Chapter 2. Principles of Cloud Age Infrastructure
Computing resources in the Iron Age of IT were tightly coupled to physical hardware. We assembled CPUs, memory, and hard drives in a case, mounted it into a rack, and cabled it to switches and routers. We installed and configured an operating system and application software. We could describe where an application server was in the data center: which floor, which row, which rack, which slot.
The Cloud Age decouples the computing resources from the physical hardware they run on. The hardware still exists, of course, but servers, hard drives, and routers float across it. These are no longer physical things, having transformed into virtual constructs that we create, duplicate, change, and destroy at will.
This transformation has forced us to change how we think about, design, and use computing resources. We can’t rely on the physical attributes of our application server to be constant. We must be able to add and remove instances of our systems without ceremony, and we need to be able to easily maintain the consistency and quality of our systems even as we rapidly expand their scale.
There are several principles for designing and implementing infrastructure on cloud platforms. These principles articulate the reasoning for using the three core practices (define everything as code, continuously test and deliver, build small pieces). I also list several common pitfalls that teams make with dynamic infrastructure.
These principles and pitfalls underlie more specific advice on implementing Infrastructure as Code practices throughout this book.
Principle: Assume Systems Are Unreliable
In the Iron Age, we assumed our systems were running on reliable hardware. In the Cloud Age, you need to assume your system runs on unreliable hardware.1
Cloud scale infrastructure involves hundreds of thousands of devices, if not more. At this scale, failures happen even when using reliable hardware—and most cloud vendors use cheap, less reliable hardware, detecting and replacing it when it breaks.
You’ll need to take parts of your system offline for reasons other than unplanned failures. You’ll need to patch and upgrade systems. You’ll resize, redistribute load, and troubleshoot problems.
With static infrastructure, doing these things means taking systems offline. But in many modern organizations, taking systems offline means taking the business offline.
So you can’t treat the infrastructure your system runs on as a stable foundation. Instead, you must design for uninterrupted service when underlying resources change.2
Principle: Make Everything Reproducible
One way to make a system recoverable is to make sure you can rebuild its parts effortlessly and reliably.
Effortlessly means that there is no need to make any decisions about how to build things. You should define things such as configuration settings, software versions, and dependencies as code. Rebuilding is then a simple “yes/no” decision.
Not only does reproducibility make it easy to recover a failed system, but it also helps you to:
-
Make testing environments consistent with production
-
Replicate systems across regions for availability
-
Add instances on demand to cope with high load
-
Replicate systems to give each customer a dedicated instance
Of course, the system generates data, content, and logs, which you can’t define ahead of time. You need to identify these and find ways to keep them as a part of your replication strategy. Doing this might be as simple as copying or streaming data to a backup and then restoring it when rebuilding. I’ll describe options for doing this in “Data Continuity in a Changing System”.
The ability to effortlessly build and rebuild any part of the infrastructure is powerful. It removes risk and fear of making changes, and you can handle failures with confidence. You can rapidly provision new services and environments.
Pitfall: Snowflake Systems
A snowflake is an instance of a system or part of a system that is difficult to rebuild. It may also be an environment that should be similar to other environments, such as a staging environment, but is different in ways that its team doesn’t fully understand.
People don’t set out to build snowflake systems. They are a natural occurrence. The first time you build something with a new tool, you learn lessons along the way, which involves making mistakes. But if people are relying on the thing you’ve built, you may not have time to go back and rebuild or improve it using what you learned. Improving what you’ve built is especially hard if you don’t have the mechanisms and practices that make it easy and safe to change.
Another cause of snowflakes is when people make changes to one instance of a system that they don’t make to others. They may be under pressure to fix a problem that only appears in one system, or they may start a major upgrade in a test environment, but run out of time to roll it out to others.
You know a system is a snowflake when you’re not confident you can safely change or upgrade it. Worse, if the system does break, it’s hard to fix it. So people avoid making changes to the system, leaving it out of date, unpatched, and maybe even partly broken.
Snowflake systems create risk and waste the time of the teams that manage them. It is almost always worth the effort to replace them with reproducible systems. If a snowflake system isn’t worth improving, then it may not be worth keeping at all.
The best way to replace a snowflake system is to write code that can replicate the system, running the new system in parallel until it’s ready. Use automated tests and pipelines to prove that it is correct and reproducible, and that you can change it easily.
Principle: Create Disposable Things
Building a system that can cope with dynamic infrastructure is one level. The next level is building a system that is itself dynamic. You should be able to gracefully add, remove, start, stop, change, and move the parts of your system. Doing this creates operational flexibility, availability, and scalability. It also simplifies and de-risks changes.
Making the pieces of your system malleable is the main idea of cloud native software. Cloud abstracts infrastructure resources (compute, networking, and storage) from physical hardware. Cloud native software completely decouples application functionality from the infrastructure it runs on.3
Cattle, Not Pets
“Treat your servers like cattle, not pets,” is a popular expression about disposability.4 I miss giving fun names to each new server I create. But I don’t miss having to tweak and coddle every server in our estate by hand.
If your systems are dynamic, then the tools you use to manage them need to cope with this. For example, your monitoring should not raise an alert every time you rebuild part of your system. However, it should raise a warning if something gets into a loop rebuilding itself.
Principle: Minimize Variation
As a system grows, it becomes harder to understand, harder to change, and harder to fix. The work involved grows with the number of pieces, and also with the number of different types of pieces. So a useful way to keep a system manageable is to have fewer types of pieces—to keep variation low. It’s easier to manage one hundred identical servers than five completely different servers.
The reproducibility principle (see “Principle: Make Everything Reproducible”) complements this idea. If you define a simple component and create many identical instances of it, then you can easily understand, change, and fix it.
To make this work, you must apply any change you make to all instances of the component. Otherwise, you create configuration drift.
Here are some types of variation you may have in your system:
-
Multiple operating systems, application runtimes, databases, and other technologies. Each one of these needs people on your team to keep up skills and knowledge.
-
Multiple versions of software such as an operating system or database. Even if you only use one operating system, each version may need different configurations and tooling.
-
Different versions of a package. When some servers have a newer version of a package, utility, or library than others, you have risk. Commands may not run consistently across them, or older versions may have vulnerabilities or bugs.
Organizations have tension between allowing each team to choose technologies and solutions that are appropriate to their needs, versus keeping the amount of variation in the organization to a manageable level.
Lightweight Governance
Modern, digital organizations are learning the value of Lightweight Governance in IT to balance autonomy and centralized control. This is a key element of the EDGE model for agile organizations. For more on this, see the book, EDGE: Value-Driven Digital Transformation by Jim Highsmith, Linda Luu, and David Robinson (Addison-Wesley Professsional), or Jonny LeRoy’s talk, “The Goldilocks Zone of Lightweight Architectural Governance”.
Configuration Drift
Configuration drift is variation that happens over time across systems that were once identical. Figure 2-1 shows this. Manually making changes can cause configuration drift. It can also happen if you use automation tools to make ad hoc changes to only some of the instances. Configuration drift makes it harder to maintain consistent automation.
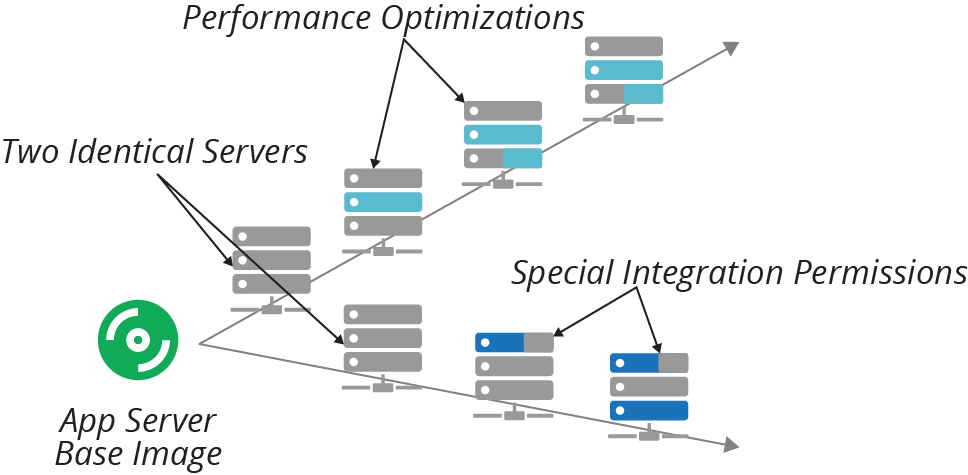
Figure 2-1. Configuration drift is when instances of the same thing become different over time
As an example of how infrastructure can diverge over time, consider the journey of our example team, ShopSpinner.5
ShopSpinner runs a separate instance of its application for each store, with each instance configured to use custom branding and product catalog content. In the early days, the ShopSpinner team ran scripts to create a new application server for each new store. The team managed the infrastructure manually or by writing scripts and tweaking them each time it needed to make a change.
One of the customers, Water Works,6 has far more traffic to its order management application than the others, so the team tweaked the configuration for the Water Works server. The team didn’t make the changes to the other customers, because it was busy and it didn’t seem necessary.
Later, the ShopSpinner team adopted Servermaker to automate its application server configuration.7 The team first tested it with the server for Palace Pens,8 a lower-volume customer, and then rolled it out to the other customers. Unfortunately, the code didn’t include the performance optimizations for Water Works, so it stripped those improvements. The Water Works server slowed to a crawl until the team caught and fixed the mistake.
The ShopSpinner team overcame this by parameterizing its Servermaker code. It can now set resource levels different for each customer. This way, the team can still apply the same code across every customer, while still optimizing it for each. Chapter 7 describes some patterns and antipatterns for parameterizing infrastructure code for different instances.
Principle: Ensure That You Can Repeat Any Process
Building on the reproducibility principle, you should be able to repeat anything you do to your infrastructure. It’s easier to repeat actions using scripts and configuration management tools than to do it by hand. But automation can be a lot of work, especially if you’re not used to it.
For example, let’s say I have to partition a hard drive as a one-off task. Writing and testing a script is much more work than just logging in and running the fdisk command. So I do it by hand.
The problem comes later on, when someone else on my team, Priya, needs to partition another disk. She comes to the same conclusion I did, and does the work by hand rather than writing a script. However, she makes slightly different decisions about how to partition the disk. I made an 80 GB /var ext3 partition on my server, but Priya made /var a 100 GB xfs partition on hers. We’re creating configuration drift, which will erode our ability to automate with confidence.
Effective infrastructure teams have a strong scripting culture. If you can script a task, script it.9 If it’s hard to script it, dig deeper. Maybe there’s a technique or tool that can help, or maybe you can simplify the task or handle it differently. Breaking work down into scriptable tasks usually makes it simpler, cleaner, and more reliable.
Conclusion
The Principles of Cloud Age Infrastructure embody the differences between traditional, static infrastructure, and modern, dynamic infrastructure:
-
Assume systems are unreliable
-
Make everything reproducible
-
Create disposable things
-
Minimize variation
-
Ensure that you can repeat any action
These principles are the key to exploiting the nature of cloud platforms. Rather than resisting the ability to make changes with minimal effort, exploit that ability to gain quality and reliability.
1 I learned this idea from Sam Johnson’s article, “Simplifying Cloud: Reliability”.
2 The principle of assuming systems are unreliable drives chaos engineering, which injects failures in controlled circumstances to test and improve the reliability of your services. I talk about this more in “Chaos Engineering”.
3 See “Cloud Native and Application-Driven Infrastructure”.
4 I first heard this expression in Gavin McCance’s presentation “CERN Data Centre Evolution”. Randy Bias credits Bill Baker’s presentation “Architectures for Open and Scalable Clouds”. Both of these presentations are an excellent introduction to these principles.
5 ShopSpinner is a fictional company that allows businesses to set up and run online stores. I’ll be using it throughout the book to illustrate concepts and practices.
6 Water Works sends you bottles of a different craft drinking water every month.
7 Servermaker is a fictional server configuration tool, similar to Ansible, Chef, or Puppet.
8 Palace Pens sells the world’s finest luxury writing utensils.
9 My colleague Florian Sellmayr says, “If it’s worth documenting, it’s worth automating.”