3.1 What Is HTML and Where Did It Come From?
Dedicated HTML books invariably begin with a brief history of HTML. Such a history might begin with the ARPANET of the late 1960s, jump quickly to the specification and implementation of HTML and HTTP between 1990 and 1991 by Tim Berners-Lee and Robert Cailliau, and then move on to HTML’s formal codification by the World Wide Web Consortium (better known as the W3C) between 1995 and 1997. Some histories of HTML tell tales of “browser wars” in the mid 1990s between Netscape Navigator and Microsoft Internet Explorer. That competition between manufacturers motivated many new tags and features such as CSS and JavaScript, but the development of new features happened quickly, and interoperability between browsers became a major issue for developers and users alike.
Perhaps in reaction to these browser innovations, in 1998 the W3C froze the HTML specification at version 4.01 (Figure 3.1 illustrates the historical timeline for HTML). This specification begins by stating:
To publish information for global distribution, one needs a universally understood language, a kind of publishing mother tongue that all computers may potentially understand. The publishing language used by the World Wide Web is HTML (from HyperText Markup Language).
Figure 3.1 HTML timeline

As one can see from the W3C quote, HTML is defined as a markup language. A markup language is simply a way of annotating a document in such a way as to make the annotations distinct from the text being annotated. Markup languages such as HTML, Tex, XML, and XHTML allow users to control how text and visual elements will be laid out and displayed. The term comes from the days of print, when editors would write instructions on manuscript pages that might be revision instructions to the author or copy editor. You may very well have been the recipient of markup from caring parents or concerned teachers at various points in your past, as shown in Figure 3.2.
Figure 3.2 Sample ad-hoc markup languages

At its simplest, markup is a way to indicate information about the content that is distinct from the content. This “information about content” in HTML is implemented via tags (or more formally, HTML elements, but more on that later). The markup in Figure 3.2 consists of the red text and the various circles and arrows and the little yellow sticky notes. HTML does the same thing but uses textual tags.
In addition to specifying “information about content,” many markup languages are able to encode information how to display the content for the end user. These presentation semantics can be as simple as specifying a bold weight font for certain words and were a part of the earliest HTML specification. Although combining semantic markup with presentation markup is no longer permitted in HTML5, “formatting the content” for display remains a key reason why HTML was widely adopted.
 Note
Note
Created in 1994, the World Wide Web Consortium (W3C) is the main standards organization for the World Wide Web (WWW). It promotes compatibility, thereby ensuring web technologies work together in a predictable way.
To help in this goal, the W3C produces Recommendations (also called specifications). These Recommendations are very lengthy documents that are meant to guide manufacturers in their implementations of HTML, XML, and other web protocols.
The membership of the W3C at present consists of almost 400 members; these include businesses, government agencies, universities, and individuals.
3.1.1 XHTML
Instead of growing HTML, the W3C turned its attention in the late 1990s to a new specification called XHTML 1.0, which was a version of HTML that used stricter XML (extensible markup language) syntax rules (see Dive Deeper next).
But why was “stricter” considered a good thing? Perhaps the best analogy might be that of a strict teacher. When one is prone to bad habits and is learning something difficult in school, sometimes a teacher who is more scrupulous about the need to finish daily homework may actually in the long run be more beneficial than a more permissive and lenient teacher.
As the web evolved in the 1990s, web browsers evolved into quite permissive and lenient programs. They could handle sloppy HTML, missing or malformed tags, and other syntax errors. However, it was somewhat unpredictable how each browser would handle such errors. The goal of XHTML with its strict rules was to make page rendering more predictable by forcing web authors to create web pages without syntax errors.
To help web authors, two versions of XHTML were created: XHTML 1.0 Strict and XHTML 1.0 Transitional. The strict version was meant to be rendered by a browser using the strict syntax rules and tag support described by the W3C XHTML 1.0 Strict specification; the transitional recommendation is a more forgiving flavor of XHTML and was meant to act as a temporary transition to the eventual global adoption of XHTML Strict.
The payoff of XHTML Strict was to be predictable and standardized web documents. Indeed, during much of the 2000s, the focus in the professional web development community was on standards: that is, on limiting oneself to the W3C specification for XHTML.
A key part of the standards movement in the web development community of the 2000s was the use of HTML validators (see Figure 3.3) as a means of verifying that a web page’s markup followed the rules for XHTML Transitional or Strict. Web developers often placed proud images on their sites to tell the world at large that their site followed XHTML rules (and also to communicate their support for web standards).
Figure 3.3 W3C markup validation service
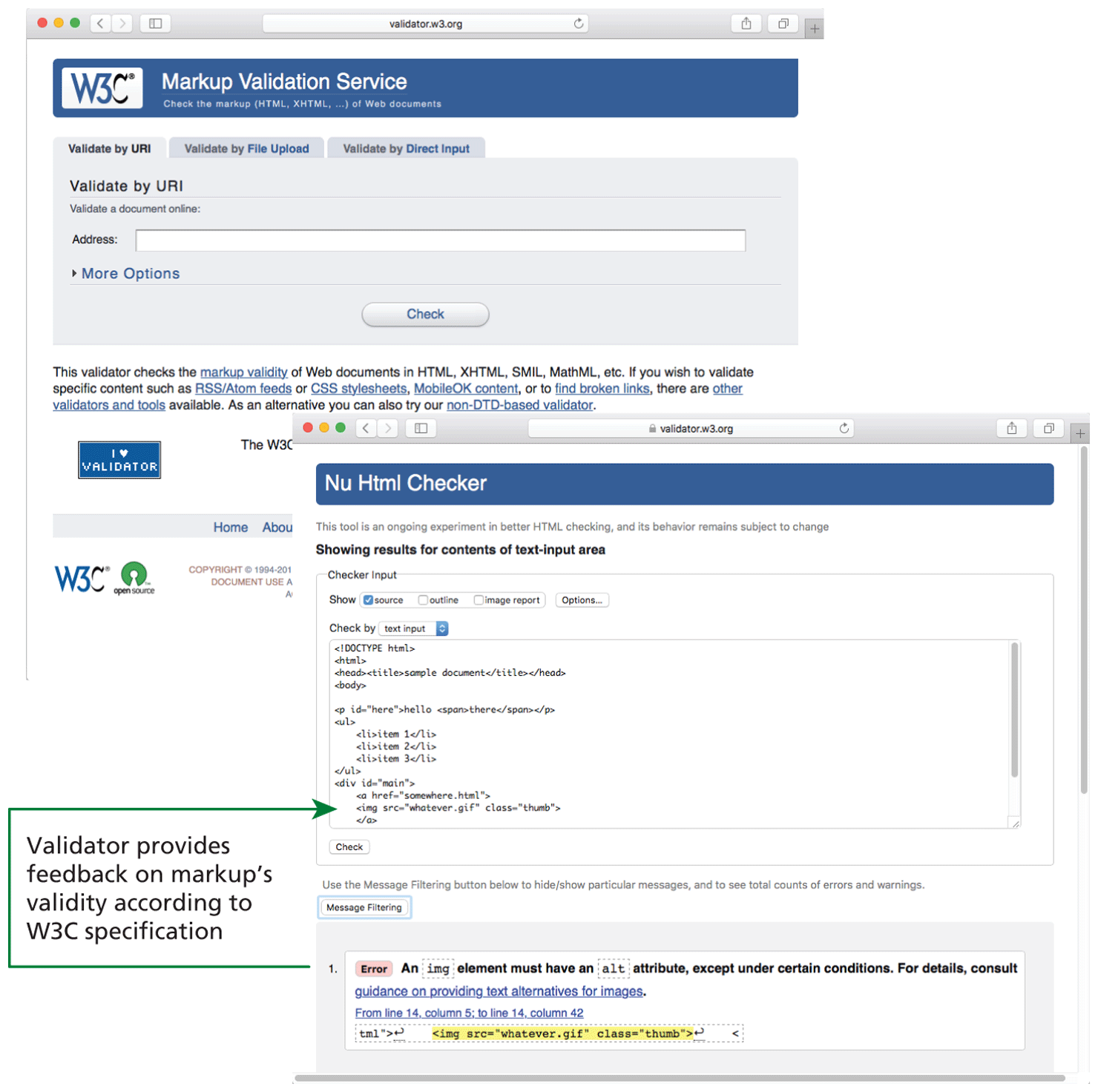
Yet despite the presence of XHTML validators and the peer pressure from book authors, actual web browsers tried to be forgiving when encountering badly formed HTML so that pages worked more or less how the authors intended regardless of whether a document was XHTML valid or not.
In the mid-2000s, the W3C presented a draft of the XHTML 2.0 specification. It proposed a revolutionary and substantial change to HTML. The most important was that backwards compatibility with HTML and XHTML 1.0 was dropped. Browsers would become significantly less forgiving of invalid markup. The XHTML 2.0 specification also dropped familiar tags such as <img>, <a>, <br>, and numbered headings such as <h1>. Development on the XHTML 2.0 specification dragged on for many years, a result not only of the large W3C committee in charge of the specification but also of gradual discomfort on the part of the browser manufacturers and the web development community at large, who were faced with making substantial changes to all existing web pages.
3.1.2 HTML5
At around the same time the XHTML 2.0 specification was being developed, a group of developers at Opera and Mozilla formed the WHATWG (Web Hypertext Application Technology Working Group) group within the W3C. This group was not convinced that the W3C’s embrace of XML and its abandonment of backwards-compatibility was the best way forward for the web.
Unlike the large membership of the W3C, the WHATWG group was very small and led by Ian Hickson. The work at WHATWG progressed quickly, and eventually, by 2009, the W3C stopped work on XHTML 2.0 and instead adopted the work done by WHATWG and named it HTML5.
There are three main aims to HTML5:
Specify unambiguously how browsers should deal with invalid markup.
Provide an open, nonproprietary programming framework (via JavaScript) for creating rich web applications.
Be backward compatible with the existing web.
In October 2014, the HTML5 specification finally moved to the Recommendation stage (i.e., the specification was finalized in terms of its features). Since then the W3C has released Recommendations for HTML5.1 and 5.2, and a Working Draft for HTML5.3 (the latter in October 2018).