5
SELECTING WHICH VALUE STREAM TO START WITH
Choosing a value stream for DevOps transformation deserves careful consideration. Not only does the value stream we choose dictate the difficulty of our transformation, but it also dictates who will be involved in the transformation. It will affect how we need to organize into teams and how we can best enable the teams and individuals in them.
Another challenge was noted by Michael Rembetsy, who helped lead the DevOps transformation as the Director of Operations at Etsy in 2009. He observed, “We must pick our transformation projects carefully—when we’re in trouble, we don’t get very many shots. Therefore, we must carefully pick and then protect those improvement projects that will most improve the state of our organization.”1
Nordstrom’s DevOps Transformation
Let us examine how the Nordstrom team started their DevOps transformation initiative in 2013, which Courtney Kissler, their VP of E-Commerce and Store Technologies, described at the DevOps Enterprise Summit in 2014 and 2015.
Founded in 1901, Nordstrom is a leading fashion retailer focused on delivering the best possible shopping experience to its customers. In 2015, Nordstrom had annual revenue of $13.5 billion.2
The stage for Nordstrom’s DevOps journey was likely set in 2011 during one of their annual board of directors meetings.3 That year, one of the strategic topics discussed was the need for online revenue growth. They studied the plight of Blockbuster, Borders, and Barnes & Noble, which demonstrated the dire consequences when traditional retailers were late creating competitive e-commerce capabilities. These organizations were clearly at risk of losing their position in the marketplace or even going out of business entirely.*
At that time, Courtney Kissler was the senior director of Systems Delivery and Selling Technology and was responsible for a significant portion of the technology organization, including their in-store systems and online e-commerce site. As Kissler described,
In 2011, the Nordstrom technology organization was very much optimized for cost—we had outsourced many of our technology functions, we had an annual planning cycle with large batch, “waterfall” software releases. Even though we had a 97% success rate of hitting our schedule, budget, and scope goals, we were ill-equipped to achieve what the five-year business strategy required from us, as Nordstrom started optimizing for speed instead of merely optimizing for cost.5
Kissler and the Nordstrom technology management team had to decide where to start their initial transformation efforts. They didn’t want to cause upheaval in the whole system. Instead, they wanted to focus on very specific areas of the business so they could experiment and learn. Their goal was to demonstrate early wins, which would give everyone confidence that these improvements could be replicated in other areas of the organization. How exactly that would be achieved was still unknown.
They focused on three areas: the customer mobile application, their in-store restaurant systems, and their digital properties. Each of these areas had business goals that weren’t being met; thus, they were more receptive to considering a different way of working. The stories of the first two focus areas are described below.
The Nordstrom mobile application had experienced an inauspicious start. As Kissler said, “Our customers were extremely frustrated with the product, and we had uniformly negative reviews when we launched it in the App Store.”6 Worse, the existing structure and processes were designed so that updates could only be released twice per year. In other words, any fixes to the application would have to wait months to reach the customer.
Their first goal was to enable faster or on-demand releases, providing faster iteration and the ability to respond quickly to customer feedback. They created a product team that was solely dedicated to supporting the mobile application. They had the goal of enabling the mobile application team to be able to independently implement, test, and deliver value to customers. By doing this, the mobile application team would no longer have to depend on and coordinate with scores of other teams inside Nordstrom.
Furthermore, the mobile application team moved from planning once per year to a continuous planning process. The result was a single prioritized backlog of work for the mobile app based on customer need—gone were all the conflicting priorities when the team had to support multiple products.
Over the following year, they eliminated testing as a separate phase of work; instead, they integrated it into everyone’s daily work.† They doubled the features being delivered per month and halved the number of defects—creating a successful outcome.
Their second area of focus was the systems supporting their in-store Café Bistro restaurants. Unlike the mobile app value stream, where the business need was to reduce time to market and increase feature throughput, the business need here was to decrease cost and increase quality. In 2013, Nordstrom had completed eleven “restaurant re-concepts,” which required changes to the in-store applications, causing a number of customer-impacting incidents. Plus, they had planned forty-four more of these re-concepts for 2014—four times as many as in the previous year.
As Kissler stated, “One of our business leaders suggested that we triple our team size to handle these new demands, but I proposed that we had to stop throwing more bodies at the problem and instead improve the way we worked.”7
Kissler’s team was able to identify problematic areas, such as their work intake and deployment processes, which is where they focused their improvement efforts. They were able to reduce code deployment lead times by 60% and reduce the number of production incidents 60–90%.
These successes gave the teams confidence that DevOps principles and practices were applicable to a wide variety of value streams. Kissler was promoted to VP of E-Commerce and Store Technologies in 2014.
In 2015, Kissler said that in order for the selling or customer-facing technology organization to enable the business to meet their goals, “. . . we needed to increase productivity in all our technology value streams, not just in a few. At the management level, we created an across-the-board mandate to reduce cycle times by 20% for all customer-facing services.”8
She continued, “This is an audacious challenge. We have many problems in our current state—process and cycle times are not consistently measured across teams, nor are they visible. Our first target condition requires us to help all our teams measure, make [the work] visible, and perform experiments to start reducing their process times, iteration by iteration.”9 Kissler concluded,
From a high-level perspective, we believe that techniques such as value stream mapping, reducing our batch sizes toward single-piece flow, as well as using continuous delivery and microservices will get us to our desired state. However, while we are still learning, we are confident that we are heading in the right direction, and everyone knows that this effort has support from the highest levels of management.10
In this chapter, various models are presented that will enable us to replicate the thought processes that the Nordstrom team used to decide which value streams to start with. We will evaluate our candidate value streams in many ways, including whether they are a greenfield or a brownfield service, a system of engagement or a system of record. We will also estimate the risk/reward balance of transforming and assess the likely level of resistance we may get from the teams we would work with.
Greenfield vs. Brownfield Services
We often categorize our software services or products as either greenfield or brownfield. These terms were originally used for urban planning and building projects. Greenfield development is when we build on undeveloped land. Brownfield development is when we build on land that was previously used for industrial purposes, potentially contaminated with hazardous waste or pollution. In urban development, many factors can make greenfield projects simpler than brownfield projects—there are no existing structures that need to be demolished nor are there toxic materials that need to be removed.
In technology, a greenfield project is a new software project or initiative, likely in the early stages of planning or implementation, where we build our applications and infrastructure from scratch, with few constraints. Starting with a greenfield software project can be easier, especially if the project is already funded and a team is either being created or is already in place. Furthermore, because we are starting from scratch, we can worry less about existing code bases, architectures, processes, and teams.
Greenfield DevOps projects are often pilots to demonstrate feasibility of public or private clouds, piloting deployment automation, and similar tools. An example of a greenfield DevOps project is the Hosted LabVIEW product in 2009 at National Instruments, a thirty-year-old organization with five thousand employees and $1 billion in annual revenue.
To bring this product to market quickly, a new team was created. They were allowed to operate outside of the existing IT processes and explore the use of public clouds. The initial team included an applications architect, a systems architect, two developers, a system automation developer, an operations lead, and two offshore operations staff. By using DevOps practices, they were able to deliver Hosted LabVIEW to market in half the time of their normal product introductions.11
On the other end of the spectrum are brownfield DevOps projects. These are existing products or services that are already serving customers and have potentially been in operation for years or even decades. Brownfield projects often come with significant amounts of technical debt, such as having no test automation or running on unsupported platforms. In the Nordstrom example presented earlier in this chapter, both the in-store restaurant systems and e-commerce systems were brownfield projects.
Although many believe that DevOps is primarily for greenfield projects, DevOps has been used to successfully transform brownfield projects of all sorts. In fact, over 60% of the transformation stories shared at the DevOps Enterprise Summit in 2014 were for brownfield projects.12 In these cases, there was a large performance gap between what the customer needed and what the organization was currently delivering, and the DevOps transformations created tremendous business benefits.
Indeed, research from the State of DevOps Reports found that the age of the application or even the technology used was not a significant predictor of performance; instead, what predicted performance was whether the application was architected (or could be re-architected) for testability and deployability.13
Teams supporting brownfield projects may be very receptive to experimenting with DevOps, particularly when there is a widespread belief that traditional methods are insufficient to achieve their goals—and especially if there is a strong sense of urgency around the need for improvement.‡
When transforming brownfield projects, we may face significant impediments and problems, especially when no automated testing exists or when there is a tightly coupled architecture that prevents small teams from developing, testing, and deploying code independently. How we overcome these issues is discussed throughout this book.
Examples of successful brownfield transformations include:
•American Airlines (2020): DevOps practices can also be applied to legacy COTS (commercial off-the-shelf product). At American Airlines, their loyalty product runs on Seibel. AA moved it onto a hybrid cloud model and then invested in CI/CD pipelines to automate delivery and infrastructure end to end for their loyalty product. Since that move, teams are deploying more frequently, with more than fifty automated deployments in just a few months, plus twice as fast loyalty web service response times and 32% cost optimization in the cloud. What’s more, this move caused the conversation between the business and IT to change. Instead of the business waiting on IT for changes, the teams are able to deploy more frequently and seamlessly than the business can validate and accept. Now the product teams, in partnership with the business and IT teams, are looking at how to optimize the end-to-end process to achieve higher deployment frequency.14
•CSG (2013): In 2013, CSG International had $747 million in revenue and over thirty-five hundred employees, enabling over ninety thousand customer service agents to provide billing operations and customer care to over fifty million video, voice, and data customers, executing over six billion transactions, and printing and mailing over seventy million paper bill statements every month. Their initial scope of improvement was bill printing, one of their primary businesses, and involved a COBOL mainframe application and the twenty surrounding technology platforms. As part of their transformation, they started performing daily deployments into a production-like environment and doubled the frequency of customer releases from twice annually to four times annually. As a result, they significantly increased the reliability of the application and reduced code deployment lead times from two weeks to less than one day.15
•Etsy (2009): In 2009, Etsy had thirty-five employees and was generating $87 million in revenue, but after they “barely survived the holiday retail season,” they started transforming virtually every aspect of how the organization worked, eventually turning the company into one of the most admired DevOps organizations and setting the stage for a successful 2015 IPO.16
•HP LaserJet (2007): By implementing automated testing and continuous integration, HP created faster feedback and enabled developers to quickly confirm that their command codes actually worked. You can read the full case study in Chapter 11.
 CASE STUDY: NEW TO SECOND EDITION
CASE STUDY: NEW TO SECOND EDITION
Kessel Run: The Brownfield Transformation of a Mid-Air Refueling System (2020)
In October 2015, the US Air Force struck a Doctors Without Borders hospital in Afghanistan, believing it to be an enemy stronghold. Afghan commandos were under fire, and the US needed to respond quickly. Unclassified analysis later showed that a number of failures contributed to this devastating outcome: there was no time to fully brief the crew and the aircraft didn’t have the latest data to identify the hospital. As Adam Furtado, Chief of Platform for Kessel Run, put it, “basically, a failed IT ecosystem caused an AC130 gunship to attack the wrong building.”17
Furtado continued to explain at the DevOps Enterprise Summit-Virtual Las Vegas 2020, “What happened here was not some kind of black swan event, it was predictable and it’s going to happen again.”18 They needed a solution.
Named after Han Solo’s famous smuggling route, an homage to their own need to “smuggle” these new ways of working into the Department of Defense (DOD), Kessel Run is the continuing effort within the US Air Force to solve the tough business challenges that traditional defense IT isn’t solving effectively. Made up of a small coalition, the group tests modern software practices, processes, and principles. Their focus is on the mission and a disregard for the status quo.
In the beginning, around 2010, walking into the DOD to work was like walking into a time machine, a completely analog environment circa 1974 where many collaborative tools, like chats and Google Docs, weren’t possible. As Adam Furtado says, “You shouldn’t have to go back in time to go to work.”19
Eric Schmidt, Executive Chairman at Google, even testified to the US Congress in September of 2020 that “the DOD violates every rule of modern product development.”20
These kinds of problems weren’t exclusive to the DOD. According to the US Digital Service, 94% of federal IT projects across the entire government were behind schedule or over budget, and 40% of them were never delivered.21
The Kessel Run coalition was watching companies like Adidas and Walmart become software companies. They wanted to transform the US Air Force into a software company that could win wars. So they turned their attention to the critcal business outcome in front of them: modernizing the Air Force’s Air Operation Center.
There are several physical Air Operation Centers (AOCs) around the world from which the US Air Force strategizes, plans, and executes air campaigns. Due to archaic infrastructure, all this work is done by specific people, in specific buildings, located in specific locations, to access specific data on specific hardware, a brick-and-mortar approach that has been in place for decades. The only updates they’ve been able to implement are Microsoft Office updates.
“You might think I’m lying, but a recent search showed 2.8 million Excel and PowerPoint files on one of the servers in one of the locations,” said Adam Furtado.22
Gall’s Law states that if you want a complex system to work, build a simpler system first, then improve over time. The Kessel Run coalition did just that by applying the Strangler Fig Pattern, otherwise known as the Encasement Strategy, to incrementally and iteratively implement more modern software systems and processes at twenty-two physical locations, each with their own software and hardware, while keeping the whole system working.
They started with a specific process: mid-air refueling. This process requires massive coordination to ensure refueling tankers are where they need to be, at the right time, at the right altitude, with the right hardware to refuel the correct aircraft. The process involved several pilots to plan every day using color pucks, an Excel macro, and lots of data entry. They had become largely efficient, but only to the point that their brains would allow, and they couldn’t react quickly to changes.
Kessel Run brought in a team to digitize their process using DevOps principles, extreme programming, and balanced team models. They got their initial minimally viable product out to users in just weeks. This early program created enough efficiency that it kept one aircraft and its crew from flying every day, a fuel savings of $214,000 a day.23
They kept iterating. After thirty iterations, they were able to double the savings, keeping two aircraft and crew on the ground a day. The new approach saved $13 million in fuel a month and cut the planning crew in half.24
While this case study shows a great DevOps transformation in general, it also wonderfully illustrates transforming brownfield practices. Kessel Run successfully reduced the complexity and improved the reliability and stability of the mid-air refueling system, helping the US Air Force to move and change faster and more safely.
Consider Both Systems of Record and Systems of Engagement
The Gartner global research and advisory firm popularized the notion of bimodal IT, referring to the wide spectrum of services that typical enterprises support.25 Within bimodal IT there are systems of record, the ERP-like systems that run our business (e.g., MRP, HR, financial reporting systems), where the correctness of the transactions and data are paramount; and systems of engagement, which are customer-facing or employee-facing systems, such as e-commerce systems and productivity applications.
Systems of record typically have a slower pace of change and often have regulatory and compliance requirements (e.g., SOX). Gartner calls these types of systems “Type 1,” where the organization focuses on “doing it right.”26
Systems of engagement typically have a much higher pace of change to support rapid feedback loops that enable them to experiment to discover how to best meet customer needs. Gartner calls these types of systems “Type 2,” where the organization focuses on “doing it fast.”27
It may be convenient to divide up our systems into these categories; however, we know that the core, chronic conflict between “doing it right” and “doing it fast” can be broken with DevOps. The data from six years of State of DevOps Reports show that high-performing organizations are able to simultaneously deliver higher levels of throughput and reliability.28
Furthermore, because of how interdependent our systems are, our ability to make changes to any of these systems is limited by the system that is most difficult to safely change, which is almost always a system of record.
Scott Prugh, VP of Product Development at CSG, observed, “We’ve adopted a philosophy that rejects bi-modal IT because every one of our customers deserve speed and quality. This means that we need technical excellence, whether the team is supporting a thirty-year-old mainframe application, a Java application, or a mobile application.”29
Consequently, when we improve brownfield systems, we should not only strive to reduce their complexity and improve their reliability and stability, but also make them faster, safer, and easier to change. Even when new functionality is added just to greenfield systems of engagement, they often cause reliability problems in the brownfield systems of record they rely on. By making these downstream systems safer to change, we help the entire organization more quickly and safely achieve its goals.
Start With the Most Sympathetic and Innovative Groups
Within every organization, there will be teams and individuals with a wide range of attitudes toward the adopting new ideas. Geoffrey A. Moore first depicted this spectrum in the form of the technology adoption life cycle in Crossing the Chasm, where the chasm represents the classic difficulty of reaching groups beyond the innovators and early adopters (see Figure 5.1).30
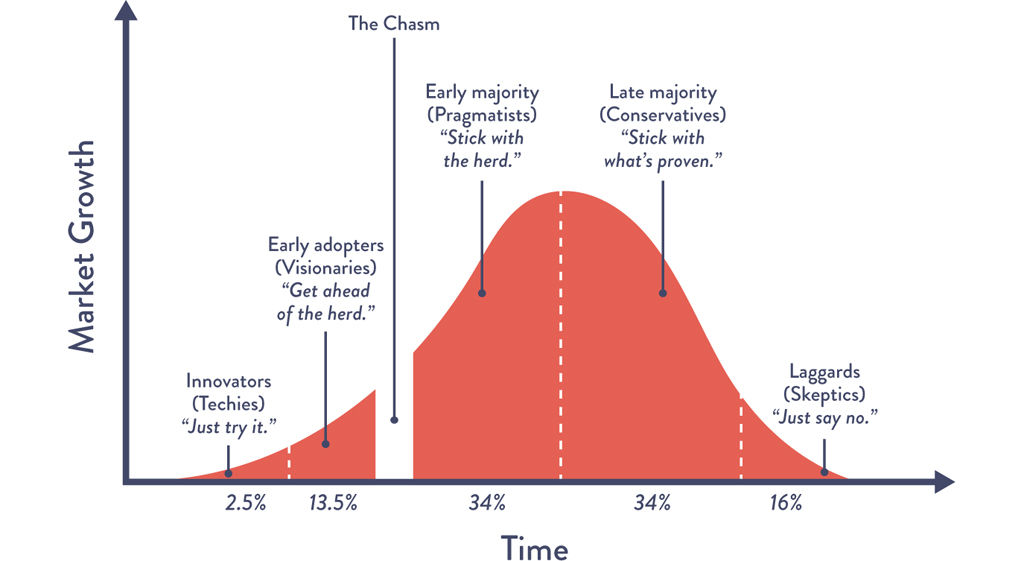
Figure 5.1: The Technology Adoption Curve
Source: Moore and McKenna, Crossing the Chasm, 15.
In other words, new ideas are often quickly embraced by innovators and early adopters, while others with more conservative attitudes resist them (the early majority, late majority, and laggards). Our goal is to find those teams that already believe in the need for DevOps principles and practices and that possess a desire and demonstrated ability to innovate and improve their own processes. Ideally, these groups will be enthusiastic supporters of the DevOps journey.
Especially in the early stages, we will not spend much time trying to convert the more conservative groups. Instead, we will focus our energy on creating successes with less risk-averse groups and build out our base from there (a process that is discussed further in the next section). Even if we have the highest levels of executive sponsorship, we will avoid the big-bang approach (i.e., starting everywhere all at once), choosing instead to focus our efforts in a few areas of the organization, ensuring that those initiatives are successful, and expanding from there.§
Expanding DevOps Across Our Organization
Regardless of how we scope our initial effort, we must demonstrate early wins and broadcast our successes. We do this by breaking up our larger improvement goals into small, incremental steps. This not only creates our improvements faster, it also enables us to discover when we have made the wrong choice of value stream—by detecting our errors early, we can quickly back up and try again, making different decisions armed with our new learnings.
As we generate successes, we earn the right to expand the scope of our DevOps initiative. We want to follow a safe sequence that methodically grows our levels of credibility, influence, and support. The following list, adapted from a course taught by Dr. Roberto Fernandez, a William F. Pounds Professor in Management at MIT, describes the ideal phases used by change agents to build and expand their coalition and base of support:31
•Find innovators and early adopters: In the beginning, we focus our efforts on teams who actually want to help—these are our kindred spirits and fellow travelers who are the first to volunteer to start the DevOps journey. In the ideal, these are also people who are respected and have a high degree of influence over the rest of the organization, giving our initiative more credibility.
•Build critical mass and silent majority: In the next phase, we seek to expand DevOps practices to more teams and value streams with the goal of creating a stable base of support. By working with teams who are receptive to our ideas, even if they are not the most visible or influential groups, we expand our coalition who are generating more successes, creating a “bandwagon effect” that further increases our influence. We specifically bypass dangerous political battles that could jeopardize our initiative.
•Identify the holdouts: The “holdouts” are the high-profile, influential detractors who are most likely to resist (and maybe even sabotage) our efforts. In general, we tackle this group only after we have achieved a silent majority and have established enough successes to successfully protect our initiative.
Expanding DevOps across an organization is no small task. It can create risk to individuals, departments, and the organization as a whole. But as Ron van Kemenade, CIO of ING, who helped transform the organization into one of the most admired technology organizations, said, “Leading change requires courage, especially in corporate environments where people are scared and fight you. But if you start small, you really have nothing to fear. Any leader needs to be brave enough to allocate teams to do some calculated risk-taking.”32
CASE STUDY: NEW TO SECOND EDITION
Scaling DevOps across the Business: American Airlines’
DevOps Journey (Part 2) (2020)
As we learned in Part 1 of the American Airlines DevOps transformation, their journey spanned several years. By year three, they had realized that DevOps was really a bigger transformation than just a way of working in IT—it was a business transformation.
Their next challenge became how to scale these new ways of working across the entire business to accelerate and further execute their transformation and their learnings. They brought in Ross Clanton as Chief Architect and Managing Director to help guide them to the next level.
To drive the conversation across the organization, American Airlines focused on two things:33 the why (building a competitive advantage) and the how (business and IT teams working together to maximize business value).
To scale the vision that was set in IT, “deliver value faster,” they mapped out a transformation based on the following structure of four key pillars:34
•delivery excellence: how we work (practices, product mindset)
•operating excellence: how we’re structured (product taxonomy, funding model, operating model, prioritization)
•people excellence: growing talent and culture (including evolving leadership behaviors)
•technology excellence: modernization (infrastructure and technology foundation, automation, move to the cloud, etc.)
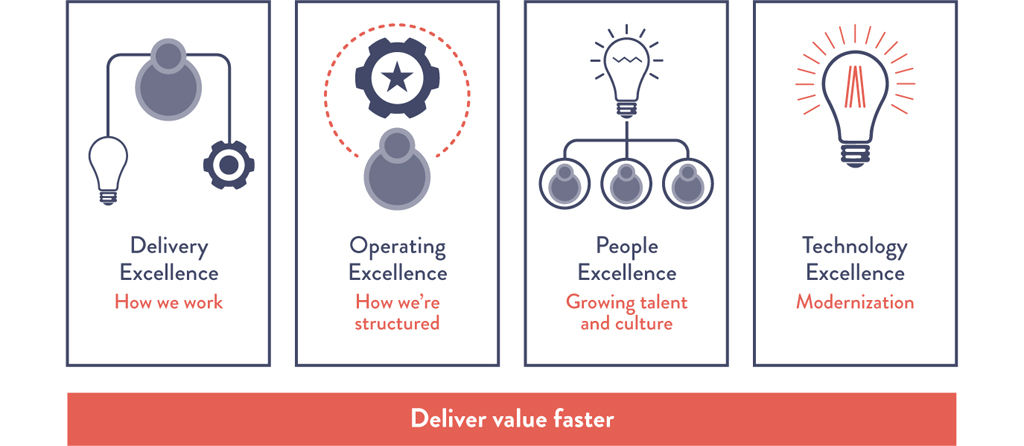
Figure 5.2: American Airlines’ Delivery Transformation
Source: Maya Leibman and Ross Clanton, “DevOps: Approaching Cruising Altitude,” presentation at DevOps Enterprise Summit-Virtual Las Vegas 2020, videolibrary.doesvirtual.com/?video=467488959.
Once they had their transformation scaling strategy in place, they had to focus on scaling the culture across the business in order to continue to drive the transformation forward.
As Clanton said in his presentation at DevOps Enterprise Summit in 2020, quoting Peter Drucker, “Culture eats strategy for breakfast.”35
To scale the culture, they focused on three key attributes:36
1.Passion: teams focused on delighting customers, being the best at getting better, embrace failure and get stronger because of it.
2.Selflessness: collaborate and share knowledge and code across organization, innersourcing, making space for others’ voices and helping others win.
3.Accountability: own the outcomes even when they’re hard; how you do something is as important as what you do.
By focusing on these three cultural pillars, the teams at American Airlines are now “empowered and going out of their way to empower others,” according to Clanton.37 As the global pandemic hit in 2020, American Airlines focused on the following values to ensure their teams could still achieve success and results even amidst global change:38
•action and doing over analysis
•collaboration over silos
•clarity of mission over trying to do everything
•empowerment over personal stamp on every effort (set the goals and empower teams to get there)
•getting something out (MVP) versus getting something perfect
•“We can do this” versus hierarchy (collaboration across org boundaries)
•finishing versus starting (limiting WIP and focusing on top priorities)
Instead of throwing requirements over a wall, American Airlines now has a team of stakeholders from the business, IT, Design, etc. They pivoted their planning model so leaders define clear outcomes and the teams are able to decide how they deliver on those outcomes. The teams deliver by focusing on small tasks that add value incrementally. By keeping tasks small, the teams are able to finish quickly (driving value faster) and focus on finishing not starting.
To enable all of this change, leadership needed to change their ways of working as well. Leaders have pivoted to serving the teams, removing impediments and constraints that prevent the teams from delivering value. Instead of status meetings, leadership attend playback meetings (demos) to see what the teams are doing and provide guidance in the moment.
American Airlines also realized that to help change the mindset of leaders and to get everyone aligned in thinking, talking, and acting from an Agile/DevOps perspective, they needed to provide a new vocabulary. Table 5.1 shows some of the ways they helped pivot the conversation.
As Doug Parker, CEO of American Airlines related,
. . . [the transformation] is making us more efficient, we get projects done more quickly, the projects delivered are more designed to what the users need . . . it’s already making a huge difference to how to manage projects at American Airlines.
What I’m most proud of is the champion of delivery transformation is not IT anymore; it’s the business leaders who embraced it. They see how much faster they’re getting the work done, and they’re spreading the word everywhere else. And that’s making a big difference.39
Table 5.1: American Airlines’ New Vocabulary
|
Before
|
After
|
|
I want to create a pop-up to incentivize people to download the mobile app.
|
Fragile applications are prone to failure.
|
|
What did our competitors do?
|
What do our customers value?
|
|
When will this project be done?
|
When do we start seeing value?
|
|
What went wrong?
|
What did we learn and how can I help?
|
|
I want a completely new website.
|
What’s the first thing we can try to experiment with this idea?
|
Source: Maya Leibman and Ross Clanton, “DevOps: Approaching Cruising Altitude,” presentation at DevOps Enterprise Summit-Virtual Las Vegas 2020, ideolibrary.doesvirtual.com/?video=467488959.
American Airlines built a critical mass and silent majority by focusing on the how and why, as well as changing the vocabulary to achieve a common language.
CASE STUDY: NEW FOR SECOND EDITION
Saving the Economy From Ruin (With a Hyperscale PaaS) at HMRC (2020)
HMRC, Her Majesty’s Revenue and Customs, is the tax collection agency for the UK government. In 2020, HMRC distributed hundreds of billions of pounds to UK citizens and businesses in an unprecedented financial support package that would eventually see around 25% of the entire UK workforce supported by public money. HMRC built the technology to do this in just four weeks, under conditions of incredible pressure and uncertainty.40
HMRC’s challenges went way beyond aggressive timescales. “We knew we would have millions of users, but nobody could actually tell us how many. So whatever we built had to be accessible to everyone and had to be capable of paying out billions into bank accounts within hours of launch. It also needed to be secure, with checks being conducted before money was paid out,” says Ben Conrad, HMRC’s Head of Agile Delivery, at the 2021 DevOps Enterprise Summit-Europe.41
And they nailed it. All the services launched on time, with most launching a week or two ahead of expectations without any issues, resulting in a 94% user satisfaction rating.42 HMRC went from being the least popular of all government departments to the people customers relied on to help out.
In order to achieve this amazing result, HMRC adopted some key processes and leveraged a mature digital platform, one that had evolved over the last seven years to allow teams to build digital services rapidly and deliver them at hyper-scale.
HMRC’s platform (the Multichannel Digital Tax Platform or MDTP) is a collection of infrastructure technologies that enable the organization to serve content to users over the internet. Business domains within HMRC can expose tax services to the public by funding a small cross-functional team to build a microservice or a set of microservices on the platform. MDTP removes much of the pain and complexity of getting a digital service in front of a user by providing tenants with a suite of common components that are necessary to develop and run high-quality digital products.
MDPT is the largest digital platform in the UK government and one of the largest platforms in the UK as a whole. It hosts about 1,200 microservices built by more than two thousand people split into seventy teams across eight geographic locations (although, since March 2020, the teams have all worked 100% remotely).43 These teams make about one hundred deployments into production every day.
“The teams use agile methods, with deliberately lightweight governance, and they’re trusted to make changes themselves whenever and as ever they see fit,” says Matt Hyatt, Technical Delivery Manager with Equal Experts. “It only takes a few seconds to push changes through our infrastructure, so getting products and services in front of users happens really fast.”44
Pivotal to the success of the platform has been a constant focus on three key things: culture, tooling, and practices. MDTP’s goal is to make it easy to add teams, build services, and deliver value quickly. The platform has evolved around that goal so that a cross-functional team can be spun up quickly and then use the common tooling to design, develop, and operate a new public-facing service.
In practice, the MDPT provides a place for a digital team’s code to live and automated pipelines for the code to be built and deployed through various environments and into production, where the team can get rapid user feedback. Common telemetry tooling is configured to enable a team to monitor its services via automated dashboards and alerting mechanisms so that they always know what’s going on. The platform provides teams with collaboration tools to help them communicate, internally and between one another, so that they can work effectively, both remotely and in person. This is all made available to a team more or less instantly, with minimal configuration or manual steps required. The idea is to free the digital team so it can focus solely on solving business problems.
With over two thousand people making changes, potentially several times a day, things could get very messy. To avoid this, MDTP uses the concept of an opinionated platform (also known as a paved road platform or guardrails). For instance, if you build a microservice, it must be written in Scala and use the Play framework. If your service needs persistence, it must use Mongo. If a user needs to perform a common action like uploading a file, then the team must use a common platform service to enable that when there is one. Essentially, a little bit of governance is baked into the platform itself. The benefit to the teams of sticking to the rails is that they can deliver services extraordinarily quickly.
But the benefits don’t stop there. By limiting the technology used on the platform, it’s far simpler to support. Moreover, digital teams are prevented from spending time rolling their own solutions to problems that have already been solved elsewhere.
“We can provide common services and reusable components that we know work with all the services. It also allows people to move between services, and, indeed, allows the services to move to new teams without worrying about whether our people have the required skills to do the job,” says Hyatt.45
Another key differentiator is that MDTP abstracts the need to care about infrastructure away from digital teams, allowing them to focus solely on their apps. “They can still observe the infrastructure through tools like Kibana and Grafana, but none of the service teams have access to AWS accounts themselves,” Hyatt notes.46
Importantly, the opinions of this “opinionated platform” can and do change according to user needs and demands, with a focus on self-service. “A service can be created, developed, and deployed on our platform without any direct involvement from platform teams at all,” Hyatt says.47
MDTP plays an important role in enabling the rapid delivery of the COVID-19 financial support package, but this isn’t the whole story. A herculean effort by the team was still required. Good decision-making and fast adaptation of processes also proved vital.
“The most important aspect of delivering a system at speed is the ability for engineers to ‘just get on with it,’” says Hyatt.48 A combination of balanced governance, established best practices, and a mandate from HMRC teams to use proven tooling meant they weren’t risking new technology problems or security concerns that would have ultimately delayed delivery.
To meet the aggressive timescales, the teams also adapted their composition and communication. A platform engineer was embedded into each COVID-19 digital service team to safely “short-circuit” existing processes. This allowed the teams to eliminate risks early and maximize collaboration, particularly on requests for new infrastructure components and for help with performance testing. Those working on the key services were also made easily identifiable via collaboration tooling, like Slack, so that requests for help could be prioritized, not just by the platform teams but by the whole two thousand–strong digital community.
The ability of the teams and business leaders to adapt so quickly in unison and then flex back into place once the services were launched is a great demonstration of the mature DevOps culture at HMRC.
The HMRC case study illustrates how much can be accomplished using a PaaS in any large organization.
Conclusion
Peter Drucker, a leader in the development of management education, observed that “little fish learn to be big fish in little ponds.”49 By carefully choosing where and how to start, we are able to experiment and learn in areas of our organization that create value without jeopardizing the rest of the organization. By doing this, we build our base of support, earn the right to expand the use of DevOps in our organization, and gain the recognition and gratitude of an ever-larger constituency.
* |
These organizations were sometimes known as the “killer B’s that are dying.”4 |
† |
The practice of relying on a stabilization phase or hardening phase at the end of a project often has very poor outcomes because it means problems are not being found and fixed as part of daily work and are left unaddressed, potentially snowballing into larger issues. |
‡ |
That the services that have the largest potential business benefit are brownfield systems shouldn’t be surprising. After all, these are the systems that are most relied upon and have the largest number of existing customers or highest amount of revenue depending upon them. |
§ |
Big-bang, top-down transformations are possible, such as the Agile transformation at PayPal in 2012 that was led by their vice president of technology, Kirsten Wolberg. However, as with any sustainable and successful transformation, this required the highest level of management support and a relentless, sustained focus on driving the necessary outcomes. |