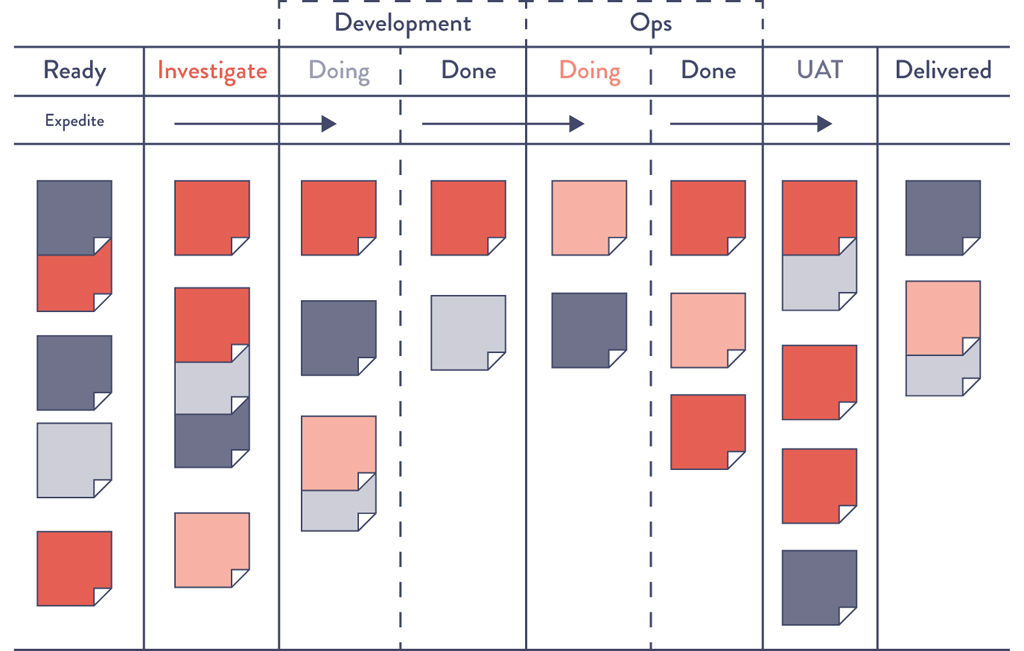
Figure 2.1: An Example Kanban Board Spanning Requirements, Dev, Test, Staging, and In Production
Source: David J. Andersen and Dominica DeGrandis, Kanban for IT Ops, training materials for workshop, 2012.
2
THE FIRST WAY: THE PRINCIPLES OF FLOW
In the technology value stream, work typically flows from Development to Operations, the functional areas between our business and our customers. The First Way requires the fast and smooth flow of work from Development to Operations in order to deliver value to customers quickly. We optimize for this global goal instead of local goals, such as Development feature completion rates, test find/fix ratios, or Operations availability measures.
We increase flow by making work visible, by reducing batch sizes, and by building quality in, preventing defects from being passed to downstream work centers. By speeding up the flow through the technology value stream, we reduce the lead time required to fulfill internal and external customer requests, further increasing the quality of our work while making us more responsive to customer and market needs and able to out-experiment the competition.
Our goal is to decrease the amount of time required for changes to be deployed into production and to increase the reliability and quality of those services. Clues on how we do this in the technology value stream can be gleaned from how Lean principles were applied to the manufacturing value stream.
Make Our Work Visible
A significant difference between technology and manufacturing value streams is that our work is invisible. Unlike physical processes, in the technology value stream we cannot easily see where flow is being impeded or when work is piling up in front of constrained work centers. Transferring work between work centers in manufacturing is usually highly visible and slow because inventory must be physically moved.
However, in technology work the move can be done with a click of a button, such as by reassigning a work ticket to another team. Because it is so easy to move, work can bounce between teams endlessly due to incomplete information, or work can be passed onto downstream work centers with problems that remain completely invisible until we are late delivering what we promised to the customer or our application fails in the production environment.
To help us see where work is flowing well and where work is queued or stalled, we need to make our work as visible as possible. One of the best methods of doing this is using visual work boards, such as kanban boards or sprint planning boards, where work can be represented on physical or electronic cards. Work originates on the left (often being pulled from a backlog), is pulled from work center to work center (represented in columns), and finishes when it reaches the right side of the board, usually in a column labeled “done” or “in production.”
Not only does our work become visible, but we can also manage our work so that it flows from left to right as quickly as possible. This also helps surface unnecessary handoffs in our work, which can introduce errors and additional delays. Furthermore, we can measure lead time from when a card is placed on the board to when it is moved into the “done” column.
Ideally, our kanban board will span the entire value stream, defining work as completed only when it reaches the right side of the board (Figure 2.1). Work is not done when Development completes the implementation of a feature. Rather, it is only done when our application is running successfully in production, delivering value to the customer.
Figure 2.1: An Example Kanban Board Spanning Requirements, Dev, Test, Staging, and In Production
Source: David J. Andersen and Dominica DeGrandis, Kanban for IT Ops, training materials for workshop, 2012.
By putting all work for each work center in queues and making it visible, all stakeholders can more easily prioritize work in the context of global goals. Doing this enables each work center to single-task on the highest priority work until it is completed, increasing throughput.
Limit Work in Process (WIP)
In manufacturing, daily work is typically dictated by a production schedule that is generated regularly (e.g., daily, weekly), establishing which jobs must be run based on customer orders, order due dates, parts available, and so forth.
In technology, our work is usually far more dynamic—this is especially the case in shared services, where teams must satisfy the demands of many different stakeholders. As a result, daily work becomes dominated by the priority du jour, often with requests for urgent work coming in through every communication mechanism possible, including ticketing systems, outage calls, emails, phone calls, chat rooms, and management escalations.
Disruptions in manufacturing are also highly visible and costly. They often require breaking the current job and scrapping any incomplete work in process in order to start the new job. This high level of effort discourages frequent disruptions.
However, interrupting technology workers is easy because the consequences are invisible to almost everyone, even though the negative impact to productivity may be far greater than in manufacturing. For instance, an engineer assigned to multiple projects must switch between tasks, incurring all the costs of having to reestablish context, as well as cognitive rules and goals.
Studies have shown that the time to complete even simple tasks, such as sorting geometric shapes, significantly degrades when multitasking. Of course, because our work in the technology value stream is far more cognitively complex than sorting geometric shapes, the effects of multitasking on process time is much worse.1
We can limit multitasking when we use a kanban board to manage our work, such as by codifying and enforcing WIP (work in process) limits for each column or work center, that puts an upper limit on the number of cards that can be in a column.
For example, we may set a WIP limit of three cards for testing. When there are already three cards in the test lane, no new cards can be added to the lane unless a card is completed or removed from the “in work” column and put back into queue (i.e., putting the card back to the column to the left). Nothing can be worked on until it is first represented in a work card, reinforcing that all work must be made visible.
Dominica DeGrandis, one of the leading experts on using kanban in DevOps value streams and author of Making Work Visible, notes that “controlling queue size [WIP] is an extremely powerful management tool, as it is one of the few leading indicators of lead time—with most work items, we don’t know how long it will take until it’s actually completed.”2
Limiting WIP also makes it easier to see problems that prevent the completion of work.* For instance, when we limit WIP, we find that we may have nothing to do because we are waiting on someone else. Although it may be tempting to start new work (i.e., “It’s better to be doing something than nothing”), a far better action would be to find out what is causing the delay and help fix that problem. Bad multitasking often occurs when people are assigned to multiple projects, resulting in prioritization problems. In other words, as David J. Anderson, author of Kanban: Successful Evolutionary Change for Your Technology Business, said, “Stop starting. Start finishing.”4
Reduce Batch Sizes
Another key component to creating smooth and fast flow is performing work in small batch sizes. Prior to the Lean manufacturing revolution, it was common practice to manufacture in large batch sizes (or lot sizes), especially for operations where job setup or switching between jobs was time-consuming or costly. For example, producing large car body panels requires setting large and heavy dies onto metal stamping machines, a process that can take days. When changeover cost is so expensive, we often stamp as many panels at a time as possible, creating large batches in order to reduce the number of changeovers.
However, large batch sizes result in skyrocketing levels of WIP and high levels of variability in flow that cascade through the entire manufacturing plant. The results are long lead times and poor quality—if a problem is found in one body panel, the entire batch has to be scrapped.
One of the key lessons in Lean is that in order to shrink lead times and increase quality, we must strive to continually shrink batch sizes. The theoretical lower limit for batch size is single-piece flow, where each operation is performed one unit at a time.†
The dramatic differences between large and small batch sizes can be seen in the simple newsletter mailing simulation described in Lean Thinking: Banish Waste and Create Wealth in Your Corporation by James P. Womack and Daniel T. Jones.5
Suppose in our own example we have ten brochures to send, and mailing each brochure requires four steps: (1) fold the paper, (2) insert the paper into the envelope, (3) seal the envelope, and (4) stamp the envelope.
The large batch strategy (i.e., “mass production”) would be to sequentially perform one operation on each of the ten brochures. In other words, we would first fold all ten sheets of paper, then insert each of them into envelopes, then seal all ten envelopes, and then stamp them.
On the other hand, in the small batch strategy (i.e., “single-piece flow”), all the steps required to complete each brochure are performed sequentially before starting on the next brochure. In other words, we fold one sheet of paper, insert it into the envelope, seal it, and stamp it—only then do we start the process over with the next sheet of paper.
The difference between using large and small batch sizes is dramatic (see Figure 2.2 on page 24). Suppose each of the four operations takes ten seconds for each of the ten envelopes. With the large batch size strategy, the first completed and stamped envelope is produced only after 310 seconds.
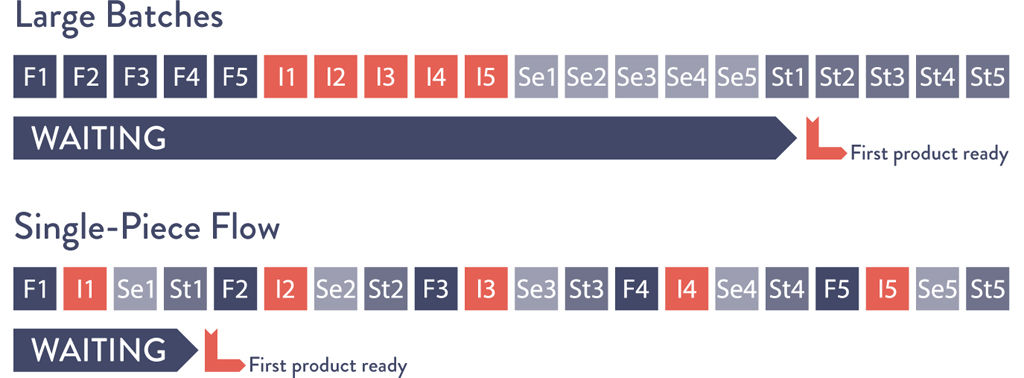
Figure 2.2: Simulation of “Envelope Game”
(Fold, insert, seal, and stamp the envelope.)
Source: Stefan Luyten, “Single Piece Flow,” Medium.com, August 8, 2014, https://medium.com/@stefanluyten/single-piece-flow-5d2c2bec845b.
Worse, suppose we discover during the envelope sealing operation that we made an error in the first step of folding—in this case, the earliest we would discover the error is at two hundred seconds, and we have to refold and reinsert all ten brochures in our batch again.
In contrast, in the small batch strategy the first completed stamped envelope is produced in only forty seconds, eight times faster than the large batch strategy. And, if we made an error in the first step, we only have to redo the one brochure in our batch. Small batch sizes result in less WIP, faster lead times, faster detection of errors, and less rework.
The negative outcomes associated with large batch sizes are just as relevant to the technology value stream as in manufacturing. Consider when we have an annual schedule for software releases, where an entire year’s worth of code that Development has worked on is released to production deployment.
Like in manufacturing, this large batch release creates sudden, high levels of WIP and massive disruptions to all downstream work centers, resulting in poor flow and poor quality outcomes. This validates our common experience that the larger the change going into production, the more difficult the production errors are to diagnose and fix, and the longer they take to remediate.
In a post on Startup Lessons Learned, Eric Ries states,
The batch size is the unit at which work-products move between stages in a development [or DevOps] process. For software, the easiest batch to see is code. Every time an engineer checks in code, they are batching up a certain amount of work. There are many techniques for controlling these batches, ranging from the tiny batches needed for continuous deployment to more traditional branch-based development, where all of the code from multiple developers working for weeks or months is batched up and integrated together.6
The equivalent to single piece flow in the technology value stream is realized with continuous deployment, where each change committed to version control is integrated, tested, and deployed into production. The practices that enable this are described in Part IV of this book.
Reduce the Number of Handoffs
In the technology value stream, whenever we have long deployment lead times measured in months, it is often because there are hundreds (or even thousands) of operations required to move our code from version control into the production environment. To transmit code through the value stream requires multiple departments to work on a variety of tasks, including functional testing, integration testing, environment creation, server administration, storage administration, networking, load balancing, and information security.
Each time the work passes from team to team, we require all sorts of communication: requesting, specifying, signaling, coordinating, and often prioritizing, scheduling, deconflicting, testing, and verifying. This may require using different ticketing or project management systems; writing technical specification documents; communicating via meetings, emails, or phone calls; and using file system shares, FTP servers, and Wiki pages.
Each of these steps is a potential queue where work will wait when we rely on resources that are shared between different value streams (e.g., centralized operations). The lead times for these requests are often so long that there is constant escalation to have work performed within the needed timelines.
Even under the best circumstances, some knowledge is inevitably lost with each handoff. With enough handoffs, the work can completely lose the context of the problem being solved or the organizational goal being supported. For instance, a server administrator may see a newly created ticket requesting that user accounts be created, without knowing what application or service the accounts are for, why they need to be created, what all the dependencies are, or whether the user account creations are actually recurring work.
To mitigate these types of problems, we strive to reduce the number of handoffs, either by automating significant portions of the work, or by building platforms and reorganizing teams so they can self-service builds, testing, and deployments to deliver value to the customer themselves instead of having to be constantly dependent on others. As a result, we increase flow by reducing the amount of time that our work spends waiting in queue, as well as the amount of non–value-added time. (See Appendix 4.)
Continually Identify and Elevate Our Constraints
To reduce lead times and increase throughput, we need to continually identify our system’s constraints and improve its work capacity. In Beyond the Goal, Dr. Goldratt states, “In any value stream, there is always a direction of flow, and there is always one and only constraint; any improvement not made at that constraint is an illusion.”7 If we improve a work center that is positioned before the constraint, work will merely pile up at the bottleneck even faster, waiting for work to be performed by the bottlenecked work center.
On the other hand, if we improve a work center positioned after the bottleneck, it remains starved, waiting for work to clear the bottleneck. As a solution, Dr. Goldratt defined the “five focusing steps”:8
•Identify the system’s constraint.
•Decide how to exploit the system’s constraint.
•Subordinate everything else to the above decisions.
•Elevate the system’s constraint.
•If a constraint has been broken in the previous steps, go back to step one but do not allow inertia to cause a system constraint.
In typical DevOps transformations, as we progress from deployment lead times measured in months or quarters to lead times measured in minutes, the constraint usually follows this progression:
•Environment creation: We cannot achieve deployments on demand if we always have to wait weeks or months for production or test environments. The countermeasure is to create environments that are on-demand and completely self-serviced, so that they are always available when we need them.
•Code deployment: We cannot achieve deployments on demand if each of our production code deployments takes weeks or months to perform (e.g., each deployment requires 1,300 manual, error-prone steps, involving up to three hundred engineers). The countermeasure is to automate our deployments as much as possible, with the goal of being completely automated so deployments can be done self-service by any developer.
•Test setup and run: We cannot achieve deployments on demand if every code deployment requires two weeks to set up our test environments and data sets and another four weeks to manually execute all our regression tests. The countermeasure is to automate our tests so we can execute deployments safely and to parallelize them so the test rate can keep up with our code development rate.
•Overly tight architecture: We cannot achieve deployments on demand if overly tight architecture means that every time we want to make a code change we have to send our engineers to scores of committee meetings in order to get permission to make our changes. Our countermeasure is to create more loosely coupled architecture so that changes can be made safely and with more autonomy, increasing developer productivity.
After all these constraints have been broken, our constraint will likely be Development or the product owners. Because our goal is to enable small teams of developers to independently develop, test, and deploy value to customers quickly and reliably, this is where we want our constraint to be. High performers, regardless of whether an engineer is in Development, QA, Operations, or Infosec, state that their goal is to help maximize developer productivity.
When the constraint is here, we are limited only by the number of good business hypotheses we create and our ability to develop the code necessary to test these hypotheses with real customers.
The progression of constraints listed above are generalizations of typical transformations—techniques to identify the constraint in actual value streams, such as through value stream mapping and measurements, are described later in this book.
Eliminate Hardships and Waste in the Value Stream
Shigeo Shingo, one of the pioneers of the Toyota Production System, believed that waste constituted the largest threat to business viability—the commonly used definition in Lean is “the use of any material or resource beyond what the customer requires and is willing to pay for.”9 He defined seven major types of manufacturing waste: inventory, overproduction, extra processing, transportation, waiting, motion, and defects.
More modern interpretations of Lean have noted that “eliminating waste” can have a demeaning and dehumanizing context; instead, the goal is reframed to reduce hardship and drudgery in our daily work through continual learning in order to achieve the organization’s goals. For the remainder of this book, the term waste will imply this more modern definition, as it more closely matches the DevOps ideals and desired outcomes.
In the book Implementing Lean Software Development: From Concept to Cash, Mary and Tom Poppendieck describe waste and hardship in the software development stream as anything that causes delay for the customer, such as activities that can be bypassed without affecting the result.10 Mary and Tom Poppendieck listed the following seven categories of waste and hardship:11
•Partially done work: This includes any work in the value stream that has not been completed (e.g., requirement documents or change orders not yet reviewed) and work that is sitting in queue (e.g., waiting for QA review or server admin ticket). Partially done work becomes obsolete and loses value as time progresses.
•Extra processes: Any additional work being performed in a process that does not add value to the customer. This may include documentation not used in a downstream work center, or reviews or approvals that do not add value to the output. Extra processes add effort and increase lead times.
•Extra features: Features built into the service that are not needed by the organization or the customer (e.g., “gold plating”). Extra features add complexity and effort to testing and managing functionality.
•Task switching: When people are assigned to multiple projects and value streams, requiring them to context switch and manage dependencies between work, adding additional effort and time into the value stream.
•Waiting: Any delays between work requiring resources to wait until they can complete the current work. Delays increase cycle time and prevent the customer from getting value.
•Motion: The amount of effort to move information or materials from one work center to another. Motion waste can be created when people who need to communicate frequently are not colocated. Handoffs also create motion waste and often require additional communication to resolve ambiguities.
•Defects: Incorrect, missing, or unclear information, materials, or products create waste, as effort is needed to resolve these issues. The longer the time between defect creation and defect detection, the more difficult it is to resolve the defect.
We also add the following two categories of waste from Damon Edwards:12
•Nonstandard or manual work: Reliance on nonstandard or manual work from others, such as using non-rebuilding servers, test environments, and configurations. Ideally, any manual work that can be automated should be automated, self-serviced, and available on demand. However, some types of manual work will likely always be essential.
•Heroics: In order for an organization to achieve goals, individuals and teams are put in a position where they must perform unreasonable acts, which may even become a part of their daily work (e.g., nightly 2:00 AM problems in production, creating hundreds of work tickets as part of every software release).
Our goal is to make these wastes and hardships—anywhere heroics become necessary—visible, and to systematically do what is needed to alleviate or eliminate these burdens and hardships to achieve our goal of fast flow.
 CASE STUDY: NEW TO SECOND EDITION
CASE STUDY: NEW TO SECOND EDITION
Flow and Constraint Management in Healthcare (2021)
DevOps and constraint management theroies aren’t just for software development or physical manufacturing. They can be applied to nearly any situation. Just look at this case study from the healthcare industry. At the DevOps Enterprise Summit 2021, Dr. Chris Strear, an emergency physician for more than nineteen years, related his experience improving patient outcomes by working with flow.13
Around 2007, our hospital was struggling. We had unbelievable problems with flow. We were boarding patients in the emergency department for hours and hours, and sometimes days, while they waited for an inpatient bed to become available.
Our hospital was so crowded and flow was so backed up that our emergency department was on ambulance diversion for sixty hours a month on average. Now that means that for sixty hours a month, our emergency department was closed to the sickest patients in our community. One month we hit over two hundred hours of diversion.
It was horrible. We couldn’t keep nurses. It was such a hard place to work that nurses would quit. And we relied on temporary nurses, on agencies for placing nurses, or traveler nurses to fill in the gaps in staffing. For the most part, these nurses weren’t experienced enough to work in the kind of emergency setting where we practiced. It felt dangerous to come to work every day. It felt dangerous to take care of patients. We were just waiting around for something bad to happen.
The president of our hospital recognized how bad things were, and she put together a committee for flow, and I was lucky enough to be on that committee. . . .
[The change] was transformative. Within a year, we had basically eliminated ambulance diversion. We went from sixty hours a month [of ambulance diversion] to forty-five minutes a month. We improved the length of stay of all of our admitted patients in the hospital. We shortened the time patients spent in the emergency department. We virtually eliminated the patients who left the department without being seen because the waits were too long. And we did all of this in a time when we had record volumes, record ambulance traffic, and record admissions.
[The transformation] was amazing. We took better care of patients. It was safer. And it felt so much easier to take care of patients. It was such an amazing turnaround, in fact, that we were able to stop hiring temporary nurses. We were able to fill our staff completely with dedicated emergency nurses who were qualified to work there. In fact, our department became the number one place for emergency nurses to want to work in the Portland/Vancouver area.
Honestly, I’d never been a part of anything that amazing before, and I haven’t been since. We made patient care better for tens of thousands of patients, and we made life better for hundreds of healthcare workers in our hospital.14
So how did they manage this turnaround? Sometime before, Chris had been introduced to the book The Goal. Constraint management had a profound influence on him and the way he tackled the problem of flow at his hospital.
So I get asked a bunch of times, what’s the difference? I don’t have all the answers, but I’ve seen some trends. I’ve seen some recurrent themes. Flow needs to be important to leaders, not just in words, but in deeds. They need to walk the walk and not just talk the talk. And a lot of them don’t do that.
Part of that is they need to create the bandwidth. The hospital leaders aren’t going to be the ones who are actually going to be making the changes day to day. What they have to do is, they have to allow the people who are going to be making those changes to have enough room on their plate to put in the work. If a nurse manager, for instance, has fifteen projects, fifteen committee meetings that they have to go to day in and day out, and the leader comes along and says, “Flow’s important,” but now flow is their sixteenth task and the sixteenth meeting that they have to go to, really, it doesn’t say that it’s important. All it says is it’s sixteenth most important.
And then there’s managers that aren’t going to have time to put in for the sixteenth project. Leaders need to figure out what really is important and what can wait, what can take a back burner, and then take an active role in clearing some of that work off of people’s plates so that they can do a job. It doesn’t just make those people who have to do the work more effective; it conveys to them in a very real, tangible, palpable sense that this new project, flow, is the most important task.
You have to break down silos. You’re looking at flow through a system. You’re not looking at flow on an inpatient unit or flow just in the emergency department, because each of these departments, when taken individually, has competing interests. When you move a patient out of the emergency department and onto an inpatient unit, you’re creating work for the inpatient unit. You incentivize people differently throughout the hospital.
When you’re discussing how to make flow better, and somebody says no, it can’t just stop at that. No can’t be the final word. I heard time and time again, “We can’t do that because that’s not how we’ve done things.” And that’s ridiculous. No is okay, as long as it’s followed up with another idea to try. Because if I have a lousy idea, but it’s the only idea out there, then you know what? My lousy idea is the best idea we got going, and so that’s the one we try.
Leaders need to make sure that they’re measuring things correctly and that they’re rewarding things thoughtfully. And what do I mean by that? Well, part of silos in a hospital setting is that a manager for a particular department is often measured on how things go just in that department. And they’re rewarded accordingly. People behave based on how they’re measured and how they’re rewarded. So if improving flow in the emergency department is what’s right for patients and what’s right for the hospital system, but it may shift burden onto another unit, and that other unit then falls off in their metrics, that should be okay because flow through the hospital is improved. Who cares about flow through an individual unit?
Make sure that what you’re measuring is commensurate with what your overall goals are. Make sure people are rewarded appropriately, and they’re not unfairly penalized for improving flow through the system. You need to think about the system, not about the department.
And finally, how we’ve set things up, that’s all artificial, that’s a constraint. It’s not a natural law of physics. Keep that in mind because so much resistance comes from the uncertainty of doing something differently.
There’s often this mindset that because we haven’t done something a certain way before, it can’t be done. But we’ve made all of this stuff up. How a body responds to a treatment, that’s not artificial, that is a natural law. But where you put a patient, who’s in charge of them, how you move a patient from one unit to another, we all just made that up and then perpetuated it. That’s all negotiable.15
This case study concretely illustrates using Goldratt’s Theory of Constraint and his five focusing steps to identify and illuminate that constraint and thus improve flow. In this example, the flow of people through the hospital system shows that this theory can be applied to any environment, not just manufacturing or software development.
Conclusion
Improving flow through the technology value stream is essential to achieving DevOps outcomes. We do this by making work visible, limiting WIP, reducing batch sizes and the number of handoffs, continually identifying and evaluating our constraints, and eliminating hardships in our daily work.
The specific practices that enable fast flow in the DevOps value stream are presented in Part IV of this book. In the next chapter, we present The Second Way: The Principles of Feedback.
Taiichi Ohno compared enforcing WIP limits to draining water from the river of inventory in order to reveal all the problems that obstruct fast flow.3 |
|
Also known as “batch size of one” or “1x1 flow,” terms that refer to batch size and a WIP limit of one. |