8
HOW TO GET GREAT OUTCOMES BY INTEGRATING OPERATIONS INTO THE DAILY WORK OF DEVELOPMENT
Our goal is to enable user-oriented outcomes where many small teams can quickly and independently deliver value to customers. This can be a challenge to achieve when Operations is centralized and functionally oriented, having to serve the needs of many different development teams with potentially wildly different needs. The result can often be long lead times for needed Ops work, constant reprioritization and escalation, and poor deployment outcomes.
We can create more market-oriented outcomes by better integrating Ops capabilities into Dev teams, making both more efficient and productive. In this chapter, we’ll explore many ways to achieve this, both at the organizational level and through daily rituals. By doing this, Ops can significantly improve the productivity of Dev teams throughout the entire organization, as well as enable better collaboration and organizational outcomes.
Big Fish Games
At Big Fish Games, which develops and supports hundreds of mobile and thousands of PC games and had more than $266 million in revenue in 2013, VP of IT Operations Paul Farrall was in charge of the centralized Operations organization.1 He was responsible for supporting many different business units that each had a great deal of autonomy.
Each of these business units had dedicated Development teams who often chose wildly different technologies. When these groups wanted to deploy new functionality, they would have to compete for a common pool of scarce Ops resources. Furthermore, everyone was struggling with unreliable test and integration environments, as well as extremely cumbersome release processes.
Farrall thought the best way to solve this problem was by embedding Ops expertise into Development teams. He observed,
When Dev teams had problems with testing or deployment, they needed more than just technology or environments. What they also needed was help and coaching. At first, we embedded Ops engineers and architects into each of the Dev teams, but there simply weren’t enough Ops engineers to cover that many teams. We were able to help more teams with what we called an Ops liaison model and with fewer people.2
Farrall defined two types of Ops liaisons: the business relationship manager and the dedicated release engineer.3 The business relationship managers worked with product management, line-of-business owners, project management, Dev management, and developers. They became intimately familiar with product group business drivers and product road maps, acted as advocates for product owners inside of Operations, and helped their product teams navigate the Operations landscape to prioritize and streamline work requests.
Similarly, the dedicated release engineer became intimately familiar with the product’s Development and QA issues and helped product management get what they needed from the Ops organization to achieve their goals. They were familiar with the typical Dev and QA requests for Ops and would often executed the necessary work themselves. As needed, they would also pull in dedicated technical Ops engineers (e.g., DBAs, Infosec, storage engineers, network engineers) and help determine which self-service tools the entire Operations group should prioritize building.
By doing this, Farrall was able to help Dev teams across the organization become more productive and achieve their team goals. Furthermore, he helped the teams prioritize around his global Ops constraints, reducing the number of surprises discovered mid-project and ultimately increasing the overall project throughput.
Farrall notes that both working relationships with Operations and code release velocity were noticeably improved as a result of the changes. He concludes, “The Ops liaison model allowed us to embed IT Operations expertise into the Dev and Product teams without adding new headcount.”4
The DevOps transformation at Big Fish Games shows how a centralized Operations team was able to achieve the outcomes typically associated with user-oriented teams. We can employ the three following broad strategies:
•Create self-service capabilities to enable developers in the service teams to be productive.
•Embed Ops engineers into the service teams.
•Assign Ops liaisons to the service teams when embedding Ops is not possible.
We can see how this approach at Big Fish Games follows both a platform team and enabling team approach, as outlined in Team Topologies by Matthew Skelton and Manuel Pais and summarized in the last chapter.
A single platform team provides infrastructure functionality for the entire organization and supports market-oriented teams. The Ops liaisons also act as members of the enabling teams.
Lastly, Ops engineers can be integrated into the Dev team’s rituals that they use in their daily work, including daily standups, planning, and retrospectives.
Create Shared Services to Increase Developer Productivity
One way to enable market-oriented outcomes is for Operations to create a set of centralized platforms and tooling services that any Dev team can use to become more productive, such as getting production-like environments, deployment pipelines, automated testing tools, production telemetry dashboards, and so forth.* By doing this, we enable Dev teams to spend more time building functionality for their customer, as opposed to obtaining all the infrastructure required to deliver and support that feature in production.
All the platforms and services we provide should (ideally) be automated and available on demand without requiring a developer to open up a ticket and wait for someone to manually perform work. This ensures that Operations doesn’t become a bottleneck for their customers (e.g., “We received your work request, and it will take six weeks to manually configure those test environments”).†
By doing this, we enable the product teams to get what they need, when they need it, as well as reduce the need for communications and coordination. As Damon Edwards observed, “Without these self-service Operations platforms, the cloud is just Expensive Hosting 2.0.”6
In almost all cases, we will not mandate that internal teams use these platforms and services—these platform teams will have to win over and satisfy their internal customers, sometimes even competing with external vendors. By creating this effective internal marketplace of capabilities, we help ensure that the platforms and services we create are the easiest and most appealing choices available (the path of least resistance).
For instance, we may create a platform that provides a shared version control repository with pre-blessed security libraries, a deployment pipeline that automatically runs code quality and security scanning tools, which deploys our applications into known, good environments that already have production monitoring tools installed on them. Ideally, we will make life so much easier for Dev teams that they will overwhelmingly decide that using our platform is the easiest, safest, and most secure means to get their applications into production.
We build into these platforms the cumulative and collective experience of everyone in the organization, including QA, Operations, and Infosec, which helps to create an ever-safer system of work. This increases developer productivity and makes it easy for product teams to leverage common processes, such as performing automated testing and satisfying security and compliance requirements.
Creating and maintaining these platforms and tools is real product development—the customers of our platform aren’t our external customers but our internal Dev teams. Like creating any great product, creating great platforms that everyone loves doesn’t happen by accident. An internal platform team with poor customer focus will likely create tools that everyone will hate and quickly abandon for other alternatives, whether for another internal platform team or an external vendor.
Dianne Marsh, Director of Engineering Tools at Netflix, states that her team’s charter is to “support our engineering teams’ innovation and velocity. We don’t build, bake, or deploy anything for these teams, nor do we manage their configurations. Instead, we build tools to enable self-service. It’s okay for people to be dependent on our tools, but it’s important that they don’t become dependent on us.”7
Often, these platform teams provide other services to help their customers learn their technology, migrate off of other technologies, and even provide coaching and consulting to help elevate the state of the practice inside the organization. These shared services also facilitate standardization, enabling engineers to quickly become productive, even if they switch between teams. For instance, if every product team chooses a different toolchain, engineers may have to learn an entirely new set of technologies to do their work, putting the team goals ahead of the global goals.
In organizations where teams can only use approved tools, we can start by removing this requirement for a few teams, such as the transformation team, so that we can experiment and discover what capabilities make those teams more productive.
Internal shared services teams should continually look for internal toolchains that are widely being adopted in the organization, deciding which ones make sense to be supported centrally and made available to everyone. In general, taking something that’s already working somewhere and expanding its usage is far more likely to succeed than building these capabilities from scratch.‡
Embed Ops Engineers into Our Service Teams
Another way we can enable more user-oriented outcomes is by enabling product teams to become more self-sufficient by embedding Operations engineers within them, thus reducing their reliance on centralized Operations. These product teams may also be completely responsible for service delivery and service support.
By embedding Operations engineers into the Dev teams, their priorities are driven almost entirely by the goals of the product teams they are embedded in—as opposed to Ops focusing inwardly on solving their own problems. As a result, Ops engineers become more closely connected to their internal and external customers. Furthermore, the product teams often have the budget to fund the hiring of these Ops engineers, although interviewing and hiring decisions will likely still be done from the centralized Operations group to ensure consistency and quality of staff.
Jason Cox said,
In many parts of Disney, we have embedded Ops (system engineers) inside the product teams in our business units, along with inside Development, Test, and even Information Security. It has totally changed the dynamics of how we work. As Operations Engineers, we create the tools and capabilities that transform the way people work, and even the way they think. In traditional Ops, we merely drove the train that someone else built. But in modern Operations Engineering, we not only help build the train, but also the bridges that the trains roll on.8
For new large Development projects, we may initially embed Ops engineers into those teams. Their work may include helping decide what to build and how to build it, influencing the product architecture, helping influence internal and external technology choices, helping create new capabilities in our internal platforms, and maybe even generating new operational capabilities.
After the product is released to production, embedded Ops engineers may help with the production responsibilities of the Dev team. They will take part in all of the Dev team rituals, such as planning meetings, daily standups, and demonstrations where the team shows off new features and decides which ones to ship. As the need for Ops knowledge and capabilities decreases, Ops engineers may transition to different projects or engagements, following the general pattern that the composition within product teams changes throughout its life cycle.
This paradigm has another important advantage: pairing Dev and Ops engineers together is an extremely efficient way to cross-train operations knowledge and expertise into a service team. It can also have the powerful benefit of transforming operations knowledge into automated code that can be far more reliable and widely reused.
Assign an Ops Liaison to Each Service Team
For a variety of reasons, such as cost and scarcity, we may be unable to embed Ops engineers into every product team. However, we can get many of the same benefits by assigning a designated liaison for each product team.
At Etsy, this model is called “designated Ops.”9 Their centralized Operations group continues to manage all the environments—not just production environments but also pre-production environments—to help ensure they remain consistent. The designated Ops engineer is responsible for understanding:
•what the new product functionality is and why we’re building it
•how it works as it pertains to operability, scalability, and observability (diagramming is strongly encouraged)
•how to monitor and collect metrics to ensure the progress, success, or failure of the functionality
•any departures from previous architectures and patterns, and the justifications for them
•any extra needs for infrastructure and how usage will affect infrastructure capacity
•feature launch plans
Furthermore, just like in the embedded Ops model, this liaison attends the team standups, integrating their needs into the Operations road map and performing any needed tasks. These liaisons escalate any resource contention or prioritization issue. By doing this, we identify any resource or time conflicts that should be evaluated and prioritized in the context of wider organizational goals.
Assigning Ops liaisons allows us to support more product teams than the embedded Ops model. Our goal is to ensure that Ops is not a constraint for the product teams. If we find that Ops liaisons are stretched too thin, preventing the product teams from achieving their goals, then we will likely need to either reduce the number of teams each liaison supports or temporarily embed an Ops engineer into specific teams.
Integrate Ops into Dev Rituals
When Ops engineers are embedded or assigned as liaisons into our product teams, we can integrate them into our Dev team rituals. In this section, our goal is to help Ops engineers and other non-developers better understand the existing Development culture and proactively integrate them into all aspects of planning and daily work. As a result, Operations is better able to plan and radiate any needed knowledge into the product teams, influencing work long before it gets into production. The following sections describe some of the standard rituals used by Development teams using agile methods and how we would integrate Ops engineers into them. By no means are agile practices a prerequisite for this step—as Ops engineers, our goal is to discover what rituals the product teams follow, integrate into them, and add value to them.§
As Ernest Mueller observed, “I believe DevOps works a lot better if Operations teams adopt the same agile rituals that Dev teams have used—we’ve had fantastic successes solving many problems associated with Ops pain points, as well as integrating better with Dev teams.”10
Invite Ops to Our Dev Standups
One of the Dev rituals popularized by Scrum is the daily standup (although physically standing up has become distinctly optional in remote teams), a quick meeting where everyone on the team gets together and presents to each other three things: what was done yesterday, what is going to be done today, and what is preventing you from getting your work done.¶
The purpose of this ceremony is to radiate information throughout the team and to understand the work that is being done and is going to be done. By having team members present this information to each other, we learn about any tasks that are experiencing roadblocks and discover ways to help each other move our work toward completion. Furthermore, by having managers present, we can quickly resolve prioritization and resource conflicts.
A common problem is that this information is compartmentalized within the Development team. By having Ops engineers attend Dev standups, Operations can gain an awareness of the Development team’s activities, enabling better planning and preparation—for instance, if we discover that the product team is planning a big feature rollout in two weeks, we can ensure that the right people and resources are available to support the rollout.
Alternatively, we may highlight areas where closer interaction or more preparation is needed (e.g., creating more monitoring checks or automation scripts). By doing this, we create the conditions where Operations can help solve our current team problems (e.g., improving performance by tuning the database instead of optimizing code) or future problems before they turn into a crisis (e.g., creating more integration test environments to enable performance testing).
Invite Ops to Our Dev Retrospectives
Another widespread agile ritual is the retrospective. At the end of each development interval, the team discusses what was successful, what could be improved, and how to incorporate the successes and improvements in future iterations or projects. The team comes up with ideas to make things better and reviews experiments from the previous iteration. This is one of the primary mechanisms where organizational learning and the development of countermeasures occurs, with resulting work implemented immediately or added to the team’s backlog.
Having Ops engineers attend our project team retrospectives means they can also benefit from any new learnings. Furthermore, when there is a deployment or release in that interval, Operations should present the outcomes and any resulting learnings, creating feedback into the product team. By doing this, we can improve how future work is planned and performed, improving our outcomes. Examples of feedback that Operations can bring to a retrospective include:
•“Two weeks ago, we found a monitoring blindspot and agreed on how to fix it. It worked. We had an incident last Tuesday, and we were able to quickly detect and correct it before any customers were impacted.”
•“Last week’s deployment was one of the most difficult and lengthy we’ve had in over a year. Here are some ideas on how it can be improved.”
•“The promotion campaign we did last week was far more difficult than we thought it would be, and we should probably not make an offer like that again. Here are some ideas on other offers we can make to achieve our goals.”
•“During the last deployment, the biggest problem we had was that our firewall rules are now thousands of lines long, making it extremely difficult and risky to change. We need to re-architect how we prevent unauthorized network traffic.”
Feedback from Operations helps our product teams better see and understand the downstream impact of decisions they make. When there are negative outcomes, we can make the changes necessary to prevent them in the future. Operations feedback will also likely identify more problems and defects that should be fixed—it may even uncover larger architectural issues that need to be addressed.
The additional work identified during project team retrospectives falls into the broad category of improvement work, such as fixing defects, refactoring, and automating manual work. Product managers and project managers may want to defer or deprioritize improvement work in favor of customer features.
However, we must remind everyone that improvement of daily work is more important than daily work itself, and that all teams must have dedicated capacity for this (e.g., reserving 20% of all capacity for improvement work, scheduling one day per week or one week per month, etc.). Without doing this, the productivity of the team will almost certainly grind to a halt under the weight of its own technical and process debt.
Make Relevant Ops Work Visible on Shared Kanban Boards
Often, Development teams will make their work visible on a project board or kanban board. It’s far less common, however, for work boards to show the relevant Operations work that must be performed in order for the application to run successfully in production, where customer value is actually created. As a result, we are not aware of necessary Operations work until it becomes an urgent crisis, jeopardizing deadlines or creating a production outage.
Because Operations is part of the product value stream, we should put the Operations work that is relevant to product delivery on the shared kanban board. This enables us to more clearly see all the work required to move our code into production, as well as keep track of all Operations work required to support the product. Furthermore, it enables us to see where Ops work is blocked and where work needs escalation, highlighting areas where we may need improvement.
Kanban boards are an ideal tool to create visibility, and visibility is a key component in properly recognizing and integrating Ops work into all the relevant value streams. When we do this well, we achieve user-oriented outcomes, regardless of how we’ve drawn our organization charts.
 CASE STUDY: NEW TO SECOND EDITION
CASE STUDY: NEW TO SECOND EDITION
Better Ways of Working at Nationwide Building Society (2020)
Nationwide Building Society is the world’s largest building society, with sixteen million members. In 2020, Patrick Eltridge, Chief Operating Officer, and Janet Chapman, Mission Leader, discussed their continued journey to better ways of working at the DevOps Enterprise Summit London-Virtual.
As a larger, older organization, Nationwide faces a number of challenges. As Patrick Eltridge puts it, they are part of a “hyper fluid and hyper competitive environment.”12
Like many organizations, they started their transformation in the IT department mainly around change activities and using Agile practices in IT delivery, seeing measurable but limited benefits.
“We deliver well and reliably, but slowly. We need to get from start to finish more quickly and to surprise and delight our members not only with the quality of our products and services, but the speed at which they are delivered,” Janet Chapman said.13
In 2020, with the help of Sooner Safer Happier author Jonathan Smart and his team from Deloitte, Nationwide was in the middle of an organizational pivot from a functional organization to one fully aligned to member needs underpinned by stronger Agile and DevOps practices. One key objective was to bring run and change activities together into long-lived and multiskilled teams. They called it their Member Mission Operating Model.
Typical ways of working in most large organizations are the result of years of evolution. Specialist functions are gathered into departments and the work passes between them with queues at every step.
“Currently, when we process a mortgage application it gets broken into parts among all the functional teams. We all do our bits and then reassemble the outcome, test it to see what we got wrong, and then see if it fits the needs of the member and fix it if it doesn’t,” Eltridge explains. “And when we want to improve performance or reduce cost, we seek to improve the efficiency or reduce the capacity of the teams of individual specialists. What that way of working doesn’t do is optimize the flow of work to our members from begininng to end, right across and through those teams.”14
To optimize flow, Nationwide made it easy for members to tell them what they wanted. Then they brought together all the people and tools necessary into a single team to make that “want.” Everyone on the team can see all the work, and they are able to organize themselves in a way that smooths the path of the work and optimizes the delivery of the work in a safe, controlled, and sustainable manner. If a bottleneck does appear, they add people or change the process. What they don’t do is add a queuing mechanism as a first response. By moving from functional teams in silos to long-lived, multi-skilled teams, Nationwide has seen throughput improve dramatically, as well as improvements in risk and quality and lower costs.
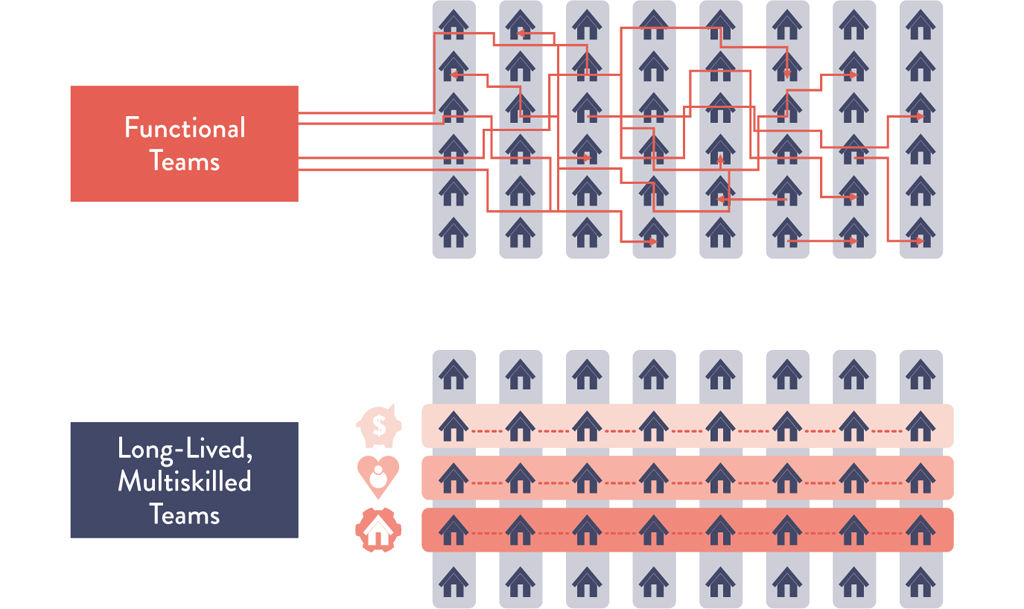
Figure 8.1: Functional Teams in Silos vs. Long-Lived, Multiskilled Teams
Source: Chapman, Janet, and Patrick Eltridge. “On A Mission: Nationwide Building Society,” presentation at DevOps Enterprise Summit-Virtual London 2020. https://videolibrary.doesvirtual.com/?video=432109857.
They had a unique opportunity to place these new ways of working to the test with the COVID-19 pandemic. As the UK went into lockdown, Nationwide’s call centers were quickly swamped due to staff absences. They needed to enable contact center staff to work from home and enable branch center staff to take calls to relieve pressure.
This was an initiative that Nationwide had been discussing for years. But it would have taken nine months and cost more than £10 million, so it never got done.15
With an urgent need to reduce call center volumes, Nationwide gathered everyone necessary around the same “virtual” table and worked through, in real time, how to enable an agent to work from home. It took the team only four days to complete.
Next, they looked to see if they could direct calls to the branch network, but they couldn’t without the recording necessary by regulation. So instead, they only directed calls to branch networks that didn’t need the regulatory recording, which helped a bit. A small improvement on a longer path. This, again, took about four days. But over the weekend, they were able to solve the recording problem as well. Another four days.
“Afterwards, I asked the team how many corners we’d cut? How many policies we’d breached? How many security holes we’d now need to plug? They looked at me and said, ‘Well, none. We had all the specialists we needed to do it properly right there. We stuck to the policies, it’s secure, it’s fine,’” explains Eltridge.16
“When everyone you need is aligned on the most important task at the same time, you get real pace and real collaboration on solving problems. That, in essence, is what a mission is to us,” says Eltridge.17
Nationwide is now aligning people from their old, functional teams into these long-lived, multiskilled mission teams, as well as their underlying value streams. They are evolving governance and financial management to support local decision-making and continuous funding of consistent teams. They are integrating run and change activities into these long-lived teams to enable continuous improvement of the work. And they’re applying systems thinking to identify and remove failure demand from these flows.
“I think of Agile as our means and DevOps as our target. This is very much a work in progress, and we’re consciously allowing the issues and opportunity to merge as we work to implement this. We’re not following a templated approach,” explains Eltridge. “It is most important to people to go on this journey of learning and unlearning, often with coaches, but not having the answers handed to them by a central team of experts.”18
Beyond simply bringing Dev and Ops together, Nationwide brought together teams with all the skills necessary to bring value to market—moving from multiple functional teams to single, multiskilled teams. This illustrates the power of breaking down silos in order to move faster.
Conclusion
Throughout this chapter, we explored ways to integrate Operations into the daily work of Development, and we looked at how to make Dev work more visible to Operations. To accomplish this, we explored three broad strategies, including creating self-service capabilities to enable developers in service teams to be productive, embedding Ops engineers into the service teams, and assigning Ops liaisons to the service teams when embedding Ops engineers is not possible. Lastly, we described how Ops engineers can integrate with the Dev team through inclusion in their daily work, including daily standups, planning, and retrospectives.
* |
The terms platform, shared service, and toolchain will be used interchangeably in this book. |
† |
Ernest Mueller observed, “At Bazaarvoice, the agreement was that these platform teams that make tools accept requirements but not work from other teams.”5 |
‡ |
After all, designing a system upfront for reuse is a common and expensive failure mode of many enterprise architectures. |
§ |
However, if we discover that the entire Development organization merely sits at their desks all day without ever talking to each other, we may have to find a different way to engage them, such as buying them lunch, starting a book club, taking turns doing “lunch and learn” presentations, or having conversations to discover what everyone’s biggest problems are, so that we can figure out how we can make their lives better. |
¶ |
Scrum is an agile development methodology, described as "a flexible, holistic product development strategy where a development team works as a unit to reach a common goal."11 It was first fully described by Ken Schwaber and Mike Beedle in the book Agile Software Development with Scrum. In this book, we use the term “agile development” or “iterative development” to encompass the various techniques used by special methodologies such as Agile and Scrum. |