3
THE SECOND WAY: THE PRINCIPLES OF FEEDBACK
While the First Way describes the principles that enable the fast flow of work from left to right, the Second Way describes the principles that enable the reciprocal fast and constant feedback from right to left at all stages of the value stream. Our goal is to create an ever-safer and more resilient system of work.
This is especially important when working in complex systems, when catastrophic outcomes, such as a manufacturing worker being hurt on the job or a nuclear reactor meltdown in progress, can result from errors.
In technology, our work happens almost entirely within complex systems with a high risk of catastrophic consequences. As in manufacturing, we often discover problems only when large failures are underway, such as a massive production outage or a security breach resulting in the theft of customer data.
We make our systems of work safer by creating fast, frequent, high-quality information flow throughout our value stream and our organization, which includes feedback and feedforward loops. This allows us to detect and remediate problems while they are smaller, cheaper, and easier to fix; to avert problems before they cause catastrophe; and to create organizational learning that we integrate into future work. When failures and accidents occur, we treat them as opportunities for learning, as opposed to causes for punishment and blame. To achieve all of the above, let us first explore the nature of complex systems and how they can be made safer.
Working Safely within Complex Systems
One of the defining characteristics of a complex system is that it defies any single person’s ability to see the system as a whole and understand how all the pieces fit together. Complex systems typically have a high degree of interconnectedness of tightly coupled components and system-level behavior that cannot be explained merely in terms of the behavior of the system components.
Dr. Charles Perrow studied the Three Mile Island partial nuclear meltdown, observing that it was impossible for anyone to understand how the reactor would behave in all circumstances or how it might fail.1 When a problem was underway in one component, it was difficult to isolate it from other components. Failures quickly cascaded through the paths of least resistance in unpredictable ways.
Dr. Sidney Dekker, who also codified some key elements of safety culture, observed another characteristic of complex systems: doing the same thing twice will not predictably or necessarily lead to the same result.2 It is this characteristic that makes static checklists and best practices, while valuable, insufficient to prevent catastrophes from occurring or manage them effectively. (See Appendix 5.)
Therefore, because failure is inherent and inevitable in complex systems, we must design a safe system of work, whether in manufacturing or technology, where we can perform work without fear, confident that most errors will be detected quickly, long before they cause catastrophic outcomes, such as worker injury, product defects, or negative customer impact.
After he decoded the mechanics of the Toyota Production System as part of his doctoral thesis at Harvard Business School, Dr. Steven Spear stated that designing perfectly safe systems is likely beyond our abilities, but we can make it safer to work in complex systems when the four following conditions are met:3*
•Complex work is managed so that problems in design and operations are revealed.
•Problems are swarmed and solved, resulting in quick construction of new knowledge.
•New local knowledge is exploited globally throughout the organization.
•Leaders create other leaders who continually grow these types of capabilities.
Each of these capabilities is required to work safely in a complex system. In the next sections, the first two capabilities and their importance are described, as well as how they have been created in other domains and what practices enable them in the technology value stream. (The third and fourth capabilities are described in Chapter 4.)
See Problems as They Occur
In a safe system of work, we must constantly test our design and operating assumptions. Our goal is to increase information flow in our system from as many areas as possible, sooner, faster, cheaper, and with as much clarity between cause and effect as possible. The more assumptions we can invalidate, the faster we can find and fix problems, increasing our resilience, agility, and ability to learn and innovate.
We do this by creating feedback and feedforward loops into our system of work. Dr. Peter Senge, in his book The Fifth Discipline: The Art & Practice of the Learning Organization, described feedback loops as a critical part of learning organizations and systems thinking.5 Feedback and feedforward loops cause effects within a system to reinforce or counteract each other.
In manufacturing, the absence of effective feedback often contributes to major quality and safety problems. In one well-documented case at the General Motors Fremont manufacturing plant, there were no effective procedures in place to detect problems during the assembly process, nor were there explicit procedures on what to do when problems were found. As a result, there were instances of engines being put in backward, cars missing steering wheels or tires, and cars even having to be towed off the assembly line because they wouldn’t start.6
In contrast, in high-performing manufacturing operations there is fast, frequent, and high-quality information flow throughout the entire value stream—every work operation is measured and monitored, and any defects or significant deviations are quickly found and acted upon by the people doing the work. This is the foundation of what enables quality, safety, and continual learning and improvement.
In the technology value stream, we often get poor outcomes because of the absence of fast feedback. For instance, in a waterfall software project, we may develop code for an entire year and get no feedback on quality until we begin the testing phase—or, worse, when we release our software to customers. When feedback is this delayed and infrequent, it is too slow to enable us to prevent undesirable outcomes.
In contrast, our goal is to create fast feedback and feedforward loops wherever work is performed, at all stages of the technology value stream, encompassing Product Management, Development, QA, Infosec, and Operations. This includes the creation of automated build, integration, and test processes so that we can immediately detect when a change has been introduced that takes us out of a correctly functioning and deployable state.
We also create pervasive telemetry so we can see how all our system components are operating in testing and production environments so that we can quickly detect when they are not operating as expected. Telemetry also allows us to measure whether we are achieving our intended goals and, ideally, is radiated to the entire value stream so we can see how our actions affect other portions of the system as a whole.
Feedback loops not only enable quick detection and recovery of problems but also inform us on how to prevent these problems from occurring again in the future. Doing this increases the quality and safety of our system of work and creates organizational learning.
As Elisabeth Hendrickson, VP of Engineering at Pivotal Software, Inc. and author of Explore It!: Reduce Risk and Increase Confidence with Exploratory Testing, said, “When I headed up quality engineering, I described my job as ‘creating feedback cycles.’ Feedback is critical because it is what allows us to steer. We must constantly validate between customer needs, our intentions and our implementations. Testing is merely one sort of feedback.”7
Feedback Types and Cycle Times
According to Elisabeth Hendrickson in her 2015 DevOps Enterprise Summit presentation, there are six types of feedback in software development:8
•Dev Tests: As a programmer, did I write the code I intended to write?
•Continuous Integration (CI) and Testing: As a programmer, did I write the code I intended to write without violating any existing expectations in the code?
•Exploratory Testing: Did we introduce any unintended consequences?
•Acceptance Testing: Did I get the feature I asked for?
•Stakeholder Feedback: As a team, are we headed in the right direction?
•User Feedback: Are we producing something our customers/users love?
And each type of feedback takes a different amount of time. Think of it as a series of concentric circles. The fastest loops are at the developer’s station (local tests, test-driven development, etc.) and the longest are the customer or user feedback at the very end of the cycle (as seen in Figure 3.1)
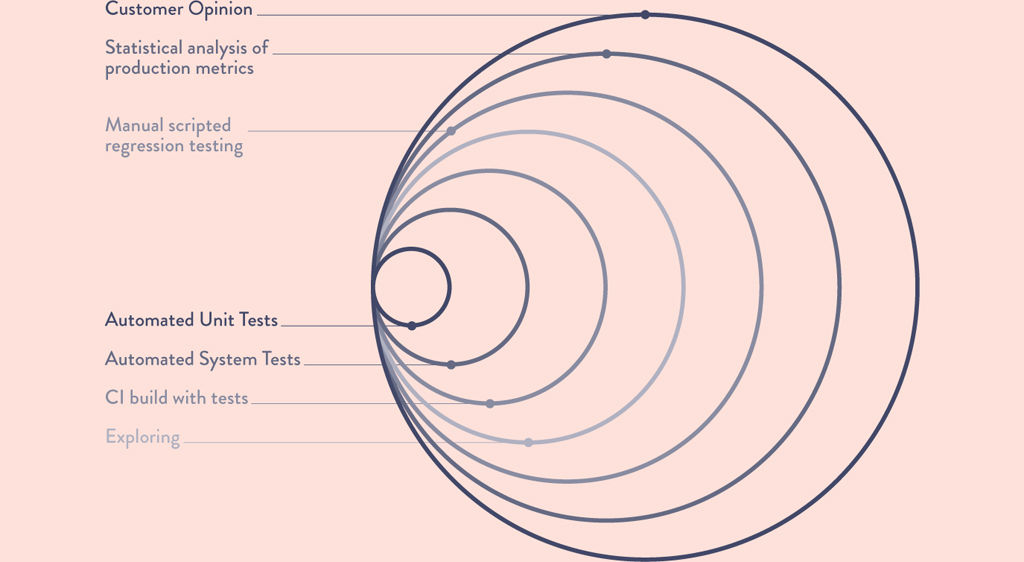
Figure 3.1: Feedback Cycle Times
Source: Hendrickson, Elisabeth. “DOES15—Elisabeth Hendrickson—Its All About Feedback.” Posted by DevOps Enterprise Summit, November 5, 2015. YouTube video, 34:47. https://www.youtube.com/watch?v=r2BFTXBundQ.
Swarm and Solve Problems to Build New Knowledge
Obviously, it is not sufficient to merely detect when the unexpected occurs. When problems occur, we must swarm them, mobilizing whoever is required to solve the problem.
According to Dr. Spear, the goal of swarming is to contain problems before they have a chance to spread, and to diagnose and treat the problem so that it cannot recur. “In doing so,” he says, “they build ever-deeper knowledge about how to manage the systems for doing our work, converting inevitable up-front ignorance into knowledge.”9
The paragon of this principle is the Toyota Andon cord. In a Toyota manufacturing plant, above every work center is a cord that every worker and manager is trained to pull when something goes wrong; e.g., a part is defective, a required part is not available, or even if work takes longer than documented.†
When the Andon cord is pulled, the team leader is alerted and immediately works to resolve the problem. If the problem cannot be resolved within a specified time (e.g., fifty-five seconds), the production line is halted so that the entire organization can be mobilized to assist with problem resolution until a successful countermeasure has been developed.
Instead of working around the problem or scheduling a fix “when we have more time,” we swarm to fix it immediately—this is nearly the opposite of the behavior at the GM Fremont plant described earlier.
Swarming is necessary for the following reasons:
•It prevents the problem from progressing downstream, where the cost and effort to repair it increases exponentially and technical debt is allowed to accumulate.
•It prevents the work center from starting new work, which will likely introduce new errors into the system.
•If the problem is not addressed, the work center could potentially have the same problem in the next operation (e.g., fifty-five seconds later), requiring more fixes and work. (See Appendix 6.)
This practice of swarming seems contrary to common management practice, as we are deliberately allowing a local problem to disrupt operations globally. However, swarming enables learning. It prevents the loss of critical information due to fading memories or changing circumstances. This is especially critical in complex systems, where many problems occur because of some unexpected, idiosyncratic interaction of people, processes, products, places, and circumstances—as time passes, it becomes impossible to reconstruct exactly what was going on when the problem occurred.
As Dr. Spear notes, swarming is part of the “disciplined cycle of real-time problem recognition, diagnosis . . . and treatment (countermeasures or corrective measures in manufacturing vernacular). It [is] the discipline of the Shewhart cycle—plan, do, check, act—popularized by Dr. W. Edwards Deming, but accelerated to warp speed.”10
It is only through the swarming of ever-smaller problems discovered ever-earlier in the life cycle that we can deflect problems before a catastrophe occurs. In other words, when the nuclear reactor melts down, it is already too late to avert the worst outcomes.
To enable fast feedback in the technology value stream, we must create the equivalent of an Andon cord and the related swarming response. This requires that we also create the culture that makes it safe, and even encouraged, to pull the Andon cord when something goes wrong, whether it is when a production incident occurs or when errors occur earlier in the value stream, such as when someone introduces a change that breaks our continuous build or test processes.
When conditions trigger an Andon cord pull, we swarm to solve the problem and prevent the introduction of new work until the issue has been resolved.‡ This provides fast feedback for everyone in the value stream (especially the person who caused the system to fail), enables us to quickly isolate and diagnose the problem, and prevents further complicating factors that can obscure cause and effect.
Preventing the introduction of new work enables continuous integration and deployment, which is “single-piece flow” in the technology value stream. All changes that pass our continuous build and integration tests are deployed into production, and any changes that cause any tests to fail trigger our Andon cord and are swarmed until resolved.
 CASE STUDY: NEW TO SECOND EDITION
CASE STUDY: NEW TO SECOND EDITION
Pulling the Andon Cord at Excella (2018)
Excella is an IT consulting firm. In 2019 at the DevOps Enterprise Summit, Zack Ayers, Scrum Master, and Joshua Cohen, Sr. Developer, discussed their experiments using an Andon cord to decrease cycle time, improve collaboration, and achieve a culture of higher psychological safety.11
Excella noticed during a team retrospective that their cycle times were beginning to rise. They had what Joshua Cohen described as a case of the “almost dones.” He noted, “During standup, our developers would give an update on the feature they were working on the previous day. They would say, ‘Hey, I made a lot of progress. I’m almost done.’ And the next morning they would say, ‘Hey, I ran into some issues but I worked through them. I just have a few more tests to run. I’m almost done.’”12
This case of the “almost dones” was happening too frequently. The team decided this was an area they wanted to improve. They noticed that teammates were only bringing up issues at specific times, like during standups. They wanted the team to shift their practice to collaborating as soon as the issue was identified, not waiting until the next day’s standup or meeting.
The team decided to experiment with the idea of an Andon cord. They had two key parameters: (1) When the cord was “pulled,” everyone would stop work to identify a path toward resolution. (2) The cord would be pulled whenever someone on the team felt stuck or needed team's help.
Instead of a literal string or cord to pull, the team created a bot in Slack as a metaphorical Andon cord. When someone typed in andon, the bot would @here the team, notifying everyone in Slack. But they didn’t want to end it there. They also created an “if/this/then/that” integration in Slack that would turn on a rotating red light, string lights, and even a dancing “tube” man in the office.
To measure their Andon cord experiment, the team decided to focus on reduction in cycle time as the key metric for success, as well as increasing the team’s collaboration and getting rid of the “almost dones” by talking about issues when they arose.
In the beginning of the experiment in 2018, their cycle time hovered around three days in progress. Over the following weeks, as the Andon cord began to be pulled, they saw a slight decrease in cycle time. A few weeks later, they stopped pulling the Andon cord and saw their cycle time rise to nearly eleven days, an all-time high.13
They evaluated what was happening with the experiment. They realized that while pulling the cord was fun, they weren’t pulling it often enough because people were afraid to ask for help and they didn’t want to disturb their teammates.
In order to alleviate this, they changed how they defined when teammates should pull the Andon cord. Instead of the cord being pulled whenever a team member was stuck, they would pull the cord whenever they needed the opinion of the team.
With this change, they saw a huge uptick in the number of Andon cord pulls and a corresponding decrease in cycle time.
Each time the team saw Andon cord pulls drop, they found new ways to incentivize pulls, and each time they saw their cycle times decrease with increased pulls. The team continued to iterate and eventually moved the Andon cord experiment into a practice and finally scaled it product wide, using "Andon: Code Red" to report major issues.
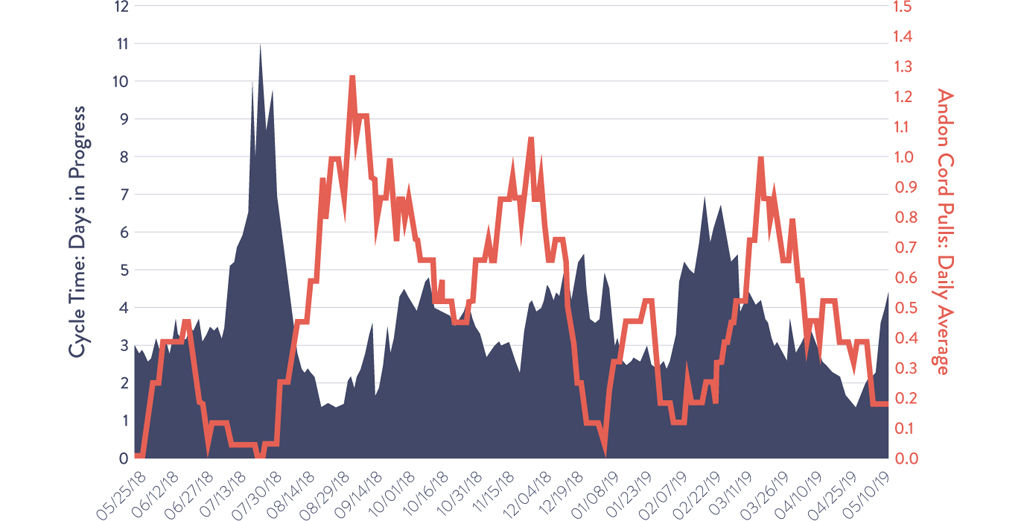
Figure 3.2: Cycle Time vs. Andon Pulls at Excella
Source: Zach Ayers and Joshua Cohen. “Andon Cords in Development Teams—Driving Continuous Learning,” presentation at the DevOps Enterprise Summit Las Vegas, 2019. https://videolibrary.doesvirtual.com/?video=504281981.
In addition to cycle time, they found that the Andon cord promoted psychological safety. Teammates spoke up more and offered more creative solutions.
As Jeff Gallimore, Chief Technology and Innovation Officer and Cofounder of Excella, explains:
One of the counterintuitive learnings from this experiment was it challenged the generally held belief that, for developers and engineers in particular, you shouldn’t interrupt flow because it hurts individual productivity. However, that’s exactly what the Andon cord does, for the benefit of team flow and productivity.14
This case study highlights the amazing effectiveness of swarming to solve problems before a local issue can become a global issue, and how the creative integration of an Andon cord system helps decrease cycle times and improve collaboration.
Keep Pushing Quality Closer to the Source
We may inadvertently perpetuate unsafe systems of work due to the way we respond to accidents and incidents. In complex systems, adding more inspection steps and approval processes actually increases the likelihood of future failures. The effectiveness of approval processes decreases as we push decision-making further away from where the work is performed. Doing so not only lowers the quality of decisions but also increases our cycle time, thus decreasing the strength of the feedback between cause and effect and reducing our ability to learn from successes and failures.§
This can be seen even in smaller and less complex systems. When top-down, bureaucratic, command-and-control systems become ineffective, it is usually because the variance between “who should do something” and “who is actually doing something” is too large, due to insufficient clarity and timeliness.
Examples of ineffective quality controls, per Lean Enterprise, include:16
•Requiring another team to complete tedious, error-prone, and manual tasks that could be easily automated and run as needed by the team who needs the work performed.
•Requiring approvals from busy people who are distant from the work, forcing them to make decisions without adequate knowledge of the work or the potential implications, or to merely rubber stamp their approvals.
•Creating large volumes of documentation of questionable detail, which become obsolete shortly after they are written.
•Pushing large batches of work to teams and special committees for approval and processing and then waiting for responses.
Instead, we need everyone in our value stream to find and fix problems in their area of control as part of their daily work. By doing this, we push quality and safety responsibilities and decision-making to where the work is performed, instead of relying on approvals from distant executives.
We use peer reviews of our proposed changes to gain whatever assurance is needed that our changes will operate as designed. We automate as much of the quality checking typically performed by a QA or Information Security department as possible. Instead of developers needing to request or schedule a test to be run, these tests can be performed on demand, enabling developers to quickly test their own code and even deploy those changes into production themselves.
By doing this, we truly make quality everyone’s responsibility as opposed to it being the sole responsibility of a separate department. Information security is not just Information Security’s job, just as availability isn’t merely the job of Operations.
Having developers share responsibility for the quality of the systems they build not only improves outcomes but also accelerates learning. This is especially important for developers, as they are typically the team that is furthest removed from the customer. As Gary Gruver observes, “It’s impossible for a developer to learn anything when someone yells at them for something they broke six months ago—that’s why we need to provide feedback to everyone as quickly as possible, in minutes, not months.”17
Enable Optimizing for Downstream Work Centers
In the 1980s, designing for manufacturability principles sought to design parts and processes so that finished goods could be created with the lowest cost, highest quality, and fastest flow. Examples include designing parts that are wildly asymmetrical to prevent them from being put on backward and designing screw fasteners so that they are impossible to over-tighten.
This was a departure from how design was typically done, which focused on the external customers but overlooked internal stakeholders, such as the people performing the manufacturing.
Lean defines two types of customers that we must design for: the external customer (who most likely pays for the service we are delivering) and the internal customer (who receives and processes the work immediately after us). According to Lean, our most important customer is our next step downstream. Optimizing our work for them requires that we have empathy for their problems in order to better identify the design problems that prevent fast and smooth flow.
In the technology value stream, we optimize for downstream work centers by designing for operations, where operational non-functional requirements (e.g., architecture, performance, stability, testability, configurability, and security) are prioritized as highly as user features.
By doing this, we create quality at the source, resulting in a set of codified, non-functional requirements that we can proactively integrate into every service we build.
Conclusion
Creating fast feedback is critical to achieving quality, reliability, and safety in the technology value stream. We do this by seeing problems as they occur, swarming and solving problems to build new knowledge, pushing quality closer to the source, and continually optimizing for downstream work centers.
The specific practices that enable fast flow in the DevOps value stream are presented in Part IV of this book. In the next chapter, we present the Third Way, the Principles of Continual Learning and Experimentation.
* |
Dr. Spear extended his work to explain the long-lasting successes of other organizations, such as the Toyota supplier network, Alcoa, and the US Navy’s Nuclear Power Propulsion Program.4 |
† |
In some of its plants, Toyota has moved to using an Andon button. |
‡ |
Astonishingly, when the number of Andon cord pulls drop, plant managers will actually decrease the tolerances to get an increase in the number of Andon cord pulls in order to continue to enable more learnings and improvements and to detect ever-weaker failure signals. |
§ |
In the 1700s, the British government engaged in a spectacular example of top-down, bureaucratic command and control, which proved remarkably ineffective. At the time, Georgia was still a colony, and despite the fact that the British government was three thousand miles away and lacked firsthand knowledge of local land chemistry, rockiness, topography, accessibility to water, and other conditions, it tried to plan Georgia’s entire agricultural economy. The results of the attempt were dismal and left Georgia with the lowest levels of prosperity and population in the thirteen colonies.15 |