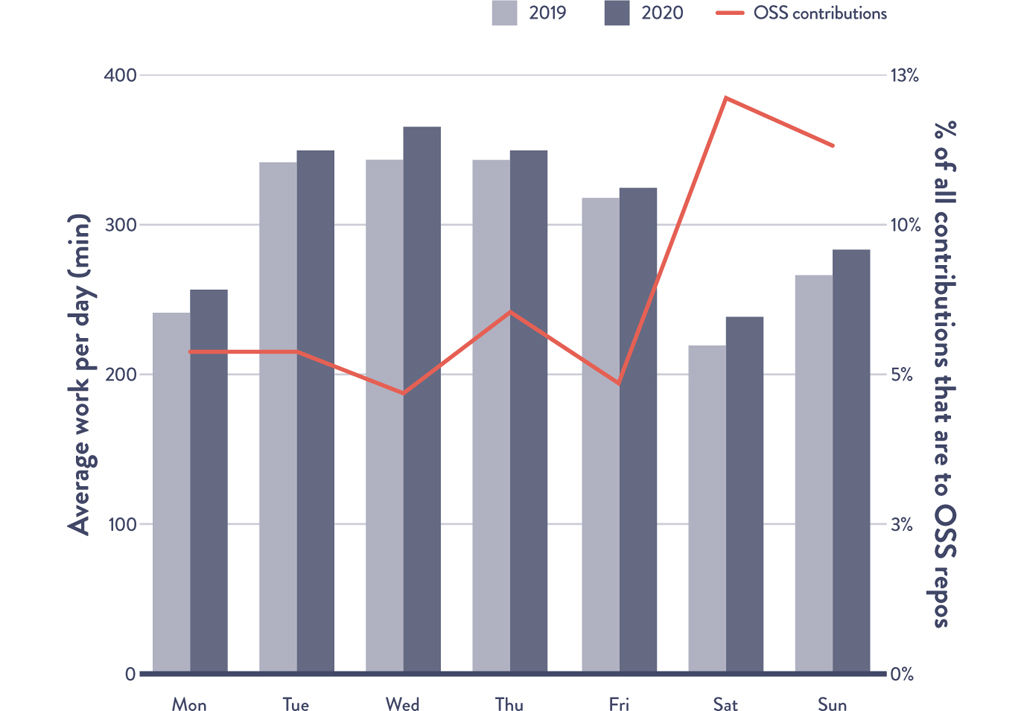
Figure AF.1: Average Development Window by Day of Week per User
Source: Forsgren et. al., 2020 State of the Octoverse.
AFTERWORD TO THE SECOND EDITION
The questions I am asked most often—by leaders and developers alike—are about productivity and performance: How can we help our teams develop and deliver software more effectively? How can we improve developer productivity? Are performance improvements sustainable, or are we simply making tradeoffs? How should we measure and track these improvements?
Data and experience have reinforced the importance of using good automation, strategic process, and a culture that prioritizes trust and information flow to help teams achieve high software delivery performance. Even during the COVID-19 pandemic, teams and organizations with smart automation, flexible processes, and good communication were able to not only survive but grow and expand, with some pivoting in just days or weeks to serve new customers and markets.
GitHub’s 2020 State of the Octoverse report found that developers spent more time at work, logging 4.2 to 4.7 more hours per day across the four time zones studied compared to the previous year.1* And developers weren’t just spreading out their work to accommodate housework or childcare; using push volume as a proxy for amount of work, the data showed that developers were also doing more. Developers pushed ten to seventeen more commits per day to their main branch during the workweek compared to a year before. Just as the data shows enterprise activity slowing on the weekend, open-source activity picks up, suggesting that developers are logging off of work and logging in to open source. Open-source project creation is up 25% since April 2020 year over year.
Figure AF.1: Average Development Window by Day of Week per User
Source: Forsgren et. al., 2020 State of the Octoverse.
While these statistics are impressive, and our ability to continue to innovate and deliver software in the face of a pandemic admirable, we must also step back to consider broader patterns. Simply pushing hard and delivering results when the conditions don’t typically allow for it can mask underlying issues.
A recent study from Microsoft reports that “high productivity is masking an exhausted workforce.”2 Those of us who have worked in technology for years may recognize the patterns and know they aren’t sustainable; true improvement and transformation requires both improvement and balance. We need to ensure that the lessons we learned from our old ways of work—long days, brute force, adrenaline-fueled delivery schedules—aren’t merely replicated now that we have better technology and methods.
The data and patterns above also highlight another important point: activity metrics like number of hours worked or number of commits don’t tell the full story. Teams and organizations that only measure productivity using these shallow metrics risk missing the full picture, one that experienced and expert technology leaders already know: productivity is complex and must be measured holistically.
Based on decades of collected expertise and research, my colleagues and I recently published the SPACE framework to help developers, teams, and leaders think about and measure productivity.3 It includes five dimensions: satisfaction and well-being, performance, activity, communication and collaboration, and efficiency and flow. By including measures across at least three dimensions in the framework, teams and organizations can measure developer productivity in ways that more accurately capture productivity, will have a better understanding of how individuals and teams work, and will have superior information to enable better decisions.
For example, if you’re already measuring commits (an activity measure), don’t simply add the number of pull requests to your metrics dashboard, as this is another activity metric. To help capture productivity, add at least one metric from two different dimensions: perhaps satisfaction with the engineering system (a satisfaction measure and an important measure of developer experience) and pull request merge time (an efficiency and flow measure). By adding these two metrics, we can now see an indication of number of commits per individual or team and pull request merge time per individual or team—as well as how those balance with development time to ensure that reviews aren’t interrupting coding time—and gain insight into how the engineering system is supporting the overall development and delivery pipeline.
We can see how this gives us much more insight than merely the number of commits and helps us make better decisions to support our development team. These metrics can also ensure more sustainable development and well-being for our developers by surfacing problems early and highlighting sustainability of our tools and inherent trade-offs our teams may be making.
As we look back over the past decade, it’s rewarding to know that our improved processes, technology, and methods of working and communicating have enabled our teams to develop and deliver software at levels we probably never imagined were possible—even in the face of daunting and unforeseen change. At the same time, it’s humbling to realize the continued (and perhaps even greater) responsibility we have to ensure our improvement journey continues. The opportunities are exciting, and we wish you well on the journey.
I continue to be so inspired by how technology leaders are creating better ways of working, enabling the creation of value sooner, safer, and happier, as framed so wonderfully by Jon Smart. And I am so delighted by how the second edition of this book contains so many new case studies (and so many of them coming from the DevOps Enterprise community). The fact that these case studies come from so many different industry verticals is another testament to the universality of the problem DevOps helps to solve.
One of the most wonderful things I’ve observed is how more and more of these experience reports are given as joint presentations between the technology leader and their business-leader counterpart, clearly articulating how the achievement of their goals, dreams, and aspirations are made possible through creating a world-class technology organization.
In one of the last pages in The Phoenix Project, the Yoda-like Erik character predicts that technology capabilities not only need to be a core competency in almost every organization but that they also need to be embedded throughout the organization, closest to where customer problems are being solved.
It’s exhilarating to see evidence of these predictions coming true, and I look forward to technology helping every organization win, fully supported by the very highest levels in the organization.
I think of DevOps as a movement of people who are working out how to build secure, rapidly changing, resilient distributed systems at scale. This movement was born from seeds planted by developers, testers, and sysadmins many years before, but really took off with the enormous growth of digital platforms. In the last five years, DevOps has become ubiquitous.
While I think we’ve learned a lot as a community over those years, I also see many of the same problems that have dogged the technology industry repeat themselves, which can basically be reduced to the fact that sustained process improvement, architectural evolution, culture change, and teamwork of the kind that produces a lasting impact is hard. It’s easier to focus on tools and organizational structure—and those things are important, but they’re not enough.
Since the book came out, I’ve used the practices we describe in the US Federal Government, in a four-person startup, and in Google. I’ve had discussions about them with people all over the world, thanks to the wonderful DevOps community. I’ve been part of a team, led by Dr. Nicole Forsgren—who I’m delighted has contributed to this second edition—that’s done world-leading research into how to build high-performing teams.
If I’ve learned anything, it’s that high performance starts with organizations whose leadership focuses on building an environment where people from different backgrounds and with different identities, experiences, and perspectives can feel psychologically safe working together, and where teams are given the necessary resources, capacity, and encouragement to experiment and learn together in a safe and systematic way.
The world is changing and evolving constantly. While organizations and teams will come and go, we in our community have the responsibility of taking care of and supporting each other and sharing what we learn. That’s the future of DevOps, and it’s also the challenge of DevOps. My deepest gratitude goes to this community, especially those of you who do the critical work of creating psychologically safe environments and welcoming and encouraging new people of all backgrounds. I can’t wait to see what you learn and share with us.
Initially, I saw DevOps as a way to improve the bottleneck between Development and Operations.
After running my own business, I understand there are many other groups in a company influencing this relationship. For example, when Marketing and Sales over-promise, this puts a lot of stress on the whole relationship. Or when HR keeps hiring the wrong people or bonuses are misaligned. This made me look at DevOps as a way of finding bottlenecks even at a higher level within a company.
Since the term was first coined, I’ve settled on my own definition of “DevOps”: everything you do to overcome the friction between silos. All the rest is plain engineering.
This definition highlights that just building technology is not enough; you need to have the intent to overcome a friction point. And that friction point will move once you have improved the blocker. This continuous evaluation of the bottleneck is crucial.
Indeed, organizations keep optimizing the pipeline/automation but don’t work on other friction points that are causing bottlenecks. This is a key challenge today. It’s interesting how concepts such as FinOps, for example, have put more pressure on collaboration, or even improvements on a personal level, to better understand and articulate what people need and want. That broader view of improvement and thinking beyond the pipeline/automation is where most people/organizations get stuck.
As we move forward, I believe we’ll keep seeing other bottlenecks being addressed under the umbrella of DevOps—DevSecOps is a good example of this, the bottleneck just moving somewhere else. I’ve seen people mention DesignOps, AIOps, FrontendOps, DataOps, NetworkOps . . . all labels to balance the attention points of things to keep in mind.
At some point, it will not matter anymore if it’s called DevOps or not. The idea that organizations must keep optimizing will just happen naturally. So I actually hope the future of DevOps is that nobody talks about the term anymore and just keeps improving the practices, mainly because we have reached peak inflation of the term.
I met Gene about ten years ago, and he told me about a book he was writing based on Dr. Eliyahu Goldratt’s, The Goal. That book was The Phoenix Project. At that time I knew very little about operations management, supply chain, and Lean. Gene had told me that he was working on another book as a follow up to The Phoenix Project that was going to be a more prescriptive work and that it was already in progress with my good friend Patrick Debois. I immediately begged to join the project, which ultimately became The DevOps Handbook. Early on we were basically focused on best-practice stories and less about the aforementioned meta concepts. Later on, Jez Humble joined the team and really added significant depth to the project in those areas.
However, to be honest, it took me over ten years to appreciate the real impact of operations management, supply chain, and Lean on what we call DevOps. The more I understand what happened in the Japanese manufacturing economy from 1950 to 1980, the more I realize the root impact on current knowledge economies. In fact, now there seems to be an interesting möbius loop between manufacturing and knowledge economy learnings. One example is autonomous vehicle production. Movements like Industrial DevOps are a great example of the loop between what we learned from manufacturing to knowledge and back to manufacturing economies.
One of the greatest challenges today is that most legacy organizations straddle two worlds. Their first-world habits are historical, systemic, and driven by calcified capital market forces. Their second-world emerging habits, like DevOps, are mostly counterintuitive to their first-world habits. Typically, these organizations struggle between their two worlds like two tectonic plates colliding, creating subduction between one and the other. These collisions tend to create temporal successes with an organization, constantly bouncing between second-world success and second-world subduction.
The good news is, the evolution of movements like Lean, Agile, DevOps, and DevSecOps seem to trend favorably toward second-world habits. Over time, organizations that embrace these new habits as a true north tend to have more successes than subductions.
One of the bright spots over the past few years has been a reductionist approach to technology. Although technology is only one of the three main principles of high performance organization success (people, process, technology), it doesn’t hurt when one of the three reduces enormous toil.
Over the past few years, we have seen less reliance on older legacy infrastructure. More than just the cloud, there is an increasing gravity to more atomic styles of computing. We see large institutions moving rapidly into cluster-based and function-style computing with an increasing emphasis on event-driven architectures (EDA). These reductionist-style technological processes leave far less room for aggregate toil across all three of the principles (people, process, technology). This, combined with the aforementioned evolutionary second-world habits, will accelerate more success than losses for larger legacy organizations.
The time zones studied were UK, US Eastern, US Pacific, and Japan Standard. |