4 | Static Team Topologies |
Instead of structuring teams according to technical know-how or activities, organize teams according to business domain areas.
—Jutta Eckstein, “Feature Teams—Distributed and Dispersed,” in Agility Across Time and Space
In Part I, we saw the strong pull that Conway’s law exercises on system architecture by mirroring team structures and communication paths in the final product design. We also highlighted that efficient software delivery requires a team-first approach that relies on long-lived autonomous teams achieving fast flow. Part II will focus on how we put these two ideas together in a way that maximizes flow yet respects the cognitive limits of teams.
In Chapter 4, we start with the need to intentionally design teams, and to understand that good and bad team patterns are a factor of many aspects, like org size, maturity, and software scale. Today, the prevailing way to set up or reorganize teams is ad hoc, focused on immediate needs rather than the ability to adapt in the long run.
In order to be as effective as possible, we need to consciously design our teams rather than merely allow them to form accidentally or haphazardly. We call these consciously designed team structures team topologies, a term that acknowledges that teams should be deliberately “placed” into organizations while also referring to the boundary of responsibility of each team.
In this chapter, we’ll take a look at examples of static team topologies—that is team structures and interactions that fit a specific organization’s context at a given point in time. In particular, we will draw from the catalog of DevOps Topologies, which makes for a good, approachable starting point for many organizations.
But first, let’s look at a couple of common anti-patterns that result from ad hoc team design.
Team Anti-Patterns
As we’ve seen so far, the way in which people are organized into teams for building and operating software systems has a strong effect on the nature of the resulting systems, following Conway’s law.
When organizations do not explicitly think about team structures and patterns of interaction, they encounter unexpected difficulties building and running software systems. In our work with clients, we’ve seen the occurrence of two particular anti-patterns for team formation across organizations of different sizes.
The first anti-pattern is ad hoc team design. This includes teams that have grown too large and been broken up as the communication overhead starts taking a toll, teams created to take care of all COTS software or all middleware, or a DBA team created after a software crash in production due to poor database handling. Of course, all of these situations should trigger some action, but without considering the broader context of the interrelationships between teams, what seems like a natural solution might slow down delivery and eat away at the autonomy of teams.
The other common anti-pattern is shuffling team members. This leads to extremely volatile team assembled on a project basis and disassembled immediately afterward, perhaps leaving one or two engineers behind to handle the “hardening” and maintenance phases of the application(s). While there is a sense of higher flexibility and a perceived ability to respond faster to deadlines, the cost of forming new teams and switching context repeatedly gets overlooked (or is unconsciously factored in the project estimates). A computer will perform the same whether it is placed in Room A or Room B, but an engineer placed on Team A may perform very differently than if placed on Team B.
Organizations must design teams intentionally by asking these questions: Given our skills, constraints, cultural and engineering maturity, desired software architecture, and business goals, which team topology will help us deliver results faster and safer? How can we reduce or avoid handovers between teams in the main flow of change? Where should the boundaries be in the software system in order to preserve system viability and encourage rapid flow? How can our teams align to that?
Design for Flow of Change
Organizations that build and run large-scale software systems are turning to organization designs that emphasize the flow of change from concept to working software—what we might call “low friction” software delivery. Older organizational models—with functional silos between different departments, heavy use of outsourcing, and repeated hand-offs between teams—do not provide the safety at speed or the organizational feedback mechanisms necessary for the ongoing evolution of business services needed to respond to customer and market conditions on a daily basis. As Naomi Stanford points out, “an organization has a better chance of success if it is reflectively designed.”1
Spotify provides a good example of explicit organizational design to improve the effectiveness of software delivery and operations, as described by Henrik Kniberg and Anders Ivarsson in their 2012 blog post, “Scaling Agile @ Spotify.”2 Known as “The Spotify Model,” technical staff at Spotify are arranged into small, autonomous, cross-functional squads, each with a long-term mission and comprised of around five to nine people. Several squads that work on similar areas are collected into a tribe, a sort of affinity grouping of squads. The squads within a tribe are familiar with the work of other squads and coordinate inside the tribe.
Engineers within a tribe with similar skills and competencies share practices through a chapter. So, for example, all the testers across six squads in a tribe could be part of a testers chapter. Line management also happens via chapters, but the line manager (the chapter lead) is also part of the day-to-day work of a squad, not an aloof manager. Spotify also uses a more diffuse “guild,” akin to a community of practice, that can include people from across multiple tribes, chapters, and squads. “Chapters and guilds . . . [are] the glue that keeps the company together, [providing] economies of scale without sacrificing too much autonomy.”3
Many organizations have mistakenly copied the Spotify model without understanding the underlying purpose, culture, dynamics, or trajectory of the Spotify team arrangements. As Kniberg and Ivarsson clearly state in their post: “We didn’t invent this model. Spotify is (like any good Agile company) evolving fast. This article is only a snapshot of our current way of working—a journey in progress, not a journey completed.”4
It is essential that organizations take into account more than a static placement of people when looking at the design of team interactions.
Shape Team Intercommunication to Enable Flow and Sensing
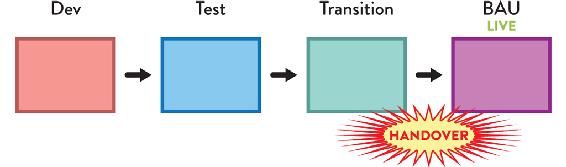
Many organizations have significant flaws in the way their teams interact as part of building and running software systems. Specifically, such organizations seem to assume that software delivery is a one-way process, leading from specification to design, from design to coding, from coding to testing and releasing, and from releasing to business as usual (BAU) operation (see Figure 4.1).
Figure 4.1: Organization not Optimized for Flow of Change
Traditional flow of change in an organization not optimized for flow, with a series of groups owning different activities and handing over the work to the next team. No information flows back from the live systems into teams building the software.
This linear, stepwise sequence of changes—usually with separate functional silo divisions for each stage—(as seen in Figure 4.1)—is completely incompatible with the speed of change and complexity of modern software systems. The assumption that the software-development process has little or nothing to learn from how the software runs in the live environment is fundamentally flawed. On the contrary, organizations that expose software-development teams to the software running in the live environment tend to address user-visible and operational problems much more rapidly compared to their siloed competitors (see Figure 4.2 on page 65).
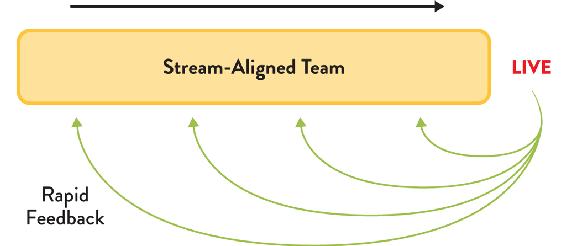
Figure 4.2: Organization Optimized for Flow of Change
Organizations set up for fast flow avoid hand-offs by keeping work within the stream-aligned team, and they ensure that the rich set of operational information flows back into the team.
In Accelerate, Nicole Forsgren, Jez Humble, and Gene Kim collected data on the software-development practices of hundreds of organizations around the world, which led them to conclude that “we must . . . ensure delivery teams are cross-functional, with all the skills necessary to design, develop, test, deploy, and operate the system on the same team.”5 Organizations that value information feedback from live (production) systems can not only improve their software more rapidly but also develop a heightened responsiveness to customers and users.
This superior “sensing” ability comes from treating frontline staff and teams as highly valuable sources of signals about the market and environment in which the organization is operating.
When we apply this kind of sensing not only at the edges of the organization but also inside the organization—between teams—we can provide a radically enhanced strategic capability for rapidly discovering deficiencies in platforms, services, and interfaces, enabling us to address these problems early and thereby improve the effectiveness of IT as a whole. (We will look further at this organizational sensing in Part III.)
DevOps and the DevOps Topologies
This kind of organizational sensing “nirvana,” with cross-functional teams that build, test, and operate their own software, was an unfamiliar concept to most organizations back in 2009. By then, the classic anti-pattern in team design and interactions of completely separating responsibilities between development and operations teams (among others) was prevalent, with software releases being thrown over the “fence” or “wall” and communication mostly accomplished through tickets. In the DevOps world, this became known as the “wall of confusion.”
The DevOps movement emerged around 2009 due to this growing friction between Dev and Ops, highlighted by an increased pressure on operations teams to deploy more often as Agile became more mainstream. The problem was that many organizations adopting Agile were not explicitly addressing the gap between software delivery speed and operations teams’ capacity to provide resources or deploy updates. The misalignment between teams became more and more evident, leading to poor behaviors and lack of focus on the flow of work.
A key contribution of DevOps was to raise awareness of the problems lingering in how teams interacted (or not) across the delivery chain, causing delays, rework, failures, and a lack of understanding and empathy toward other teams. It also became clear that such issues were not only happening between application development and operations teams but in interactions with many other teams involved in software delivery, like QA, InfoSec, networking, and more.
Even though many people see DevOps as fundamentally addressing technological aspects of automation and tooling, only organizations that also address fundamental misalignments between teams are able to achieve the full potential benefits from adopting DevOps.
DevOps Topologies
The DevOps Topologies catalog, originally created by Matthew Skelton in 2013 and later expanded by Manuel Pais, is an online collection of team design and interactions patterns and anti-patterns that work well for kick-starting conversations around team responsibilities, interfaces, and collaboration between technology teams.6 Crucially, successful patterns are strongly dependent on contextual aspects, like organization and product size, engineering maturity, and shared goals.
The topologies became an effective reference of team structures for enterprise software delivery; however, they were never meant to be static structures, but rather a depiction of a moment in time influenced by multiple factors, like the type of products delivered, technical leadership, and operational experience. The implicit idea was that teams should evolve and morph over time.
This chapter presents some of the patterns in the DevOps Topologies catalog to help illustrate the thinking around choosing team structures with organization context and needs in mind. It is not intended to be a deep dive into the DevOps Topologies that are available online; instead, it is a helpful introduction to team design for technology teams applied to DevOps. The rest of the book will focus on the broader context of business and technology teams at large, beyond DevOps.
The DevOps Topologies reflect two key ideas: (1) There is no one-size-fits-all approach to structuring teams for DevOps success. The suitability and effectiveness of any given topology depends on the organization’s context. (2) There are several topologies known to be detrimental (anti-patterns) to DevOps success, as they overlook or go against core tenets of DevOps. In short, there is no “right” topology, but several “bad” topologies for any one organization.
Successful Team Patterns
An inadequate choice of topology doesn’t necessarily mean that the desired outcomes aren’t good. It’s often the case that a given topology doesn’t yield those outcomes because there is a focus on the new team structure but not enough consideration about the surrounding teams and structures. The success of different types of teams does not depend solely on team members’s skills and experience; it also depends on (perhaps most importantly) the surrounding environment, teams, and interactions.
Feature Teams Require High-Engineering Maturity and Trust
Let’s take the example of feature teams. We consider a feature team to be a cross-functional, cross-component team that can take a customer facing feature from idea all the way to production, making them available to customers and, ideally, monitoring its usage and performance. Are these a pattern or an anti-pattern? As you might have guessed by now, it depends.
A cross-functional feature team can bring high value to an organization by delivering cross-component, customer-centric features much faster than multiple component teams making their own changes and synchronizing into a single release. But this can only happen when the feature team is self-sufficient, meaning they are able to deliver features into production without waiting for other teams.
The feature team typically needs to touch multiple codebases, which might be owned by different component teams. If the team does not have a high degree of engineering maturity, they might take shortcuts, such as not automating tests for new user workflows or not following the “boy-scout rule” (leaving the code better than they found it). Over time, this leads to a breakdown of trust between teams as technical debt increases and slows down delivery speed.
A lack of ownership over shared code may result from the cumulative effects of several teams working on the same codebase unless inter-team discipline is high.
Around 2015, Ericsson moved to a DevOps approach to building and running software for emerging telecom business areas, such as “Software-Defined Networking” or “Network Functions Virtualization.”7 Teams in this space became responsible for developing and supporting their software in production.
Some of Ericsson’s large-scale projects, comprised of multiple subsystems, require teams working across multiple sites. Each team is composed of five to nine members, and a single subsystem might be developed by multiple teams. However, teams must include all the core capabilities/roles to develop and maintain their own features in a largely independent fashion. Occasionally, very large features are worked on simultaneously by a few colocated teams, acting as a single, larger feature team.
However, while inter-team communication and dependencies were greatly reduced with teams working on intra-subsystem features, someone still had to keep oversight of the system as a whole and ensure subsystems integrated and interacted according to the desired user experience, performance, and reliability. Therefore, specific roles were created, such as system architects, system owners, or integration leads. Crucially, people in these roles work across the entire project/organization sort of like “communication conduits,” with direct and frequent interaction with feature teams. They support them on cross-subsystem concerns (such as interfaces and integration) to allow them to maintain a regular feature delivery cadence.
Product Teams Need a Support System
Product teams (identical in purpose and characteristics to a feature team but owning the entire set of features for one or more products) still depend on infrastructure, platform, test environments, build systems, and delivery pipelines (and more) for their work to become available to end users. They might have full control over some of these dependencies, but they will likely need help with others due to the natural cognitive and expertise limits of a team (as explained in Chapter 3).
The key for the team to remain autonomous is for external dependencies to be non-blocking, meaning that new features don’t sit idle, waiting for something to happen beyond the control of the team. For example, it’s extremely difficult to ensure that a separate QA team will be available to evaluate a new feature exactly when the product team finishes it. Teams have different workloads, priorities, and problems; and generally, there’s too much uncertainty in building and running software systems for a pre-defined schedule to succeed in coordinating multiple teams on the same stream of work. Insisting on this approach inevitably leads to wait times and delays.
Non-blocking dependencies often take the form of self-service capabilities (e.g., around provisioning test environments, creating deployment pipelines, monitoring, etc.) developed and maintained by other teams. These can be consumed independently by the product teams when they need them.
For example, Microsoft has been using product teams since the 1980s. With the availability of Azure as an IaaS and PaaS solution for Microsoft products and services, teams within Microsoft are able to consume infrastructure and platform features “as a service.” This allows teams to significantly increase delivery speed. In particular, the teams building the Visual Studio product have undergone a radical transformation from a desktop-first, multi-month delivery cycle, to a cloud-first, daily/weekly delivery cycle.8
Creating product teams without a compatible support system, consisting of easy-to-consume services (preferably via a platform-oriented approach) and readily available expertise for tasks that the team is unfamiliar with, creates more bottlenecks. Product teams end up frequently waiting on “hard dependencies” to functional teams (such as infrastructure, networking, QA). There is increased friction as product teams are pressured to deliver faster, but they are part of a system that does not support the necessary levels of autonomy.
Cloud Teams Don’t Create Application Infrastructure
Cloud teams that are, for the most part, a rebranding of traditional infrastructure teams will fail to take advantage of the speed and scalability that the cloud offers. If the cloud team simply mimics the current behaviors and infrastructure processes, the organization will incur the same delays and bottlenecks for software delivery as before.
Product teams need autonomy to provision their own environments and resources in the cloud, creating new images and templates where necessary. The cloud team might still own the provisioning process—ensuring that the necessary controls, policies, and auditing are in place (especially in highly regulated industries)—but their focus should be in providing high-quality self-services that match both the needs of product teams and the need for adequate risk and compliance management.
In other words, there needs to be a split between the responsibility of designing the cloud infrastructure process (by the cloud team) and the actual provisioning and updates to application resources (by the product teams).
SRE Makes Sense at Scale
Site Reliability Engineering is an approach to the operation and improvement of software applications pioneered by Google to deal with their global, multi-million-user systems. If adopted in full, SRE is significantly different from IT operations of the past, due to its focus on the “error budget” (namely defining what is an acceptable amount of downtime) and the ability of SRE teams to push back on poor software.
People on SRE teams need excellent coding skills and—crucially—a strong drive (and bandwidth) to automate repetitive Ops tasks using code, thereby continually reducing toil. Ben Treynor, Vice President of Engineering at Google, said that SRE is “what happens when you ask a software engineer to design an operations function.”9
The SRE model sets up a healthy and productive interaction between the development and SRE teams by using service-level objectives (SLOs) and error budgets to balance the speed of new features with whatever work is needed to make the software reliable.
TIP
SRE teams are not essential; they are optional.
That’s right: not every development team at Google uses SRE. “Downscale the SRE support if your project is shrinking in scale, and finally let your development team own the SRE work if the scale doesn’t require SRE support,” said Jaana B. Dogan, SRE at Google.10
The SRE approach is a highly dynamic approach to building and running large-scale software systems. The SRE team has several different interactions with application development teams at different times, depending on various factors: how many users the software application has, how reliable the software is, how available the software needs to be from a product perspective, etc. Figure 4.3 illustrates this.
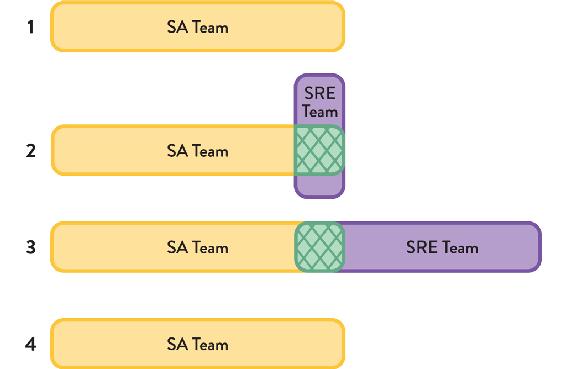
Figure 4.3: Relationship between SRE Team and Application Team
SRE teams have a strong relationship with one or more application-development team, a kind of affinity. In this respect, we can see the SRE model as a special kind of stream-aligned team.
The relationship between an SRE team and an application-development team changes at different points of the software’s life and even month by month. Initially (#1 in Figure 4.3), the application development team alone builds and runs the software in production until the scale merits SRE help. During a second stage (#2 in Figure 4.3), as the application usage increases, SRE provides guidance (represented in green) to the application development team on how to make the application work better at global scale. Later, SRE becomes fully involved by running and supporting the application (but still collaborating with the application team) when the scale merits it (#3 in Figure 4.3). At this point, the product owner for the application must decide a suitable service-level objective with a corresponding error budget. If at some point (#4 in Figure 4.3) the application becomes too difficult to support due to lack of operability, or if the application usage drops off, the application team takes on operational responsibility again. If the application’s operability improves sufficiently (to meet the error budget) and application usage also increases, the relationship might go back to stage #3.
The dynamic interaction between SRE and application-development teams is part of what makes the SRE approach work so well for Google and similar organizations: it recognizes that building and running software systems is a sociotechnical activity, not an assembly line in a factory.
The SRE model is not an easy option, however. Dave Rensin, Director of Customer Reliability Engineering at Google Cloud, says “achieving Google-class operational rigor requires a sustained commitment on your part.”11 SRE is a dynamic balance between a commitment to operability from the application-development team and expertise from the SRE team. Without a high degree of engineering discipline and commitment from management, this fine balance in SRE can easily degrade into a traditional “us and them” silo that leads to repeated service outages and mistrust between teams.
Considerations When Choosing a Topology
An organization’s context influences the successful setup of certain types of teams, as is apparent from the many team-structure examples we just provided. Next, we will outline different factors to take into account when selecting a topology.
Technical and Cultural Maturity
Organizations at different stages of technical and cultural maturity will find different team structures to be effective. For example, by 2013, both Amazon and Netflix had a well-established strategy, using cross-functional teams with end-to-end responsibility for the services they provided to the rest of the organization.12
Meanwhile, traditional organizations adopting Agile—moving to smaller batches of delivery—often lacked the mature engineering practices required to keep a sustainable pace over time (such as automated testing, deployment, or monitoring). They could benefit from a temporary DevOps team with battle-tested engineers to bring in expertise and, more importantly, bring teams together by collaborating on shared practices and tools.
However, without a clear mission and expiration date for such a DevOps team, it’s easy to cross the thin line between this pattern and the corresponding anti-pattern of yet another silo (DevOps team) with compartmentalized knowledge (such as configuration management, monitoring, deployment strategies, and others) in the organization.
On the other hand, for a large enterprise where successful DevOps adoption across the board requires both top-down and bottom-up alignment, it makes sense to invest in a team of DevOps evangelists that raise awareness and are vocal about initial achievements in other parts of the organization.
Organization Size, Software Scale, and Engineering Maturity
As we’ve seen, choosing a good team topology is highly dependent on the situational context of the organization and teams within it. At the very least, organization size (or software scale) and engineering maturity should influence which topologies are chosen in a DevOps context, as shown in Figure 4.4.
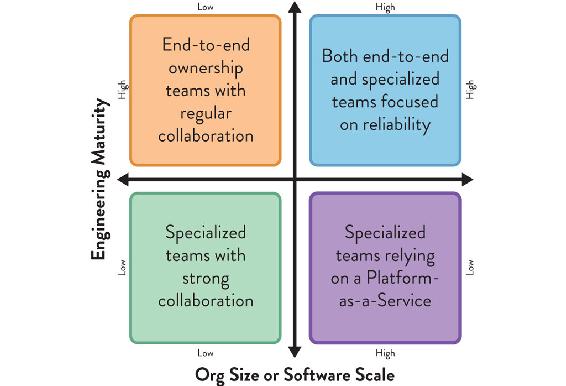
Figure 4.4: Influence of Size and Engineering Maturity on Choice of Topologies
Organization size (or software scale) and engineering discipline influence the effectiveness of team interaction patterns.
Low maturity organizations will need time to acquire the engineering and product development capabilities required for autonomous end-to-end teams. Meanwhile, more specialized teams (development, operations, security, and others) are an acceptable trade-off, as long as they collaborate closely to minimize wait times and quickly address issues. For a moderate scale of organization or software, patterns that emphasize close collaboration between teams at speed work well. As the size of the organization or software scale increases, focusing on providing the underlying infrastructure or platform as a service brings important benefits in terms of user-facing service reliability and the ability to meet customer expectations. If the organization has a high level of engineering maturity and discipline, then the SRE model described earlier may be effective at scale as well.
Splitting Responsibilities to Break Down Silos
Sometimes we can remove or lessen dependencies on specific teams by breaking down their set of responsibilities and empowering other teams to take some of them on. For example, a pattern increasingly adopted in many organizations over the past few years has been to separate the activities of database development (DB Dev) from database administration (DBA).
The activities of DB Dev and DBA had often been joined in a functional silo of the database team, but the need for more rapid flow of change, coupled with a reduction in the use of shared databases, makes it more effective to split these roles. In practice, the DBA role typically becomes part of a platform, whether internally run or as part of a cloud provider’s Database-as-a-Service offering. (See Chapter 5 for more details about platforms.)
All the examples we mentioned so far highlight the importance of thinking about teams’ capabilities (or lack thereof) and how that causes dependencies between teams. Instead of simply replicating teams or adding more people when workload increases, it’s important to think about which dependencies between teams we should remove and which we should explicitly accept, because we see more benefits than disadvantages. (See Chapter 5 and Chapter 7 for more details about the relationships between teams.)
Dependencies and Wait Times between Teams
To achieve teams that have well-defined responsibilities, can work independently, and are optimized for flow, it is essential to detect and track dependencies and wait times between teams. In Making Work Visible, Dominica DeGrandis recommends the use of a Physical Dependency Matrix or “dependency tags” on kanban cards to identify and track dependencies, and infer the communication needed to make these dependencies work well: “Visualizing important cross-team information helps communicate across teams.”13
In their 2012 paper, “A Taxonomy of Dependencies in Agile Software Development,” Diane Strode and Sid Huff propose three different categories of dependency: knowledge, task, and resource dependencies.14 Such a taxonomy can help pinpoint dependencies between teams and the potential constraints to the flow of work ahead of time.
Whichever tool is used, it is important to track the number of dependencies per area, and to establish thresholds and alerts that are meaningful for a particular situation. The number of dependencies should not be allowed to increase unchecked. Instead, such an increase should trigger adjustments in the team design and dependencies.
TIP
Detect and track interdependencies.
Spotify relies on a simple spreadsheet to detect and track interdependencies between squads and tribes. It highlights whether a dependency is on a squad within the same tribe (acceptable) or in a different tribe (potentially a warning that team design or work assignment is wrong). The tool also tracks how soon the dependency will impact the flow of the depending team.
Using DevOps Topologies to Evolve the Organization
So far we’ve addressed multiple aspects that impact the effectiveness of certain topologies at a given point in time. But organizations, teams, and strategies change over time, either via an intentional course of action (e.g., DevOps dojos to improve teams’ cultural and engineering maturity) or due to changes in markets and technology.
While many organizations looked at the DevOps Topologies catalog for “snapshot” advice on effective team structures, some went a couple of steps further by thinking of an evolutionary path, from a topology that makes the most sense in today’s context to an end goal that matches expected changes in organizational capabilities and constraints.
What follows are a couple of industry examples of DevOps transformations strongly influenced by evolving DevOps Topologies over time to adapt to new contexts.
Pulak Agrawal, Continuous Delivery Architext, and Jonathan Hammant, UKI DevOps Lead, told us firsthand how they’ve used the DevOps Topologies patterns to evolve organizations Accenture consults for—in particular, at a healthcare client they started with a DevOps team back in April 2017. They soon realized they had fallen into an anti-pattern because the tooling expertise brought in by the DevOps team ended up in a silo.
In January 2018, they evolved their team structures in order to bring development, operations, and the DevOps tooling team closer together. Pulak described to us how this took place:
We delivered an Infrastructure as Code (IaC) project on our client’s Azure infrastructure, automatically installing, configuring, and operating an enterprise document management product. We utilized an “Ops as Infrastructure-as-a-Service” pattern for this project. This included early involvement from the Ops team who were checking in operational code and developers who focused on non-functional production requirements from day one. Individuals from the siloed tooling team from the earlier stage were present to help support the infrastructure while this happened.15
A third stage of evolution aimed to build on their earlier success and fully transition the DevOps team from an execution role to an evangelizing one, so that development and operations teams would become self-sufficient and collaborate around automation of the required steps. Pulak explained:
The [DevOps] team is now evolving into a “DevOps Evangelists team” pattern, working with the client to educate and enable the individual project teams, so they make themselves obsolete along the way. They will automate the development and operations steps, implement monitoring and alerting solutions. They will then look to make development and operations own the automation and execution of it themselves.16
In Part III of the book, we will look in more detail at the evolution of team topologies in a broader context, beyond DevOps.
CASE STUDY: EVOLUTION OF TEAM TOPOLOGIES AT TRANSUNION (PART 1)
Ian Watson, Head of DevOps, TransUnion
TransUnion (formerly Callcredit) is the UK’s second largest credit reference agency (CRA), with international offices in Spain, the US, Dubai, and Lithuania. They provide expert services for managing consumer data for businesses across every sector around the world, helping businesses and consumers make more informed, confident decisions.
Ian Watson, Head of DevOps at TransUnion from 2015 to 2018, recalls how the DevOps Topologies helped them guide their growth over time.
In 2014, our technology group within TransUnion began a major expansion to meet growing demand for software-based analytical solutions. We knew that in order to scale effectively, we had to consider the interrelationships between different technology teams. We turned to the DevOps Topologies patterns to help us plan out our digital transformation. We wanted to bring development (Dev) and operations (Ops) closer together but avoid a separate “DevOps team.” Instead, we adopted a hybrid model, with two temporary DevOps teams collaborating to help bring Dev and Ops together over time.
We realized that our DevOps journey at TransUnion needed to be based on the evolution of team relationships, not a static reconfiguration. The DevOps Topologies patterns helped us to reason about how our digital transformation would happen and accelerated our adoption of cloud technologies and automation approaches. The patterns helped us avoid some pitfalls, like a separate DevOps team, and helped define team responsibilities more effectively. We’ve been able to scale our technology division significantly over the past four years, with great results.
Summary: Adopt and Evolve Team Topologies that Match Your Current Context
Setting up new team structures and responsibilities reactively, triggered by the need to scale a product, adopt new technologies, or respond to new market demands, can help in the present moment but often fails to achieve the speed and efficiency of well thought-out topologies.
Because those decisions are often made on an individual team basis, they lack consideration for important organization-wide factors, like technical and cultural maturity, organization size, scale of the software, engineering disciple, or inter-team dependencies. The result is team structures optimized for problems that are temporary or limited in scope, rather than adaptive to new problems over time.
The “DevOps team” anti-pattern is a quintessential example. On paper, it makes sense to bring automation and tooling experts in house to accelerate the delivery and operations of our software. However, this team can quickly become a hard dependency for application teams if the DevOps team is being asked to execute steps on the delivery path of every application, rather than helping to design and build self-service capabilities that application teams can rely on autonomously.
It is critical to explicitly consider the different aspects at play and adopt topologies that work given the organizational context (which tends to evolve slowly), rather than adapting those that solve a particular problem or need in a given moment in time.
In particular, within a DevOps context the DevOps Topologies can help shed some light on which topologies work well for which contexts. Forward-thinking organizations take a multi-stage approach to their team design, understanding that what works best today might not necessarily be the case in a few years, or even months from now.