21
RESERVE TIME TO CREATE ORGANIZATIONAL LEARNING AND IMPROVEMENT
One of the practices that forms part of the Toyota Production System is called the improvement blitz (or sometimes a kaizen blitz), defined as a dedicated and concentrated period of time to address a particular issue, often over the course of several days.1 Dr. Spear explains, “blitzes often take this form: A group is gathered to focus intently on a process with problems. . . . The blitz lasts a few days, the objective is process improvement, and the means are the concentrated use of people from outside the process to advise those normally inside the process.”2
Spear observes that the output of the improvement blitz team will often be a new approach to solving a problem, such as new layouts of equipment, new means of conveying material and information, a more organized workspace, or standardized work. They may also leave behind a to-do list of changes to be made down the road.3
Thirty-Day Challenge at Target (2015)
An example of a DevOps improvement blitz is the monthly challenge program at the Target DevOps Dojo. Ross Clanton, former Director of Operations at Target, was responsible for accelerating the adoption of DevOps. One of his primary mechanisms for this was the Technology Innovation Center, more popularly known as the DevOps Dojo.
Target’s DevOps Dojo occupies about eighteen thousand square feet of open office space, where DevOps coaches help teams from across the Target technology organization elevate the state of their practice. The most intensive format is what they call “thirty-day challenges,” where internal development teams come in for a month and work together with dedicated Dojo coaches and engineers. The team brings their work with them, with the goal of solving an internal problem they have been struggling with and creating a breakthrough in thirty days.
Throughout the thirty days, they work intensively with the Dojo coaches on the problem—planning, working, and doing demos in two-day sprints. When the thirty-day challenge is complete, the internal teams return to their lines of business, not only having solved a significant problem, but bringing their new learnings back to their teams.
Clanton described, “We currently have capacity to have eight teams doing 30-Day Challenges concurrently, so we are focused on the most strategic projects of the organization. So far, we’ve had some of our most critical capabilities come through the Dojo, including teams from Point Of Sale (POS), Inventory, Pricing, and Promotion.”4
By having full-time assigned Dojo staff and being focused on only one objective, teams going through a thirty-day challenge make incredible improvements. Ravi Pandey, a Target development manager who went through this program, explains, “In the old days, we would have to wait six weeks to get a test environment. Now, we get it in minutes, and we’re working side by side with Ops engineers who are helping us increase our productivity and building tooling for us to help us achieve our goals.”5
Clanton expands on this idea: “It is not uncommon for teams to achieve in days what would usually take them three to six months. So far, two hundred learners have come through the Dojo, having completed fourteen challenges.”6
The Dojo also supports less intensive engagement models, including flash builds, where teams come together for one- to three-day events, with the goal of shipping a minimal viable product (MVP) or a capability by the end of the event. They also host open labs every two weeks, where anyone can visit the Dojo to talk to the Dojo coaches, attend demos, or receive training.
In this chapter, we will describe this and other ways of reserving time for organizational learning and improvement, further institutionalizing the practice of dedicating time for improving daily work.
Institutionalize Rituals to Pay Down Technical Debt
In this section, we schedule rituals that help enforce the practice of reserving Dev and Ops time for improvement work, such as non-functional requirements, automation, etc. One of the easiest ways to do this is to schedule and conduct day- or week-long improvement blitzes, where everyone on a team (or in the entire organization) self-organizes to fix problems they care about—no feature work is allowed. It could be a problematic area of the code, environment, architecture, tooling, and so forth. These teams span the entire value stream, often combining Development, Operations, and Infosec engineers. Teams that typically don’t work together combine their skills and effort to improve a chosen area and then demonstrate their improvement to the rest of the company.
In addition to the Lean-oriented terms kaizen blitz and improvement blitz, the technique of dedicated rituals for improvement work has also been called spring or fall cleanings and ticket queue inversion weeks.7 Other terms have also been used, such as hack days, hackathons, and 20% innovation time. Unfortunately, these specific rituals sometimes focus on product innovation and prototyping new market ideas rather than on improvement work, and, worse, they are often restricted to developers—which is considerably different than the goals of an improvement blitz.*
Our goal during these blitzes is not to simply experiment and innovate for the sake of testing out new technologies but to improve our daily work, such as solving our daily workarounds. While experiments can also lead to improvements, improvement blitzes are very focused on solving specific problems we encounter in our daily work.
We may schedule week-long improvement blitzes that prioritize Dev and Ops working together toward improvement goals. These improvement blitzes are simple to administer: One week is selected where everyone in the technology organization works on an improvement activity at the same time. At the end of the period, each team makes a presentation to their peers that discusses the problem they were tackling and what they built. This practice reinforces a culture in which engineers work across the entire value stream to solve problems. Furthermore, it reinforces fixing problems as part of our daily work and demonstrates that we value paying down technical debt.
What makes improvement blitzes so powerful is that we are empowering those closest to the work to continually identify and solve their own problems. Consider for a moment that our complex system is like a spider web, with intertwining strands that are constantly weakening and breaking. If the right combination of strands breaks, the entire web collapses.
There is no amount of command-and-control management that can direct workers to fix each strand one by one. Instead, we must create the organizational culture and norms that lead to everyone continually finding and fixing broken strands as part of our daily work. As Dr. Spear observes, “No wonder then that spiders repair rips and tears in the web as they occur, not waiting for the failures to accumulate.”8
A great example of the success of the improvement blitz concept is described by Mark Zuckerberg, Facebook CEO. In an interview with Jessica Stillman of Inc., he says,
Every few months we have a hackathon, where everyone builds prototypes for new ideas they have. At the end, the whole team gets together and looks at everything that has been built. Many of our most successful products came out of hackathons, including Timeline, chat, video, our mobile development framework and some of our most important infrastructure like the HipHop compiler.9
Of particular interest is the HipHop PHP compiler. In 2008, Facebook was facing significant capacity problems, with over one hundred million active users and rapidly growing, creating tremendous problems for the entire engineering team.10 During a hack day, Haiping Zhao, Senior Server Engineer at Facebook, started experimenting with converting PHP code to compilable C++ code, with the hope of significantly increasing the capacity of their existing infrastructure. Over the next two years, a small team was assembled to build what became known as the HipHop compiler, converting all Facebook production services from interpreted PHP to compiled C++ binaries. HipHop enabled Facebook’s platform to handle production loads six times higher than the native PHP.11
In an interview with Cade Metz of Wired, Drew Paroski, one of the engineers who worked on the project, noted, “There was a moment where, if HipHop hadn’t been there, we would have been in hot water. We would probably have needed more machines to serve the site than we could have gotten in time. It was a Hail Mary pass that worked out.”12
Later, Paroski and fellow engineers Keith Adams and Jason Evans decided that they could beat the performance of the HipHop compiler effort and reduce some of its limitations that reduced developer productivity. The resulting project was the HipHop virtual machine project (“HHVM”), taking a just-in-time compilation approach. By 2012, HHVM had completely replaced the HipHop compiler in production, with nearly twenty engineers contributing to the project.13
By performing regularly scheduled improvement blitzes and hack weeks, we enable everyone in the value stream to take pride and ownership in the innovations they create, and we continually integrate improvements into our system, further enabling safety, reliability, and learning.
Enable Everyone to Teach and Learn
A dynamic culture of learning creates conditions so that everyone can not only learn but also teach, whether through traditional didactic methods (e.g., people taking classes, attending training) or more experiential or open methods (e.g., conferences, workshops, mentoring). One way that we can foster this teaching and learning is to dedicate organizational time to it.
Steve Farley, VP of Information Technology at Nationwide Insurance, said,
We have five thousand technology professionals, who we call “associates.” Since 2011, we have been committed to create a culture of learning—part of that is something we call Teaching Thursday, where each week we create time for our associates to learn. For two hours, each associate is expected to teach or learn. The topics are whatever our associates want to learn about—some of them are on technology, on new software development or process improvement techniques, or even on how to better manage their career. The most valuable thing any associate can do is mentor or learn from other associates.14
As has been made evident throughout this book, certain skills are becoming increasingly needed by all engineers, not just by developers. For instance, it is becoming more important for all Operations and Test engineers to be familiar with Development techniques, rituals, and skills, such as version control, automated testing, deployment pipelines, configuration management, and creating automation. Familiarity with Development techniques helps Operations engineers remain relevant as more technology value streams adopt DevOps principles and patterns.
Although the prospect of learning something new may be intimidating or cause a sense of embarrassment or shame, it shouldn’t. After all, we are all lifelong learners, and one of the best ways to learn is from our peers. Karthik Gaekwad, who was part of the National Instruments DevOps transformation, said, “For Operations people who are trying to learn automation, it shouldn’t be scary—just ask a friendly developer, because they would love to help.”15
We can further help teach skills through our daily work by jointly performing code reviews that include both parties so that we learn by doing, as well as by having Development and Operations work together to solve small problems. For instance, we might have Development show Operations how to authenticate an application and log in and run automated tests against various parts of the application to ensure that critical components are working correctly (e.g., key application functionality, database transactions, message queues). We would then integrate this new automated test into our deployment pipeline and run it periodically, sending the results to our monitoring and alerting systems so that we get earlier detection when critical components fail.
As Glenn O’Donnell from Forrester Research quipped in his 2014 DevOps Enterprise Summit presentation, “For all technology professionals who love innovating, love change, there is a wonderful and vibrant future ahead of us.”16
ASREDS Learning Loop
Humans have an innate need to belong to groups. But this instinct to belong can also be an instinct to exclude. When it comes to shared learning, this group mentality can result in learning bubbles (learning silos) or the permanent loss of institutional knowledge when people leave the group (company).
When learnings become trapped in bubbles, knowledge is hidden and different teams unnecessarily struggle with similar issues, run similar experiments, develop the same antipatterns, and fail to use each other’s learnings. In Sooner Safer Happier, the authors use the ASREDS learning loop to pop these learning bubbles.17
The loop asks teams to first Align on a goal, then Sense the context, Respond by designing one or more Experiments, Distill the results into insights and metrics, and then Share the results by publishing the learnings so others can pick them up again at Sense.
Practices like ASREDS help pop disconnected learning bubbles, and when combined with awards and Centers of Practice (see Sooner Safer Happier for more), these patterns eventually promote the creation of a learning ecosystem.
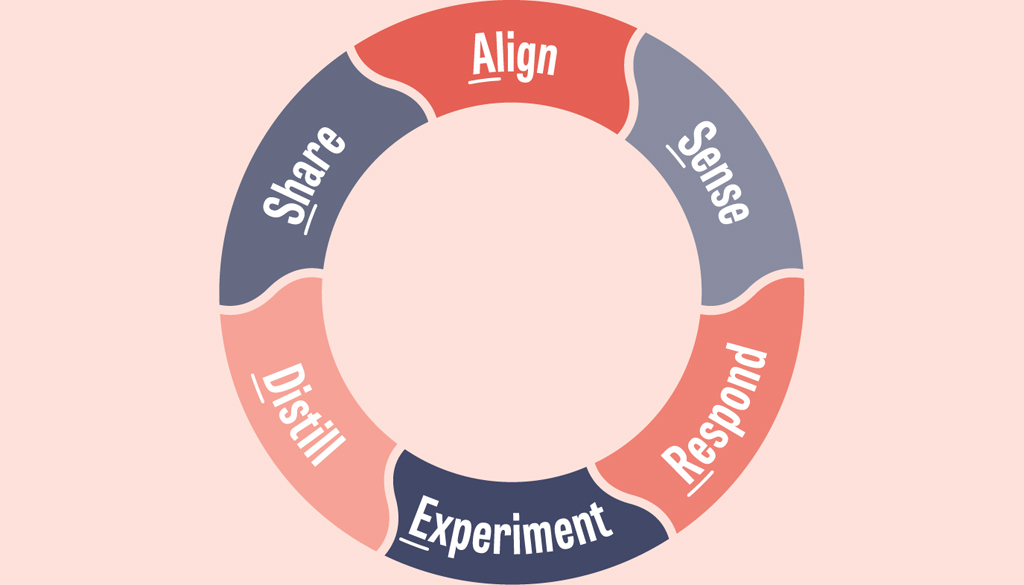
Figure 21.1: The ASREDS Learning Loop
Source: Smart et al., Sooner Safer Happier: Antipatterns and Patterns for Business Agility (Portland, OR: IT Revolution, 2020).
Share your Experiences from DevOps Conferences
In many cost-focused organizations, engineers are often discouraged from attending conferences and learning from their peers. To help build a learning organization, we should encourage our engineers (both from Development and Operations) to attend conferences, give talks at them, and, when necessary, create and organize internal or external conferences themselves.
DevOpsDays remains one of the most vibrant self-organized conference series today. Many DevOps practices have been shared and promulgated at these events. It has remained free or nearly free, supported by a vibrant community of practitioner communities and vendors.
The DevOps Enterprise Summit was created in 2014 for technology leaders to share their experiences adopting DevOps principles and practices in large, complex organizations. The program is organized primarily around experience reports from technology leaders on the DevOps journey, as well as subject matter experts on topics selected by the community. By 2021, DevOps Enterprise Summit has held fourteen conferences, with nearly one thousand talks from technology experts from almost every industry vertical.
Internal Technology Conferences at Nationwide Insurance, Capital One, and Target (2014)
Along with attending external conferences, many companies have internal conferences for their technology employees. Nationwide Insurance is a leading provider of insurance and financial services and operates in heavily regulated industries. Their many offerings include auto and homeowner's insurance, and they are the top provider of public-sector retirement plans and pet insurance. As of 2014, they had $195 billion in assets, with $24 billion in revenue.18
Since 2005, Nationwide has been adopting Agile and Lean principles to elevate the state of practice for their five thousand technology professionals, enabling grassroots innovation.
Steve Farley, VP of Information Technology, remembers,
Exciting technology conferences were starting to appear around that time, such as the Agile national conference. In 2011, the technology leadership at Nationwide agreed that we should create a technology conference, called TechCon. By holding this event, we wanted to create a better way to teach ourselves, as well as ensure that everything had a Nationwide context, as opposed to sending everyone to an external conference.19
Capital One, one of the largest banks in the US with over $298 billion in assets and $24 billion in revenue in 2015, held their first internal software engineering conference in 2015 as part of their goal to create a world-class technology organization.20 The mission was to promote a culture of sharing and collaboration, and to build relationships between the technology professionals and enable learning. The conference had thirteen learning tracks and fifty-two sessions, and over 1,200 internal employees attended.21
Dr. Tapabrata Pal, a technical fellow at Capital One and one of the organizers of the event, describes, “We even had an expo hall, where we had twenty-eight booths, where internal Capital One teams were showing off all the amazing capabilities they were working on. We even decided very deliberately that there would be no vendors there, because we wanted to keep the focus on Capital One goals.”22
Target is the sixth-largest retailer in the US, with $72 billion in revenue in 2014 and 1,799 retail stores and 347,000 employees worldwide.23 Heather Mickman, a director of Development, and Ross Clanton have held six internal DevOpsDays events since 2014 and have over 975 followers inside their internal technology community, modeled after the DevOpsDays held at ING in Amsterdam in 2013.24†
After Mickman and Clanton attended the DevOps Enterprise Summit in 2014, they held their own internal conference, inviting many of the speakers from outside firms so that they could re-create their experience for their senior leadership. Clanton describes, “2015 was the year when we got executive attention and when we built up momentum. After that event, tons of people came up to us, asking how they could get involved and how they could help.”26
Institutions can enable their technologists by providing a dynamic culture of learning and teaching, not only through attending and presenting at external conferences but also by building and holding internal conferences. This can foster greater team and organizational trust, increase communication and innovation, and improve daily work.
The DORA 2019 State of DevOps Report investigated how oganizations spread DevOps and Agile practices, asking them to choose from a variety of common methods, such as training centers, centers of excellence, various kinds of proof of concept, big bang, and communities of practice.
Analysis showed that:
high performers favor strategies that create community structures at both low and high levels in the organization, likely making them more sustainable and resilient to re-organizations and product changes. The top two strategies employed are communities of practice and grassroots, followed by proof of concept as a template (a pattern where the proof of concept gets reproduced elsewhere in the organization), and proof of concept as a seed.27
Create Community Structures to Spread Practices
Earlier in the book, we began the story of how the Testing Grouplet built a world-class automated testing culture at Google starting in 2005. Their story continues here, as they try to improve the state of automated testing across all of Google by using dedicated improvement blitzes, internal coaches, and even an internal certification program.
Mike Bland said, at that time, there was a 20% innovation time policy at Google, enabling developers to spend roughly one day per week on a Google-related project outside of their primary area of responsibility. Some engineers chose to form communities of practice they called grouplets, ad hoc teams of like-minded engineers who wanted to pool their 20% time, allowing them to do focused improvement blitzes.28
A testing community of practice was formed by Bharat Mediratta and Nick Lesiecki, with the mission of driving the adoption of automated testing across Google. Even though they had no budget or formal authority, as Mike Bland described, “There were no explicit constraints put upon us, either. And we took advantage of that.”29
They used several mechanisms to drive adoption, but one of the most famous was Testing on the Toilet (or TotT), their weekly testing periodical. Each week, they published a newsletter in nearly every bathroom in nearly every Google office worldwide. Bland said, “The goal was to raise the degree of testing knowledge and sophistication throughout the company. It’s doubtful an online-only publication would’ve involved people to the same degree.”30
Bland continues, “One of the most significant TotT episodes was the one titled, ‘Test Certified: Lousy Name, Great Results,’ because it outlined two initiatives that had significant success in advancing the use of automated testing.”31
Test Certified (TC) provided a road map to improve the state of automated testing. As Bland describes, “It was intended to hack the measurement-focused priorities of Google culture . . . and to overcome the first, scary obstacle of not knowing where or how to start. Level 1 was to quickly establish a baseline metric, Level 2 was setting a policy and reaching an automated test coverage goal, and Level 3 was striving towards a long-term coverage goal.”32
The second capability was providing test certified mentors to any team who wanted advice or help, and test mercenaries (i.e., a full-time team of internal coaches and consultants) to work hands-on with teams to improve their testing practices and code quality. The mercenaries did so by applying the testing grouplet’s knowledge, tools, and techniques to a team’s own code, using TC as both a guide and a goal.
Bland was eventually a leader of the testing grouplet from 2006 to 2007, and a member of the test mercenaries from 2007 to 2009.33
Bland continues,
It was our goal to get every team to TC Level 3, whether they were enrolled in our program or not. We also collaborated closely with the internal testing tools teams, providing feedback as we tackled testing challenges with the product teams. We were boots on the ground, applying the tools we built, and eventually, we were able to remove ‘I don’t have time to test’ as a legitimate excuse. . . .34
The TC levels exploited the Google metrics-driven culture—the three levels of testing were something that people could discuss and brag about at performance review time. The Testing Grouplet eventually got funding for the Test Mercenaries, a staffed team of full-time internal consultants. This was an important step, because now management was fully onboard, not with edicts, but by actual funding.35
Another important construct was leveraging company-wide “fixit” improvement blitzes. Bland describes fixits as “when ordinary engineers with an idea and a sense of mission recruit all of Google engineering for one-day, intensive sprints of code reform and tool adoption.”36
He organized four company-wide fixits, two pure testing fixits and two that were more tools-related, the last involving more than one hundred volunteers in over twenty offices in thirteen countries. He also led the Fixit Grouplet from 2007 to 2008.37
These fixits, as Bland describes, mean that we should provide focused missions at critical points in time to generate excitement and energy, which helps advance the state of the art. This will help the long-term culture change mission reach a new plateau with every big, visible effort.38
The results of the testing culture are self-evident in the amazing results Google has achieved, as presented throughout the book.
Conclusion
This chapter described how we can institute rituals that help reinforce the culture that we are all lifelong learners and that we value the improvement of daily work over daily work itself. We do this by reserving time to pay down technical debt, and creating community structures that allow everyone to learn from and teach each other, both inside our organization and outside it. By having everyone help each other learn in our daily work, we out-learn the competition, helping us win in the marketplace. But also, we help each other achieve our full potential as human beings.
* |
From here on, the terms “hack week” and “hackathon” are used interchangeably with “improvement blitz,” and not in the context of “you can work on whatever you want.” |
† |
Incidentally, the first Target internal DevOpsDays event was modeled after the first ING DevOpsDays that was organized by Ingrid Algra, Jan-Joost Bouwman, Evelijn Van Leeuwen, and Kris Buytaert in 2013, after some of the ING team attended the 2013 Paris DevOpsDays.25 |