Chapter 14. Core Infrastructure Delivery Workflows
In the traditional waterfall model, a system is fully developed in a build phase, tested and deployed in a release phase, and then maintained in a run phase. In the past 10 to 20 years various interpretations of Agile and DevOps have emerged that, at their essence, focus on optimizing the flow of delivering value. Continuous delivery (CD) is an approach to software delivery that leverages automation, Extreme Programming (XP), and Lean principles to deliver incremental changes frequently and quickly.1 Figure 14-1 illustrates the difference between traditional and continuous delivery lifecycles.
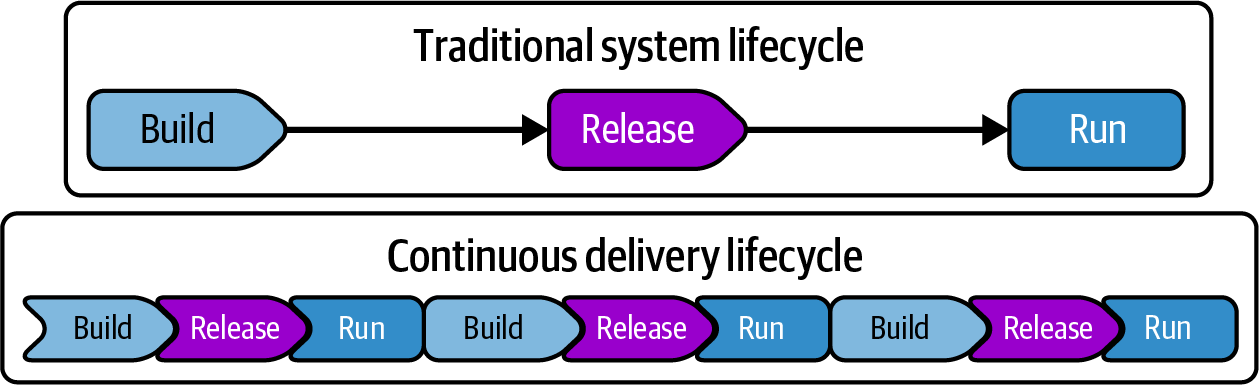
Figure 14-1. Traditional versus continuous delivery system lifecycles
CD has the following advantages over the traditional model:
-
Testing each change thoroughly enough to release, one by one, means issues are discovered and fixed sooner, when it’s simpler and cheaper to do so. A common failing of longer release cycles is that there is not enough time to fix everything discovered at the end, leading to kludgy workarounds and accepting “known issues.” CD supports a rigorous, “build quality in” culture.
-
Making the system usable early creates the opportunity to review how it works and gain user feedback early and often during development. CD enables fast feedback loops to improve the effectiveness and usability of the system during development and beyond.
-
The same tools, processes, and habits for fully proving and delivering incremental changes are useful for developing features and fixes before and after going live. Teams that release less frequently don’t build the levels of competence and often use less rigorous processes for “emergency” changes, increasing risk.
-
Measures for validating security, compliance, and other concerns can be incorporated into the automation, improving the consistency, reliability, and auditability for governance.
This chapter describes workflows for delivering infrastructure. The first part describes how to apply CD principles and practices to deliver new infrastructure, changes, updates, and upgrades to a system quickly and reliably and with strong governance. The second part defines the high-level stages of the change delivery workflow, including developing, building, testing, and releasing changes to infrastructure. The last part introduces basic team topologies for delivering infrastructure.
Continuous Delivery Principles for Infrastructure as Code
Chapter 2 lists a set of principles for designing and implementing cloud infrastructure. As a refresher, these are as follows:
-
Assume that systems are unreliable.
-
Make everything reproducible.
-
Avoid snowflake systems.
-
Create disposable things.
-
Minimize variation.
-
Ensure that you can repeat any procedure.
-
Apply software design principles to your infrastructure code.
These principles inform the design of infrastructure delivery workflows. In particular, by using automated pipelines to test and apply changes defined as code, you can easily reproduce your system and its elements, minimize variation among systems, and ensure procedures can be repeated. A few additional principles and practices are more specific to delivery workflows for infrastructure code changes. Some of these are drawn from practices commonly used in software delivery, and others are related to the nature of infrastructure and the cloud.
Automate the Full Process
Many teams starting out with Infrastructure as Code tools use them to automate steps in a manual process—for example, creating a runbook describing the steps to build an environment. The steps may include which files to edit and which commands to run, but a human needs to carry out those steps. A fully automated process, on the other hand, orchestrates each step without human intervention. In practice, humans may play a part, including reviewing the results of the change in a test environment, and approving the change to progress through the process. But the system manages the progression, and each action within it is automated.
A corollary to this principle is “define everything as code.” Code should describe not only the infrastructure resources, but also the deployment process, pipeline stages, developer setup, tests, and monitoring.
Make Changes Using Only the Automated Process
Teams using manual delivery processes will often find and fix an issue in a downstream environment such as staging. Often, tests that were run in previous stages aren’t run again after making the fix. Making a fix directly to a production environment takes this to the extreme, bypassing the release process entirely. This risks introducing new issues or regressions that could have been caught by the testing process. The fix may also not be implemented in the original source, leading to a regression when later changes are made to the code and applied over the fix.
When using a code-driven, pipeline-managed delivery process, every change should be made to the source and pushed through the pipeline from the beginning. No changes should be made to application, infrastructure, or other elements of the system anywhere other than at the start of the pipeline. When you discover an issue in a later stage of the delivery process, you might make changes directly as part of troubleshooting. But the fix should then be made to the source and progressed through the pipeline as soon as feasible. Doing this validates that the fix still works correctly when it reaches the environment where it failed originally, and that it isn’t reverted by a later change made to the unfixed source.
Ensure That Environments Are Consistent
Chapter 2 describes the perils of configuration drift, where similar infrastructure elements become inconsistent over time. Differences between environments used in the path to production make it harder to find and fix defects and issues before they impact users. Differences between production environment instances increase the cost of ownership, and make it hard to keep systems well-configured and up to date.
Implementing environments by using the Reusable Stack pattern is a key part of keeping environments consistent. However, you need effective workflows to make sure the code from those stacks is applied quickly and comprehensively across environments.
Deliver Changes Comprehensively
The delivery process should apply code changes to all relevant infrastructure within a short time frame. If it takes too long to apply changes to all environments, over time the versions of code will drift apart. Those differences, and local fixes and manual tweaks to environments, add to the time it takes to make a single change or update everywhere, creating a negative cycle that leads to Snowflakes as Code.
Ensure that each change is defined in code and any necessary variations are captured as configuration so the code can be tested and safely delivered everywhere.
When tracking and reporting the time and frequency of delivering changes to systems, be sure to measure the time to deliver a change to all relevant systems, not only to the first production system. It may be useful to also measure the lag between applying a change to the first production system and the last.
Keep Delivery Cycles Short
Tracking and optimizing the key metrics for the speed and frequency of delivering changes to infrastructure drives consistency across environments by making sure we don’t leave differing versions of infrastructure in place for very long.
A slow, heavyweight change process encourages people to go outside that process for urgent changes and fixes. These changes, made “temporarily,” have a way of staying in place. A fix may be overwritten if nobody has the time to go back and add it into the code and run it through the pipeline. Or people may disable the automation to avoid overwriting environment-specific fixes and tweaks. Over time, slower automated delivery processes tend to be abandoned because people find it easier and safer to just do things manually.
Continually optimize delivery systems and processes to deliver changes quickly and reliably, so that people prefer using the automated processes over making changes by hand.
Keep All Code Production-Ready
The principle of ensuring that the codebase is always production-ready, even if you don’t plan to release it, is fundamental to CD, although not always well understood. Traditional approaches to development normalize the idea that you may postpone some of the work needed to make the code production-ready for later, such as before release, or at the end of a time-boxed period like a sprint. The work left until later might include testing and bug fixing, security scanning, merging feature branches, deploying into a production-like environment, or reviews by stakeholders.
The thinking with CD is that it’s easier and more effective to carry out these tasks as you go. By checking whether the code passes all its validations and runs correctly for each small change, it’s easier to troubleshoot and fix problems than testing, troubleshooting, and fixing a larger batch of changes. I often think of it as similar to washing the dishes and cleaning the kitchen after every meal rather than letting dirty dishes pile up to be washed at the end of the week.
Not only is it less work to clean up after a small code change, but you also become very good at making changes. You find ways to make it easier to do the job quickly, including improving automation and streamlining system designs.
Another benefit of keeping your codebase always production-ready is that you can deliver small changes very quickly if needed. When you discover a critical issue or security hole, you can confidently push it straight out to your production systems.
Ensure That Code and Deployed Resources Are Consistent
It seems natural to deploy and apply code to systems only to make a change. The assumption is that deployed software and infrastructure resources won’t change from any other source. In practice, it’s possible that someone might change things from outside the automated delivery systems. They might do this because they find the automation too difficult or confusing to use, because they are under pressure to make a change quickly, or maybe even because they have bad intentions and don’t want the changes they make to be traceable.
Server-oriented Infrastructure as Code tools, notably Puppet and Chef, are designed to be run as agents that continually synchronize infrastructure code to servers. The tool executes periodically, for example hourly, applying the current version of the code whether it has changed or not. With the emergence of Kubernetes, application deployment tools, particularly Weaveorks and Argo, took advantage of the platform’s orchestration engine to implement control loops to continually synchronize immutable containerized applications by using declarative configuration, creating the GitOps approach. Chapter 19 describes how the Controller pattern can also be applied to deploy infrastructure.
Minimize Disruption When Deploying Changes
Deploying changes to an environment, especially changes to infrastructure, often interrupts operations. Production system downtime has obvious costs to an organization, but taking even nonproduction environments offline can disrupt business activities like developing and testing software. This downtime can impact the delivery time and frequency metrics of software.
I’ve found it useful to directly measure and track the typical downtime required for infrastructure changes of different types across all environments. How long is an environment down when a database is patched, container cluster upgraded, or network structures modified?
Techniques are available to reduce or eliminate downtime when deploying code, in addition to using testing and keeping environments consistent to make deploying less risky. However, it’s also useful to keep changes and their scope small by preferring to make small, incremental changes frequently rather than larger, less frequent changes, as well as by composing the system from smaller deployable components. See Chapter 20 for more detail on this topic.
Core Infrastructure Delivery Workflow
Figure 14-2 gives an overview of the stages of a change delivery workflow, which apply to software as well as infrastructure. Keep in mind that, as explained at the start of the chapter, this workflow applies to incremental changes, even those that may not be a complete new feature. The workflow is usually repeated many times to deliver and apply all the changes for a feature, project, or other piece of work. So these stages should not be confused with long-running phases of a delivery project in a waterfall model.

Figure 14-2. Delivery workflow stages
Each of these stages may include multiple parts or steps, such as having different sets of tests, and testing with and then without integrating dependencies. Some activities are repeated in multiple stages. For example, a developer may run tests locally before committing a change into the pipeline, where the same tests are run and recorded in a pipeline stage.
Development Stage
In the development stage, an infrastructure developer edits the infrastructure code in a personal workspace. They also run tests and may deploy the code to a personal instance of the system, which may be a local emulator, or to a sandbox instance on the IaaS platform. When the changes are ready, the developer pushes a change so that it can move on to the build stage. See “Working on Code Locally” for more details.
Build Stage
In a software build stage, an automated process prepares the code change for distribution and use in later workflow phases. The stage downloads libraries and other dependencies, and packages the build into a versioned, deployable artifact such as a container image. Software build stages are typically combined with running offline tests (see “Offline Testing Stages for Stacks”) as a part of a CI stage.
The use of a build stage for infrastructure delivery is not as well established as it is for software delivery, although it’s important for effectively implementing reusable stacks (see “Reusable Stack”). When a change is pushed to a stack project’s code, it creates a new version of a deployable code build. The build may be packaged into an artifact, such as a file stored in an artifact repository, or it may be referenced in the source code repository as a tag or branch. However it’s implemented, it should be possible to identify the build as a versioned changeset of code and dependencies.
“Build Stage: Preparing for Distribution” discusses infrastructure code build activities in detail, including ways to include them in delivery workflows for infrastructure.
Test Stages
The code build is validated, usually by deploying it to a series of test environments where testing is carried out. Testing is often divided across multiple stages to test the build in different contexts, such as before and after integrating it with other elements of the system. Some test stages may be manual, such as exploratory testing, code reviews, user acceptance testing, or reviews and authorization. Chapter 17 discusses testing strategy for infrastructure code, and Chapter 18 provides implementation guidance.
Workflow Cycles
As mentioned earlier, the workflow described here is not a batch process where a complete set of changes are made in one stage, and then progressed stage by stage until release. Instead, work is divided into incremental changes, with each change developed and pushed into the pipeline that implements the workflow. The incremental changes accumulate until the complete feature or project has been delivered.
Not every incremental change runs through the complete workflow to release. When a change fails at a stage of the pipeline (for example, in a test stage), the change does not continue. Even if the failure is diagnosed and fixed in the test environment, the change is made to the source, restarting the workflow from the beginning.
Even when an incremental change passes the testing stages, the team may decide not to release it to production. Ideally, team members use techniques such as those explained in “Changing a System Incrementally” that would allow them to safely deploy an incomplete change into production, but they may choose to wait.
As an example, two FoodSpin platform developers spend a week working on an update to a container cluster. They could make all the changes to a local copy of their code and push it into the pipeline when they’ve finished. They would then need to troubleshoot and fix the deployment issues and test failures from all of the changes they’d made over the week, which could take a day or more. In the meantime, their broke builds would potentially block anyone else from releasing changes to the cluster—for example, if someone found a critical issue or optimization.
Instead, the developers make small, incremental changes, pushing each one into the pipeline. Each change is run through all the build tests, including static analysis and dependency checking (see “Offline Testing Stages for Stacks”), and is then deployed to two test environments on their IaaS platform, one for automated testing, one for exploratory testing (see “Online Testing Stages for Stacks”). If one of their incremental changes introduces a problem that causes tests to fail, they discover and correct it immediately, rather than waiting until all the work is done at the end of the week before they find out.
Figure 14-3 shows multiple commits made by the platform developers passing through the stages of their workflow.
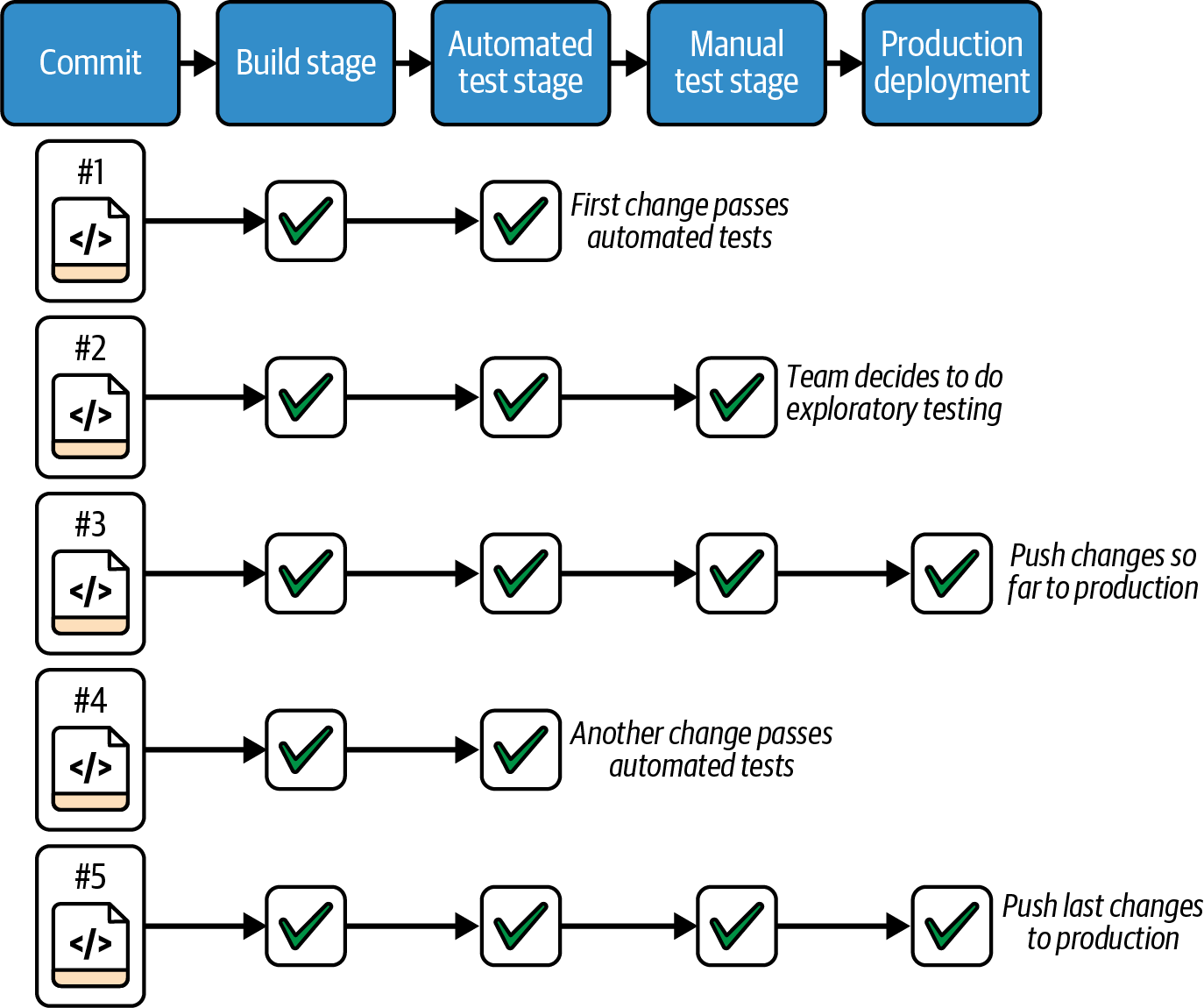
Figure 14-3. Not every change is pushed all the way to production
The developers often commit several changes before they deploy to the manual testing environment for exploratory testing. And they push changes to production only once or twice a day, when they reach a point where they are happy with their work so far and are confident their changes won’t disrupt production use.
When a deployment or test fails in the automated test stage, they could fix the issue in that test environment and then push their fixed code the rest of the way through the pipeline. But doing that would mean their fix isn’t subjected to the testing that happens in the build stage of the pipeline. So instead, they troubleshoot their fix in the test environment, but make the change in the source code and push it through the start of the pipeline, as in Figure 14-4.
As the developers finish their work on updating the cluster at the end of the week, they have very little left to do. Their local copy of the code is nearly identical to the code that has been thoroughly tested many times over the course of the week. When they push their last change, they know that, even if a test or deployment fails, they can focus their troubleshooting on that one change rather than needing to pick through and untangle a week’s worth of work, which may have multiple problems.
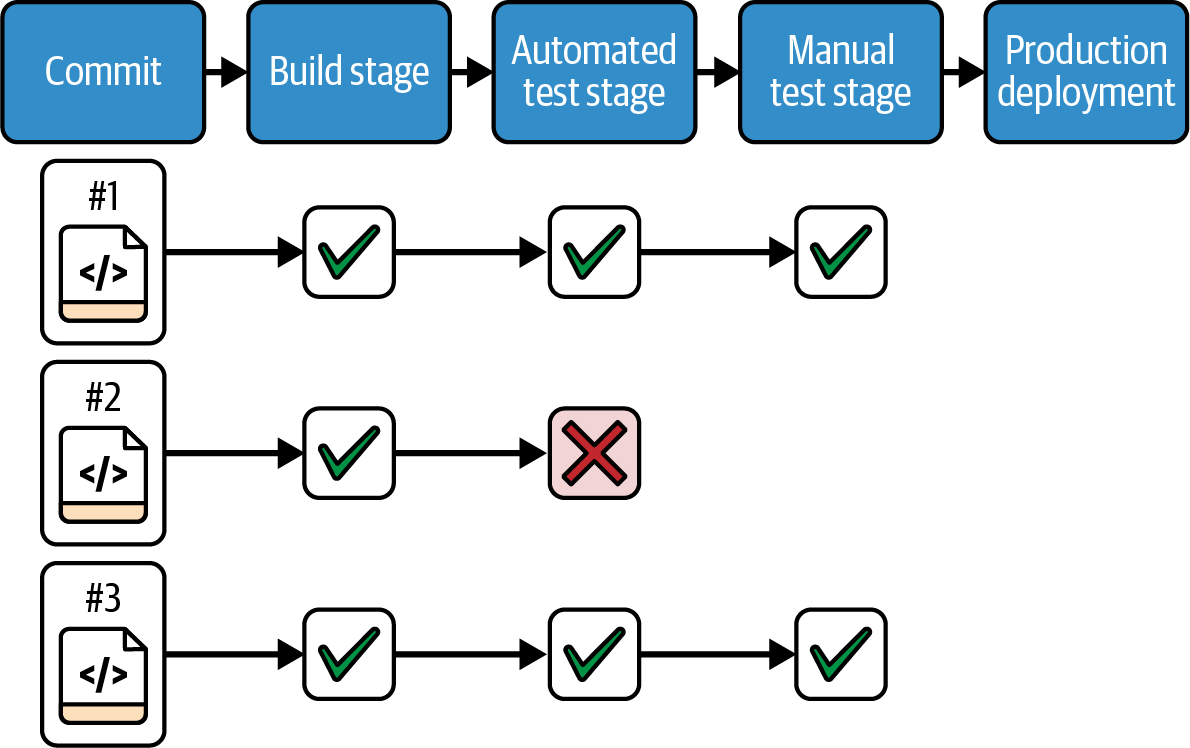
Figure 14-4. When a change fails in the pipeline, the fix is made as a new change
Workflows and Team Topologies for Delivering Software and Infrastructure
Software delivery workflows typically assume infrastructure is in place and updated for each stage where the software is deployed for testing or production. A common model for this approach has two separate workflows, one for the infrastructure and one for the software, as shown in Figure 14-5.
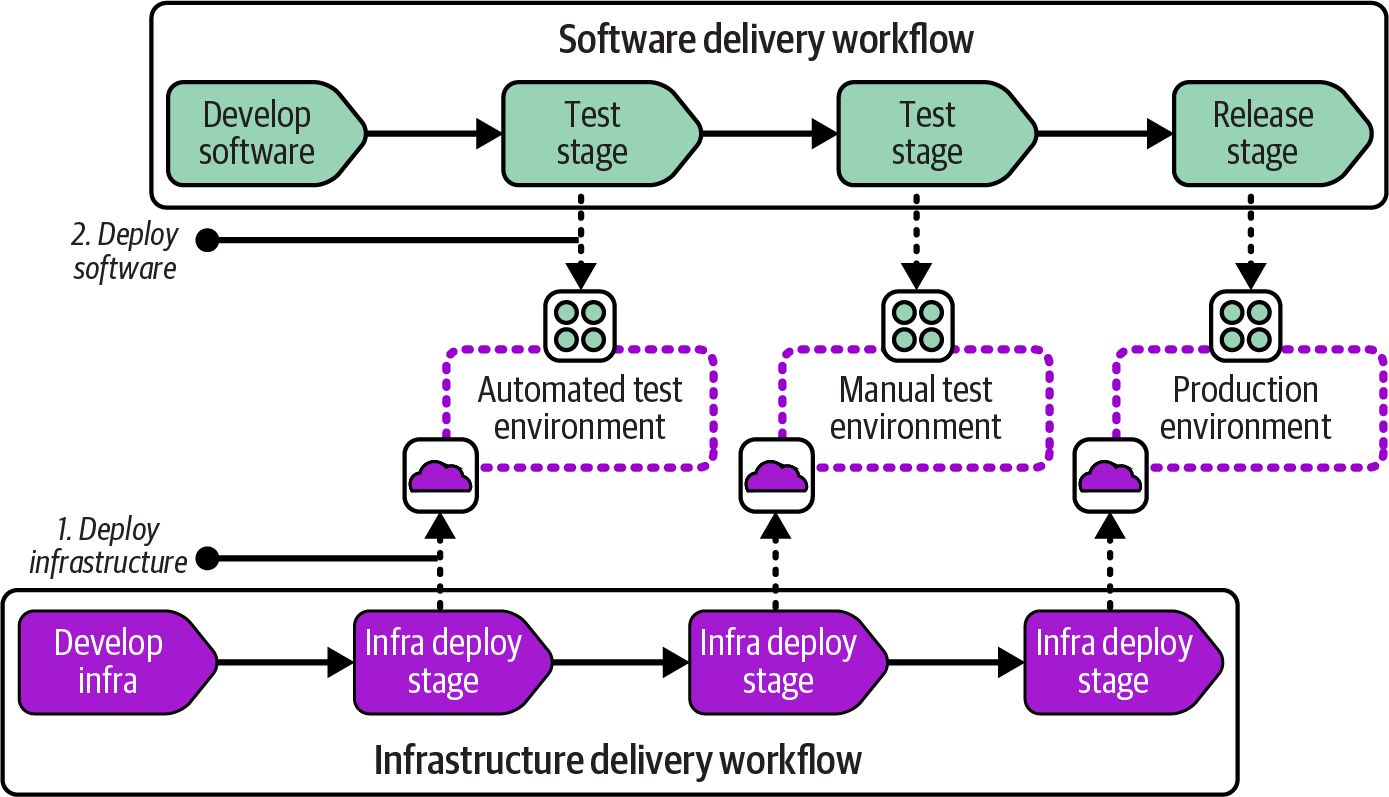
Figure 14-5. Separate workflows for software and infrastructure
Considering how multiple workflows interact raises questions about team structure and ownership of different parts of the system. I’ll use shapes and terminology from team topologies to illustrate team structures that can be used to support workflows for infrastructure. See “Team Topologies” for an introduction to the shapes used in this book.
Chapter 15 discusses more-complex workflows and topologies for handling infrastructure and systems that are decomposed into multiple components. For now, even the simple case of delivering one software component and one infrastructure stack to host it creates at least two options for organizing teams and their workflows. The first is separate software and infrastructure teams. The second is the full stack team.
Infrastructure Instance Management Teams
Many organizations go immediately to the idea of splitting the ownership of software and infrastructure across two teams, as shown in Figure 14-7.
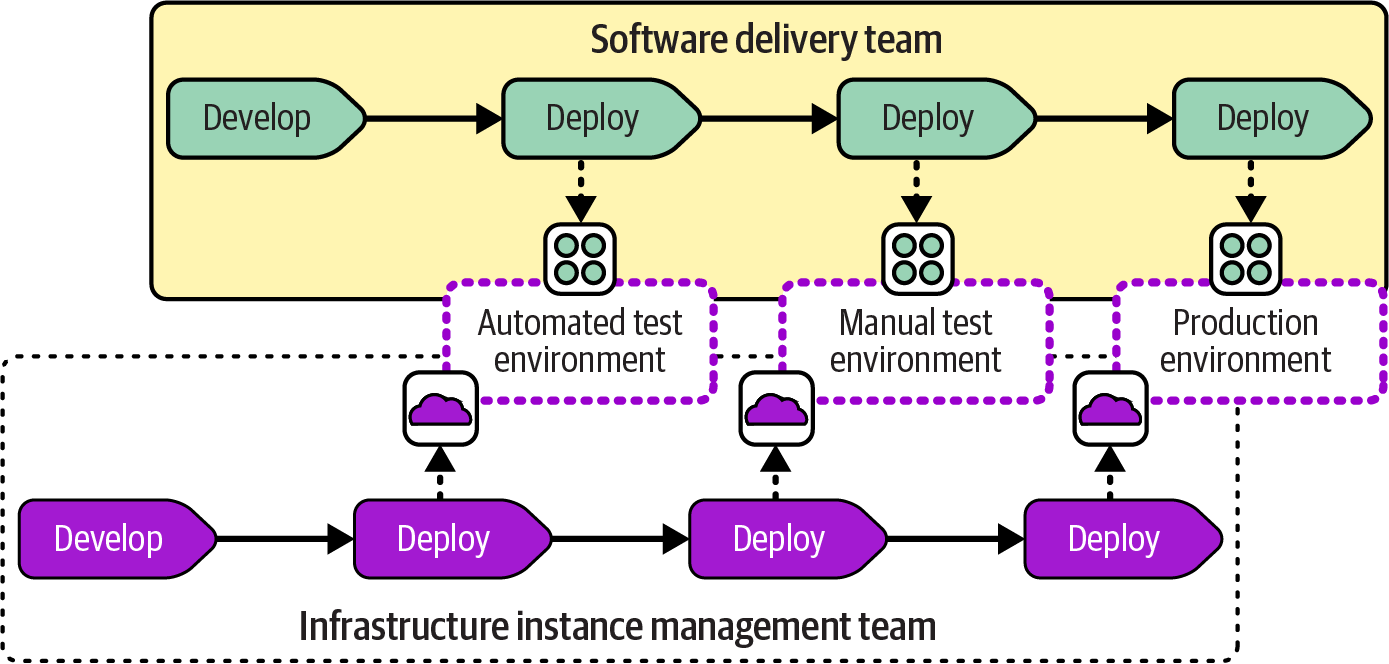
Figure 14-7. Infrastructure instance management team
This topology is a simple translation of the software and infrastructure workflows shown earlier into a team structure. An infrastructure instance management team becomes appealing with more-complex systems that involve shared infrastructure and multiple software applications. However, this divide can create issues.
“Using Value Stream Mapping to Improve Workflows” describes how to use value stream mapping to understand and optimize the flow of value. Figure 14-8 shows a simple value stream map for a software change that involves a change to infrastructure code.
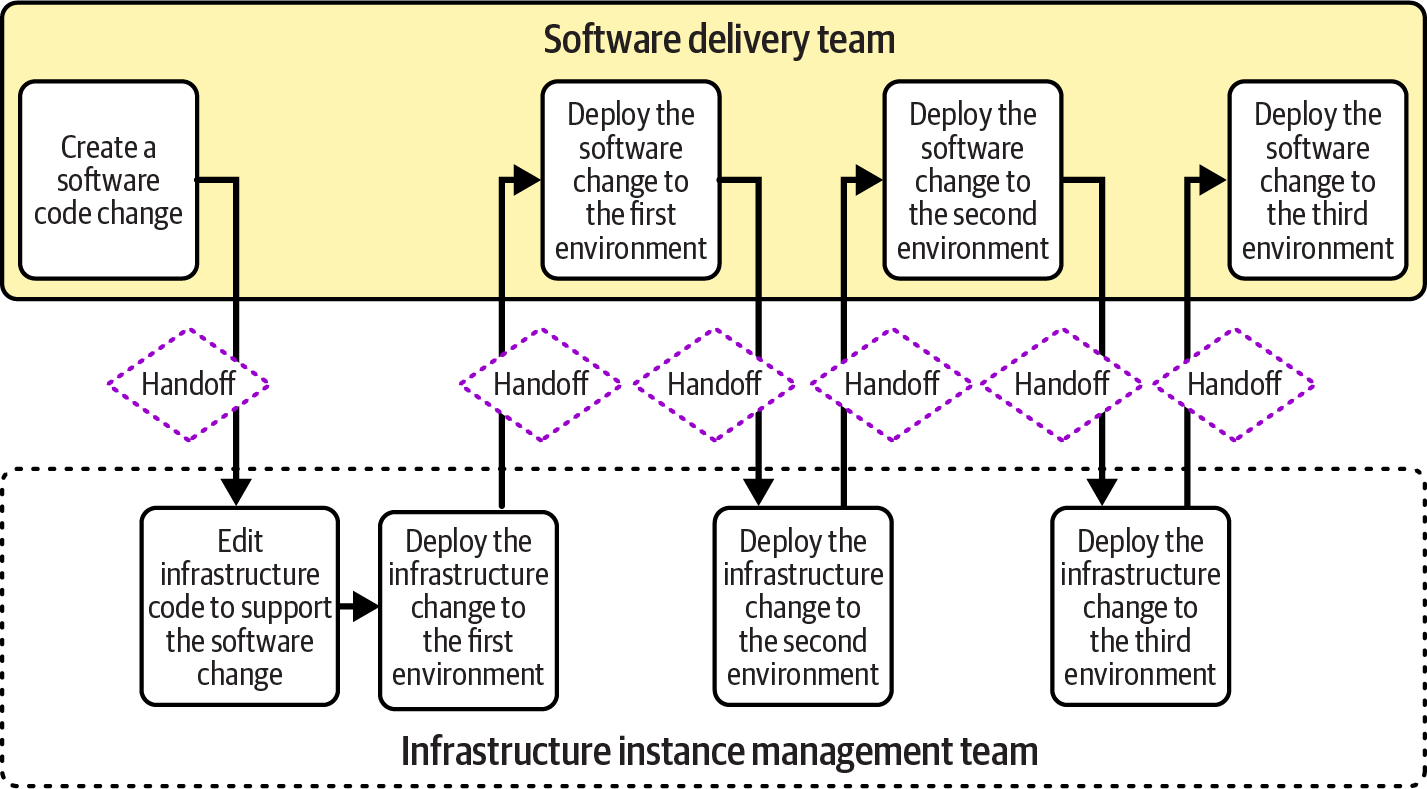
Figure 14-8. Handoffs across software and infrastructure instance management teams
This value stream shows quite a few handoffs between the software and infrastructure teams. Each of these handoffs is an opportunity for delay, waiting for someone in the other team to become available. It’s also an opportunity for a failure and rework. For example, the software team may discover that its software fails to deploy to the first environment because of an incompatibility between the infrastructure change and the software change.
As we’ll discuss in “Infrastructure Service Teams”, there are ways to minimize handoffs and reduce the chance of failures. However, taking these actions tends to become more practical with larger systems, when providing infrastructure to multiple teams. For a simple system, it’s often more effective to combine the responsibility for infrastructure and software in a single, full stack team.
Full Stack Infrastructure Team
A full stack team owns the development, deployment, and operation of infrastructure along with the software that runs on it. The workflow for the software and the infrastructure can be seen as a single stream, as in Figure 14-9.
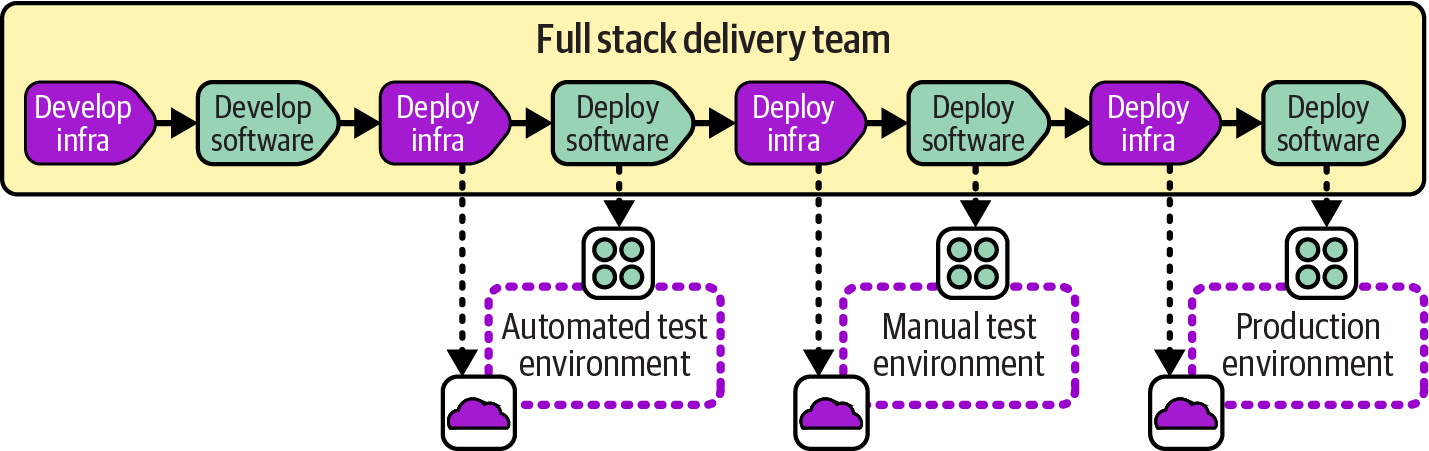
Figure 14-9. The full stack infrastructure team owns the workload and its infrastructure
All members of a full stack team don’t necessarily have the same skills and work on every part of their system. The team may include developers and infrastructure engineers, but they prioritize their work across the parts as a whole. Each change that involves both software and infrastructure can be worked on as a single item, with the necessary people collaborating to make sure the change works correctly across the system.
Infrastructure Enablement Team
As a system grows to the point where full stack teams begin to struggle, one way to evolve is to introduce an infrastructure enablement team, as shown in Figure 14-10.
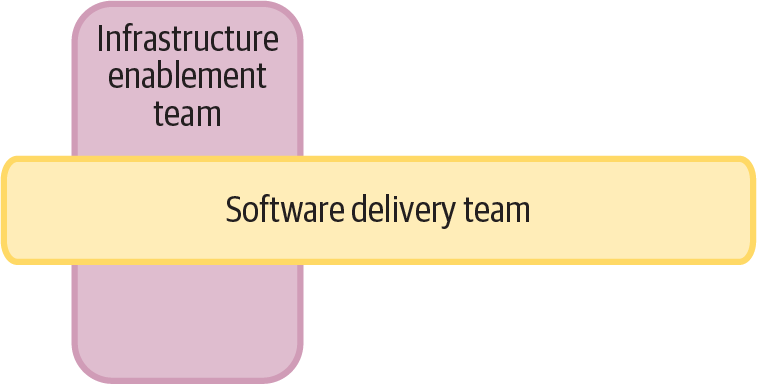
Figure 14-10. The infrastructure enablement team supports the software team to deliver infrastructure
The software delivery team members still have responsibility for building and deploying the infrastructure they use, but the enablement team helps them with infrastructure development work and makes sure they’re able to deploy and configure it. Enablement teams work closely with the teams they support, often having team members pair with members of the software team on the infrastructure work.
Infrastructure enablement teams are usually an interim stage, before moving to infrastructure service teams or infrastructure component teams (see “Infrastructure Service Teams”).
Measuring Infrastructure Delivery Effectiveness
Measures are useful for making decisions about delivery workflows and practices, as well as about design and team organization. The four key metrics identified by the DORA group (see “The Four Key Metrics”) are a good base set of measures. The performance of software delivery processes on these metrics, although also affected by other factors, is an indicator of how well environments and infrastructure for delivery and production hosting enable delivery effectiveness.
As a refresher, the four key metrics are listed here:
- Delivery lead time
-
The elapsed time it takes to implement, test, and deliver changes to the production system
- Deployment frequency
-
How often changes are deployed to production systems
- Change fail percentage
-
The percentage of changes that either cause an impaired service or need immediate correction, such as a rollback or emergency fix
- Mean time to restore (MTTR)
-
The amount of time it takes to restore service after an unplanned outage or impairment
The four key metrics can also be measured for changes to infrastructure and platform services, giving an idea of the effectiveness of infrastructure delivery systems and processes.
Other metrics that may be useful for infrastructure delivery include the following:
- Effort
-
How much expert time is needed to complete a change? Self-service systems and other automation can reduce this number.
- Toil
-
The amount of your infrastructure and platform team members’ time that is spent on work that could potentially be removed (typically repetitive, manual, tactical work).3
- Version spread
-
How many versions of the given software, infrastructure, and systems are currently deployed to systems in the estate? Keeping systems patched and upgraded reduces the time needed to maintain them and avoids the potential number of vulnerabilities.
- Utilization
-
How often environments and other infrastructure are actually in use. Replacing static, long-running environments with dynamically provisioned “environments as a service” can reduce waste.
These are only a few examples of measures you might use. See the Infrastructure as Code website for more ideas.
Conclusion
The workflows and topologies I’ve outlined in this chapter are the starting point for the rest of Part III. Chapter 15 discusses workflows, practices, and team shapes for building, distributing, and integrating infrastructure as part of a larger system that includes software delivery. Later chapters provide details on implementing delivery pipelines as well as testing, deploying, and modifying infrastructure with code.
1 For more on CD, see Continuous Delivery by Jez Humble and David Farley (Addison-Wesley), Continuous Delivery Pipelines by Dave Farley (independently published), and Continuous Deployment by Valentina Servile (O’Reilly).
2 Value Stream Mapping by Karen Martin and Mike Osterling (McGraw-Hill) is a good reference.
3 See Chapter 5 of Site Reliability Engineering, edited by Betsy Beyer et al. (O’Reilly).