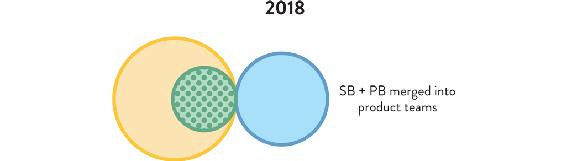
Figure 8.5: System-Build and Platform-Build Teams Merged Back into Dev and Ops at TransUnion
The SB and PB teams merged back into Dev and Ops, providing Platform-as-a-Service.
Our early realization that this should be an evolution of teams was really important for our success. People knew that things would take some time, and the clear but changing responsibility boundaries helped people to understand their part in the process.
Constant Evolution of Team Topologies
Collaboration is costly but good for discovery of new approaches, and X-as-a-Service is good for predictable delivery; so teams can be set up to match the needs of each area of the software system and each team. But what happens when the requirements or operating context changes?
Interaction modes of different teams should be expected to change regularly, depending on what the teams need to achieve. If a team needs to explore part of the technology stack or part of the logical domain model currently handled by another team, then they should agree to use collaboration mode for a specific period of time. If a team needs to increase its delivery predictability following successful discovery of new approaches with another team, then it should move away from collaboration mode toward X-as-a-Service to help define the API between the teams.
In this way, teams should expect to adopt different interaction modes for periods of time depending on what they need to achieve. Of course, Conway’s law tells us that during the discovery and rapid learning taking place as part of collaboration mode, the responsibilities and architecture of the software is likely to be more “blended together” compared to when the teams are interacting using X-as-a-Service. By anticipating this fuzziness, some awkward team interactions (“the API is not well designed” and so forth) can be avoided by tightening up the API as the team moves to X-as-a-Service.
The evolution of team topologies from close collaboration to limited collaboration to X-as-a-Service can be visualized in Figure 8.6 (see page 160).

Figure 8.6: Evolution of Team Topologies
The evolution of Team Topologies from close collaboration to limited collaboration (discovery) through to X-as-a-Service for established, predictable delivery.
Initial close collaboration evolves into more limited collaboration on a smaller number of things as the technology and product is better understood through discovery, and it further evolves into X-as-a-Service once the product or service boundary is more established.
In a larger enterprise, this “discover to establish” pattern is expected to happen all the time with different teams at different stages of development. There should be multiple discovery activities happening simultaneously, with other teams taking advantage of well-defined APIs to be able to consume things as a service, as shown in Figure 8.7 (see page 160).
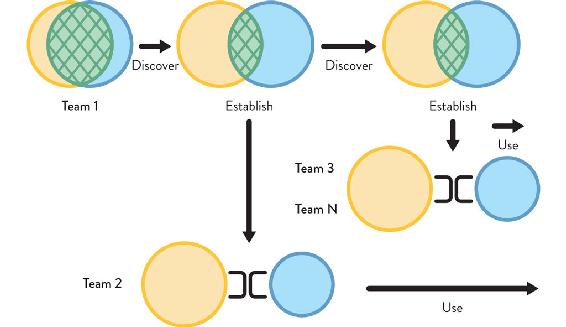
Figure 8.7: Evolution of Team Topologies in an Enterprise
Team 1 continues to collaborate with a platform team, discovering new patterns and ways of using new technologies. This discovery activity eventually enables Team 2 to adopt an X-as-a-Service relationship with the platform team. Later, Teams 3 and beyond adopt a later version of the platform, using it as a service without having to collaborate closely with the platform team.
In some organizations, teams may operate on a permanent basis with many teams using collaboration, especially if the rate of innovation is very high. Other organizations may have a tendency toward mostly X-as-a-Service interactions, because they have a well-defined problem space and mostly need to execute on well-understood business problems. The key point here is that teams need different interaction modes depending on what they need to achieve.
Ultimately, by expecting and encouraging team interactions to move between collaboration and X-as-a-Service for specific reasons, organizations can achieve agility.
Keeping the interrelations between teams in the organization well defined and dynamic provides the foundation for what Jeff Sussna calls a “continuous design capability” for external and internal contexts.4 This dynamic reshaping provides a key strategic capability. John Kotter, expert in organizational change, says: “I think of [strategy] as an ongoing process of ‘searching, doing, learning, and modifying’. . . . The more the organization exercises its strategy skills, the more adept it becomes at dealing with a hypercompetitive environment.”5
TIP
Evolve different team topologies for different parts of the organization at different times to match the team purpose and context.
We have seen that team interactions should explicitly evolve over time, depending on what the teams are doing. In a discovery phase, some degree of collaboration is expected, but close collaboration often doesn’t scale across the organization. The aim should be to try to establish a well-defined and capable platform that many teams can simply use as a service.
Organizations should aim to move from discovery activities to establish predictable delivery over time as new commodity services and platforms become available. The implication for organizations is that the experience of people in different teams within the organization will differ depending on the kind of thing they’re working on at that point in time. Not all teams will interact with other teams in the same way, and that is what we want.
Different topologies and different team interactions for different parts of an organization need to evolve at different times based on what they are doing and what they are trying to achieve. The organization must ask itself: “Are we trying to discover things? And how rapidly do we need to discover them?” There might be times when there is a need to colocate people—at the same desks or simply on the same floor in the same building—to produce the kind of proximity that encourages the right amount of collaboration. At other times, teams might move to separate floors or even separate buildings in order to help enforce an API boundary; a slight distance in terms of communication can help do that (see Chapter 3 for more details on office layouts).
The team topologies within an organization change slowly over several months, not every day or every week. Over a few months, change should be encouraged in the team interaction modes, and a corresponding change should be expected in the software architecture.
CASE STUDY: SKY BETTING & GAMING—PLATFORM FEATURE TEAMS (PART 2)
Michael Maibaum, Chief Architect, Sky Betting & Gaming
(Continued from Chapter 5)
Platform Evolution had reached a tipping point, and we had a choice to make: we could dissolve the team and make each of the now relatively large product teams responsible for their own configuration management, or we could try and figure out how to support those teams more effectively—to enable them to accelerate delivery with high quality and reliability.
We decided that the Platform Evolution team had to change, becoming a product team with services and support capabilities, in order to think and design the things they were working on as services to be consumed by other teams. In short, the team had to focus on features that drive value to the business.
Platform Evolution became Platform Services and began to work with a very different worldview. Their mission was to provide services designed to support other teams with features and capabilities driven by their customers. In other words, Platform Services became a product-driven team.
Alongside the work to break down our Chef monolith, Platform Services developed a number of customer-focused services, providing centralized value-add services to teams, including AWS integrations, build and test environments, logging platforms, and much more. In each case, Platform Services took a fundamental capability that teams needed (and could, in theory, build for themselves) and provided a managed service equivalent. Platform Services took the time to provide bespoke adaptations that delivery teams needed to make the standard tool more valuable and easier to use in the SB&G environment; and in doing so, saved the business the overhead of repeating those solutions in many teams around the business.
Through this period, Platform Evolution/Services were most closely aligned with the in-house software teams. It was often a point of debate and contention on the appropriate boundaries of responsibility, particularly between our infrastructure team and Platform Services. Platform Services was building things like firewall and load-balancer automation, tools to support our increasing usage of AWS, secrets management and PKI, but it was often struggling with the organizational boundaries between it and the infrastructure team. The question arose of how much should infrastructure be responsible for in the “platform layer”? And—slightly more delicately—were they organized in a way to support products?
Once this conversation started, it became clear that it overlapped with conversations within our infrastructure team about how they should be organized. Infrastructure was the last significant function in the business with a clear delivery/operations split in the team, and there was an appetite to try something different. Infrastructure reorganized around products and services; smaller teams owned the end-to-end life cycle of a coherent set of related things, with a drive to make them better for their customers around the business. As part of that transformation, it also became obvious where Platform Services fit best—not as one team between infrastructure and the rest of technology but as part of the infrastructure function.
Some services—like load balancer and firewall automation—found a more natural home in one of our networking-related squads, while some remained in the two Platform Services squads: Platform Engineering and Delivery Engineering. We seeded automation engineers into infrastructure squads around services that had never had that capability, and developed an infrastructure product function to support the team’s engagement with the wider business.
We now have infrastructure-platform feature teams, just like we have customer-facing product feature teams; and while the change hasn’t been simple or without its challenges, it’s clear from the level of engagement, sense of ownership, and reduced friction with other areas of the business that the change has been transformative. From the other areas of the business, it’s now clear who to talk to and what that team is doing and why, when it often wasn’t before, because it was all just “infrastructure.”
Combining Team Topologies for Greater Effectiveness
At any one time, different teams within an organization will have different interaction and collaboration needs. Different kinds of team topologies should be expected to be seen simultaneously. Some degree of collaboration between teams is expected, but collaboration often doesn’t scale across the organization; and consuming things as a service is often more effective as the number of teams increases.
For example, perhaps we have four stream-aligned teams building different parts of the software system. One of the teams may be in collaboration mode with the platform team, undertaking some discovery work on new logging technology, while the other three teams are simply consuming the platform in X-as-a-Service mode.
Superimposed on the same diagram, the interactions might look like this: The first stream-aligned team has a collaboration interaction with the platform team—the teams collaborate on new technology approaches and learn new techniques rapidly. The stream-aligned team is supported by a enabling team. The other three stream-aligned teams treat the platform as a service and are also supported by the enabling team. These different interactions are present to reflect the nature of the work being undertaken by the stream-aligned teams and the kind of interactions present in the software they are building.
In this example, there are three different kinds of team interactions happening simultaneously: the stream-aligned teams are experiencing a facilitating interaction with the enabling team, and three of the four stream-aligned teams expect an X-as-a-Service interaction with the platform, leaving one stream-aligned team to undertake the discovery work with the platform team via a collaboration interaction.
Because the interaction modes are clear and explicit, and because these are mapped to well-defined purposes, people on different teams within the organization understand why they interact in different ways with other teams. This helps to increase engagement within teams and to enable teams to use any friction from the interactions as signals to detect a range of problems. We explore some of these signals in the next section.
Triggers for Evolution of Team Topologies
Using the advice from Chapter 5, it is fairly straightforward to map an organization’s structure to the four fundamental team topologies at a specific point in time, but it’s often difficult to have the required organizational self-awareness to detect when it’s time to evolve the team structure. There are some situations that act as triggers to redesign team topologies within the organization. Learning to recognize these will help an organization continue to adapt and evolve with its needs.
Trigger: Software Has Grown Too Large for One Team
Symptoms
Context
Successful software products tend to grow larger and larger as more features get added and more customers adopt the product. While initially it is possible that everyone in the product team has a fairly broad understanding of the codebase, that becomes increasingly more difficult over time.
This can lead to an (often unspoken) specialization within the team regarding different components of the system. Requests that require changes to a specific component or workflow routinely get assigned to the same team member(s), because they will be able to deliver faster than other team members.
This reinforcing cycle of specialization is a local optimization (“get this request delivered quickly”) that can negatively affect the team’s overall flow of work when planning gets dictated by “who knows what” rather than “what’s the highest priority work we need to do now.” This level of specialization introduces bottlenecks in delivery (as storied in The Phoenix Project and explained in The DevOps Handbook). The routine aspect can also negatively affect individual motivation.
Another aspect at play occurs when the team no longer holds a holistic view of the system; thus, it loses the self-awareness to realize when the system has become too large. While there is some correlation between system size in terms of lines of code or features, it is the limit on cognitive capacity to handle changes to the system in an effective way that is most of concern here.
Trigger: Delivery Cadence Is Becoming Slower
Symptoms
Context
A long-lived, high-performing product team should be able to steadily improve their delivery cadence as they find ways to work more efficiently together and remove bottlenecks in delivery. However, a pre-requisite for these teams to flourish is to grant them autonomy over the entire life cycle of the product. This means no hard dependencies on external teams, such as waiting for another team to create new infrastructure. Being able to self-serve new infrastructure via an internal platform is a soft dependency (assuming the provisioning self-service is maintained by a platform team).
This level of autonomy is difficult to achieve in many organizations. In fact, it’s common to see the opposite: reducing autonomy by introducing new hard dependencies between teams. It could be an attempt at increasing test coverage by creating a quality assurance (QA) team to centralize testing of all the products and, theoretically, allocate work to testers more efficiently. While such a goal is laudable, this team design introduces a “functional silo” (QA), whereby all teams delivering software will need to wait on the QA team to be available to test their updates.
The emergence of DevOps highlighted the divide between development and operations teams in the 2010s, but it’s the same problem—to a greater or lesser extent—for all other silos that intervene in the product delivery life cycle.
Note that it’s also possible that delivery has slowed down because of accrued technical debt. In this scenario, the complexity of the codebase might reach a state where even small changes are costly and frequently cause regressions. That means deliveries take much longer to develop and stabilize than when the codebase was initially created.
Trigger: Multiple Business Services Rely On a Large Set of Underlying Services
Symptoms
Context
In some highly regulated industry sectors, such as finance, insurance, legal, and government, several different high-level business services may rely on a large set of separate underlying services, APIs, or subsystems. For example, an insurance company may need to conduct lengthy physical checks on factory machinery in order to provide an updated insurance quote; or a bank may need to await delivery of proof-of-address documents before opening a new bank account. The lower-level systems on which these higher-level business services rely might provide specialist payment mechanisms, data cleansing, identity verification, background legal checks, and so forth, each of which needs multiple teams working on it to evolve and sustain the service. Business process management (BPM)—perhaps augmented with machine learning (ML)—can help to automate some of the work in these cases; but engaged, aware teams still need to configure and test the BPM workflow scenarios. Some of these services and subsystems may be built and provided in house, but others may be provided by external suppliers.
In order to deliver useful business value, the higher-level streams need to integrate with many lower-level services (the realm of enterprise service management). If the streams have to integrate separately with each underlying service, it can be challenging to assess the effectiveness of flow and to diagnose errors in long-running processes that may have some human-decision input. For example, the underlying services may not expose tracking mechanisms or may each have a separate way to identify transactions.
The solution to these kinds of multi-service integration problems is twofold: (1) “Platformize” the lower-level services and APIs with a thin “platform wrapper” that provides a consistent developer experience (DevEx) for stream-aligned teams with things like request-tracking correlation IDs, health-check endpoints, test harnesses, service-level objectives, and diagnostic APIs. This “outer platform” is built on a still lower-level platform, but that remains hidden from stream-aligned teams. (2) Use stream-aligned teams for each high-level business service responsible for operational telemetry and fault diagnosis: building and evolving “just enough” telemetry integration and diagnostic capabilities to be able to detect where problems occur. Being in control of telemetry and diagnostics enables the stream-aligned teams to trace and improve the flow of change in their stream (see Figure 8.8 on page 168).
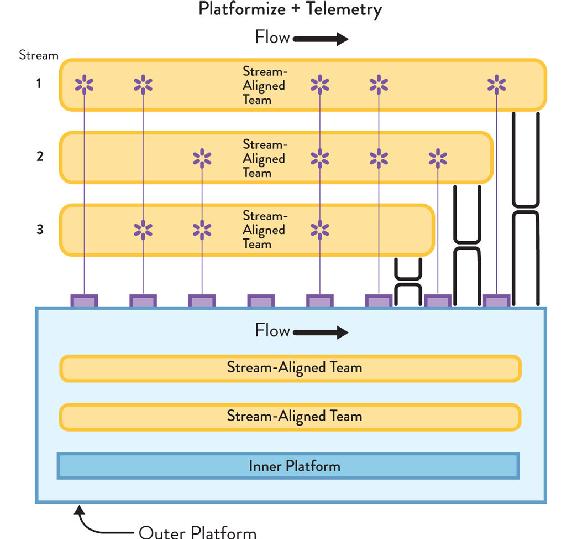
Figure 8.8: Example of a “Platform Wrapper”
Increase flow predictability in higher-level business services (streams) through the use of a “platform wrapper” to “platformize” the lower-level services and APIs, allowing the streams to treat all their dependencies as a single platform with a holistic roadmap and consistent DevEx. The streams also have rich telemetry to track flow and resource usage of the platform.
As part of the rich telemetry around each higher-level business service, the stream-aligned team builds and owns: (1) a lightweight digital-service “wrapper” that provides consistent logging time stamps, consistency in correlation IDs, request/response identification and logging, etc. when calling different underlying services and APIs in the platform; (2) logging, metrics, and dashboarding for the digital-service wrapper, allowing all “stream side” coordination to be tracked and traced (even if the “platform side” aspects are variable in their visibility initially).
To support a sustained and predictable flow in the higher-level business services, the platform wrapper must improve the DevEx around the platform services—consistency and standards around logging, metrics, dashboards, correlation IDs, etc.—so that greater traceability is possible from within the digital-service wrapper built by stream-aligned teams.
Self Steer Design and Development
Historically, many organizations have treated “develop” and “operate” as two distinct phases of software delivery, with very little interaction and certainly almost no feedback from operate to develop. Modern software delivery must take a completely different approach: the operation of the software should act as and provide valuable signals to the development activities. By treating operations as rich, sensory input to development, a cybernetic feedback system is set up that enables the organization to self steer.
Treat Teams and Team Interactions as Senses and Signals
With well-defined, stable teams taking effective ownership of different parts of the software systems and interacting using well-defined communication patterns, organizations can begin to activate a powerful strategic capability: organizational sensing.
Organizational sensing uses teams and their internal and external communication as the “senses” of the organization (sight, sound, touch, smell, taste)—what Peter Drucker calls “synthetic sense organs for the outside.”6 Without stable, well-defined neural communication pathways, no living organism can effectively sense anything. To sense things (and make sense of things), organisms need defined, reliable communication pathways. Similarly, with well-defined and stable communication pathways between teams, organizations can detect signals from across the organization and outside it, becoming something like an organism.
Many organizations—those with unstable and ill-defined teams, relying on key individuals and (often) suppressing the voices of large numbers of staff—are effectively “senseless” in both meanings of the word: they cannot sense their environmental situation, and what they do makes no sense. When speed of change was measured in months or years (as in the past), organizations could manage with very slow and limited environmental sensing; however, in today’s network-connected world, high-fidelity sensing is crucial for organizational survival, just as an animal or other organism needs senses to survive in a competitive, dynamic natural environment.
Not only do organizations need to sense things with high fidelity, they also need to respond rapidly. Organisms generally have separate specialized organs for sensing (eyes, ears, etc.) and responding to input (limbs, body, etc.). The kinds of signals that different teams will be able to detect will differ depending on what the team does and how close it is to external customers, internal customers, other teams, and so on, but each team will be capable of providing sensory input to the organization and responding to the information by adjusting their team interaction patterns.
Thankfully, to help us with this task of what Naomi Stanford calls “environmental scanning,”7 we have modern digital tools. Rich telemetry from digital metrics and logging helps teams achieve a real-time view of the health and performance of their software systems; and lightweight, network-connected devices (IoT and 4IR) provide regular sensor data from many thousands of physical locations.
So, what kinds of things should an organization sense? These questions can help an organization discover the answer:
IT Operations as High-Value Sensory Input to Development
Moving quickly relies on sensory feedback about the environment. To sustain a fast flow of software changes, organizations must invest in organizational sensing and cybernetic control. A key aspect of this sensory feedback is the use of IT operations teams as high-fidelity sensory input for development teams, requiring joined-up communications between teams running systems (Ops) and teams building systems (Dev). Sadly, many organizations prevent themselves from moving quickly and safely. As Sriram Narayan says, “Project sponsors looking to reduce cost opt for a different team of lower-cost people for maintenance work. This is false economy. It hurts the larger business outcome and reduces IT agility.”8
Instead of trying to optimize for lowest cost in so-called “maintenance” work, it is essential that organizations use signals from maintenance work as input to software-development activities. In the The DevOps Handbook, Gene Kim and colleagues define The Three Ways of DevOps for modern, high-performing organizations:9
The second and third ways rely on strong communication pathways between Ops and Dev. As we saw in Chapter 5, one of the simplest ways to ensure a continual flow of high-fidelity information from Ops to Dev is to have Ops and Dev on the same team, or at least aligned to the same stream of change as a stream-aligned pair of teams, with swarming for operational incidents. For organizations that have yet to move to this model or have a separate operations group, it is vital that communication paths are established and nurtured between Ops and Dev. This provides high-fidelity information about operational aspects, such as operability, reliability, usability, securability, and so forth, to enable Dev teams to course correct and navigate toward software designs that reduce operational overheads and improve reliability.
Treating Ops as an input to Dev requires a radical rethinking of the roles of these often-separate groups. Jeff Sussna, author of Designing Delivery, puts it like this: “Businesses normally treat operations as an output of design. . . . In order to empathize, though, one must be able to hear. In order to hear, one needs input from operations. Operations thus becomes an input to design.”10
As Jeff implies, the aim here is to empathize with the various groups of users of the software and services we are building. By developing greater empathy for users, we can improve the kinds of interactions we have with them, enhancing their experiences and better meeting their needs.
Increasingly, software is less of a “product for” and more of an “ongoing conversation with” users. To make this ongoing conversation effective and successful, organizations need a “continuity of care” for its software. The team that designs and builds the software needs to be involved in its running and operational aspects in order to be able to build it effectively in the first place. The team providing this “design and run” continuity of care also needs to have some responsibility for the commercial viability of the software service; otherwise, decisions will be made in a vacuum separate from financial reality.
How can we encourage teams to continue to care about the software long after they have finished coding a feature? One of the most important changes to improve the continuity of care is to avoid “maintenance” or “business as usual” (BAU) teams whose remit is simply to maintain existing software. Sriram Narayan, author of Agile IT Organization Design, says “separate maintenance teams and matrix organizations . . . work against responsiveness.”11 By separating the maintenance work from the initial design work, the feedback loop from Ops to Dev is broken, and any influence that operating that software may have on the design of the software is lost (see Figure 8.9).
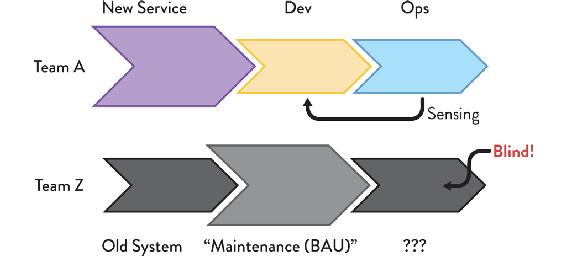
Figure 8.9: New-Service and “Business as Usual” (BAU) Teams
Having separate teams for “new stuff” and BAU tends to prevent learning, improvements and ability to self-steer. It is a non-cybernetic approach.
Having separate teams for new-stuff and BAU also tends to prevent learning between these two groups. The new-service team gets to implement new technologies and approaches but without any ability to see whether these approaches are effective. The new approaches may be damaging, but the new-service team has little incentive to care, as only the BAU team will feel the pain of these poor choices. Furthermore, the BAU team typically has little chance to apply newer telemetry techniques to existing software, leaving them blind to the signals potentially available to indicate customer happiness or unhappiness.
Instead, it is much more effective to have one team responsible for new services and BAU of an existing system side by side. This helps the team to increase the quality of signals from the older system by retro-fitting telemetry from the newer system and increasing the organization’s ability to sense its environment and self steer (see Figure 8.10).
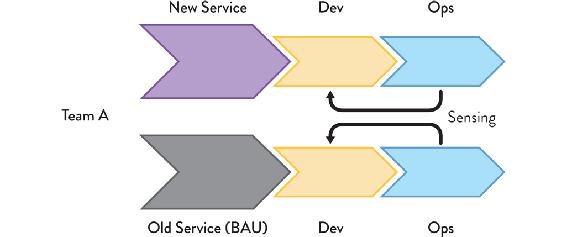
Figure 8.10: Side-by-Side New Service and BAU Teams
A cybernetic approach to maintaining older systems has a single stream-aligned team (or pair of teams) developing and running the new service and the older systems, enabling the team to retro-fit newer telemetry to the older system and increase the fidelity of the sensing from both systems.
In effect, each stream-aligned team should expect to look after one or more older systems in addition to the newer systems they are building and running. This helps them learn about a wider range of user and system behaviors, and avoid repeating mistakes made in earlier systems.
To generate and receive high-fidelity information from frontline, operational systems, highly skilled, highly aware people are needed. This means that—contrary to how many IT operations teams were staffed in the past—people in IT operations need to be able to recognize and triage problems quickly and accurately, providing accurate, useful information to their colleagues who are focused on building new features. Instead of the IT-operations service desk being staffed with the most junior people, it should be staffed with some of the most experienced engineers in the organization, either exclusively or in tandem with some of the more junior members.
Summary: Evolving Team Topologies
The rapid pace of change in technology, markets, customer and user demands, and regulatory requirements means successful organizations need to expect to adapt and evolve their organization structure on a regular basis. However, organizations that build and run software systems need to ensure that their team interactions optimize for flow, Conway’s law, and a team-first approach (including team cognitive load). By deploying the four fundamental team topologies with the three core team interaction modes, organizations gain crucial clarity of purpose for their teams on an ongoing basis. Teams understand how, when, and why they need to collaborate with other teams; how, when, and why they should be consuming or providing something “as a service”; and how, when, and why they should provide or seek facilitation with another team. Thus, an organization should expect to see different kinds of interactions between different kinds of teams at any given time as the organization responds to new challenges.
The combination of well-defined teams and well-defined interaction modes provides a powerful and flexible organizational capability for structural adaptation to changing external and internal conditions, enabling the organization to “sense” its environment, modify its activities, and focus to fit.