easier to manage the application as a single unit.
Applicability
This pattern can work well when a single team owns the infrastructure and deployment of all of the pieces of the application. An application group stack can align the boundaries of the stack to the team’s responsibilities.
Multiservice stacks are sometimes useful as an incremental step from a monolithic stack to service stacks.
Consequences
Grouping the infrastructure for multiple applications together also combines the time, risk, and pace of changes. The team needs to manage the risk to the entire stack for every change, even if only one part is changing. This pattern is inefficient if some parts of the stack change more frequently than others.
The time to provision, change, and test a stack is based on the entire stack. So again, if it’s common to change only one part of a stack at a time, having it grouped adds unnecessary overhead and risk.
Implementation
To create an application group stack, you define an infrastructure project that builds all of the infrastructure for a set of services. You can provision and destroy all of the pieces of the application with a single command.
Related patterns
This pattern risks growing into a monolithic stack (see “Antipattern: Monolithic Stack”). In the other direction, breaking each service in an application group stack into a separate stack creates a service stack.
Pattern: Service Stack
A service stack manages the infrastructure for each deployable application component in a separate infrastructure stack (see Figure 5-4).
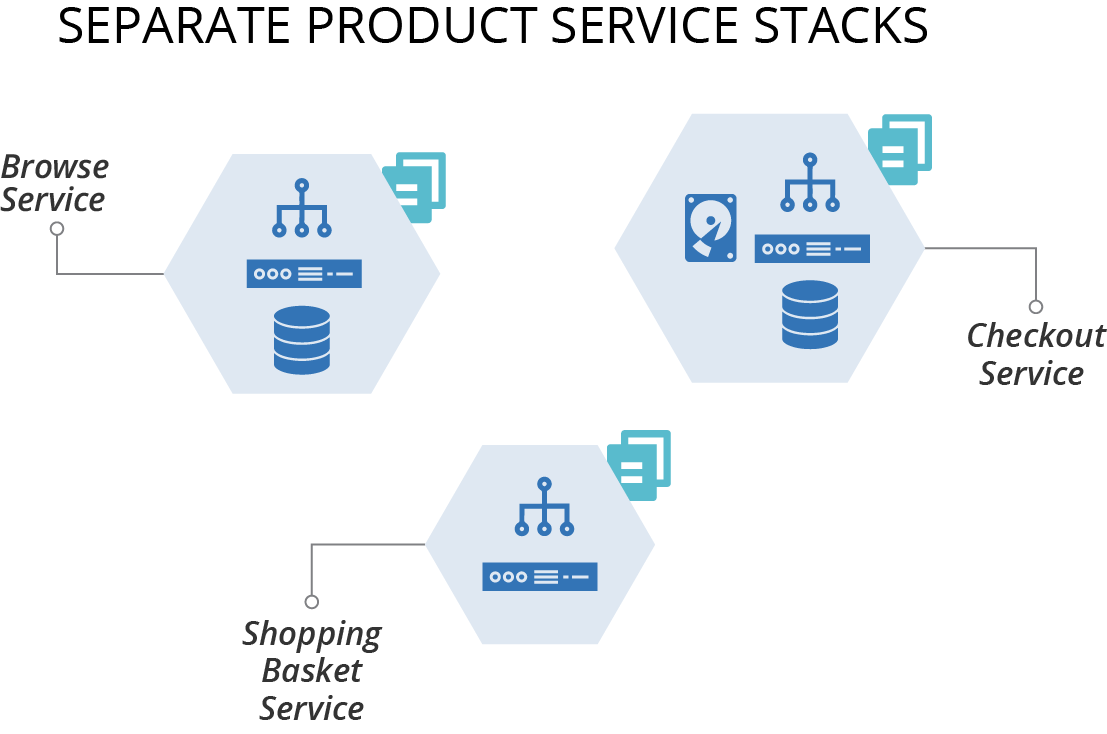
Figure 5-4. A service stack manages the infrastructure for each deployable application component in a separate infrastructure stack
Motivation
Service stacks align the boundaries of infrastructure to the software that runs on it. This alignment limits the blast radius for a change to one service, which simplifies the process for scheduling changes. Service teams can own the infrastructure that relates to their software.
Consequences
If you have multiple applications, each with an infrastructure stack, there could be an unnecessary duplication of code. For example, each stack may include code that specifies how to provision an application server. Duplication can encourage inconsistency, such as using different operating system versions, or different network configurations. You can mitigate this by using modules to share code (as in Chapter 16).
Implementation
Each application or service has a separate infrastructure code project. When creating a new application, a team might copy code from another application’s infrastructure. Or the team could use a reference project, with boilerplate code for creating new stacks.
In some cases, each stack may be complete, not sharing any infrastructure with other application stacks. In other cases, teams may create stacks with infrastructure that supports multiple application stacks. You can learn more about different patterns for this in Chapter 17.
Related patterns
The service stack pattern falls between an application group stack (“Pattern: Application Group Stack”), which has multiple applications in a single stack, and a micro stack, which breaks the infrastructure for a single application across multiple stacks.
Pattern: Micro Stack
The micro stack pattern divides the infrastructure for a single service across multiple stacks (see Figure 5-5).
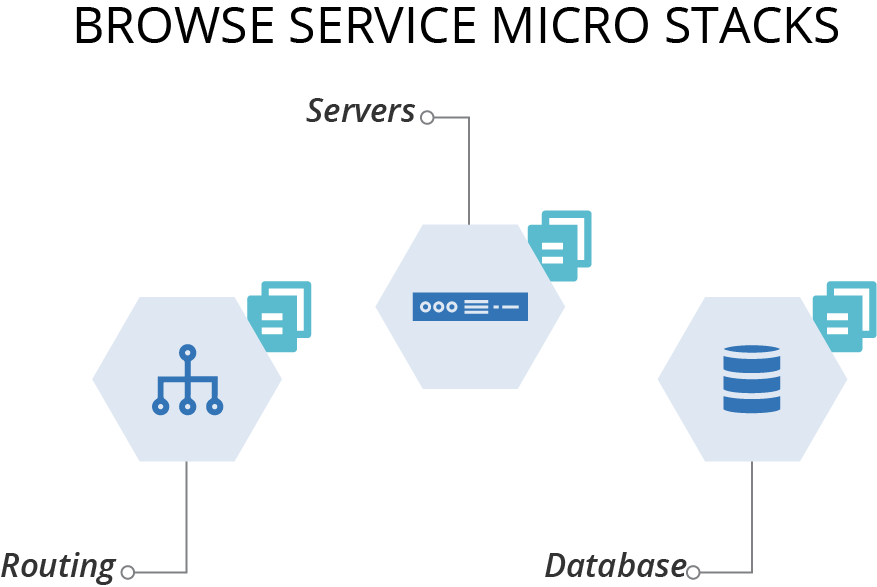
Figure 5-5. Micro stacks divide the infrastructure for a single service across multiple stacks
For example, you may have a separate stack project each for the networking, servers, and database.
Motivation
Different parts of a service’s infrastructure may change at different rates. Or they may have different characteristics that make them easier to manage separately. For instance, some methods for managing server instances involve frequently destroying and rebuilding them.5 However, some services use persistent data in a database or disk volume. Managing the servers and data in separate stacks means they can have different life cycles, with the server stack being rebuilt much more often than the data stack.
Consequences
Although smaller stacks are themselves simpler, having more moving parts adds complexity. Chapter 17 describes techniques for handling integration between multiple stacks.
Implementation
Adding a new micro stack involves creating a new stack project. You need to draw boundaries in the right places between stacks to keep them appropriately sized and easy to manage. The related patterns include solutions to this. You may also need to integrate different stacks, which I describe in Chapter 17.
Related Patterns
Micro stacks are the opposite end of the spectrum from a monolithic stack (see “Antipattern: Monolithic Stack”), where a single stack contains all the infrastructure for a system.
Conclusion
Infrastructure stacks are fundamental building blocks for automated infrastructure. The patterns in this chapter are a starting point for thinking about organizing infrastructure into stacks.
1 No, that’s not actually a public IP address.
2 Charity Majors popularized the term blast radius in the context of Infrastructure as Code. Her post “Terraform, VPC, and Why You Want a tfstate File Per env” describes the scope of potential damage that a given change could inflict on your system.
3 See “Microservices” by James Lewis.
4 See “The Art of Building Autonomous Teams” by John Ferguson Smart, among many other references.
5 For example, immutable servers (see “Pattern: Immutable Server”).