18.3 Indexing and Reverse Indexing
The concept of indexing was covered in Chapter 14, with MySQL and other relational databases. Indexing identifies key data items and builds a data structure, which can be quickly searched to hold them. In our examples we will make use of standard databases, although in practice, search engines use custom database engines tuned for their needs.
To understand indexing, consider what a crawler and a scraper might identify from a web page and how they might store it. Surely the URL is stored, as are rows for each link found to other URLs. We could store the page as a set of words, with counts associated with this page and a primary autogenerated key we will call URLID. Since URLID is an integer, we can readily build an index on the URL key so that each URL is in the search tree. An index on this URL will allow us to quickly search all URLs due to the tree data structure as well as the ability to do fast compares with the integer field as illustrated in Figure 18.2.
Figure 18.2 Visualization of indexes on database tables
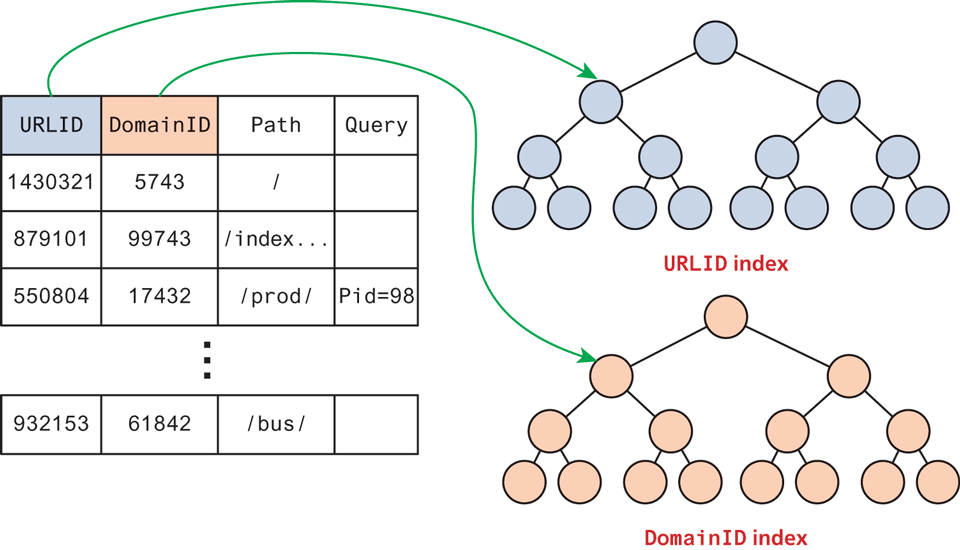
This type of index can be created on any data set, but building indexes on strings is not efficient, since comparing two strings takes longer than comparing two integers. Now with the URL indexed, we can quickly get all the words associated with that index, but we normally don’t need to know which words are at a URL unless we are searching just a single site. Instead, we need to know, if given a word, which URLs contain that word. With no index on the words, the database would have to search every record, and it would be too slow to use. Instead, a reverse index is built, which indexes the words, rather than the URLs. The mechanics of how this is done are not standardized, but generally word tables are created so that each one can be referenced by a unique integer, and indexes can be built on these word identifiers.
Since there are tens of thousands of words, and each word might appear in millions of web pages, the demands on these indexes far exceed what a single database server can support. In practice the reverse indexes are distributed to many machines, so that the indexes can be in memory, across many machines, each with a small portion of the overall responsibility.
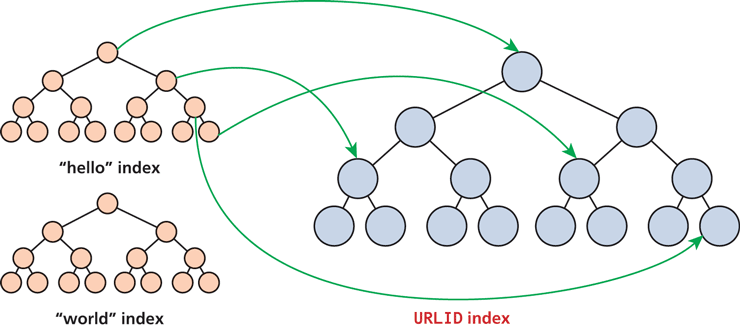
Since engines are indexing words anyhow, there is an opportunity to improve the efficiency of the index by stemming the words first—that is identifying conjugations, polarizations, and other transformations on the base words. By reducing words down to their most basic form, we further reduce the size of the search space. As an example dance, dancing, danced, and dancer could all be indexed as dance. A reverse indexing is illustrated in Figure 18.3 for a couple of words with references to URLs.
Figure 18.3 Reverse index illustration