Long description
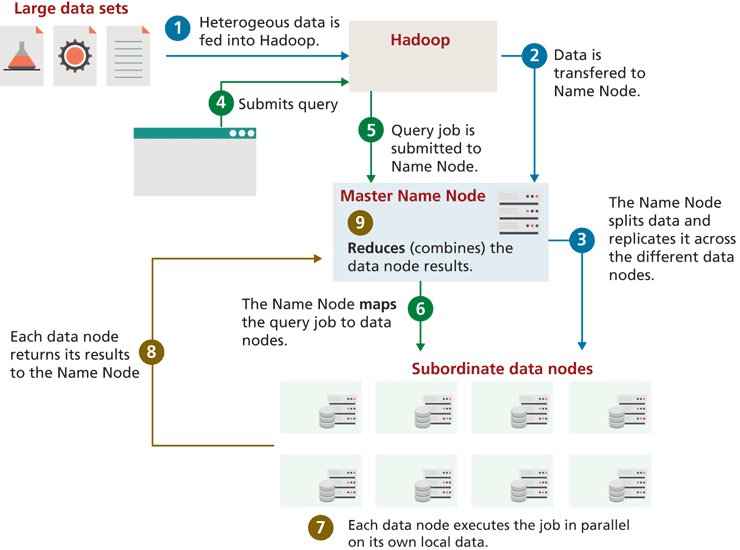
Three icons representing the large dataset is shown initially. An arrow from the Heterogeous data is fed into the hadoop. Arrows from the hadoop block points to the master name node. Two arrows from the master name node points to the subordinate data nodes. An arrow from the subordinate data nodes points back to the master name node. An arrow from a query page also points to the hadoop. The following are the different stages in the data processing, discussed as per the flow mentioned above.
Stage 1: Heterogenous data is fed into Hadoop.
Stage 2: Data is transferred to Name Node.
Stage 3: Name Node splits data and replicates it across the different data nodes.
Stage 4: Submits query.
Stage 5: Query job is submitted to Name Node.
Stage 6: The Name Node maps the query job to data nodes.
Stage 7: Each data node execute the job in parallel on its own local data.
Stage 8: Each data node returns its results to the Name Node.
Back