14.5 NoSQL Databases
NoSQL (which stands for Not-only-SQL) is category of database software that describes a style of database that doesn’t use the relational table model of normal SQL databases. They have grown in popularity in recent years, especially in the areas of big data, analytics, and search. Companies such as Apple, Facebook, Google, Twitter, CERN (to process physics data from the Large Hadron Collider), and others develop and use NoSQL databases in order to handle the massive amounts of data they encounter.
In relational databases, huge data sets can cause entry and retrieval operations to perform slowly. Instead of modularizing the data into distinct tables and relationships like we do with relational databases, NoSQL databases rely on a different set of ideas for data modeling, ideas that put fast retrieval ahead of other considerations like consistency. NoSQL database systems are willing to accept some duplication of data, and therefore place fewer restrictions on redundancy than relational systems.
Test Your Knowledge #1
You have been provided with the markup for the next exercise in the file lab14a-test03.php (the lab includes additional test your knowledge exercises not shown here). You will use helper and gateway classes similar to those shown in Listing 14.21 and 14.22; these classes are already proved for you in lab14a-db-classes.inc.php.
Create a new class named
GalleryDBinlab14a-db-classes.inc.php. This will need agetAll()method that will return all the galleries. Your SQL will need to include the fieldsGalleryIDandGalleryNamefrom the Galleries table and be sorted byGalleryName.Fill the
<select>list with a list of gallery names using the method created in step 1. Set thevalueattribute of each<option>to theGalleryIDfield.Add a new method to
PaintingDBinlab14a-db-classes.inc.php. This method will return just the top 20 paintings, sorted byYearOfWork. Simply append “LIMIT 20” to the end of the SQL. You will need to also addYearOfWorkandImageFileNameto SQL.Modify
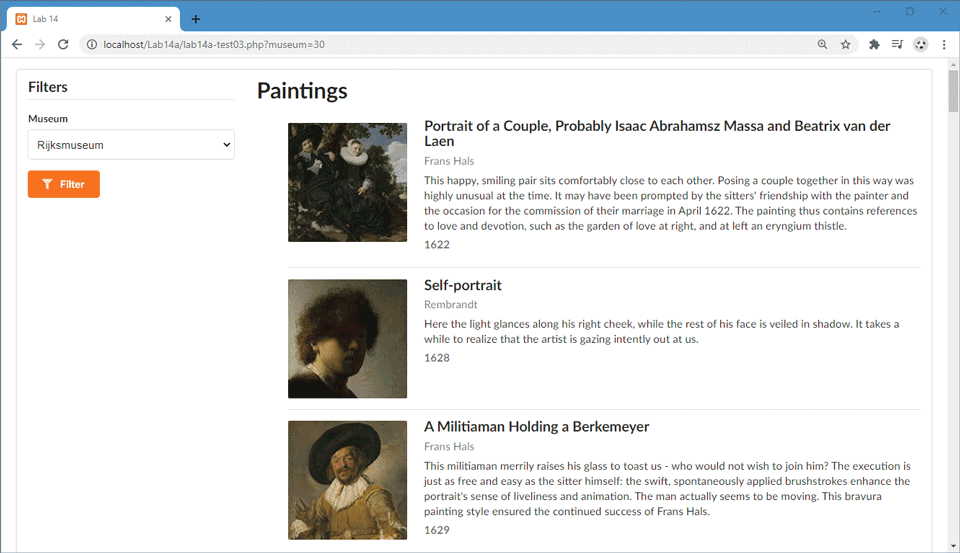
lab14a-test03.phpso that it initially displays the top 20 paintings using the method created in Step 3. The filelab14a-test03.phphas the sample markup for a single painting.When the user selects from the museum list (remember we are not using JavaScript so the user will have to click the filter button which re-requests the page), display just the paintings from the selected museum/gallery. This will require adding a new method to your
PaintingDBclass that returns paintings with the specifiedGalleryID. The result should look similar to that shown in Figure 14.24.Figure 14.24 Test Your Knowledge #1
Systems like DynamoDB, Firebase, and MongoDB now power thousands of sites including household names like Netflix, eBay, Instagram, Forbes, Facebook, and others. These systems are designed to be deployed in a cloud architecture and come with built-in tools to support these deployments as well as their own query languages.
14.5.1 Why (and Why Not) Choose NoSQL?
The main use case for NoSQL is that not all data is relational (or could only be converted into a relational schema with a great deal of work). Some data is “naturally” in a hierarchical form, perhaps because the systems that are generating it are using JSON. A NoSQL database system allows you to store such data in its “natural” form.
Relational databases require one to follow a schema, which needs to remain more or less invariant. But for some web-based scenarios, data formats change relatively quickly. Since NoSQL systems don’t follow a schema, they are able to handle data format changes seamlessly.
As mentioned above, NoSQL systems handle huge datasets better than relational systems. A SQL database usually needs to exist in its entirety on a single computer (though it can be mirrored to other data servers). This limits the size of an SQL database, and that database server needs to be an expensive server with large and fast disks with a lot of memory. If one is using virtual servers on a cloud platform, a database server will be a very expensive cloud instance.
Many NoSQL systems (for instance, MongoDB) can be scaled out horizontally to clusters of commodity servers. That is, the NoSQL system can handle larger loads or sizes by running on multiple inexpensive server machines (or virtual instances). In MongoDB, this capability is known as sharding.
The data in most NoSQL database systems is identified by a unique key. The key-value organization often results in faster retrieval of data in comparison to a relational database.
Despite these advantages, NoSQL databases aren’t the best answer for all scenarios. SQL databases use schemas for a very good reason: they ensure data consistency and data integrity. Not all data requires such consistency and integrity, but some data definitely does. Similarly, SQL databases are transactional, which ensures data reliability when it comes to data modifications. Again, not all data requires transactional integrity, but some data (for instance, financial data) absolutely does.
NoSQL systems are quite different from one another. This means a query written for one NoSQL system will have to be completely rewritten for a different NoSQL system. As a result, it is much easier to hire people who already have SQL experience. SQL has been standardized for many years. Indeed, this author wrote his first SQL in 1992. But for young developers, the scarcity of experienced NoSQL developers could be seen as an advantage, since no one has 15 years of experience with NoSQL systems (indeed, even very experienced NoSQL developers often have less than 5 years of experience with it).
14.5.2 Types of NoSQL Systems
NoSQL database systems rely on a range of modeling paradigms that differ from the relational model used in SQL databases. Key-value stores, Document stores, and Column stores are distinct strategies implemented by the various NoSQL databases, all of which are different from the thinking of relational systems.
Key-Value Stores
In key-value NoSQL systems each entry is simply a set of key-value pairs. Key-value stores alone are quite straightforward in that every value, whether an integer, string, or other data structure, has an associated key (i.e., they are analogous to PHP associative arrays). While a SQL table has a single primary key field for the entire record, here every value has a key, as shown in Figure 14.25.
Figure 14.25 Data in a key/value store

This allows fast retrieval through means such as a hash function, and precludes the need for indexes on multiple fields as is the case with SQL. Perhaps the most popular examples in the web context are memcache and Redis, which you will encounter again in the next chapter.
Document Stores
Document Stores (also called document-oriented databases) associate keys with values, but unlike key-value stores, they call that value a document. A document can be a binary file like a .doc or .pdf or a semi-structured XML or JSON document. By building on the simple retrieval of key-value systems, document store systems can read and write data very quickly. Most NoSQL systems are of this type. MongoDB, AWS DynamoDB, Google FireBase, and Cloud Datastore are popular examples.
To illustrate how a NoSQL document store differs from a relational database, consider the example in Figure 14.26. Here a user’s personal information might be highly normalized across many tables. A document store, in contrast, keeps the user’s information together in a single object (in this case a JSON object literal) associated with a key.
Figure 14.26 Relational data versus document store data
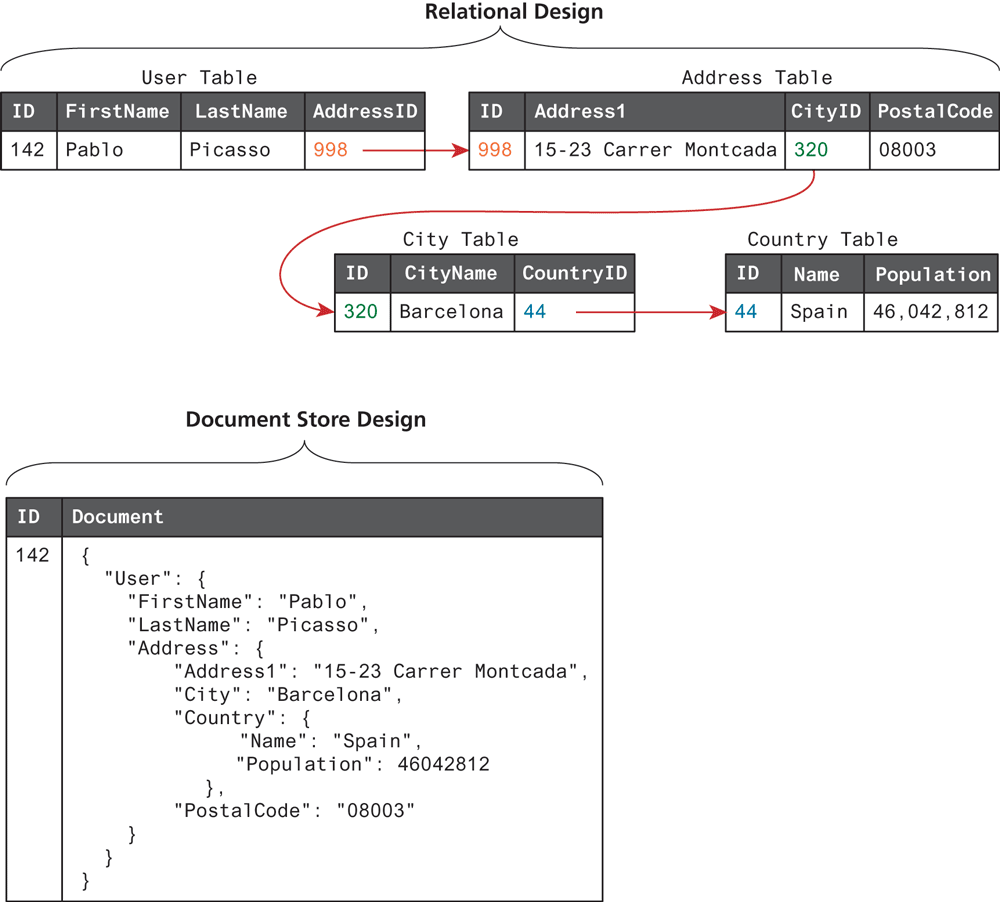
In order to get the equivalent data from a relational model, a relational database has to join the foreign keys across other tables, which can be a time-intensive operation when involving very complex queries or when the server is experiencing high loads. In contrast, the document store requires no joins to retrieve a single user.
It should be noted that the advantage of speed is offset by the challenge of maintaining integrity of the data. Since there are no relational checks in the NoSQL system, changes in one document will not easily be reflected in other documents representing a similar user (while they would in a relational model). In the relational model in the diagram, every address in Barcelona will always have the country of Spain due to how the data is modeled. In the document store approach, the system itself doesn’t maintain data integrity in the same way. Instead it is up to the application using it to maintain this integrity. Thus, if data input mistakes are made, one document in the NoSQL system might have Barcelona within Spain, but another might put it in Sweden, an inconsistency that would not happen in a properly normalized RDMS.
Column Stores
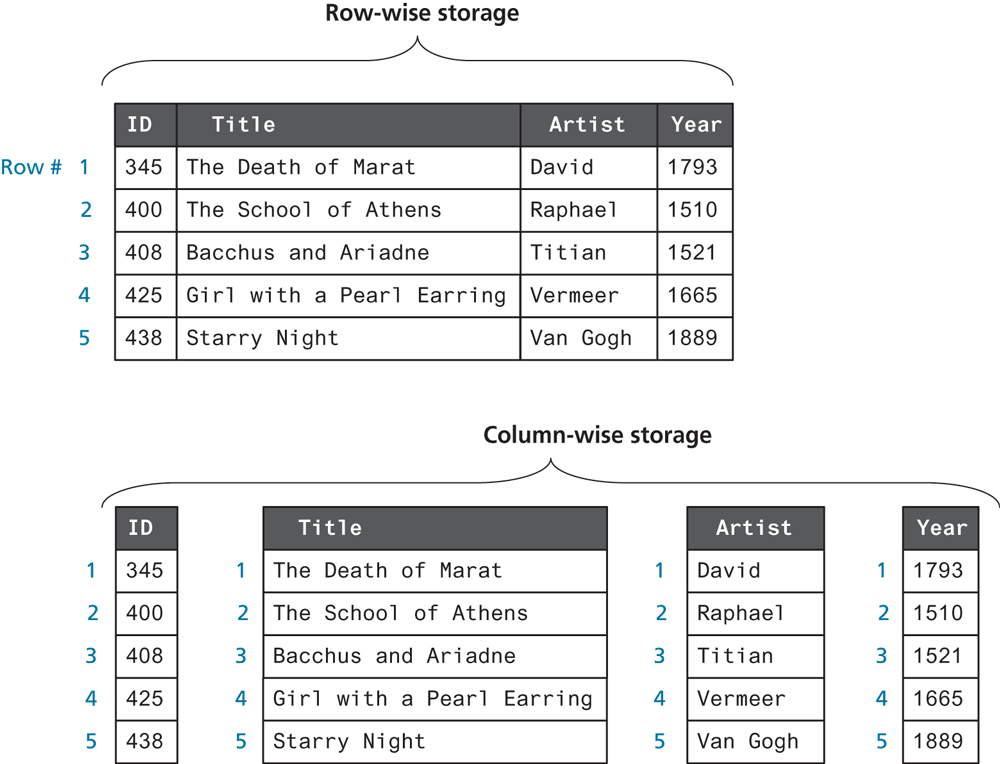
In traditional relational database systems, the data in tables is stored in a row-wise manner. This means that the fundamental unit of data retrieved is a row. To speed up those systems, indexes are used to create fast ways searching across rows by field. Column Store systems store data by column instead of by row, meaning that fetches retrieve a column of data and retrieving an entire row requires multiple operations.
The advantage of column stores is that in a column the data is all of the same type, so higher rates of compression can be achieved. The disadvantage is that writing rows requires writing multiple times to the multiple column stores.
Column stores are not a good choice for applications where rows of data are typically accessed. However, if the majority of a (large data) application uses only a few columns, column stores can offer speed increases, which is why they are integrated into many systems including Cassandra. A visual contrast of how row and columnar systems handle the same data is shown in Figure 14.27.
Figure 14.27 Contrast between row- and column-wise stores
Graph Stores
In a Graph Store system (often simply called graph databases), data is represented as a network or graph of entities and their relationships. Recall that in a relational SQL database, relationships are expressed indirectly via foreign keys and primary keys (for instance, see Figure 14.11). In a graph database, relationships are explicit “things” that can be stored and queried; that is, each object or field in the graph database contains not just its “normal” data, but all its relationships as well, as shown in Figure 14.28.
Figure 14.28 Relationships in a graph database
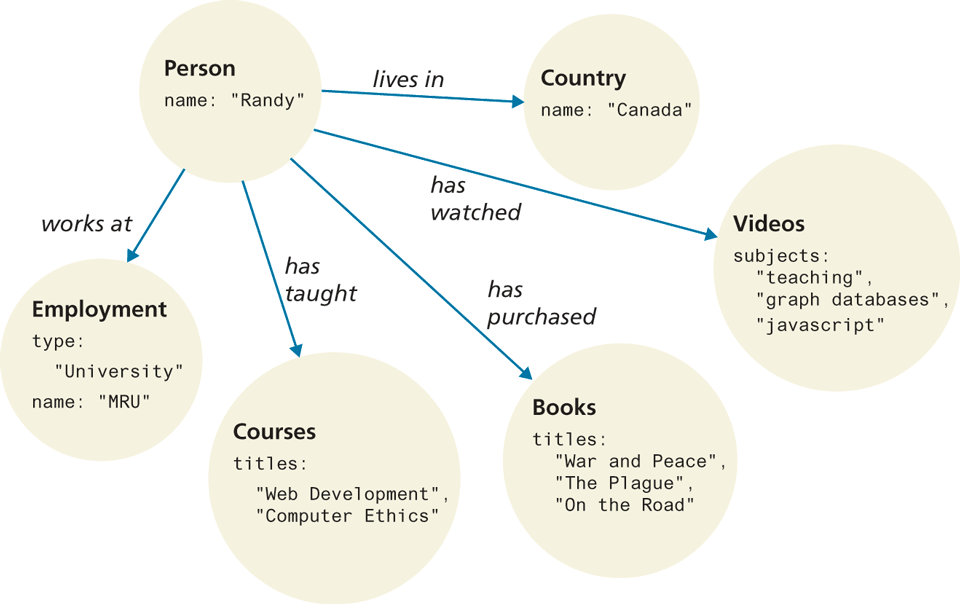
The key advantage of this approach is the ease at which one can query relationships. For instance, in Figure 14.28, we could ask the database to provide us with all persons who work at a university in Canada, who teach web development, who have bought the book War and Peace, and who have watched a video on graph databases. In a traditional SQL database, which is designed for data integrity not relationship discoverability, such a query would likely require multiple subqueries as well as multiple joins, and thus be very computationally expensive (that is, slow). A graph database in contrast can run this query efficiently and easily. As such, they are ideal for efficiently discovering answers to unanticipated questions. Some examples of graph databases include Neo4j, OrientDB, and RedisGraph.