18.1 The History and Anatomy of Search Engines
The ability to find exactly what you’re looking for with a few terms and a few clicks has transformed how many people access and retrieve information. The impact of search engines is so pronounced that The Oxford English Dictionary now defines the verb google as
Search for information about (someone or something) on the Internet using the search engine Google.1
This shift in the way we retrieve, perceive, and absorb information is of special importance to the web developer since search engines are the medium through which most users will find our websites. Every client seeking traffic will eventually turn to SEO techniques in their quest for more eyes on their content, just as every student now turns there for research and tutelage.
18.1.1 Search Engine Overview
It’s all too common to assume search engines are simple, since Google has kept the interface straightforward and easy: a single box to enter a user’s search query. Search engines we know today consist of several components, working together behind the scenes to make a functional piece of software. These components fall into three categories (shown interacting in Figure 18.1): input agents, database engine, and the query server. In practice, these components are distributed and redundant, rather than existing on one machine, although conceptually they can be thought of as services on the same machine.
Figure 18.1 Major components of a search engine
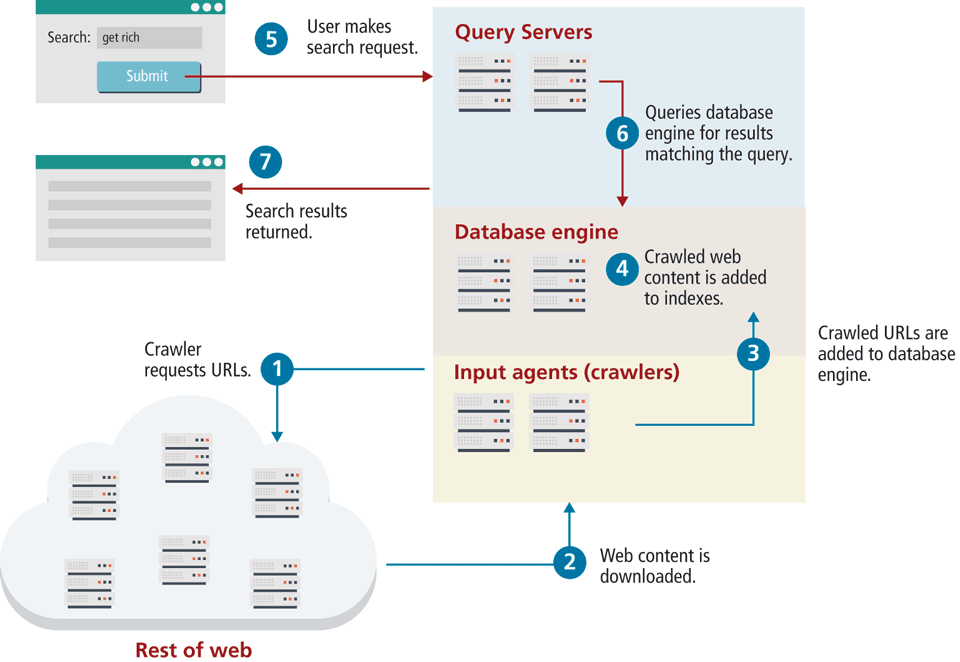
The input agents refer mostly to web crawlers, which surf the WWW requesting ![]() and downloading web pages
and downloading web pages ![]() , all with the intent of identifying new URLs. These agents are distributed across many machines, since the act of fetching and downloading pages can be a bottleneck if run on a single one. Additional input agents include URL submission systems, ratings systems, and administrative back-ends, but web crawlers are the most important.
, all with the intent of identifying new URLs. These agents are distributed across many machines, since the act of fetching and downloading pages can be a bottleneck if run on a single one. Additional input agents include URL submission systems, ratings systems, and administrative back-ends, but web crawlers are the most important.
The resulting URLs have to be stored somewhere, and since the agents are distributed, a database engine manages the URLs and the agents in general ![]() . These database engines are normally proprietary systems written to specifically support the requirements of a search engine, although they may exhibit many characteristics of a relational database.
. These database engines are normally proprietary systems written to specifically support the requirements of a search engine, although they may exhibit many characteristics of a relational database.
URLs are broken down into their components (domain, path, query string, fragment). This allows the engine to prioritize domains and URLs for more intelligent downloading. In modern crawlers, the URL’s content is also downloaded, and the engine performs indexing operations on the web page’s text ![]() . Indexes, as you may recall from Chapter 14, speed up searches by storing B-trees or hashes in memory so queries can be executed quickly on those indexes to recover complete records. Search engines create and manage a range of indexes from domain indexes to indexes for certain words and increasingly, geographic, or advertising data. Indexing is a big part of making sense of the vast amount of data retrieved.
. Indexes, as you may recall from Chapter 14, speed up searches by storing B-trees or hashes in memory so queries can be executed quickly on those indexes to recover complete records. Search engines create and manage a range of indexes from domain indexes to indexes for certain words and increasingly, geographic, or advertising data. Indexing is a big part of making sense of the vast amount of data retrieved.
Finally, with pages crawled and fully indexed, we have a system that can be queried in our database engine. The query server handles requests from end users ![]() for particular queries. This final part of a search engine is probably the most interesting since it contains the algorithms, such as PageRank. It determines what order to list the search results in and makes use of the database engine’s indexes
for particular queries. This final part of a search engine is probably the most interesting since it contains the algorithms, such as PageRank. It determines what order to list the search results in and makes use of the database engine’s indexes ![]() . Search engines such as Yahoo and Bing apply the same principles, but the specific algorithms that companies use to drive their query servers are trade secrets like the Coca-Cola and Pepsi recipes.
. Search engines such as Yahoo and Bing apply the same principles, but the specific algorithms that companies use to drive their query servers are trade secrets like the Coca-Cola and Pepsi recipes.
 Note
Note
Although we explore the components and principles of search engines in depth, there are many plug and play search engine as a service options available for a cost, which solve common web search needs (say a internal site search, or intranet search of company pages and documents).
Tools including Google search appliance and Elasticsearch not only provide search functionality but also package their tools with reporting and analysis features. Users either tap into an API that crawls their content or runs tools to generate indexes on internal intranets.