Infrastructure Deployment Stacks
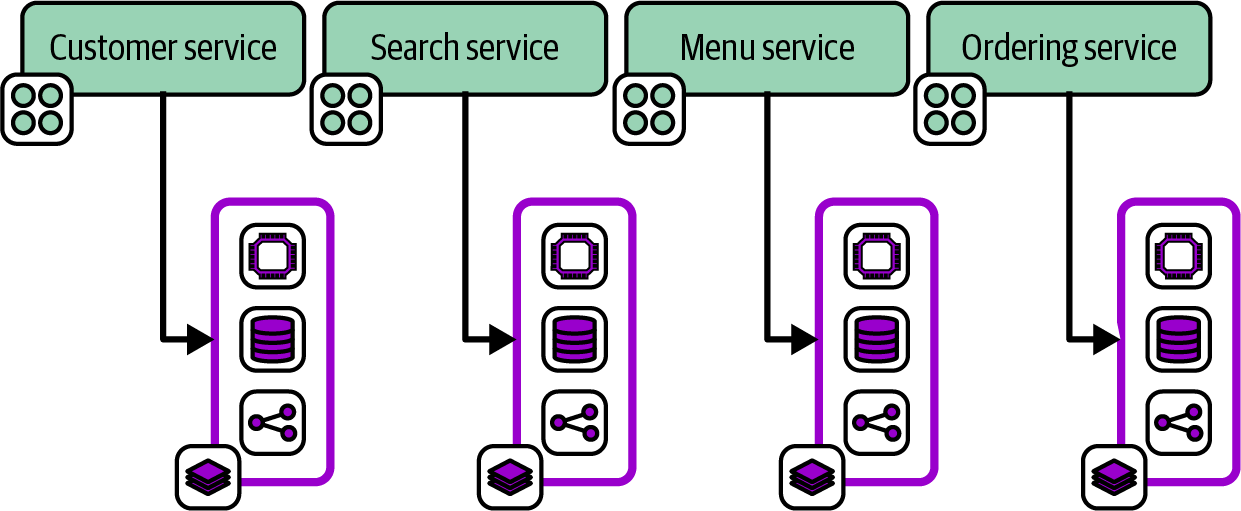
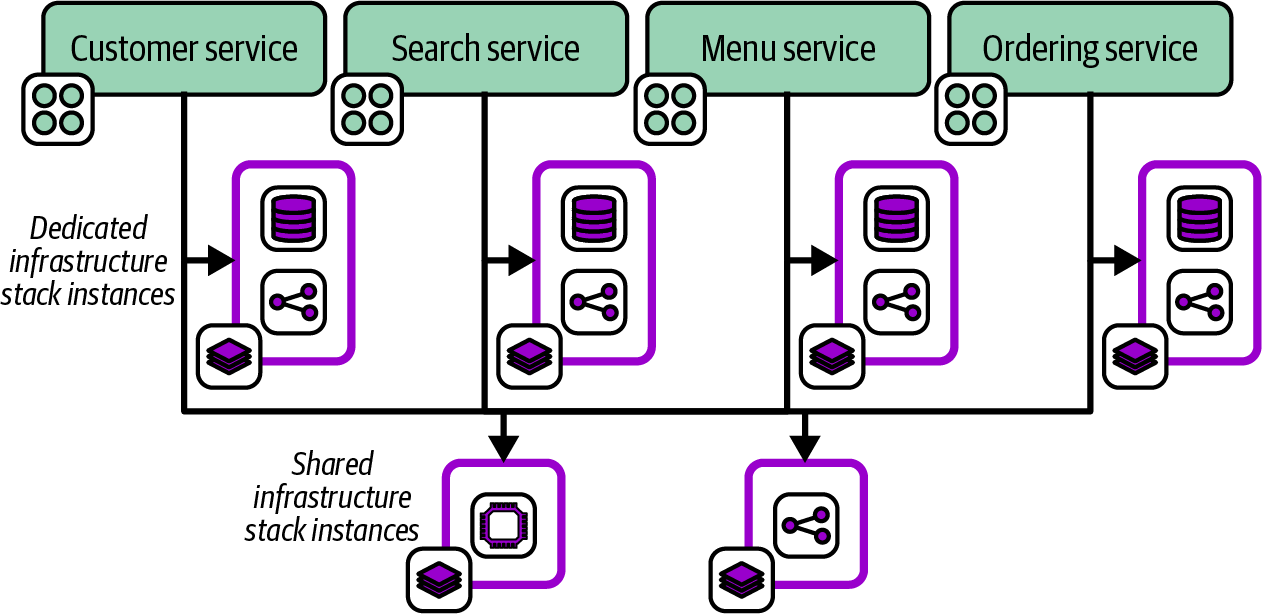
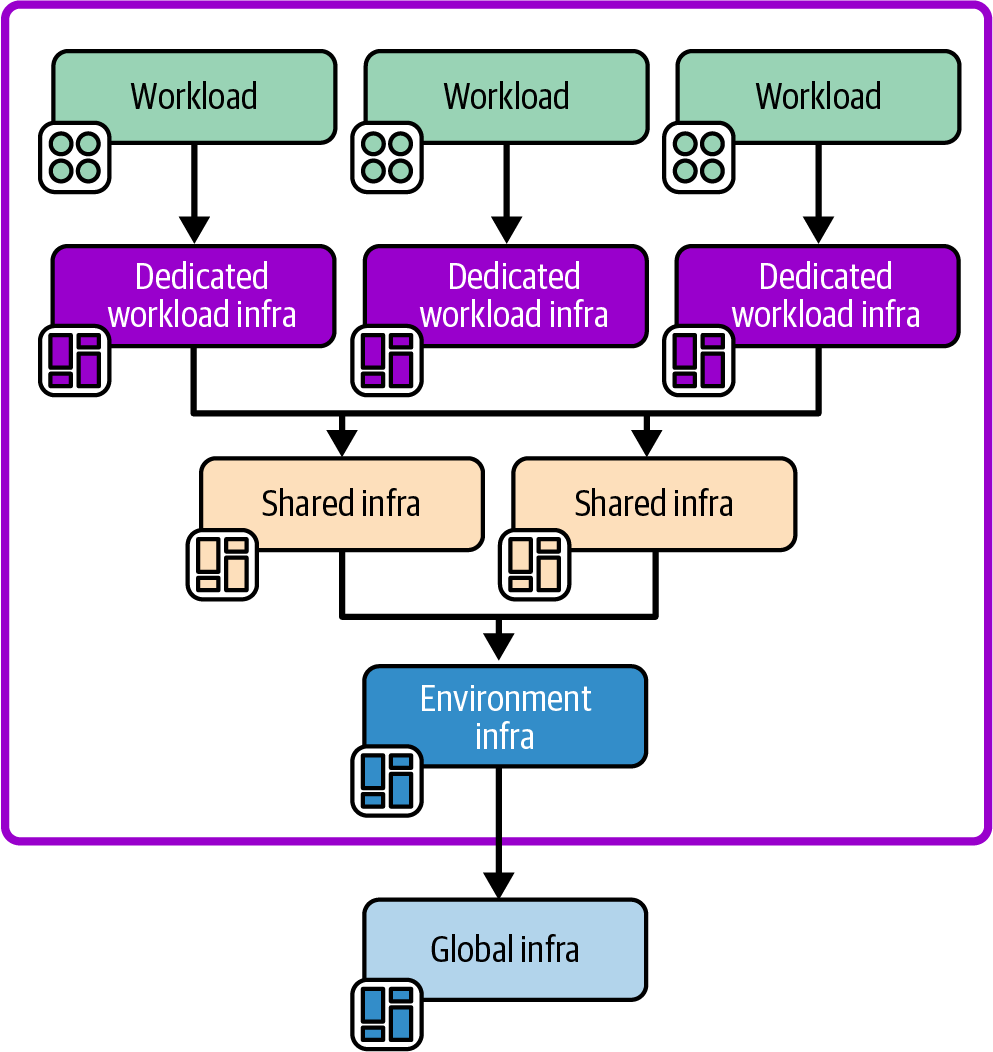
An infrastructure deployment stack, or just stack, is a collection of IaaS resources defined, created, and modified as an independent, complete unit. In the terminology defined by the authors of Building Evolutionary Architectures, an infrastructure deployment stack is an architectural quantum, “an independently deployable component with high functional cohesion.” As with software deployment architecture, decisions around how large stacks should be and how to group resources within them have a big impact on how easy it is to deliver, update, and manage a system.
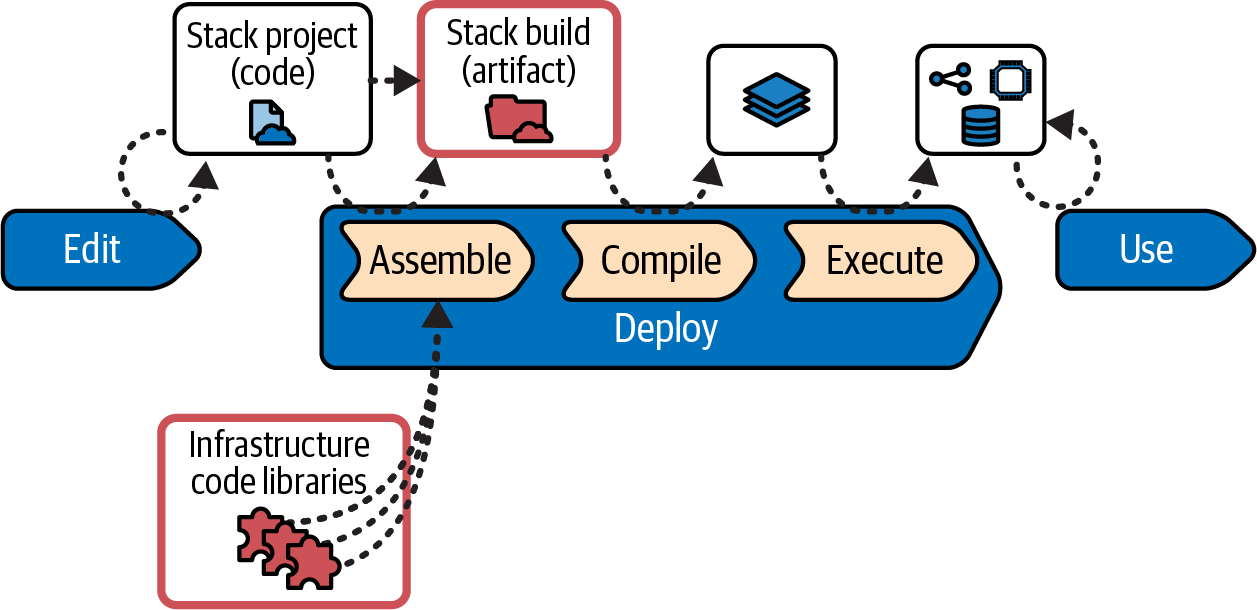
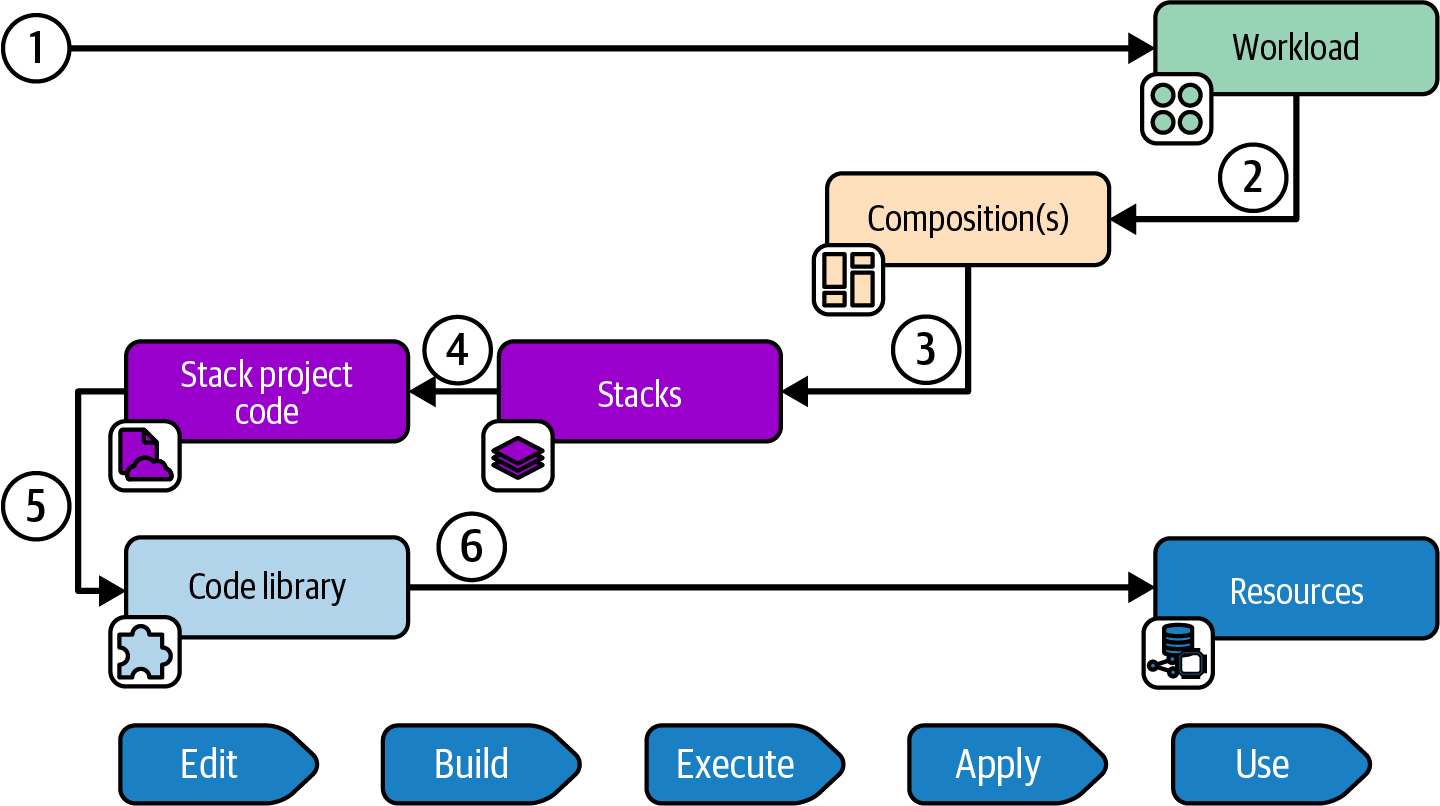
Figure 6-4 shows the progress of an infrastructure stack in the infrastructure code processing model described in “Infrastructure Code Processing”.
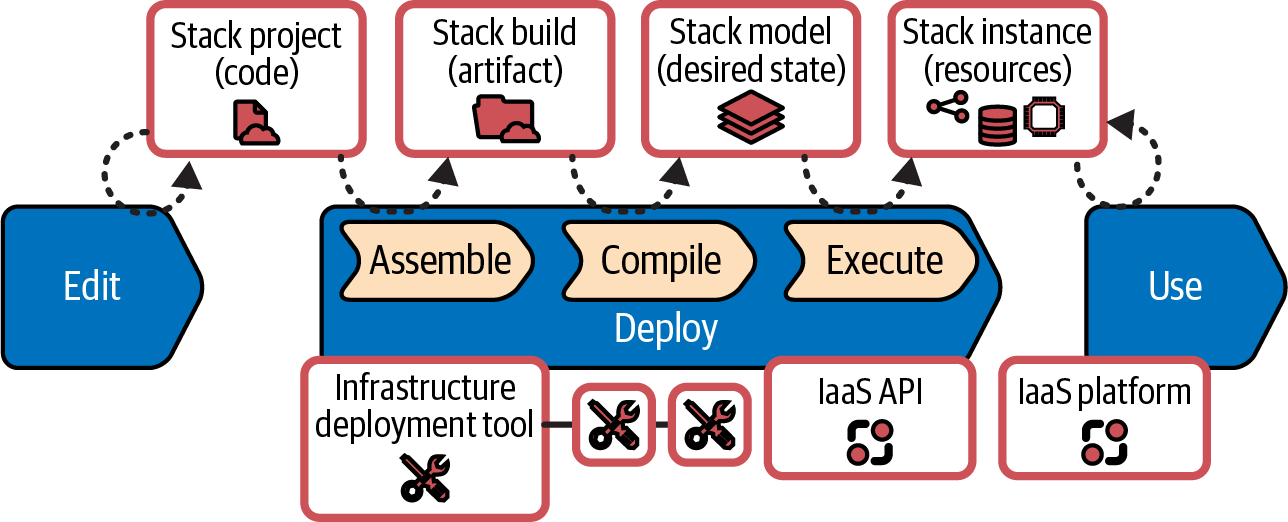
Figure 6-4. Stacks in the infrastructure code processing model
The stack project contains the code that specifies the resources in the stack. In the Assemble substep, the stack tool (probably one of the stack-oriented infrastructure tools listed in “Infrastructure as Code Tools” such as Terraform, Pulumi, or CDK) creates the stack build, importing libraries and other elements. Depending on how the infrastructure tool works and the delivery workflow used by the team, the stack artifact could be files generated in a working directory, a branch or tag in source control, or an archive like a ZIP file stored in a repository.
The stack tool compiles the code build, along with any instance-specific information like configuration parameters, to create the stack model, the desired state for the infrastructure resources. The tool then executes the stack model by calling the IaaS API to create, modify, or destroy resources to make the infrastructure stack instance match the desired state. The stack instance is the live infrastructure available for use by workloads. See “Build Stage: Preparing for Distribution” for workflow approaches to building and deploying stacks.
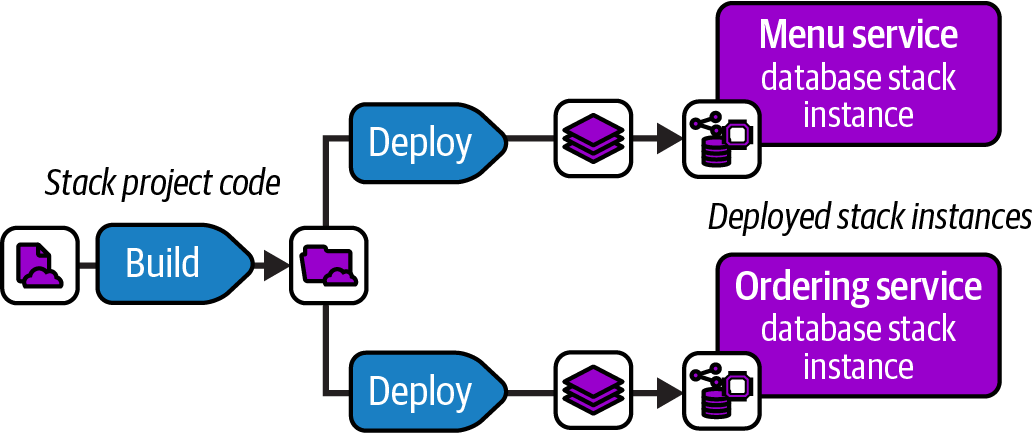
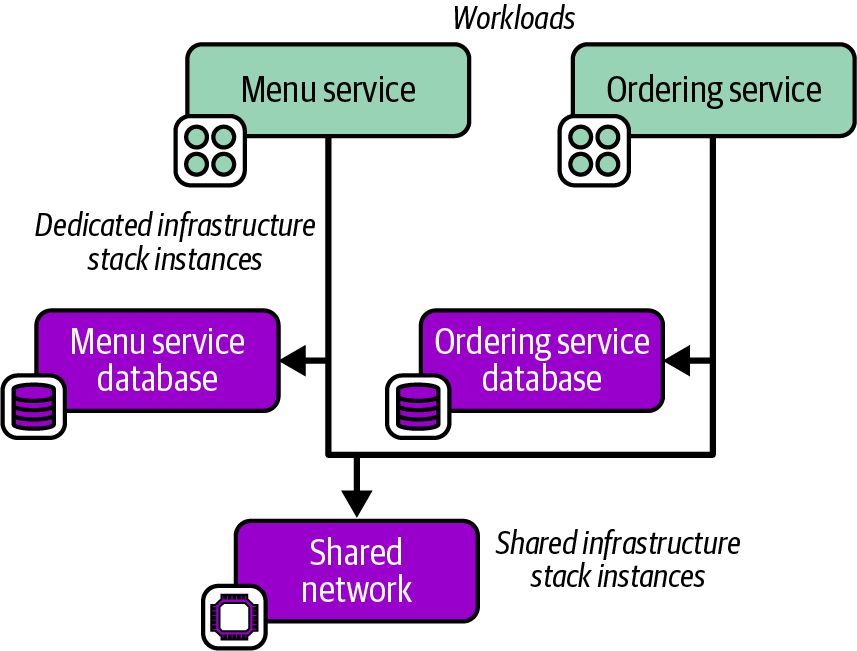
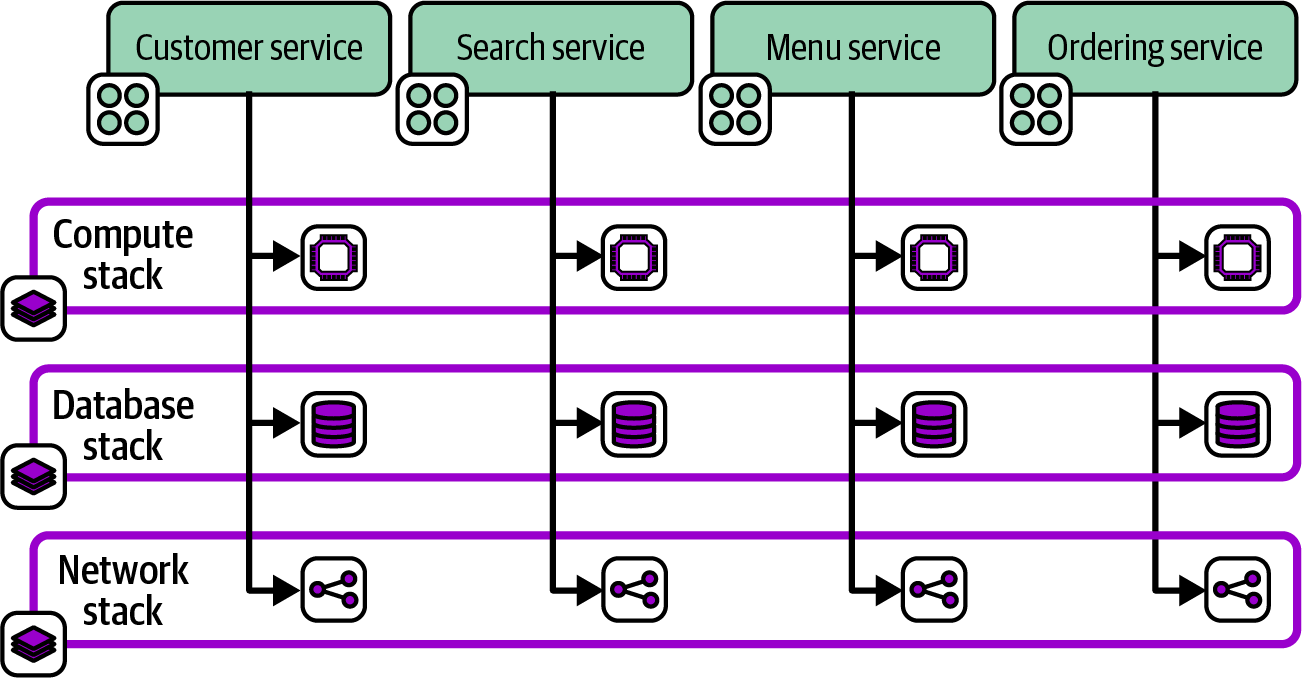
Chapter 7 describes design patterns for stacks. “Reusable Stack” defines one of these patterns, in which a single infrastructure stack project may be reused to deploy multiple stack instances. Chapter 8 then describes patterns for configuring stack instances when deploying them.
“Stack” as a Term
Not all infrastructure tools use the term “stack” to describe a deployable unit of resources. CloudFormation and Pulumi both use the term this way, but HashiCorp has much more recently introduced a composition feature that, confusingly, is named “stack.”
Terraform calls a separately deployable unit within a stack a “component.” Outside of a Terraform stack (composition), HashiCorp doesn’t have a separate term for the concept, although you sometimes see the terms “project,” “configuration,” or “workspace” used in a related way.
In this book, I describe patterns and practices that should be relevant to any tool. The concept of a deployable infrastructure component is one of the most common concepts in the book. Because “deployable infrastructure component” is too awkward, I have been using the word stack for this concept since the first edition of this book in 2016. It is the most widely used term for this in the industry, even if it isn’t universal.
I hope that readers will be able to map the patterns and practices described for stacks in this book to whatever tool they use. When I refer to Terraform’s stack feature, I will generally say “Terraform stack (composition).” Otherwise, when I use the term “stack” by itself, it follows my definition.