18 Testing
The longer it takes to detect a bug, the more expensive it becomes to fix it. Testing is all about catching bugs as early as possible, allowing developers to change the implementation with confidence that existing functionality won’t break, increasing the speed of refactorings, shipping new features, and other changes. As a welcome side effect, testing also improves the system’s design since developers have to put themselves in the users’ shoes to test it effectively. Tests also provide up-to-date documentation.
Unfortunately, because it’s impossible to predict all the ways a complex distributed application can fail, testing only provides best-effort guarantees that the code being tested is correct and fault-tolerant. No matter how exhaustive the test coverage is, tests can only cover failures developers can imagine, not the kind of complex emergent behavior that manifests itself only in production1.
Although tests can’t give you complete confidence that your code is bug-free, they certainly do a good job at detecting failure scenarios you are aware of and validating expected behaviors. As a rule of thumb, if you want to be confident that your implementation behaves in a certain way, you have to add a test for it.
18.1 Scope
Tests come in different shapes and sizes. To begin with, we need to distinguish between code paths a test is actually testing (aka system under test or SUT) from the ones that are being run. The SUT represents the scope of the test, and depending on it, the test can be categorized as either a unit test, an integration test, or an end-to-end test.
A unit test validates the behavior of a small part of the codebase, like an individual class. A good unit test should be relatively static in time and change only when the behavior of the SUT changes — refactoring, fixing a bug, or adding a new feature shouldn’t require a unit test to change. To achieve that, a unit test should:
- use only the public interfaces of the SUT;
- test for state changes in the SUT (not predetermined sequence of actions);
- test for behaviors, i.e., how the SUT handles a given input when it’s in a specific state.
An integration test has a larger scope than a unit test, since it verifies that a service can interact with its external dependencies as expected. This definition is not universal, though, because integration testing has different meanings for different people.
Martin Fowler makes the distinction between narrow and broad integration tests. A narrow integration test exercises only the code paths of a service that communicate with an external dependency, like the adapters and their supporting classes. In contrast, a broad integration test exercises code paths across multiple live services.
In the rest of the chapter, we will refer to these broader integration tests as end-to-end tests. An end-to-end test validates behavior that spans multiple services in the system, like a user-facing scenario. These tests usually run in shared environments, like staging or production. Because of their scope, they are slow and more prone to intermittent failures.
End-to-end tests should not have any impact on other tests or users sharing the same environment. Among other things, that requires services to have good fault isolation mechanisms, like rate-limiting, to prevent buggy tests from affecting the rest of the system.
End-to-end tests can be painful and expensive to maintain. For example, when an end-to-end test fails, it’s not always obvious which service is responsible and deeper investigation is required. But they are a necessary evil to ensure that user-facing scenarios work as expected across the entire application. They can uncover issues that tests with smaller scope can’t, like unanticipated side effects and emergent behaviors.
One way to minimize the number of end-to-end tests is to frame them as user journey tests. A user journey test simulates a multi-step interaction of a user with the system (e.g. for e-commerce service: create an order, modify it, and finally cancel it). Such a test usually requires less time to run than splitting the test into N separate end-to-end tests.
As the scope of a test increases, it becomes more brittle, slow, and costly. Intermittently-failing tests are nearly as bad as no tests at all, as developers stop having any confidence in them and eventually ignore their failures. When possible, prefer tests with smaller scope as they tend to be more reliable, faster, and cheaper. A good trade-off is to have a large number of unit tests, a smaller fraction of integration tests, and even fewer end-to-end tests (see Figure 18.1).
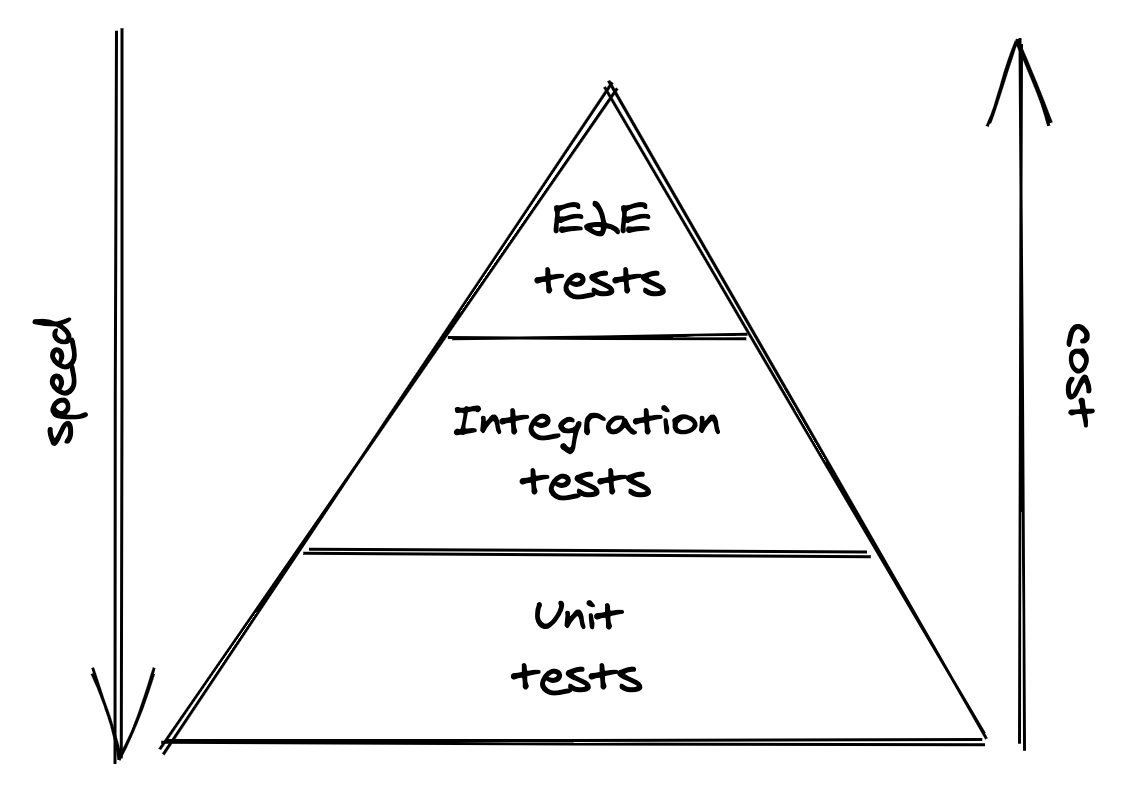
Figure 18.1: Test pyramid
18.2 Size
The size of a test reflects how much computing resources it needs to run, like the number of nodes. Generally, that depends on how realistic the environment is where the test runs. Although the scope and size of a test tend to be correlated, they are distinct concepts, and it helps to separate them.
A small test runs in a single process and doesn’t perform any blocking calls or I/O. It’s very fast, deterministic, and has a very small probability of failing intermittently.
An intermediate test runs on a single node and performs local I/O, like reads from disk or network calls to localhost. This introduces more room for delays and non-determinism, increasing the likelihood of intermittent failures.
A large test requires multiple nodes to run, introducing even more non-determinism and longer delays.
Unsurprisingly, the larger a test is, the longer it takes to run and the flakier it becomes. This is why you should write the smallest possible test for a given behavior. But how do you reduce the size of a test, while not reducing its scope?
You can use a test double in place of a real dependency to reduce the test’s size, making it faster and less prone to intermittent failures. There are different types of test doubles:
- A fake is a lightweight implementation of an interface that behaves similarly to a real one. For example, an in-memory version of a database is a fake.
- A stub is a function that always returns the same value no matter which arguments are passed to it.
- Finally, a mock has expectations on how it should be called, and it’s used to test the interactions between objects.
The problem with test doubles is that they don’t resemble how the real implementation behaves with all its nuances. The less the resemblance is, the less confidence you should have that the test using the double is actually useful. Therefore, when the real implementation is fast, deterministic, and has few dependencies, use that rather than a double. If that’s not the case, you have to decide how realistic you want the test double to be, as there is a tradeoff between its fidelity and the test’s size.
When using the real implementation is not an option, use a fake maintained by the same developers of the dependency, if one is available. Stubbing, or mocking, are last-resort options as they offer the least resemblance to the actual implementation, which makes tests that use them brittle.
For integration tests, a good compromise is to use mocking with contract tests. A contract test defines the request it intends to send to an external dependency and the response it expects to receive from it. This contract is then used by the test to mock the external dependency. For example, a contract for a REST API consists of an HTTP request and response pair. To ensure that the contract doesn’t break, the test suite of the external dependency uses the same contract to simulate a client and ensure that the expected response is returned.
18.3 Practical considerations
As with everything else, testing requires making tradeoffs.
Suppose we want to test the behavior of a specific user-facing API endpoint offered by a service. The service talks to a data store, an internal service owned by another team, and a third-party API used for billing (see Figure 18.2). As mentioned earlier, the general guideline is to write the smallest test possible with the desired scope.
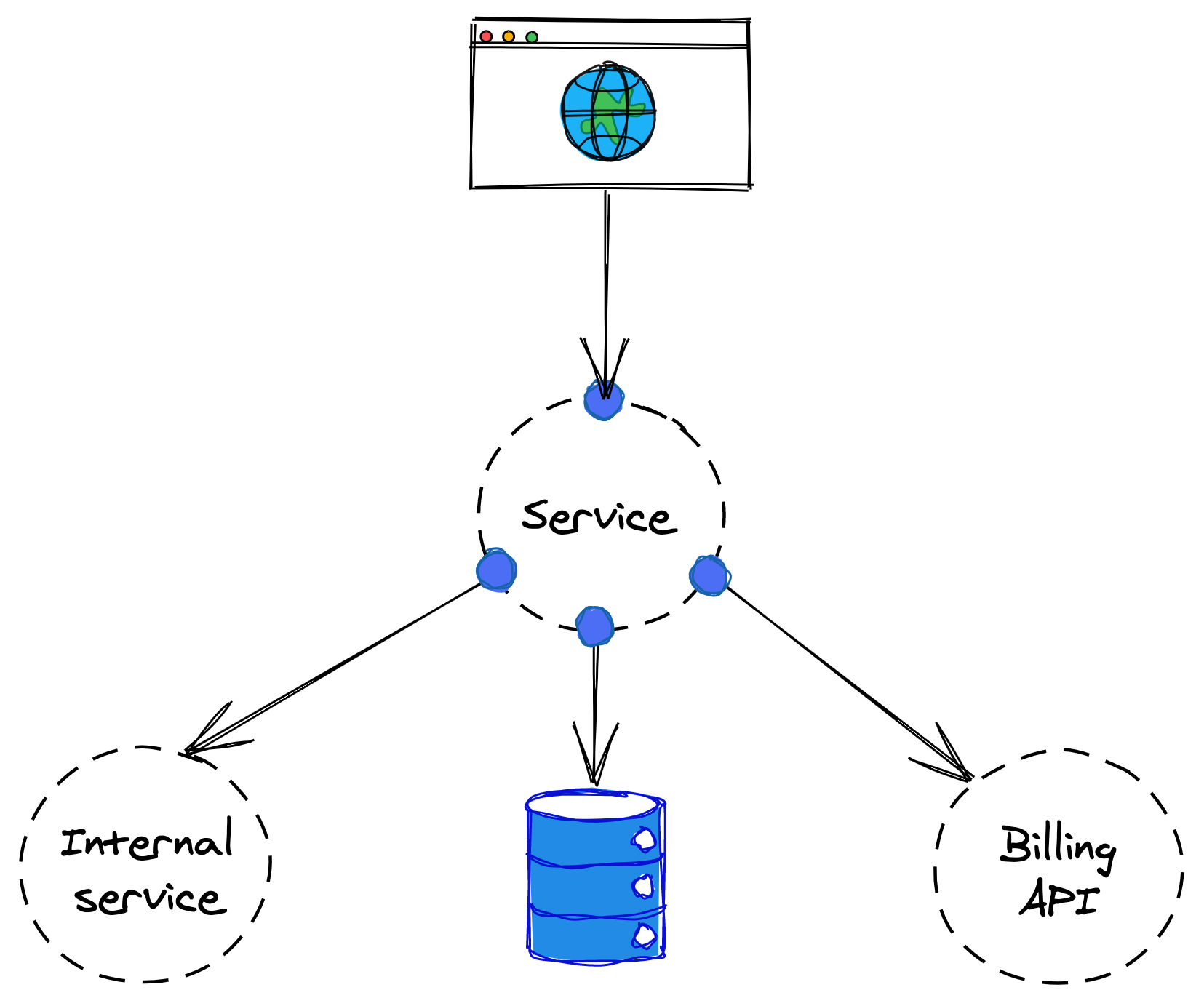
Figure 18.2: How would you test the service?
As it turns out, the endpoint doesn’t need to communicate with the internal service, so we can safely use a mock in its place. The data store comes with an in-memory implementation (a fake) that we can leverage to avoid issuing network calls to a remote data store.
Finally, we can’t use the third-party billing API, as that would require the test to issue real transactions. Fortunately, the API has a different endpoint that offers a playground environment, which the test can use without creating real transactions. If there was no playground environment available and no fake either, we would have to resort to stubbing or mocking.
In this case, we have cut the test’s size considerably, while keeping its scope mostly intact.
Here is a more nuanced example. Suppose we need to test whether purging the data belonging to a specific user across the entire application stack works as expected. In Europe, this functionality is mandated by law (GDPR), and failing to comply with it can result in fines up to 20 million euros or 4% annual turnover, whichever is greater. In this case, because the risk for the functionality silently breaking is too high, we want to be as confident as possible that the functionality is working as expected. This warrants the use of an end-to-end test that runs in production and uses live services rather than test doubles.