5 | The Four Fundamental Team Topologies |
The architecture of the system gets cemented in the forms of the teams that develop it.
—Ruth Malan, “Conway’s Law”
In many organizations, there is a variety of team types and there are even teams taking on multiple roles (e.g., an infrastructure and tooling team). This sprawl makes it hard for everyone to visualize the full organizational landscape: Do we have the right teams in place? Are we lacking capabilities in some areas that are not being addressed by any team? Does it look like teams have the necessary balance between autonomy and support by other teams?
Answering these questions becomes simpler if we reduce the number of team variations to four fundamental team topologies:
When used with care, these are the only four team topologies needed to build and run modern software systems. When combined with effective software boundaries (as presented in Chapter 6) and team interactions (as presented in Chapter 7), the restriction of these four team types acts as a powerful template for effective organization design (see Figure 5.1 on page 80).
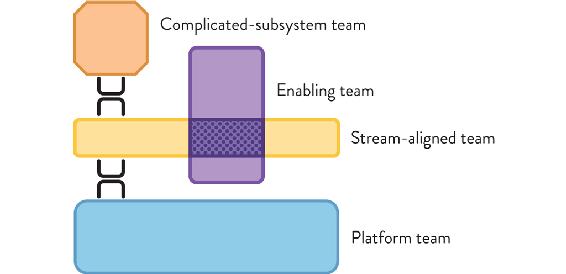
Figure 5.1: The Four Fundamental Team Topologies
The four fundamental team topologies—stream aligned, enabling, complicated subsystem, and platform—should act as “magnets” for all team types. All teams should move toward one of these four magnetic poles; that is, we should prefer these types, and aim to adopt the purpose, role, responsibility, and interaction behavior of these fundamental types for every team in our organization. Simplifying the types of teams to just these four helps to reduce ambiguity within the organization. As was identified by Jiao Luo and colleagues in research published in 2018, reduced ambiguity around organizational roles is a key part of success in modern organization design.1
A large or mid-sized organization is likely to have one or more teams of each fundamental topology; multiple stream-aligned teams are the starting point (as we will see in this chapter), but an organization may also have several platform teams, a few enabling teams for different purposes (perhaps one addressing CI/CD and a second addressing infrastructure or architecture), and, if strictly necessary, one or two complicated-subsystem teams.
NOTE
Where is the Ops team? Where is the support team?
There is no “Ops” team or “support” team in the fundamental topologies, and this is deliberate. The long-lived teams building the systems are very close to the live operation of the systems they are building. There is no “handover” to a separate Ops or support team; even with the SRE pattern (see Chapter 4), the teams are closely aligned. Stream-aligned teams follow good software-delivery practices (like continuous delivery and operability), and they are responsible for live operation, even if very little code is being written. In effect, Ops and support are largely aligned to streams. (We will go into how successful organizations manage support activities in the context of rapid, safe flow of change later in this chapter.)
Now let’s go into more detail on each of the four fundamental team topologies.
Stream-Aligned Teams
A “stream” is the continuous flow of work aligned to a business domain or organizational capability. Continuous flow requires clarity of purpose and responsibility so that multiple teams can coexist, each with their own flow of work.
A stream-aligned team is a team aligned to a single, valuable stream of work; this might be a single product or service, a single set of features, a single user journey, or a single user persona. Further, the team is empowered to build and deliver customer or user value as quickly, safely, and independently as possible, without requiring hand-offs to other teams to perform parts of the work.
The stream-aligned team is the primary team type in an organization, and the purpose of the other fundamental team topologies is to reduce the burden on the stream-aligned teams. As we see later in this chapter, the mission of an enabling team, for instance, is to help stream-aligned teams acquire missing capabilities, taking on the effort of research and trials, and setting up successful practices. The mission of a platform team is to reduce the cognitive load of stream-aligned teams by off-loading lower level detailed knowledge (e.g., provisioning, monitoring, or deployment), providing easy-to-consume services around them.
Because a stream-aligned team works on the full spectrum of delivery, they are, by necessity, closer to the customer and able to quickly incorporate feedback from customers while monitoring their software in production. Such a team can react to system problems in near real-time, steering the work as needed. In the words of Don Reinertsen: “In product development, we can change direction more quickly when we have a small team of highly skilled people instead of a large team.”2
Different streams can coexist in an organization: specific customer streams, business-area streams, geography streams, product streams, user-persona streams, or even compliance streams (in highly regulated industries). (See Chapter 6 for details on how to organize work along these different types of streams.) A stream can even take the form of a micro-enterprise within a large firm, with an independent focus and purpose (e.g., innovating on products that do not exist yet). Whichever kind of stream of changes a stream-aligned team is aligned to, that team is funded in a long-term, sustainable manner as part of a portfolio or program of work, not as a fleeting project.
In a modern software organization, we expect most teams to be stream aligned. The flow of work is clear, and each stream has a steady, expectable flow of work for the stream-aligned team to prioritize.
This stands in stark contrast to traditional work allocation, whereby either a large request by a single customer or a set of smaller requests by multiple customers get translated into a project. Once the project is approved and funded, several teams will potentially get involved (e.g., front-end, back-end, and DBA teams) and be required to fit the new work into their existing backlog.
CASE STUDY: STRICTLY INDEPENDENT SERVICE TEAMS AT AMAZON
As far back as 2002, Amazon adopted a team topology that used highly independent teams. This was a deliberate mandate from CEO Jeff Bezos to ensure that each service or application in the Amazon estate was truly independent—acknowledging Conway’s law—and ensured that the teams would be independent as well.3 Amazon is also known for limiting the size of its software teams to those that can be fed by two pizzas, in order to increase accountability and maximize speed of delivery and discovery.4
Around 2002, Jeff Bezos’ sent a mandate to the Amazon engineering division that set out very specific rules for team organization:5
In line with the principle “you build it, you run it” popularized by Werner Vogels, CTO of Amazon, “service teams” (as they’re called internally) must be cross-functional and include all the required capabilities to manage, specify, design, develop, test, and operate their services (including infrastructure provisioning and client support). These capabilities are not necessarily mapped to individuals; the team as a whole must provide them. Each individual has a primary area of expertise, but their contributions are not limited to it.
There is very little coordination required between service teams, leading to a highly distributed and heterogeneous stack of microservices. Interestingly, there is an exception for testing, as software development engineers in testing (SDETs) work across the whole organization, looking to promote good testing practices and tools across teams (but each team has the day-to-day testing role embedded). They also ensure a smooth cross-service, cross-device, cross-geography user experience. The SDET role provides the kind of valuable input provided by people in a productivity or tooling team, facilitating and encouraging good practices across teams.
The Amazon two-pizza-team model is an example of stream-aligned teams: the teams are substantially independent, have ownership over their services, and have responsibility for the runtime success of the software they write. The fact that Amazon has been using this model for over seventeen years shows how effective it can be to align teams to independent streams of change.
Capabilities within a Stream-Aligned Team
Generally speaking, each stream-aligned team will require a set of capabilities in order to progress work from its initial (requirements) exploration stages to production. These capabilities include (but are not restricted to):
It’s critical not to assume each capability maps to an individual role in the team; that would mean teams would have to include at least nine members to match the list above. Instead, we’re talking about being able, as a team, to understand and act upon the above capabilities. This might mean having a mix of generalists and a few specialists. Having only specialized roles would lead to a bottleneck every time a piece of work depended on a specialist who might be currently busy.
NOTE
Site Reliability Engineering (SRE) teams, pioneered by Google, are really a special kind of stream-aligned team in the sense that they are responsible for the reliability of large-scale applications running in production. SRE teams interact primarily with one or more stream-aligned teams responsible for developing applications, and the flow of software change is very much aligned to a stream.
Why Stream-Aligned Team, Not “Product” or “Feature” Team?
In the past, many software-delivery frameworks used the terms “product team” or “feature team” to refer to teams with a remit to deliver valuable end-to-end software increments, but these days there are many reasons why talking about streams makes more sense than talking about products or features. Aligning a team’s purpose with a stream helps to reinforce a focus on flow at the organization level—a stream should flow unimpeded.
With the advent of IoT, embedded devices everywhere, and holistic approaches to service management, the end-to-end user experience looks different. Customers interact not just with a discrete piece of software but with a range of products and devices that all run different kinds of software, from mobile to embedded to voice-led controls. Customers also interact with brands via multiple channels (in person, social media, website, phone), expecting consistent responses and interfaces. In the book Designing Delivery, Jeff Sussna talks about the need for teams to include “continuous design” capabilities to meet these challenges: with continuous design we “treat ideas such as service, feedback, failure, and learning as first-class concepts,” and the best way to enable this is with a stream-oriented view of change with an emphasis on flow.6
In this multi-channel, highly connected context, a “product” can mean very different things, making it hard to understand what the responsibilities of a “product team” are. For instance, in manufacturing companies, the product might be a fixed-life physical device built by an engineering team for a number of years and then disbanded as the product is superseded.
Not only is the term “stream aligned” more suited to a wider range of situations than either “product” of “feature,” but “stream aligned” also incorporates and helps to emphasize a sense of flow (because a stream flows). Finally, not all software situations need products or features (especially those focused on providing public services), but all software situations benefit from alignment to flow.
Expected Behaviors
As we’ve seen, the mission of stream-aligned teams is to ensure the smooth flow of work for a given stream, often related to a business domain area but not always.
What kind of behaviors and outcomes do we expect to see in an effective stream-aligned team?
(We will provide a more detailed view of how stream-aligned teams relate to the platform in Chapter 8.)
Enabling Teams
In the book Accelerate, Forsgren, Humble, and Kim tell us that high-performing teams are continuously improving their capabilities in order to stay ahead. But how can a stream-aligned team with end-to-end ownership find the space for researching, reading about, learning, and practicing new skills? Stream-aligned teams are also under constant pressure to deliver and respond to change quickly.
An enabling team is composed of specialists in a given technical (or product) domain, and they help bridge this capability gap. Such teams cross-cut to the stream-aligned teams and have the required bandwidth to research, try out options, and make informed suggestions on adequate tooling, practices, frameworks, and any of the ecosystem choices around the application stack. This allows the stream-aligned team the time to acquire and evolve capabilities without having to invest the associated effort (in our experience, such efforts and their impact on the rest of the team also tend to be dramatically underestimated by ten to fifteenfold).
Enabling teams have a strongly collaborative nature; they thrive to understand the problems and shortcomings of stream-aligned teams in order to provide effective guidance. Jutta Eckstein calls them “Technical Consulting Teams,”8 a definition that maps well to what we’d expect a consulting team to provide (guidance, not execution), whether internal or external to the organization.
Enabling teams actively avoid becoming “ivory towers” of knowledge, dictating technical choices for other teams to follow, while helping teams to understand and comply with organization-wide technology constraints. This is akin to the idea of “servant leadership” but applied to team interactions rather than individuals. The end goal of an enabling team is to increase the autonomy of stream-aligned teams by growing their capabilities with a focus on their problems first, not the solutions per se. If an enabling team does its job well, the team that it is helping should no longer need the help from the enabling team after a few weeks or months; there should not be a permanent dependency on an enabling team.
TIP
Use these heuristics from Robert Greenleaf to guide the behavior and drive of the enabling team: “Do those served grow as persons? Do they, while being served, become healthier, wiser, freer, more autonomous?”9
A single enabling team might map to any of the stream-aligned team capabilities we listed in the previous section (user experience, architecture, testing, and so on), but often they are focused on more specific areas, such as build engineering, continuous delivery, deployments, or test automation for particular client technology (e.g., desktop, mobile, web). For example, the enabling team might set up a walking skeleton of a deployment pipeline or a basic test framework combining automation tools and some initial scenarios and examples.
Knowledge transfer between an enabling and a stream-aligned team can take shape on a temporary basis (when a stream-aligned team adopts a new technology, like containerization, for instance) or on a long-term basis (for continuously improving aspects, such as faster builds or faster test execution). Pairing can be quite effective for some types of practices, such as defining Infrastructure-as-Code.
Expected Behaviors
As we’ve seen, the mission of enabling teams is to help stream-aligned teams acquire missing capabilities, usually around a specific technical or product management area.
What kind of behaviors and outcomes do we expect to see in an effective enabling team?
CASE STUDY: ENGINEERING ENABLEMENT TEAM WITHIN A LARGE LEGAL ORGANIZATION
Robin Weston, Engineering Leader, BCG Digital Ventures
In 2017, I led a year-long consulting engagement with a newly-formed engineering enablement team within a large legal organization. The organization’s software development capability was spread among multiple global teams.
The engineering enablement team was formed in response to a number of painful symptoms being felt throughout the organization, such as including long feature lead times, coupled release cycles for separate systems, low team morale, siloed technical knowledge, and (most fundamentally) the organization losing ground to competitors due to the inability to keep up an innovative pace of change.
The enablement team consisted of a number of people with strong skills and awareness across software engineering disciplines (application development, build and release, testing, etc.). Crucially, rather than just bringing in new technology and tools, we focused on sharing good practices and educating teams. Introducing new build and deployment tooling without tackling the underlying culture and development teams’ skills can actually do more harm than good. We devised and published a “team charter” that we committed to and shared openly throughout the organization:
Our high-level goal is to enable teams to deliver features faster and with higher quality. We have an initial eight weeks to improve the following metrics:
Trying to fix engineering issues by mandating them from above is doomed to failure, as you really need buy-in from the folks working at the coalface. The enablement team itself was intentionally formed from a mix of external consultants and developers taken from the existing teams. To help launch the team and its mission, we ran an organization-wide workshop, inviting representatives from all global development teams.
I felt strongly that an engineering enablement team should plan for its own extinction from the very first day to avoid other teams becoming dependent. We broadcasted all the work that we were doing with the aim that all other teams would become self-sufficient. To this end, we ran mob programming sessions, recorded demos, and invited every team to our showcases. We estimated that a quarter of our team’s time was spent actually implementing solutions; the rest was sharing knowledge.
After the first eight weeks, we saw the following results from our key metrics:
Although the absolute numbers themselves weren’t that impressive, the fact that we could demonstrate clear progress was a great confidence boost and gave us the trust within the organization to push for more wide-reaching changes to attack other pain points.
The primary purpose of an enabling team is to help stream-aligned teams deliver working software in a sustainable, responsible way. Enabling teams do not exist to fix problems that arise from poor practices, poor prioritization choices, or poor code quality within stream-aligned teams. Stream-aligned teams should expect to work with enabling teams only for short periods of time (weeks or months) in order to increase their capabilities around a new technology, concept, or approach. After the new skills and understanding have been embedded in the stream-aligned team, the enabling team will stop daily interaction with the stream-aligned team, switching their focus to a different team.
Enabling Team versus Communities of Practice (CoP)
Both enabling teams and communities of practice (CoP) can help to increase awareness and capabilities within other teams. The members of an enabling team work on enabling activities full-time, whereas a CoP is a more diffuse grouping of interested individuals from across several teams, with an aim to share practices and improve working methods on a weekly (or monthly) basis. In her book Building Successful Communities of Practice, Emily Webber says “Communities of practice create the right environment for social learning, experiential learning, and a rounded curriculum, leading to accelerated learning for members.”11
Enabling teams and CoP can co-exist because they have slightly different purposes and dynamics: an enabling team is a small, long-lived group of specialists focused on building awareness and capability for a single team (or a small number of teams) at any one point in time, whereas a CoP usually seeks to have more widespread effects, diffusing knowledge across many teams. Of course, several enabling teams can also have their own “enabling-teams community of practice!”
Complicated-Subsystem Teams
A complicated-subsystem team is responsible for building and maintaining a part of the system that depends heavily on specialist knowledge, to the extent that most team members must be specialists in that area of knowledge in order to understand and make changes to the subsystem.
The goal of this team is to reduce the cognitive load of stream-aligned teams working on systems that include or use the complicated subsystem. The team handles the subsystem complexity via specific capabilities and expertise that are typically hard to find or grow. We can’t expect to embed the necessary specialists in all the stream-aligned teams that make use of the subsystem; it would not be feasible, cost-effective, or in line with the stream-aligned team’s goals.
Examples of complicated subsystems might include a video processing codec, a mathematical model, a real-time trade reconciliation algorithm, a transaction reporting system for financial services, or a face-recognition engine.
The critical difference between a traditional component team (created when a subsystem is identified as being or expected to be shared by multiple systems) and a complicated-subsystem team is that the complicated-subsystem team is created only when a subsystem needs mostly specialized knowledge. The decision is driven by team cognitive load, not by a perceived opportunity to share the component.
Consequently, we expect to have only a few complicated-subsystem teams in a Team Topologies–driven organization when compared to the number of component teams in a traditional structure. (Later in this chapter, we’ll look at how to map traditional component teams to one of the fundamental topologies supporting stream-aligned teams.)
Expected Behaviors
As we’ve seen, the mission of complicated-subsystem teams is to off-load work from stream-aligned teams on particularly complicated subsystems that need to be developed by a group of specialists.
What kind of behaviors and outcomes do we expect to see in an effective complicated-subsystem team?
Platform Teams
The purpose of a platform team is to enable stream-aligned teams to deliver work with substantial autonomy. The stream-aligned team maintains full ownership of building, running, and fixing their application in production. The platform team provides internal services to reduce the cognitive load that would be required from stream-aligned teams to develop these underlying services.
This definition of “platform” is aligned with Evan Bottcher’s definition of a digital platform:
A digital platform is a foundation of self-service APIs, tools, services, knowledge and support which are arranged as a compelling internal product. Autonomous delivery teams can make use of the platform to deliver product features at a higher pace, with reduced coordination.12
This approach has been successfully adopted in many internet-era organizations. The platform team’s knowledge is best made available via self-service capabilities via a web portal and/or programmable API (as opposed to lengthy instruction manuals) that the stream-aligned teams can easily consume. “Ease of use” is fundamental for platform adoption and reflects the fact that platform teams must treat the services they offer as products that are reliable, usable, and fit for purpose, regardless of if they are consumed by internal or external customers. Jutta Eckstein has a suitable recommendation: “Technical-service teams should always regard themselves as pure service providers for the domain teams.”13
Peter Neumark, former platform engineer at Prezi, stresses the need for alignment of purpose between the platform team and the stream-aligned teams they support: “A platform team’s value can be measured by the value of the services they provide to product teams.”14
In practice, platform teams are expected to focus on providing a smaller number of services of acceptable quality rather than a large number of services with many resilience and quality problems. There will always be a need to balance the effort invested with quality. As with commercial products, the platform can provide different levels of service. If all the stream-aligned teams ask for “premium level” services (e.g., zero downtime of the service, auto scaling, self-recovery in case of failure), then it will likely become impossible for the platform team to cope with demand.
TIP
Don Reinertsen recommends using internal pricing (for infrastructure and services) to regulate demand, helping to avoid everyone asking for premium level.15 An example could be tracking cloud-infrastructure costs by team or service.
There is a wide range of boundaries for what a platform can be. A thick platform might consist of the combination of several inner platform teams providing a myriad of services. A thin platform could simply be a layer on top of a vendor-provided solution. (Later in this chapter, we expand on what constitutes a good platform.)
Platform examples at a lower level of the stack could range from provisioning a new server instance to providing tools for access management and security enforcement. A stream-aligned team can then decide to use these patterns without fearing a lack of in-depth skills or effort available to acquire them.
NOTE
Common platforms we find abstract away infrastructure, networking, and other cross-cutting capabilities at a lower level of the stack. This is a great first step but, as explained later in this chapter, a platform can refer to a higher level of abstraction.
Expected Behaviors
As we’ve seen, the mission for a platform team is to provide the underlying internal services required by stream-aligned teams to deliver higher level services or functionalities, thus reducing their cognitive load.
What kind of behaviors and outcomes do we expect to see in an effective platform team?
CASE STUDY: SKY BETTING & GAMING—PLATFORM FEATURE TEAMS (PART 1)
Michael Maibaum, Chief Architect, Sky Betting & Gaming
Sky Betting & Gaming is a British-based gambling company owned by The Stars Group, with headquarters in Leeds, West Yorkshire, and offices in Sheffield, London, Guernsey, Rome, and Germany. Founded in 1999, the company has been a major force for innovation in the online betting and gaming industry. From around 2009, the company began investing heavily in in-house technical expertise in order to drive rapid innovation, effective delivery, and 24/7 operations.
Since I joined the company in 2012, Sky Betting & Gaming (SB&G) has been a place of almost constant, rapid change. To begin with, technology at SB&G was an infrastructure focused function, focused on hosting applications developed by third parties. In 2009, after a period of relatively slow growth, the business decided it needed to be able to move faster and have more control.
Our in-house software delivery has always taken an Agile approach; as it grew, we went through a number of organizational changes, moving from a small number of scrum teams to many squads in tribes and sub-tribes. Early in that process, we started incorporating DevOps into the way we worked. We started with specific goals in mind and a distinct “seed” team—for example, improving build and release tools, because while we were successfully being “Agile” in our software development, we realized we were having problems delivering it to live efficiently and reliably. Later, we used DevOps practices as a core part of squads, and eventually we evolved dedicated reliability teams, combined with operations people being embedded in the delivery teams.
During this time of rapid growth, we needed to solve the problem of configuration management, and to make our services more reliable and to help provide the tools needed to maintain a disaster recovery (DR) environment in sync with production systems. Drawing from the lessons of how we started our DevOps journey, we created a platform evolution team drawn from a mixture of software and infrastructure backgrounds. The platform evolution team’s first priority was implementing a configuration management system using the well-known tool Chef—working to “Chef all the things,” working through the backlog of existing systems, and trying to support the rollout of new or changed services.
Soon after this, we started learning some lessons pretty quickly. The initial implementation of Chef at SB&G was the product of a centralized function with a specific goal (help fix DR), battling to keep up with a period of rapid change and expansion. It became clear that this organizational origin had resulted in a design approach that became a significant constraint. We had a large Chef environment and a significant set of tools built up around it for platform control that lots of people used. Soon they started tripping over each other—problems with shared dependencies, differing priorities, difficulties upgrading—all the usual problems of coupled systems shared between many teams.
(Continued in Chapter 8)
Compose the Platform from Groups of Other Fundamental Teams
In large organizations, a platform will need more than one team to build and run it (and in some cases, separate streams may each have their own platform). In these situations, a platform is composed of groups of other fundamental team types: stream aligned, enabling, complicated subsystem, and platform. Yes: the platform is itself built on a platform (see more on this later in this chapter). However, the streams to which platform teams align are different from the streams for teams building the main (revenue-generating or customer-facing) products and services. In a platform, the streams relate to services and products within the platform, which could be things like logging and monitoring services, APIs for creating test environments, facilities for querying resource usage, and so on. From the viewpoint of the product owner of the platform, there are clear internal streams of value within the platform to which stream-aligned teams align to help them deliver value to the customers of the platform: the teams that use the platform (see more on this later in this chapter). We can see these inner topologies in Figure 5.2 on page 96.
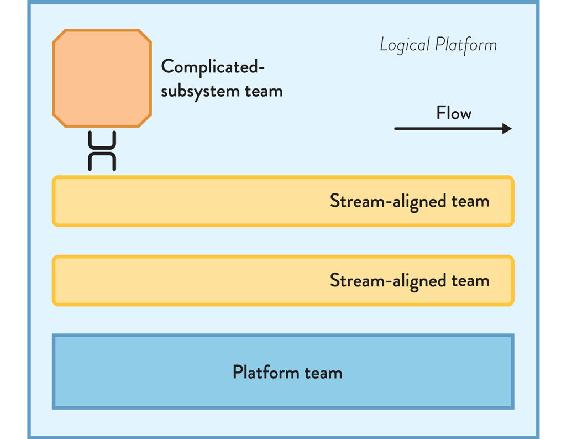
Figure 5.2: Platform Composed of Several Fundamental Team Topologies
In a large organization, the platform is composed of several other fundamental team topologies: stream-aligned Dev teams, complicated-subsystem teams, and a lower-level platform.
In effect, this creates nested or “fractal” teams within the platform—what we like to call inner topologies. As James Womak and Daniel Jones put it, “a product-line manager overseeing an entire product may work with a number of value-stream managers at lower levels taking responsibility for different courses of the value stream.”16 We simply apply the recommendations and guidelines for the various fundamental team topologies within the platform boundary.
From the viewpoint of the Dev teams, the platform is a single entity that provides them with a service that they simply consume via an API: machine or container provisioning, network configuration, etc. However, inside the platform team there are several distinct teams (dealing with network, environments, metrics, etc.) that themselves collaborate with or provide a service to other platform teams.
This “nested” approach is similar to the “layered Ops” approach outlined by veteran technologist James Urquhart, based on his experience at Sun Microsystems and Cisco. In the layered approach, one team provides the base infrastructure hardware (physical and virtual) and a second team focuses on running supporting services on top of the base infrastructure.17 (See Chapter 8 for a more detailed view of this multi-team platform approach.)
CASE STUDY: EVOLVING HIGHLY RESPONSIVE IT OPERATIONS AT AUTO TRADER
Dave Whyte, Operations Engineering Lead, Auto Trader
Andy Humphrey, Head of Customer Operations, Auto Trader
Auto Trader is the UK’s largest digital automotive marketplace. It aims to improve the process of buying and selling vehicles in the UK by continually evolving the ecosystem to provide a better experience for consumers, retailers, and manufacturers alike. Auto Trader is a 100% digital business. Starting life as a local classified magazine in 1977, it has grown and evolved alongside its customers. In 2013, it successfully completed the transition from a print title and became a fully digital marketplace. Auto Trader listed on the London Stock Exchange in March 2015 and is now a member of the FTSE 250 Index.
Moving from a print-oriented organization to a 100% digital business required huge changes within Auto Trader. Back in 2013, the organization was very siloed and not joined up, with “the business” in London and “IT” in Manchester, nearly two hundred miles away. IT work was done with big projects—usually with contractors, not permanent staff—and organizational reporting lines caused big problems and mistrust. Developers would leave a project on the day of go-live, which destroyed the sense of operational responsibility and continuity of care for the software systems.
To make things worse, before 2013 new software-development projects were financed with capital expenditure (CapEx) but the IT operations activities were treated as operational expenditure (OpEx,) which produced a sharp divide between teams building things and teams running things. Software development (Dev) time was booked 90% to CapEx; effectively, they were told, “You must build new things.” They could not work on fixes or things that were right for the customer. Dev was working to serve the “boss” of product management rather than users of the services. We knew we had to change this.
So in 2013, we moved everyone to OpEx. Now everyone is simply doing the work needed to make the company money. With our OpEx-only model, everyone is closer to the customer because we are not thinking about “building new stuff for the product manager” but meeting the needs of users. In fact, OpEx is a deliberate enabling constraint for us: we have a stable workforce of around eight hundred people, and we have no plans to grow hugely. This stable set of people helps with the continuity of care for our software applications and services.
As part of the move to 100% digital, we moved to long-lived, multi-disciplined squads with the responsibility of an end-to-end customer journey. We based the model loosely on the ideas from Spotify but made these work for our context. We also created a special continuous-delivery (CD) team to help other teams adopt CD practices, like automated deployment pipelines, test automation, rich monitoring, and automated environment provisioning. Within three months, we had fully automated deployment for the first application, and then we started on the next application. As this enabling team got more of an understanding of what needed to be done, we realized that it made sense to turn this team into a kind of platform-development team (which we called Infrastructure Engineering).
Fast-forward to 2018, and the remit of Infrastructure Engineering is to build and evolve a platform that takes the pain away from Dev teams, allowing them to take control of their products and services, including operational aspects of their products. Within the platform area, we have several different squads, some focused on new product development for platform features (using standard Agile software development techniques like TDD [test-driven development], retrospectives, and product owners), and some focused on day-to-day operational activities. We don’t have any “DevOps” people; instead, we have experienced operations engineers who do in-depth analysis of live service problems. This means that our focus in the infrastructure area is on the flow of work for Dev teams and how application and infrastructure changes affect customers.
The platform enables squads to focus not only on visible product features but also the invisible operational concerns that are essential to a modern digital offering like Auto Trader. The platform gives product squads the time to care about operability. Interestingly, unlike other organizations, we have never embedded Ops people in Dev squads. Instead, we have an Ops “squad buddy” for each Dev squad, a person from Ops who regularly works with specific Dev squads, attending their standups and providing the “glue” between Dev and Ops.
Since 2013, we have had no concept of an IT department within Auto Trader: product and technology are the same department, the same big team. We have taken the Lean thinking approaches of process design and flow into other areas of the organization, so we now have accounts and sales departments using kanban boards with WIP limits. The sales department even does blameless post-incident reviews for missed sales opportunities!
Avoid Team Silos in the Flow of Change
Generally speaking, teams composed only of people with a single functional expertise should be avoided if we want to deliver software rapidly and safely. Traditionally, many organizations created islands, or “silos,” of functional expertise by grouping the staff, such as:
For years, many organizations used a dedicated “operations” team to manage all aspects of the live or production systems, preventing flow of changes with an explicit hand-off from teams building software coupled with delays accepting the changes. This model also works poorly for safe and rapid flow of change; instead, we combine stream-aligned teams that support and operate software in production together with platform teams that provide the underlying “substrate” for stream-aligned teams.
Organizations that optimize for a safe and rapid flow of change tend to use mixed-discipline or cross-functional teams aligned to the flow of change—what we call stream-aligned teams. Sometimes a particular area is so complicated that a dedicated complicated-subsystem team is needed (see earlier in this chapter). But such teams never sit in the flow of change; instead, they provide services to stream-aligned teams. Work is never handed off to another team for a later stage in the flow.
TIP
Keeping things simple with cross-functional teams.
The use of cross-functional, stream-aligned teams has a very useful side effect. Precisely because stream-aligned teams are composed of people with various skills, there is a strong drive to find the simplest, most user-friendly solution in any given situation. Solutions that require deep expertise in one area are likely to lose against simpler, easier-to-comprehend solutions that work for all members of the stream-aligned team.
A Good Platform Is “Just Big Enough”
A well-designed and well-run platform using what Henrik Kniberg calls “customer-driven platform teams”18 can be a significant “force multiplier” for software delivery within organizations, but care needs to be taken to ensure that the platform always serves the needs of consuming applications and services, not the other way round.
A good platform provides standards, templates, APIs, and well-proven best practices for Dev teams to use to innovate rapidly and effectively. A good platform should make it easy for Dev teams to do the right things in the right way for the organization; this applies to all kinds of product development, not just those involving software. Too often, a platform is left to former system administrators to build and run without using well-defined software development techniques (Agile practices, TDD, continuous delivery, product management, etc.); or it receives so little funding and attention from the organization that it never helps other teams, only hinders them.
The Thinnest Viable Platform
The simplest platform is purely a list on a wiki page of underlying components or services used by consuming software. If those underlying components and services always work reliably, then there is no need for a full-time platform team. However, as the underlying substrate becomes more complicated—even if all components and services are still outsourced—a platform team can provide a valuable management abstraction over the details of the platform, dealing with the coordination of new and deprecated APIs and components. If an organization needs to build custom solutions and integrations into the platform to meet the needs of Dev teams, then the activities of the platform team increase in scope further.
In all cases, we should aim for a thinnest viable platform (TVP) and avoid letting the platform dominate the discourse. As Allan Kelly says, “software developers love building platforms and, without strong product management input, will create a bigger platform than needed.”19 A TVP is a careful balance between keeping the platform small and ensuring that the platform is helping to accelerate and simplify software delivery for teams building on the platform.
Cognitive Load Reduction and Accelerated Product Development
Consider the successful, well-liked software technology platforms of the past few decades: the IBM 8086 processor, the Linux and Windows operating systems, Borland Delphi, the Java Virtual Machine, the .Net Framework, Pivotal Cloud Foundry, Microsoft Azure, and (recently) the IoT platform balena.io and container platform Kubernetes. These platforms have all generally succeeded in reducing the complexity of the underlying systems while exposing enough functionality to be useful to teams building on the platform. This drive to “simplify the developer’s life” (as Conway puts it)20 and reduce cognitive load (see Chapter 3) is an essential aspect of a good platform.
By aiming to reduce cognitive load on Dev teams, a good platform helps Dev teams focus on the germane (differentiating) aspects of a problem, increasing personal and team-level flow, and enabling the whole team to be more effective. As Kenichi Shibata of global publishing company Conde Nast International says, “The most important part of the platform is that it is built for developers.”21
Compelling, Consistent, Well-Chosen Constraints
To avoid the too-common trap of building a platform disconnected from the needs of teams, it is essential to ensure that the platform teams have a focus on user experience (UX) and particularly developer experience (DevEx). This means that as the platform increases in size, expect to add UX capabilities to the platform teams. Shibata says: “Developers will sometimes have frustrations. . . . There should be a way to give feedback to platform developers and how the platform is doing in general. Without this, the platform lives in isolation with the rest of the company. Adoption will be strenuous at best.”22
An attention to good UX/DevEx will make the platform compelling to use, and the platform will feel consistent in the way the APIs and features work. How-to guides and other documentation will be comprehensive (but not verbose), up to date, and focused on achieving specific tasks, not documenting every last corner and niche of the platform.
The platform attempts to “get out of the way” of Dev teams, enabling them to build what they need with few pre-conceptions about how teams need to do that. A good test for DevEx is how easy it is to onboard a new Developer to the platform.
Built On an Underlying Platform
Every software application and every software service is built on a platform. Often the platform is implicit or hidden, or perhaps not noticed much by the team that builds the software, but the platform is still there. As the philosophical expression goes: it’s turtles all the way down.
In a software context, this metaphor means that each platform is itself built on another platform, even if the underlying platform is hidden or implied. If the underlying or lower-level platform is not well defined or stable, the upper platform will itself be unstable, and unable to provide the firm foundation needed to accelerate software delivery within the rest of the organization. If the underlying platform has operational quirks or performance problems, the platform team group will need to build insulation abstractions and workarounds for the operational problems, and/or advertise the potential problems to Dev teams and make it easy for them to avoid hitting the problems. This corresponds with the multi-layer viable-systems model (VSM) described by Stafford Beer in the classic book Brain of the Firm.23
TIP
To help clarify the platform layers in use in your organization, draw the platform layers on a large diagram. This will help to explain to internal platform teams and to teams that use that platform exactly what the platform provides and what it depends on.
Manage as a Live Product or Service
The platform has users (Dev teams) and clearly defined active hours of operation (whenever Dev teams are using it). The users will come to depend on the reliability of the platform and will need an understanding of when new features will appear and when old features will be retired. Therefore, in order to help the Dev team users to be as effective as possible, we need to: (1) treat the platform as a live/production system, with any downtime planned and managed, and (2) use software-product-management and service-management techniques.
When we treat the platform as a live or production system, we need to undertake all the normal activities and practices that we would with any other live system: define the hours of operation, define the response time for incidents and support, ensure we have an on-call rota to support the platform, manage incidents and unplanned downtime with suitable communication channels (such as service status pages), and so on. Naturally, as the platform grows, it can be useful to reconsider exactly what is needed from the teams within the organization and what can actually be provided externally, thereby reducing the need for an ever-increasing operational-support burden on the platform teams: “the platform team’s main clientele is the product teams,” as Kenichi Shibata says.24
So, how do we manage a live software system with well-defined users and hours of operation? By using software-product-management techniques. The platform, therefore, needs a roadmap curated by product-management practitioners, possibly co-created but at least influenced by the needs of users (Dev teams). The platform team will almost certainly be working with user personas for the users (such as Samir the Web Developer, Jennifer the Tester, Mani the Product Owner, Jack the Service Experience Engineer, and so on). The user personas will help the platform team to empathize with the needs, frustrations, and goals of typical users of the platform. Members of the platform teams will engage with customers (Dev teams and others) regularly to understand what they need.
Crucially, the evolution of the platform “product” is not simply driven by feature requests from Dev teams; instead, it is curated and carefully shaped to meet their needs in the longer term. Feature usage is tracked with metrics and used to shape conversations about prioritization. A platform is not just a collection of features that Dev teams happened to ask for at specific points in the past, but a holistic, well-crafted, consistent thing that takes into account the direction of technology change in the industry as a whole and the changing needs of the organization. A good platform will also serve to reduce the need for security and audit teams to spend time with the Dev team.
Convert Common Team Types to the Fundamental Team Topologies
Many organizations would benefit from increasing the clarity around the definition and purpose of their teams. In fact, we think that most organizations would see major gains in effectiveness by mapping each of their teams to one of the four fundamental topologies; that is, identify which of the four fundamental topologies would represent the best way of working for each team, and then change that team’s remit to adopt the purpose and behavior patterns of that topology.
Move to Mostly Stream-Aligned Teams for Longevity and Flexibility
Most teams in a flow-optimized organization should be long-lived, multi-disciplined, stream-aligned teams. These teams take ownership of discrete slices of functionality or certain user outcomes, building strong and lasting relationships with business representatives and other delivery teams. Stream-aligned teams can expect to have cognitive load matched to their capabilities through the support and help they get from enabling teams, platform teams, and complicated-subsystem teams.
Infrastructure Teams to Platform Teams
Traditionally, many infrastructure teams were responsible for all aspects of the live/production infrastructure, including any changes to applications deployed on that infrastructure, as shown in Figure 5.3: