Chapter 21. Governance
Governance, compliance, and security are not topics that can be added after a system is built; they must be built into its foundations. Don’t be misled by this chapter being the last in this book, as these topics are woven throughout the preceding chapters. Governance and related concerns are key design forces guiding decisions about how to organize infrastructure into components and delivery workflows.
Automating delivery and testing with pipelines creates opportunities to continually validate the integrity and compliance of the system. Good automation makes governance an inherent, natural part of workflows for frequently and quickly improving and evolving a system, rather than an opposing force that slows delivery.
The purpose of this chapter is to step back and consider how governance works when infrastructure is managed using code with a continual, Agile approach.
Governance is about making sure the system we built is built right. This process includes quality and correctness, as well as operational qualities like performance, cost, capacity, and reliability. An organization can set architectural guidelines and policies that systems need to meet. Standards bodies define requirements for certifications like PCI. Government regulators impose legal requirements for general areas like privacy, and for domains including finance and healthcare.
But governance should not stop at meeting the letter of standards and regulations. It’s important to keep the underlying intention of governance requirements in mind, whether the intention is protecting users’ safety, money, or data, or ensuring that a system can be scaled and maintained cost-effectively.
Although good governance starts with designing and building elements of the system to support various requirements, guaranteeing that the system is safe and reliable isn’t possible. Some of the steps we can take to strengthen compliance include the following:
-
Continually validate each change to the system by default, without relying on humans to spend the time and attention needed.
-
Continually and automatically validate the compliance of the live system.
-
Continually and automatically monitor activities on the live system.
-
Provide visibility into the operation of the system for people to investigate incidents and issues.
-
Provide safe, routine processes to quickly and reliably deliver corrections, fixes, and improvements to the system.
-
Record changes and activities so we can easily provide the evidence needed for audits and certifications.
The normal workflow for delivering changes to production should be fast enough to get a fix through in an emergency. If the pipeline takes too long, people will be tempted to bypass it to make fixes manually, which often leads to mistakes. Even having a special, “emergency fix” process typically means relaxing controls, creating an opportunity for errors or noncompliant changes. A useful exercise is to design the most stripped-down, minimal process to reliably deliver changes that meet governance requirements, and make that your default. If a process is good enough and safe enough to use in an emergency, it should be good enough and safe enough to use every day.
Two key ideas of compliance and governance in the modern Cloud Age are shift left and compliance as code. I’ll discuss each of these next. I’ll finish the chapter with a discussion of how to implement governance within a composable infrastructure architecture and CD workflow.
Shift Left
Shifting left describes the principle of ensuring that compliance, security, quality, and other governance concerns are addressed as early as possible in the workflow for making a change. People who make a change, whether developers or infrastructure engineers, are empowered and responsible for validating that their changes are compliant so that they can immediately correct any conflicts. Shifting left extends the concepts of TDD and “building quality in” to all aspects of governance.
Workflow for Shifting Left
Left refers to diagrams that show the steps in a workflow running from left to right, as the workflow diagrams in this book do. Figure 21-1 is a traditional workflow, where checks such as security reviews, penetration tests, and other assessments are carried out only after all the developers’ work is complete, at the right end of the process flow.
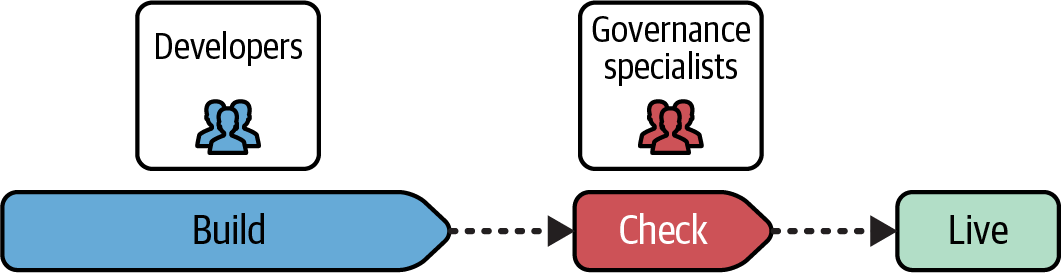
Figure 21-1. In a traditional workflow, governance checks are carried out late in the process
In this flow, compliance checks are often done manually by a separate team of specialists who are not involved in building the system. This division of responsibility often means developers and other engineers don’t have much understanding of or responsibility for the security and compliance implications of the decisions they make when implementing the system, encouraging the attitude that it’s not their problem.
The workflow in Figure 21-2 carries out all possible checks during the development process, following CD principles described in Chapter 14. Infrastructure developers run tests as they work, and each change they commit to source control is run through automated checks in the pipeline, including security scans and policy validations.
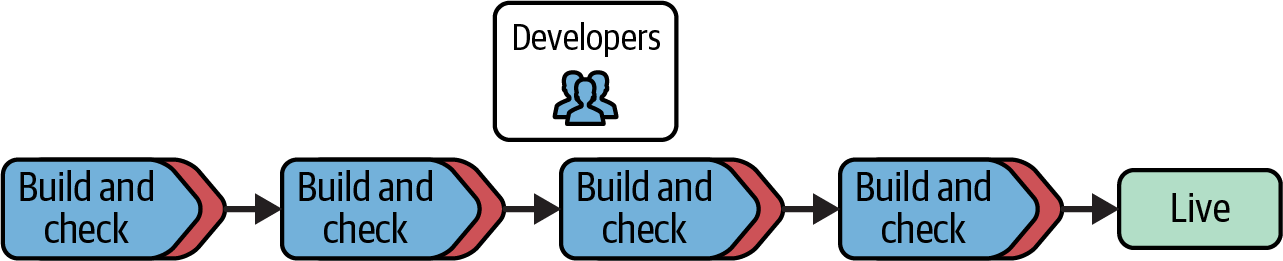
Figure 21-2. Workflow that shifts governance left into the build process
One of the advantages of shifting governance left is that developers are given immediate feedback when they make a change that violates compliance policies or security rules, so they can correct it immediately. The longer the feedback loop is to check whether a change is compliant, the more difficult it is to correct the issue. More changes may have been implemented on top of the noncompliant one, which means more work needs to be redone. In some cases, making code changes compliant may need not just a reimplementation but a redesign of the solution. When compliance issues are found late in the process, the amount of rework needed to properly fix the issues often leads to a decision to quickly implement less effective workarounds and then release “at risk.”
Team Topologies for Shifting Left
People who work in governance roles like security may wonder where they fit in a process that expects developers to build quality and compliance into their code and that largely automates validations. Governance specialists are used to acting as gatekeepers for every change. Figure 21-3 shows several ways that governance stakeholders can support stream-aligned software and infrastructure development teams.
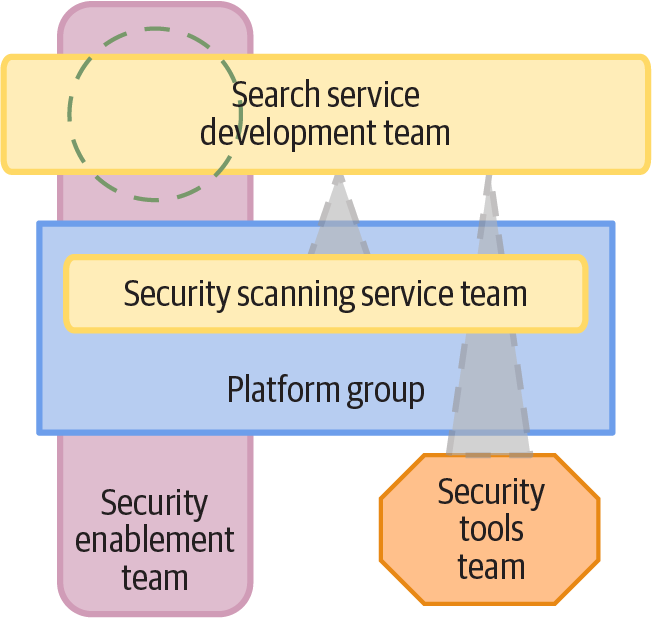
Figure 21-3. Team topologies for compliance enablement and tool teams
This topology shows three team interactions for the FoodSpin search service development team. In practice, a single security governance team could provide all three of these interactions. The security enablement team interaction involves supporting the search service team, to help that team implement its code securely. This support could include training, documentation, and collaborating to implement trickier aspects of the search service.
The security scanning service team provides tools that the development team uses in its pipeline to automatically scan code for security issues, vulnerabilities in dependencies, and automated penetration testing.
The security research team interaction handles special situations, such as researching and implementing security controls for new services. For example, the FoodSpin search service team develops a new generative AI chatbot to help users choose restaurants and menu items. The FoodSpin developers haven’t worked with generative AI before, so the security team works to understand its risks and develop approaches to managing those risks. Over time the work of this team will make its way into tools and services provided by a stream-aligned platform team.
Collaboration among development, infrastructure, and governance teams is sometimes referred to as DevSecOps. The underlying idea of DevSecOps is that, like DevOps, teams should jointly own responsibility for governance rather than treating it as a siloed concern of a single team.
A typical challenge to shifting governance left is that it places trust in developers. It’s essential to implement automated policy checks throughout the delivery lifecycle, using the pipeline and the deployment platform and services. Automation should ensure that no code change is deployed without appropriate controls and approvals. Automated systems should also log changes to provide a clear and irrefutable audit trail for every change.
Compliance as Code
Compliance as code, or policy as code, leverages automation and more collaborative working practices to support short feedback loops for shifting left.1 Compliance controls are defined using code and automatically applied in delivery pipelines. A given compliance control may be used to detect, prevent, or correct violations:
- Detection controls
-
A detection control reports when a violation has occurred or has potentially occurred, so that a human can take action. Detection controls are useful for actions that can’t be automatically prevented, or where automatically attempting to correct the violation could be harmful. For example, one financial services client automatically blocked access to a critical backend system when hacking attempts were detected. This measure gave attackers an easy way to inflict a denial-of-service attack on the bank, interrupting the business without needing to succeed in breaking into the system. The bank switched to logging and reporting attempted attacks so InfoSec staff could decide how to respond.
- Prevention controls
-
A prevention control disallows a noncompliant action. An automated check may stop the deployment of code to a live system if the check discovers code that contains a known security issue, for example.
- Correction controls
-
A correction control combines detection with an automated response. For example, an unauthorized user account might be automatically removed or disabled when discovered on a server. Correction controls should be combined with logging and reporting, especially when they are triggered repeatedly.
In addition to these three types of controls, a control is implemented and provisioned across two dimensions: the component layer and the workflow stage.
Controls by Component Design Layer
A control is implemented at a particular layer of the infrastructure design. Chapter 6 described a design approach that drives different layers of deployed infrastructure components from the workload (see “Reference Application-Driven Infrastructure Design”). Figure 21-4 shows that controls may be applied at various layers.
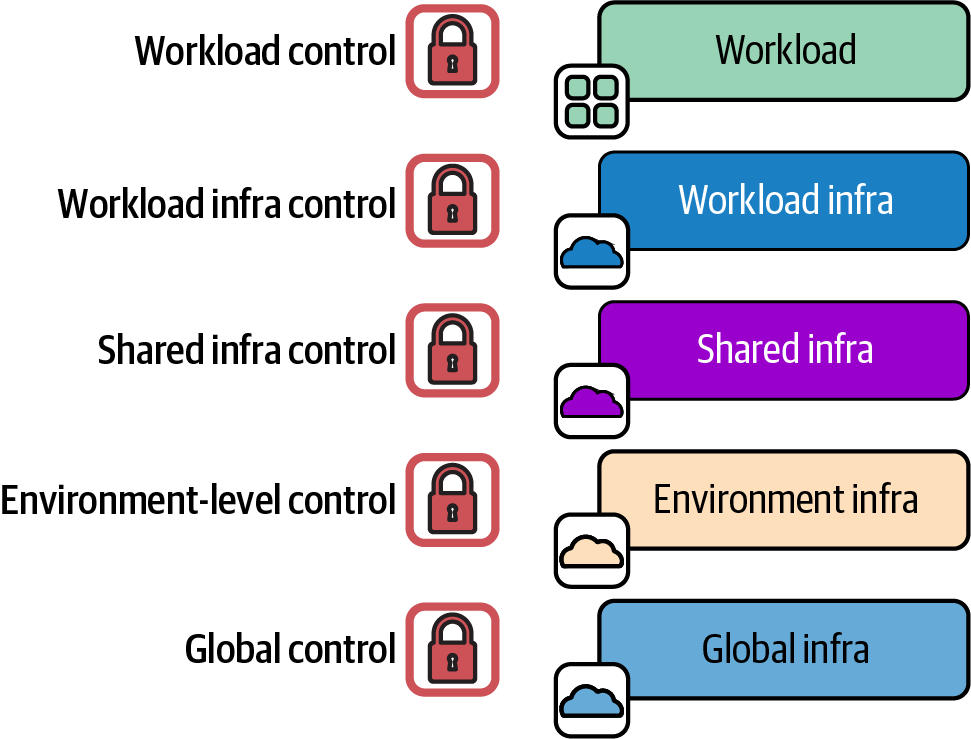
Figure 21-4. Policy controls applied at various levels of the infrastructure design
As a rule of thumb, controls at the lower level are broadly scoped restrictions, while controls at higher levels (more specific to the workloads) tend to define specific exceptions. For example, inbound network traffic may be denied on all ports as a global control, and then allowed on port 443 (HTTPS) as a workload infrastructure control. This keeps to the principle of implementation at the most specific level. It also follows the principle of keeping lower levels of infrastructure implementation tied to the specific higher-level components that depend on them.
Controls by Workflow
A compliance control may be implemented at one of several points in the code workflow, as shown in Figure 21-5.
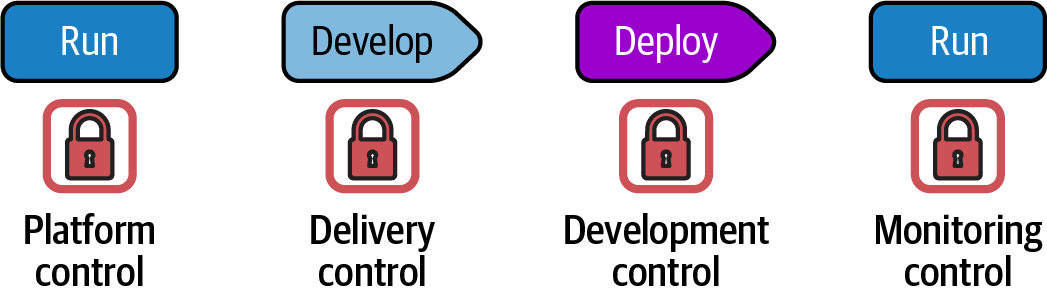
Figure 21-5. Policy controls implemented at various points in the workflow
Controls have four types based on where they are implemented in the workflow:
- Platform control
-
A platform control is usually infrastructure code that deploys and configures policies and other controls supported by the IaaS platform itself. For example, an IaaS platform policy may be used to restrict who is authorized to make changes to certain types of infrastructure resources. A platform control is implemented in a deployable infrastructure code component, and should be tested, delivered, and deployed just like any other infrastructure code. Automated tests may validate that the control works as expected—for example, attempting to carry out a restricted action and failing if the action is allowed. Platform controls should be applied consistently to all environments, not only to production, so that issues are discovered as early as possible in the workflow.
- Delivery control
-
A delivery control is an automated test that runs in the delivery pipeline for an infrastructure component to validate that code changes comply with relevant policies. One example is static analysis that checks for unsafe code. Another delivery control might check libraries and other dependencies against registries of versions with known security vulnerabilities. Some delivery controls are more active, attempting to prove compliant functionality. For example, a check could validate that a transaction is recorded in an audit log where required by regulations. Running these checks in test environments gives strong assurance that code is compliant before applying it into production systems.
- Deployment control
-
A deployment control runs when code is being deployed or applied to an environment. The control may block deployment if a violation is found. Or it may simply record relevant details of the changes being deployed so that it is available for any audits that may happen later. Deployment controls should be used in all environments, not only production, to ensure that issues are caught as soon as possible.
- Monitoring control
-
A monitoring control runs continuously against deployed workloads and infrastructure. It typically confirms that the system remains in compliance to protect against changes to the running system. For example, delivery and deployment checks may have validated that the infrastructure code configures the system correctly, but someone, whether deliberately or otherwise, might make a change outside of the automation that exposes a security vulnerability. A monitoring check runs out of band to ensure that the system remains in compliance after deployment.
Conclusion
Governance is a fitting way to tie together all the concepts and practices described throughout this book. Infrastructure as Code builds on and supports modern Cloud Age approaches to building IT systems, using automation to create a continual, reliable flow of improvements to digital services. Rather than viewing changes as a source of risk to be minimized, digital software delivery views change as necessary to improve the quality, reliability, and security of a system.
Infrastructure as Code, and whatever approaches may follow it, should help us as technology practitioners spend less of our time and energy on tedious, repetitive work. Instead, we should be able to build foundations that we can use to focus our efforts on work that improves value for our customers and the organizations we work for.
1 See “Compliance as Code” from Thoughtworks Decoder for guidance on compliance as code.