13.1 Introducing Node.js
Node.js (herein simply called Node) is an asynchronous, event-driven runtime environment using JavaScript. It was developed by Ryan Dahl in 2009 as a better way of handling concurrency issues between clients and servers. It makes use of V8, Google’s open-source JavaScript engine (written in C++) that also powers Chrome. V8 not only parses JavaScript, it also compiles it into a fast-executing architecture-specific machine code. V8 also provides efficient runtime garbage collection of objects. As a result, Node is an extremely efficient and performant execution environment.
Node is somewhat equivalent to PHP in that a Node application can generate HTML in response to HTTP requests, except it uses JavaScript as its programming language. But while that comparison with PHP might be comforting, it is also misleading in many ways. As you learned in the last chapter, PHP code is typically injected into HTML markup, thus simplifying the process of writing server-side web applications. As you will shortly discover, Node is much less friendly from a developer perspective. If you want to send HTML to the server, you do so via response.write() calls, but not before also writing the custom code to send the appropriate HTTP headers. Indeed, it reminds us of Java Servlet development from 1997!
13.1.1 Node Advantages
If Node is so much extra work for the developers, then what is the reason for all this interest in it? Node provides several unique advantages over PHP, Ruby on Rails, or ASP.NET.
JavaScript Everywhere
Using the same language on both the client and the server has multiple benefits. Developer productivity is likely to be higher when there is only a single language to use for the entirety of a project. With a single language, there are also more opportunities for code sharing and reuse when only a single language is being used. Finally, JavaScript has arguably become the most popular and widely used programming language in the world; this means hiring knowledgeable developers is likely to be easier and that the hiring team only needs to test its potential applicants for knowledge with a single language.
Push Architectures
Node really shines in push-based web applications. What does this mean exactly? Web applications that we have explored in this book up to now have all been pull-based. A web server sits idle until you make a request: we would say then that a user pulls information/services from the server. That is, the user is in charge of making the request, and it is the server’s job to respond to that request.
While the pull-based nature of the web works just fine, there are certain categories of application that needs to be push-based. That is, some applications need to push information from the server to the client. Phone calls are push-based: the master phone system pushes out a message (incoming call) to the phone and it responds (by ringing).
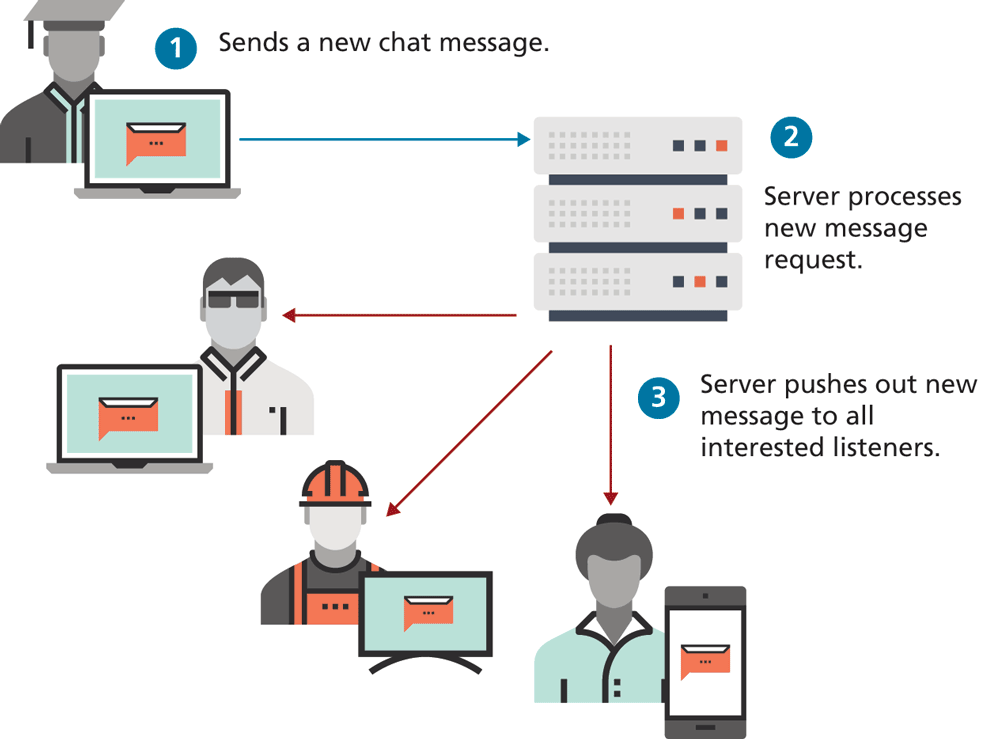
The classic example of a push web application is a chat facility housed within a web page. As illustrated in Figure 13.1, the server has to respond to incoming chat messages by pushing them out to all listening parties in the chat. While one can construct this type of application using an environment like PHP, it typically requires inefficient polling (that is, having the server repeatedly “asking” the clients if they have anything new). In contrast, the Node environment is especially well suited to constructing this type of application. Indeed, many online Node tutorials build a chat server as the first sample application after the obligatory “Hello World” one.
Figure 13.1 Example of a push web application
Nonblocking Architectures
Another key advantage Node provides is of interest perhaps more to SysOps and DevOps personnel. Node uses a nonblocking, asynchronous, single-threaded architecture. What does that mean exactly? Apache runs applications like PHP using either a multiprocessing or multithreaded model. That is, different requests (even for the same page) are executed independently of one another in separate operating system threads or processes. The advantage of this approach is that a problem with the execution of one thread/process will not affect other threads. The disadvantage of this approach is that there is a fixed amount of processes available (typically in the 150–250 range) and a fixed number of total threads available (typically in the 25–50 range per process); if none are free, then a request will have to wait. As well, even though Linux is very efficient with switching between processes/threads (called context switching), there still is a time cost (about 65 microseconds) involved in every context switch. While this doesn’t sound like much of a time cost, once you have about 4000 concurrent connections or requests, your server’s CPU will be spending more of its time switching between processes than actually executing the processes. This is one of the reasons why busy sites need to make use of server farms.
Node, in contrast, uses just a single thread. This means that no time is spent context switching between threads, which is a significant benefit for busy sites. But how, you may ask, can a single thread possibly handle many simultaneous requests? The key to the effectiveness of Node is that it is a nonblocking asynchronous architecture. Figure 13.2 illustrates the typical blocking approach (e.g., PHP) using an analogy from real life, while Figure 13.3 shows the nonblocking approach used by Node.
Figure 13.2 Blocking thread-based architecture
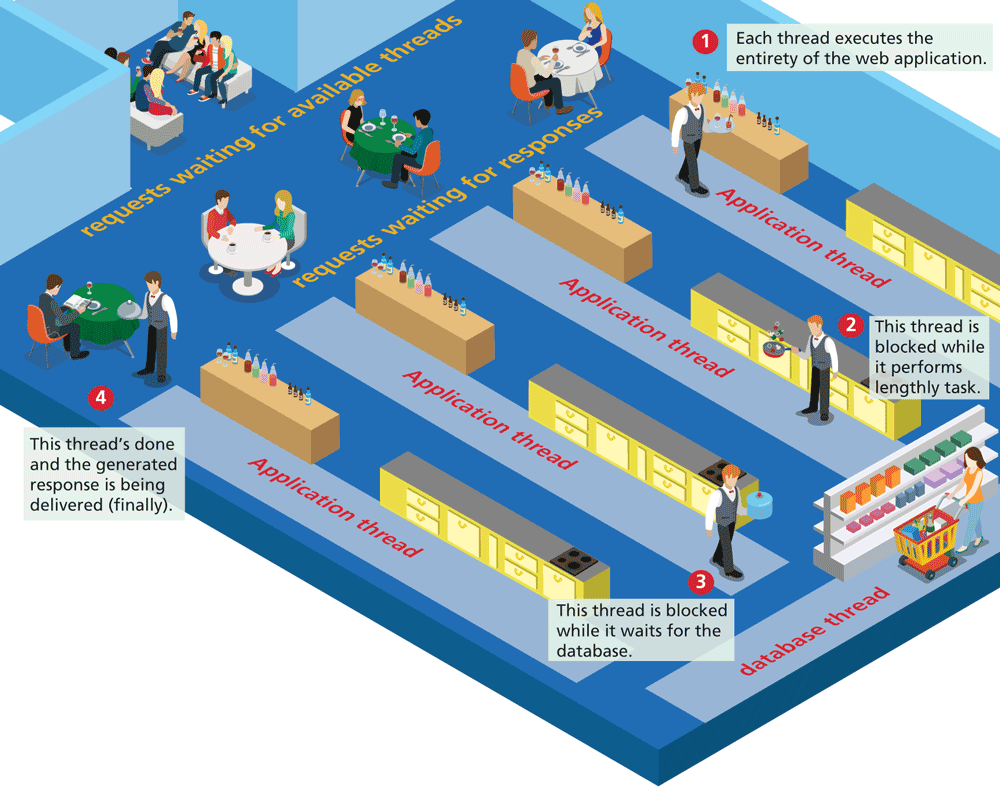
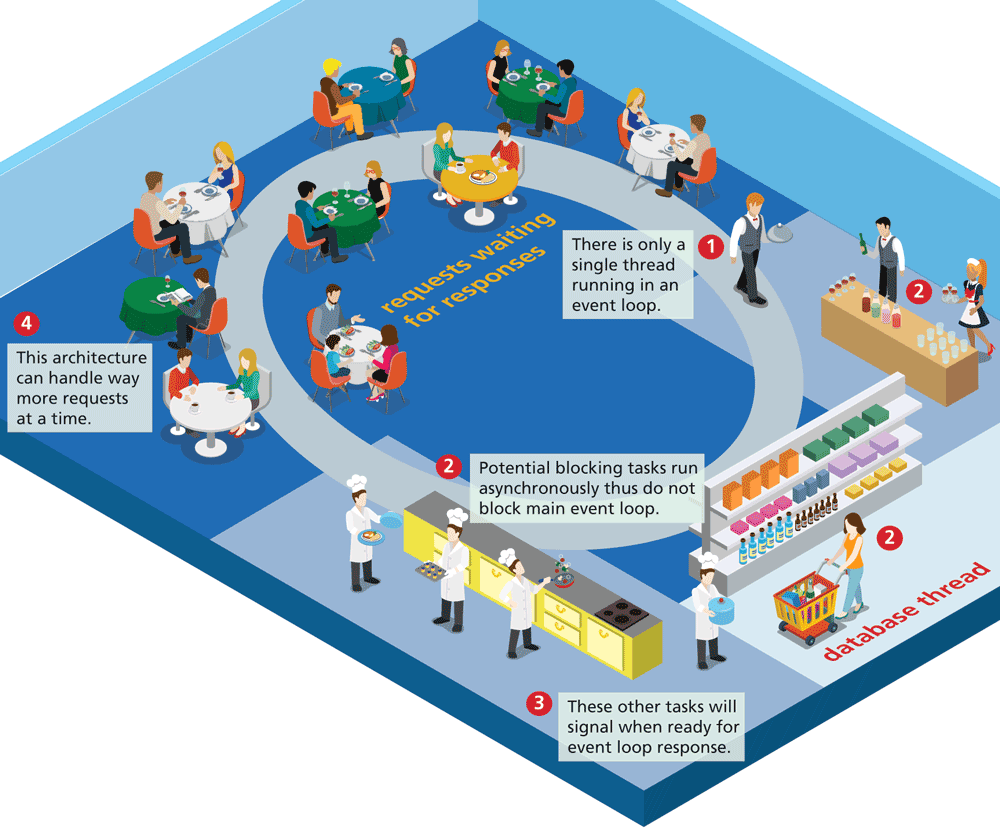
Figure 13.3 Nonblocking thread-based architecture
The analogy with a restaurant is not as fanciful as it may seem. It would be an inefficient restaurant indeed that assigned a single person to handle all the tasks required for each table. After taking an order (i.e., receiving an HTTP request), we wouldn’t want the waiter to walk to the bar, mix the drinks, then walk to the kitchen, and start cooking the order. As can be seen in ![]() in Figure 13.2, a thread can be blocked while it waits for some other task (for instance, a database retrieval). In our restaurant example, imagine the poor customers impatiently wondering where their dinner is while the waiter/bartender/cook is waiting for someone else to finish grocery shopping for an ingredient needed in the order!
in Figure 13.2, a thread can be blocked while it waits for some other task (for instance, a database retrieval). In our restaurant example, imagine the poor customers impatiently wondering where their dinner is while the waiter/bartender/cook is waiting for someone else to finish grocery shopping for an ingredient needed in the order!
Figure 12.3 illustrates the nonblocking architecture used by Node. There is only a single worker servicing all the requests in a single event loop thread. This worker can only be doing a single thing a time. But other tasks (mixing drinks, getting groceries, and cooking the meals) are delegated to other agents. The bartenders might be making drinks for many tables; in the same way, the kitchen staff is cooking several meals at a time. We would say that this is an asynchronous system. When a task is completed (“drink for table 3 is ready!”), it signals (rings a bell maybe) that the task is done, and the event thread will return to pick up and deliver the order. This might seem like too much work for the solitary waiter, but as you know from real-life restaurants, a single waiter can actually service many tables simultaneously due to this delegation of tasks.
What does this scenario look like in programming code? In PHP, you might find yourself writing code that looks like this:
if ( $result = $db->fetchFromDataBase($sql) ) {
// do something with results
. . .
}
if ( $data = $service->retrieveFromService($url, $querystring) ) {
// do something with data
. . .
}
// doesn't need $result or $data
doSomethingElseReallyImportant();In this example, the calls to fetch and retrieve within the two conditionals are blocking calls, in that execution in the thread will halt until the methods return with their results. The doSomethingElseReallyImportant() function cannot execute until the two previous functions are finished executing.
In JavaScript we can write this same code in a nonblocking manner:
fetchFromDataBase(sql, function(results) {
// do something with results
. . .
});
retrieveFromService(url, querystring, function(data) {
// do something with data
. . .
});
// this isn't blocked by two previous lines
doSomethingElseReallyImportant();In this case there is no blocking and the doSomethingElseReallyImportant() function is not delayed. JavaScript is thus the ideal language for this type of asynchronous architecture because so many of the tasks you do with the language involve passing callback functions to tasks or agents who will make use of the callback at some point in the future.
Since Node avoids the significant time costs incurred by blocking and context switching, it can handle a staggeringly large number of simultaneous requests (as high as 100,000). When Walmart switched to Node.js on Black Friday (the day with the highest request load) in 2014, its server CPU utilization never went past 2% even with millions of users.1 Of course, the big drawback with this approach is that a crash while servicing one request affects all requests.
Rich Ecosystem of Tools and Code
After more than a decade of adoptions, Node now has an amazingly rich ecosystem of both prebuilt code and tools that make use of Node. For instance, in Chapter 11, you made use of npm, the Node Package Manager, which provides access to a massive repository of already existing code libraries that you can integrate into your JavaScript applications. In addition, most new server-based environments either depend on Node or provide Node bindings or APIs. This means that if you want to make use of emerging web development approaches—such as microservices, serverless computing, the Internet of Things, or cloud-service integration—you will find that Node is often a necessity.
Broad Adoption
Companies from startups to large companies such as eBay, Netflix, Mozilla, GoDaddy, Groupon, Yahoo, Uber, PayPal, and LinkedIn are using Node for a wide variety of mission-critical projects. Microsoft, which for almost two decades, focused on its own .NET+IIS technology stack, has embraced Node both in its tools and in its Azure Cloud platform. At the time of writing (spring 2020), Microsoft even announced its purchase (via GitHub, which it purchased in 2018) of npm.
13.1.2 Node Disadvantages
The advantages of Node detailed above have made it an ideal technology for web APIs, for complicated browser-based applications that mimic desktop applications but rely on extensive back-end processing, and for applications that need fast real-time, push-based responses, such as mobile games or messaging programs. But Node isn’t ideal for all web-based applications.
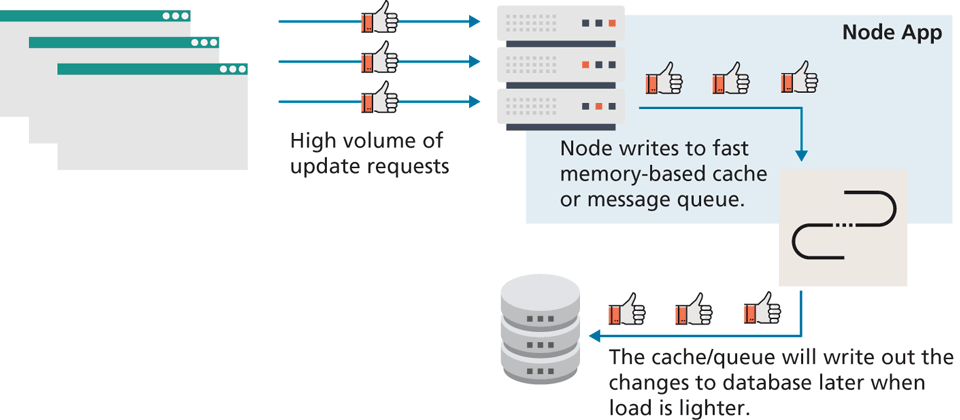
While Node can be used for traditional data-driven informational websites, it is not really the easiest tool to create such sites. For sites whose data is in a traditional relational database such as Oracle, PostgresSQL, or MySQL, accessing that data in Node is often a complex programming task. Node is more suited to developing data-intensive real-time applications that need to interact with distributed computers and whose data sources are noSQL databases. For instance, imagine our web application needs to keep track of mouse analytics or even just clicks of the Like button. Such a site would need to handle a massive number of concurrent data writes. While a transactional relational database might be used for this, writing to a relational database is a slow process and would act as a performance bottleneck. A Node-based system could instead make use of a memory-based message queueing system that would keep a record of all data changes, and then those changes could eventually be persisted, as shown in Figure 13.4.
Figure 13.4 Handling high volume data changes in Node
The single-thread nonblocking architecture of Node is also not ideal for computationally heavy tasks, such as video processing or scientific computing. A long-running computational task will monopolize the single thread, preventing other tasks from being run, despite the asynchronous nature of Node. Node is much better for IO-heavy tasks, where its nonblocking approach will better manage the time-delays of IO.
While Node uses JavaScript, even experienced JavaScript developers can find the asynchronous nature of Node programming difficult to master. Complicated nested callback queues are common in Node, and even with recent support for promises and async...await in Node, applications in Node can be more significantly more complex to develop and maintain than in PHP or in client-side JavaScript.