Chapter 5. Design Principles for Infrastructure as Code
A good system design leads to an implementation that is effective in meeting the needs of its users and that is easy to continually evolve. This chapter discusses how to do this in the context of infrastructure implemented through code.
Traditional approaches to infrastructure architecture assume that an initial design, once implemented, won’t change much—which, as explained in Chapter 1, is a misconception. Many people aspire to treat designing software systems like designing a bridge or a building.1 The idea is that a design can anticipate and meet all potential future needs. The result is most often overly complex systems that are difficult to change in unexpected ways and so need to be completely replaced a few years later.
Software, including infrastructure defined as code, is much easier to change than a bridge or skyscraper. The difficulties that people have encountered with changing software mostly come from complex design and implementation, and from a lack of tooling and processes to make changes routine. The goal of modern system architecture should be to enable changes both small and large.
Building Evolutionary Architectures by Neal Ford et al. (O’Reilly) describes approaches to designing systems to change. The principles and practices underlying Agile and Lean approaches to software development all, at heart, work by making changes easier and safer. This book encourages applying this same way of thinking to infrastructure, so the approaches to design described in this chapter are oriented toward that goal of simplifying maintenance and changes.
This chapter describes design principles that have proven effective in software and system architecture, and when they are relevant to infrastructure architecture and when they aren’t.
Design Considerations for Infrastructure as Code
Beyond the obvious goal of meeting the current requirements effectively, good design should make it easy to understand the system, to improve its effectiveness, to correct issues, and to meet new requirements. The principle underpinning these goals is making it easy and safe to change the system. A design that is easy to understand helps people analyze, plan, and implement changes. A good system design lends itself to improving performance, capacity, security, and cost by making smaller adjustments rather than a complete overhaul. And, aligning systems with organizational structures removes overhead and risks from making changes.
I’ll cover a few useful concepts from software design and how they’re relevant to infrastructure. Two broad types of decisions are involved in system design. One is how to group elements into separate components. The other is handling dependencies among those components. These two considerations are related, so designing infrastructure involves making choices while understanding the trade-offs.
CUPID Properties for Design
Daniel Terhorst-North defines a set of properties that make software “a joy to work with,” using the acronym CUPID. Unlike other approaches that define principles that should be followed, CUPID defines properties that can be assessed to understand how trade-offs might be different in different situations.
Each of the five CUPID properties is as relevant to infrastructure code as it is to general software design:
- Composable
-
Plays well with others. Composable infrastructure code is implemented as components with a small surface area and minimal dependencies. A composable infrastructure component is easy to work on, test, and deliver changes to in isolation from other parts of the system.
- Unix philosophy
-
Does one thing well. Each component should embody a single purpose. All components should follow a simple, consistent model in the way they are used.2
- Predictable
-
Does what you expect. An infrastructure component should be deterministic and observable. It should be easy to understand what the component will provision, what it’s doing when applying it, and what it has done when reviewing the resulting infrastructure.
- Idiomatic
-
Feels natural. Design infrastructure components so that their use feels obvious and natural to someone familiar with the resources they will provision and platforms they will be provisioned on.
- Domain-based
-
The solution domain models the problem domain in language and structure. Infrastructure code and components should be organized around the capabilities provided by the infrastructure they provision rather than implementation and technology details.
The CUPID properties are useful for understanding the rationale behind many of the concepts described in this section and beyond.
Cohesion and Coupling
Cohesion and coupling are two key attributes for considering the effectiveness of a design in grouping elements into components.3 They describe the relationships among elements within a component and across components, such as IaaS resources within and across infrastructure components.
Cohesion describes the relationships among the elements within a component. A component has high cohesion when all its elements are related to a single purpose. It has low cohesion if its elements aren’t closely related. The concept of cohesion aligns with the Unix philosophy mentioned in CUPID.
Figure 5-1 shows the infrastructure resources for several of FoodSpin’s software services defined and deployed together in a single infrastructure component.
Each of the services in this example has dedicated network and storage resources, as well as some shared compute and network resources. Many changes to the infrastructure are made to the resources for only one of the services, such as changing the network configuration for inbound requests to the patron service. However, making that single change involves modifying and deploying the entire infrastructure component, including the other resources that aren’t related to the service being worked on. The component in this example has low cohesion, because many of the resources it contains aren’t directly related to one another.
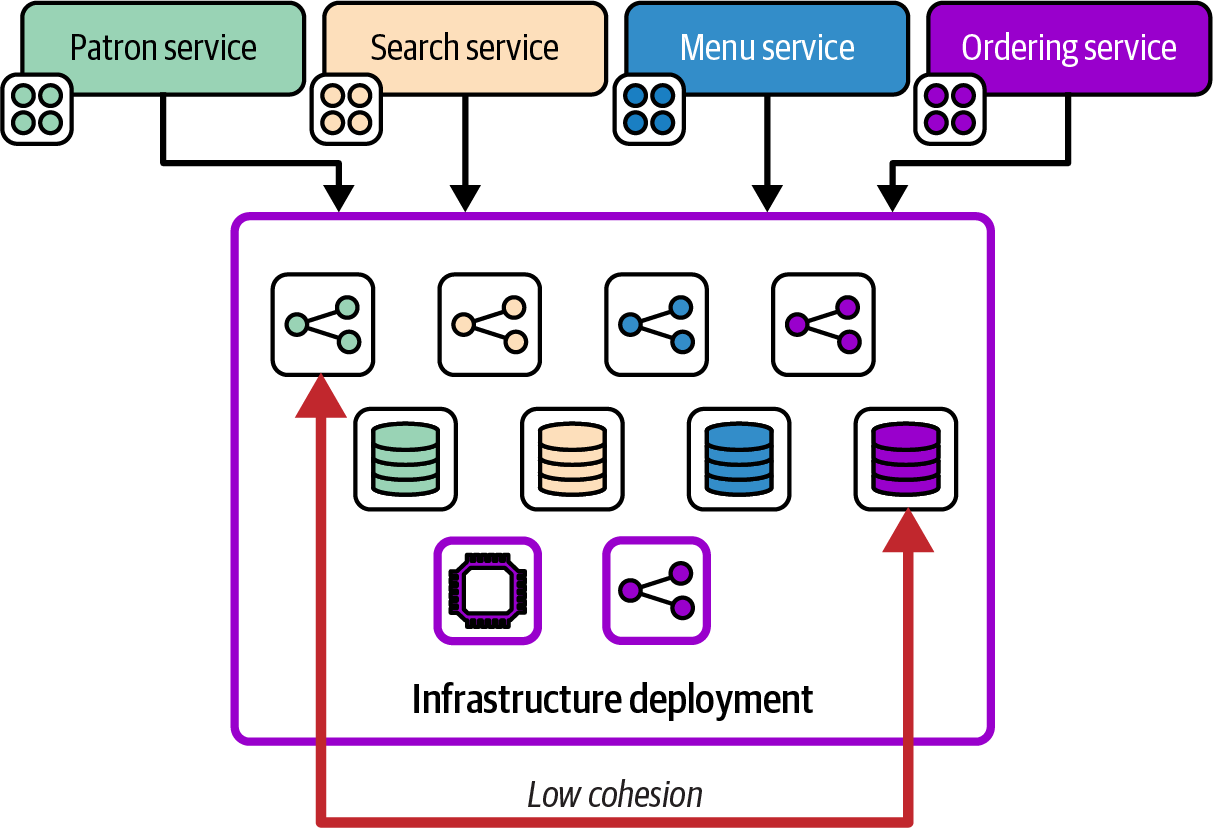
Figure 5-1. An infrastructure component with low cohesion
A rule of changing software is that you should never assume that the code you think you’re changing is the only thing that will change when you deploy it.4 This rule goes double for infrastructure code. So one rule of thumb for assessing cohesion for a component is to analyze which elements of the component are most often modified in the same change. If some elements are rarely changed with the others, they may belong in a separate component.
Components with low cohesion also tend to be large, in which case a useful approach to dealing with the issue is to break the component into smaller components. We’ll discuss approaches to breaking large components apart throughout this book. One of the trade-offs when breaking a component into smaller components is the potential for coupling across components.
Coupling describes the relationships among elements in different components. As with cohesion, considering the scope of common changes helps you understand the level of coupling. Two components are described as highly coupled, or tightly coupled, when it’s common for a change to one component to require a change to the other. Components are considered loosely coupled when one of them depends on the other but changes to one can most often be made without needing to change the other.
Figure 5-2 modifies the earlier example, moving the infrastructure resources specific to the search service application into a separate component, while keeping the networking resources for the service in a shared component with the resources for other services.
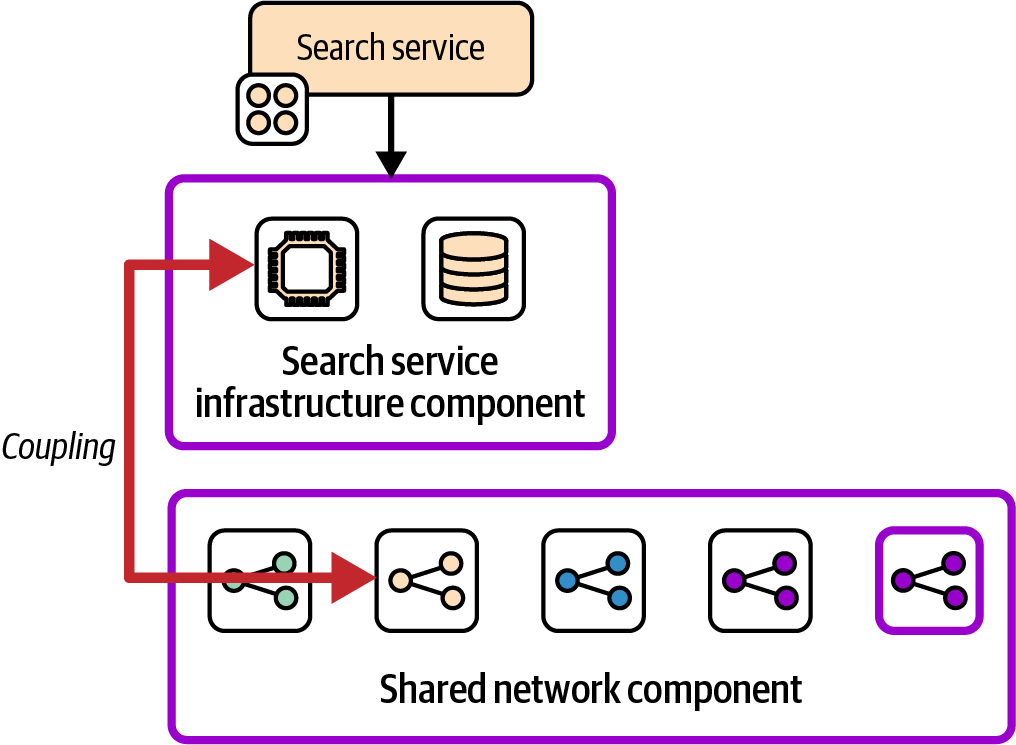
Figure 5-2. Tightly coupled infrastructure components
These two components are highly coupled if changing the infrastructure for the search service often requires a change to the shared network component, or the other way around.
Components designed with a single purpose, as per the Unix philosophy property of CUPID, tend to have high cohesion. Low coupling across components helps make them more composable.
Providers, Consumers, and Interfaces
Although we try to avoid tight coupling among components, we can’t avoid dependencies. A provider is a component that consumer components depend on. With infrastructure, a provider typically defines an infrastructure resource that the consumers need to refer to, such as subnets and load balancers. The provider-consumer relationship is relevant to many discussions around design, especially coupling and interfaces. Figure 5-3 shows a simple provider-consumer relationship for two infrastructure components.
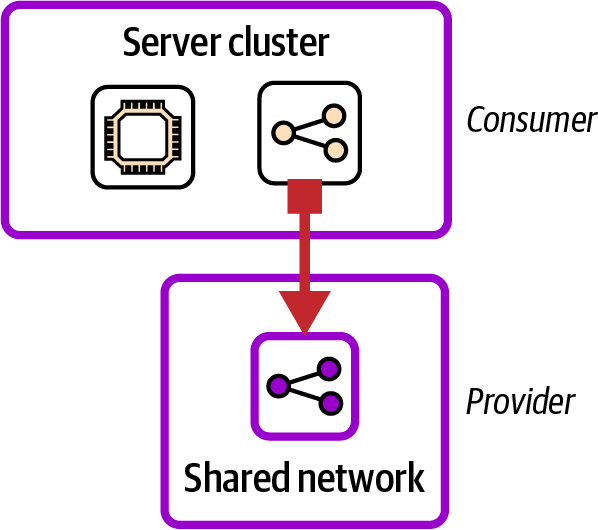
Figure 5-3. A consumer and provider relationship
In this example, the server cluster component is the consumer. It includes a load balancer that directs traffic to the application hosted on the servers. The shared network component is the provider, defining a virtual network and subnets that the load balancer from the server cluster is provisioned within.
Management of Interfaces Between Components
A dependency between two components should be explicitly defined as an interface. Building an infrastructure system without giving much thought to the dependencies usually leads to brittle implementations and tight coupling. Making a change to one part of the infrastructure can have a chain of effects on other parts that is difficult to untangle. Effective design and implementation of interfaces should keep coupling loose, making it easy to test, change, and troubleshoot the system.
Systems that evolve without much attention to dependencies often have implicit interfaces that can create problems later. For example, the FoodSpin container team owns a component that defines a Kubernetes cluster with its VPC and subnets. When the monitoring team created a new component to provision VMs to host a log aggregation service, the team used subnets created by the Kubernetes component to simplify connectivity with the cluster. Later, the container team restructured its subnets, not realizing that the monitoring team was also using them, which caused an outage of the logging service.
So the design of any type of infrastructure component should explicitly define what the component needs from other components. This forms an interface contract, which means the provider team commits to maintaining the interface consistently. Most infrastructure tools have multiple features that can be used to expose resources, such as declaring outputs and naming and tagging resources. Organizations should establish conventions and standards for declaring and managing interfaces and contracts between infrastructure components so that teams clearly know how to use them consistently.
Use of Interfaces for Composability
Making the interfaces explicit helps clarify when a change to one component may affect other components. However, well-defined interfaces aren’t enough to keep components loosely coupled. It’s often impossible to provision one component to develop and test it without provisioning a pile of other components that it depends on.
Composable infrastructure components can be independently provisioned, which is not only a CUPID property, but also an enabler for effective delivery, testing, and operability. In some cases, it may even be useful for a component to use different provider components in different contexts.
The FoodSpin monitoring team refactored its log aggregation service component to remove the dependency on the container team’s component. For production environments and others that involve integrating with the full system, the team integrates with the production network component. However, that infrastructure component is heavy, slow to provision, and fairly expensive to run. So the monitoring team uses a lightweight network component to provision its infrastructure for developing and testing. The team can even use it in a delivery pipeline that tests changes to its network component in isolation before applying them to environments that other teams rely on.
A useful technique for making infrastructure components composable is to implement interfaces between them at the component level rather than integrating with specific IaaS resources in them. Figure 5-4 illustrates the difference.
The components on the left have a dependency defined at the resource level. The code that defines the load balancer in the consumer component specifically refers to the subnets defined in the provider component, perhaps by knowing how they are named or tagged. This direct dependency between the elements on both sides of the relationship makes changes difficult.
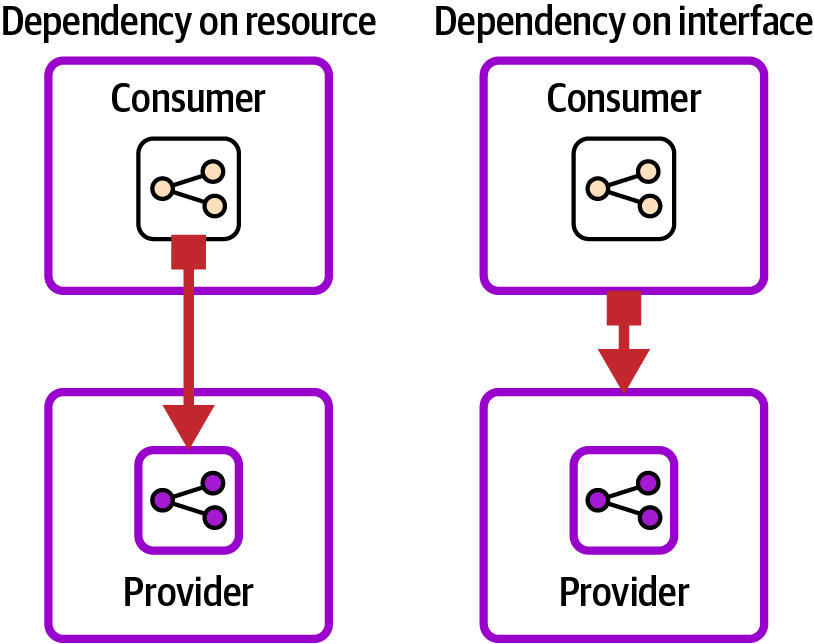
Figure 5-4. Dependency on a resource compared to dependency on an interface
This pseudocode for the provider component defines a subnet group named main_subnet_group:
component:name:shared_network...resource:subnet_groupname:main_subnet_group...
The consumer component specifies the subnet group that its load balancer uses by the same name:
component:name:search_server_cluster...resource:cluster_load_balancersubnet_group:main_subnet_group
If someone needs to restructure the subnets in the provider component and changes the name, they must update the code in this consumer component and in any other consumer components that use it. Finding all the components that depend on the subnets may be difficult, especially with larger and more-complex codebases that involve multiple repositories and teams.
The components on the right in Figure 5-4 have a dependency at the component level. The provider component exports the identifiers of the subnets it creates—for example, by exporting them as outputs stored in a configuration registry, as in this example code:
component:name:shared_network...resource:subnet_groupname:main_subnet_group...stored_values:shared_network/exported_subnets:main_subnet_group
The consumer component can discover the identifiers without knowing the provider component’s implementation details:
component:name:search_server_cluster...resource:cluster_load_balancersubnet_group:stored_values/shared_network/exported_subnets
The subnets in the provider component can be restructured or completely re-implemented, and as long as they expose the resulting identifiers in the same way, consumer components are unaffected. Chapter 9 discusses approaches for implementing interfaces between infrastructure components.
The idea that a consumer component should not depend on implementation details of provider components is called the principle of least knowledge, or the law of Demeter.
Use Testing to Drive Better Design
Chapter 17 and others in this book describe practices for continually testing infrastructure code as people work on changes. This heavy focus on testing makes testability an essential design consideration for infrastructure components.
Each infrastructure component should be developed along with its tests and delivery pipelines (as described in Chapter 16), ensuring that it is fully tested in isolation from other components. Testing a component in isolation forces decoupled implementation. It also strongly encourages components to be kept small, focused, and highly cohesive. Otherwise, the test and delivery process becomes slow and unusable.
Adding automated testing and delivery pipelines to an infrastructure codebase that doesn’t have them already is a large undertaking. The reason for this is that these codebases tend to be over-coupled and messy. Effective, maintainable testing requires effective, maintainable design. This dynamic is why Agile development advocates insist on TDD. It not only is a practice for writing tests but also drives better system design.
Grouping definitions of infrastructure resources into components can make it easier to understand, maintain, and change your system. The effectiveness of a design is influenced by various forces and trade-offs, as I’ll discuss shortly. Specific design forces and trade-offs for infrastructure vary for different parts of the infrastructure code lifecycle.
Design Across Infrastructure Code Lifecycle Stages
The preceding chapter described the lifecycle of infrastructure code, including steps for editing code, building code to assemble a package that can be used for multiple deployments, executing code to create the desired state model for a specific deployment, and applying code through an IaaS API to create the runtime resources. Designing infrastructure code as components has different implications in the different states of the code lifecycle.
The way code is organized in a repository may look different from the way it is packaged and distributed, which can be different from the desired state generated when the code is executed. And in the end, the resulting infrastructure resources provisioned in the IaaS platform may not have an obvious relationship to the way the code was organized during its journey.
Let’s consider how the code at these stages relates to infrastructure design. In each stage, design is focused on supporting certain activities, which means different concerns may come into play, summarized in Table 5-1.
| Lifecycle stage | Activities | Design concerns | Manifestation |
|---|---|---|---|
Source code |
Engineers edit and test infrastructure code. |
Understanding, sharing, collaborating, and changing the code |
Codebase—repositories, folders, and files. |
Package |
Code is made available to deploy to one or more instances of the infrastructure. |
Fast and reliable feedback on the readiness of the code for production use |
Packages, branches, tags, or artifacts. |
Deployment |
The code is executed to generate a desired state model and then applied to provision resources on the IaaS platform. |
Speed and reliability of the deployment |
The desired state model. Engineers rarely interact directly with this model, but it’s represented in memory of the infrastructure tool and affects how long the deployment takes to complete. |
Live resources |
Workloads use the infrastructure. |
Support operability and troubleshooting |
Resources provisioned on the IaaS platform. |
The activities for each stage are discussed in more detail, along with approaches to implementing them, in Part III.
Design Forces
Given that we may need to break an infrastructure project into multiple components, how do we group IaaS resources into components, and where should we define the boundaries between them? Rather than looking for a fixed set of answers, it’s useful to consider the design forces that may apply.
Design forces are constraints, requirements, and influences that guide design decisions. Different design forces may be relevant in each of the stages described in Table 5-1, while some apply across the lifecycle.
Design Forces for Source Code
A few design forces may affect the way a team organizes its infrastructure code across source repositories. I’ll give a brief overview here, although “Organizing Projects in a Codebase” provides more details on how to deal with these forces.
Code ownership
Permissions to view and modify code are set at the repository level, so it’s natural to group code into repositories based on its owners and the people expected to need to edit it. Some source code management systems can be configured to set ownership at the folder level, or even by branches, but these are not as transparent. It’s best to keep code ownership and structure aligned and clear.
Working sets
People who work on infrastructure code tend to have particular sets and subsets of code and components they work on as part of a single change. You may often work on several related infrastructure components and code modules that others use, in which case it’s useful to have all this code together. On the flip side, the wider the scope of code in a repository, the more likely it is that other people are working on different changes in the same repository, which complicates coordination of testing and delivery of changes.
Design Forces for Infrastructure Packaging and Deployment
The effectiveness of the design of infrastructure code components in getting from code to deployment can be measured using the DORA four key metrics (the time, frequency, and failure rate of delivering changes; and the time to recover from failures, as described in “The Four Key Metrics”). Various forces come into play that can create trade-offs for finding the most effective designs for optimizing for these measures and other goals your organization or team may have. Addressing these forces is a major theme throughout this book, influencing component design and the delivery lifecycle.
Management of downtime
Delivering updates and other changes to a set of infrastructure resources impacts the workloads that use those resources, and whatever business or customer processes that those workloads support. A change may require scheduling downtime for the workload, or it may create the risk of unscheduled downtime. In either case, this impact on workloads creates constraints on when infrastructure changes can be applied.
The difficulty of scheduling changes to infrastructure grows (often exponentially) with the number of workloads running on it. More workloads leads to more development teams, more operations teams, and more customer teams that need to agree on a good time to make a change. The difficulty of scheduling infrastructure updates is one of the most common reasons for keeping outdated and unpatched systems software like databases, application servers, and container clusters.
Splitting infrastructure into smaller components that can be delivered independently, and multiple runtime instances that can be upgraded separately, reduces the scope of workloads affected by any given change. Although downtime may still need to be scheduled, it can be scheduled for smaller subsets of the workload.
Workload alignment
Runtime sharing creates deployment dependencies, so sharing a deployable to provision multiple runtime instances can decouple delivery processes. For example, a database upgrade may require the applications that use it to be tested and updated. If multiple applications share a single runtime instance of the database, it can’t be upgraded until all the applications are ready. But if a separate runtime instance can be deployed for each application, each instance can be upgraded as soon as the application is ready.
Compliance
Regulations, whether imposed by government, industry, or internal authorities, often apply to the delivery process. Controls and approvals may be required before changes are made to certain infrastructure, as well as tracking the history of changes for auditing.
However, the scope of these requirements is normally limited to the parts of the system involved with the target of the regulations, such as personal or financial data and transactions. You may be able to deliver changes to other parts of the system, such as those that handle content and design elements of a user interface, with a less rigorous process. Dividing the system into components with different compliance requirements makes it possible to rapidly fix and improve many parts of your system and infrastructure.
Design Forces for Runtime
An infrastructure system’s effectiveness is measured by how well it meets its operational requirements. Typical goals include service delivery, qualities like performance and reliability, and cost of ownership. These lead to design forces that affect decisions about where to split infrastructure into components that can be deployed and run separately.
Scaling
Resources may need to be added and removed as usage levels increase and decrease. Many IaaS resources can scale automatically, especially compute resources like auto-scaling virtual server groups, container clusters, and serverless code runtimes.
However, other elements of your infrastructure, such as databases, message queues, and storage devices, can become bottlenecks when compute scales up. And other parts of your software system may become bottlenecks, even aside from the infrastructure.
For example, the FoodSpin team can deploy multiple instances of its menu browsing service to cope with higher load, because most user traffic hits that part of the system at peak times. The team keeps a single instance of its frontend traffic routing component, and a single instance of the database component that the application server instances connect to, but creates multiple copies of the core compute component when needed.
Other parts of the system, such as the customer management and ordering services, probably don’t need to scale together with the menu browsing service. Splitting the infrastructure for those services into separate components helps the team scale them more quickly. This approach reduces the waste that replicating everything would create.
Geographical distribution
Deploying replicas of services across multiple regions can serve local users more effectively. In some cases, it’s useful to run shared parts of the system in a central location, integrated with multiple distributed replicas. Dividing the relevant infrastructure into separately deployable components can simplify the implementation and reduce costs.
Resilience
The ability to easily rebuild systems from the infrastructure up is one of the headline benefits of Infrastructure as Code. However, different parts of the system have different requirements for recovering from failures, so it can be helpful to design components around these requirements. For example, rebuilding storage resources may require loading data from snapshots or backups. Managing these within a separate component simplifies managing its recovery differently from compute, networking, and other resources that can be rebuilt more simply.
Infrastructure components need to be designed to make it possible to quickly rebuild and recover them. If you organize resources into components based on their lifecycle, you can also take rebuild and recovery use cases into account.
Data regulations
Different types of data within a system are often subject to different requirements. For example, the Payment Card Industry (PCI) security standard imposes requirements on parts of a system that handle credit card numbers. Personal data of customers and employees often needs to be handled with stricter controls. Regulations often require the data and the infrastructure that hosts it to be managed differently from other data in the system. Provisioning separate instances of infrastructure components for handling controlled data simplifies enforcing controls and can help make audits go smoothly.
Data partitioning
Other data may be subject to contractual requirements, such as storing data owned by different customers separately. A major restaurant chain that is a FoodSpin customer requires that its patrons’ data be hosted separately from the data for other FoodSpin customers. The team uses the same infrastructure components to provision separate instances of the patron databases, even while sharing other parts of the infrastructure across the multiple restaurants.
Component lifecycles
Different parts of an infrastructure may have different lifecycles, in terms of how often they need to be updated; actions that need to be taken when creating, updating, or destroying them; and even how long it takes to provision or update them.
For example, the FoodSpin team has a “service runtime stack” infrastructure component that includes a pool of virtual servers, load balancing for traffic to the servers, and a database instance. Whenever the infrastructure component is changed, such as to patch the servers, the database needs to be backed up in case a problem occurs that requires destroying and rebuilding the infrastructure component.5 The team decides to split the database infrastructure into a separate component, which means that updates to other parts of the infrastructure don’t trigger unnecessary updates and restores of the data, saving time and hosting costs.
Over time, the team finds that rebuilding the load-balancer rules takes much longer than rebuilding other parts of the service’s infrastructure. To save running costs (as per the hosting cost design force), the team automatically destroys development and test environments when they’re not being actively used. However, when environments are used as part of a delivery pipeline, the development teams want to see fast test results. The lag waiting for the load-balancer rule to be created takes up more than half of the entire time of the test stage it supports. So the team splits the load-balancer rule into a separate infrastructure component and leaves it running. The company still saves money by destroying the compute resources, but the feedback loop for automated test stages is much faster.
Hosting and environmental costs
Minimizing hosting costs and carbon emissions can drive design decisions about how to organize resources into components. When some parts of the infrastructure need to be replicated, such as with the scaling and distribution design forces described previously, costs can be reduced by arranging resources across components to avoid replicating those that don’t need it. For example, you may need to provision multiple container clusters across regions, but not a database cluster that all the applications use. Splitting these into separate components means you avoid running extra copies of the database.
Most cloud vendors charge different costs based on the hosting location, and different hosting locations have different carbon footprints.6 So cost and environmental impact can sometimes be optimized by managing the locations where different parts of the system are run.
Runtime influence on other stages
Design decisions driven by runtime forces may come into play for components only at the runtime stage, or they may affect the design of components for deployment and sometimes even code. For example, the need to host data for multiple customers in separate databases can be satisfied by reusing a single infrastructure component to provision multiple instances of the infrastructure. There is no need to build or deliver the infrastructure code differently for each instance.
However, some of these runtime forces may drive design decisions that lead to separate infrastructure code components. The solution for storing credit card data might have infrastructure requirements that are different enough from the solution for storing customer data that defining two different infrastructure components makes more sense.
Design Forces Across Lifecycle Stages
The design forces I’ve described apply mainly in separate stages. However, most component boundaries apply across these contexts, so design decisions aren’t made in isolation. Several design forces are best viewed through a cross-lifecycle lens.
Cognitive size
A component becomes more unwieldy as it grows in size. It has more code that is more complex to get your head around as you work on it,7 making it easier to make mistakes and more difficult to debug and fix. Larger infrastructure components take more time to test and debug. Provisioning or updating a larger component is slower, creating longer feedback loops for the end-to-end delivery process. The blast radius when applying a larger infrastructure component is wider, increasing the likelihood and impact of failures.
The time needed to coordinate and manage changes to an infrastructure component grows nonlinearly with the number of resources it includes.
Smaller components have fewer moving parts and a smaller surface area. They are easier to test and deliver, following the Unix philosophy of “do one thing and do it well.” The trade-off of breaking a large component into smaller ones is that it shifts complexity into managing their relationships. Each component might be well designed and thoroughly tested, but good testing is needed to make sure an integrated collection of components work well together.
Building infrastructure from loosely coupled components is a fundamental tenet of this book, so we cover quite a few aspects of managing this well, including choosing design patterns for sizing infrastructure components (Chapter 7), testing infrastructure at various levels of abstraction (Chapter 17), decoupling delivery of integrated components (Chapter 16), and standardizing approaches to integrating components at runtime (Chapter 9).
Change scope
The more components that need to be modified to implement a change, the more complex and risky the change is. You may need to make changes to various parts of the codebase, test and deliver changes to multiple components, and then coordinate the impact on production systems. Eliminating the need to modify multiple components isn’t realistic, running up against the challenges of having components that are too large. But with a certain amount of analysis and effort, you may be able to reduce how often you need to do it and work out ways to make the changes that do happen often easier to manage.
With an existing system, you may learn about which elements typically change together by examining historical changes. Finer-grained changes, like code commits, give the most useful insight. The most effective teams optimize for frequent commits, fully integrating and testing each one. By understanding which components tend to change together as part of a single commit, or closely related commits across components, you can find patterns that suggest how to refactor your code for more cohesion and less coupling.
Examining higher levels of work, such as tickets, stories, or projects, can help you understand which parts of the system are often involved in a set of changes. But you should optimize for small, frequent changes. Be sure to drill down to understand any changes that can be made independently, to enable incremental changes within the context of larger change initiatives.
Organizational structure
Even for changes that can’t be limited to the resources in a single infrastructure component, it may be possible to limit the scope of changes to components owned by a single team. Aligning changes with team structure implies aligning designs to team structures as well.
Conway’s law says that systems tend to reflect the structure of the organization that creates it.8 One team usually finds it easier to integrate software and infrastructure that it owns wholly, and the team will naturally create harder boundaries with parts of the system owned by other teams.
Conway’s law has two general implications for designing systems that include infrastructure. One is to avoid designing components that multiple teams need to make changes to. The other is to consider using the inverse Conway maneuver, structuring teams to reflect the architectural boundaries you want.
Cost of ownership
Variation across your system affects the time and effort needed to maintain and support it. Obvious variations include the number of system software solutions you run (container cluster packages, database products, and types of OSs, for example). Componentizing your infrastructure effectively can not only reduce the amount of custom infrastructure code you maintain and test but can also simplify work by reducing the number of types of infrastructure you deploy and run. Delivering routine patches and updates across all environments is easier when it involves changing fewer components and therefore less code. It’s also easier when component instances are smaller and loosely coupled, so that each instance can be changed on its own schedule.
Security
The topic of designing secure cloud infrastructure is much broader than the scope of this book. However, it’s useful to consider the relationship of infrastructure components and their context to security. Assumptions, mindsets, and “best practices” that apply to data center infrastructure can become pitfalls when applied without considering the differences between infrastructure code and provisioned infrastructure resources.
Attackers may attack a system from various avenues, each of which drives implementation decisions in different areas. The traditional focus of infrastructure security design is attacks that come over the network. Infrastructure is grouped into network segments, starting with public segments and demilitarized zones (DMZs) on the perimeter, and separate segments for resources used for concerns like business processes, data storage, and operational management.
While we still group cloud resources into defensive layers to protect against network-based attacks, they aren’t necessarily useful as boundaries for infrastructure code components. IaaS platforms create an entirely different attack vector based on authorization to use the IaaS API to manipulate resources. Separating infrastructure code for different network segments doesn’t force an attacker to break through multiple layers of defense. They only need to gain permission to use the IaaS API, at which point they can interfere directly with any part of the system.
Design strategies to protect against attackers exploiting the IaaS API focus on separating infrastructure deployment into separate IaaS accounts, with separate permissions. Attention is paid to which service and resources are managed within each of these groups, and the risks of compromise to each. For example, many teams host monitoring systems in a separate IaaS account from an account with the main workload. An attacker who compromises the main workload account doesn’t gain access to the monitoring systems, which reduces the risk that they will stop alerts from being raised. Conversely, the account that hosts the alerting systems can be designed so that someone who gains access doesn’t gain access to the main workload account.
Lightweight Governance
Modern digital organizations are learning the value of lightweight governance in IT to balance autonomy and centralized control. This is a key element of the EDGE model for Agile organizations. For more on this, see EDGE: Value-Driven Digital Transformation by Jim Highsmith et al. (Addison-Wesley), or Jonny LeRoy’s talk, “The Goldilocks Zone of Lightweight Architectural Governance”. I also recommend Andrew Harmel-Law’s article “Scaling the Practice of Architecture, Conversationally”, and Facilitating Software Architecture (O’Reilly).
Conclusion
This chapter discussed guiding principles for designing Infrastructure as Code. These included applying concepts like cohesion and coupling to infrastructure, considering the CUPID design properties, and understanding design forces that apply in various infrastructure code lifecycle stages. All this sets the scene for the next chapter, which defines types of infrastructure components to consider using in your system designs. These components can be used at multiple levels of abstraction and in different stages of the infrastructure code lifecycle.
1 The idea that buildings and other structures don’t change after they’re built isn’t accurate. How Buildings Learn by Stewart Brand (Viking Press) gives many examples of how people adapt buildings over their lifetime. This book gave me an appreciation that, when designing anything, we should consider the need to change it in unexpected ways later.
2 See the Unix philosophy entry on Wikipedia.
3 See the C2 wiki’s definition of coupling and cohesion.
4 This should be one of Murphy’s laws.
5 In an ideal world, you wouldn’t need to destroy and rebuild all the infrastructure in a component like a Terraform project or CloudFormation stack. In the real world, this happens all too often.
6 See the Cloud Carbon Footprint project for information and open source tools to help optimize the carbon footprint of your infrastructure.
7 James Lewis, who defined the microservices architectural style, wrote in his post “How Big Should a Micro-service Be?” that the right size of a component at any given level of abstraction is no bigger than what you can fit into your head.
8 The complete definition is “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”