11 Transactions
Transactions provide the illusion that a group of operations that modify some data has exclusive access to it and that either all operations complete successfully, or none does. You can typically leverage transactions to modify data owned by a single service, as it’s likely to reside in a single data store that supports transactions. On the other hand, transactions that update data owned by different services, each with its own data store, are challenging to implement. This chapter will explore how to add transactions to your application when your data model is partitioned.
11.1 ACID
Consider a money transfer from one bank account to another. If the withdrawal succeeds, but the deposit doesn’t, the funds need to be deposited back into the source account — money can’t just disappear into thin air. In other words, the transfer needs to execute atomically; either both the withdrawal and the deposit succeed, or neither do. To achieve that, the withdrawal and deposit need to be wrapped in an inseparable unit: a transaction.
In a traditional relational database, a transaction is a group of operations for which the database guarantees a set of properties, known as ACID:
- Atomicity guarantees that partial failures aren’t possible; either all the operations in the transactions complete successfully, or they are rolled back as if they never happened.
- Consistency guarantees that the application-level invariants, like a column that can’t be null, must always be true. Confusingly, the “C” in ACID has nothing to do with the consistency models we talked about so far, and according to Joe Hellerstein, the “C” was tossed in to make the acronym work. Therefore, we will safely ignore this property in the rest of this chapter.
- Isolation guarantees that the concurrent execution of transactions doesn’t cause any race conditions.
- Durability guarantees that once the data store commits the transaction, the changes are persisted on durable storage. The use of a write-ahead log (WAL) is the standard method used to ensure durability. When using a WAL, the data store can update its state only after log entries describing the changes have been flushed to permanent storage. Most of the time, the database doesn’t read from this log at all. But if the database crashes, the log can be used to recover its prior state.
Transactions relieve you from a whole range of possible failure scenarios so that you can focus on the actual application logic rather than all possible things that can go wrong. This chapter explores how distributed transactions differ from ACID transactions and how you can implement them in your systems. We will focus our attention mainly on atomicity and isolation.
11.2 Isolation
A set of concurrently running transactions that access the same data can run into all sorts of race conditions, like dirty writes, dirty reads, fuzzy reads, and phantom reads:
- A dirty write happens when a transaction overwrites the value written by another transaction that hasn’t been committed yet.
- A dirty read happens when a transaction observes a write from a transaction that hasn’t completed yet.
- A fuzzy read happens when a transaction reads an object’s value twice, but sees a different value in each read because a committed transaction updated the value between the two reads.
- A phantom read happens when a transaction reads a set of objects matching a specific condition, while another transaction adds, updates, or deletes an object matching the same condition. For example, if one transaction is summing all employees’ salaries while another deletes some employee records simultaneously, the sum of the salaries will be wrong at commit time.
To protect against these race conditions, a transaction needs to be isolated from others. An isolation level protects against one or more types of race conditions and provides an abstraction that we can use to reason about concurrency. The stronger the isolation level is, the more protection it offers against race conditions, but the less performant it is.
Transactions can have different types of isolation levels that are defined based on the type of race conditions they forbid, as shown in Figure 11.1.
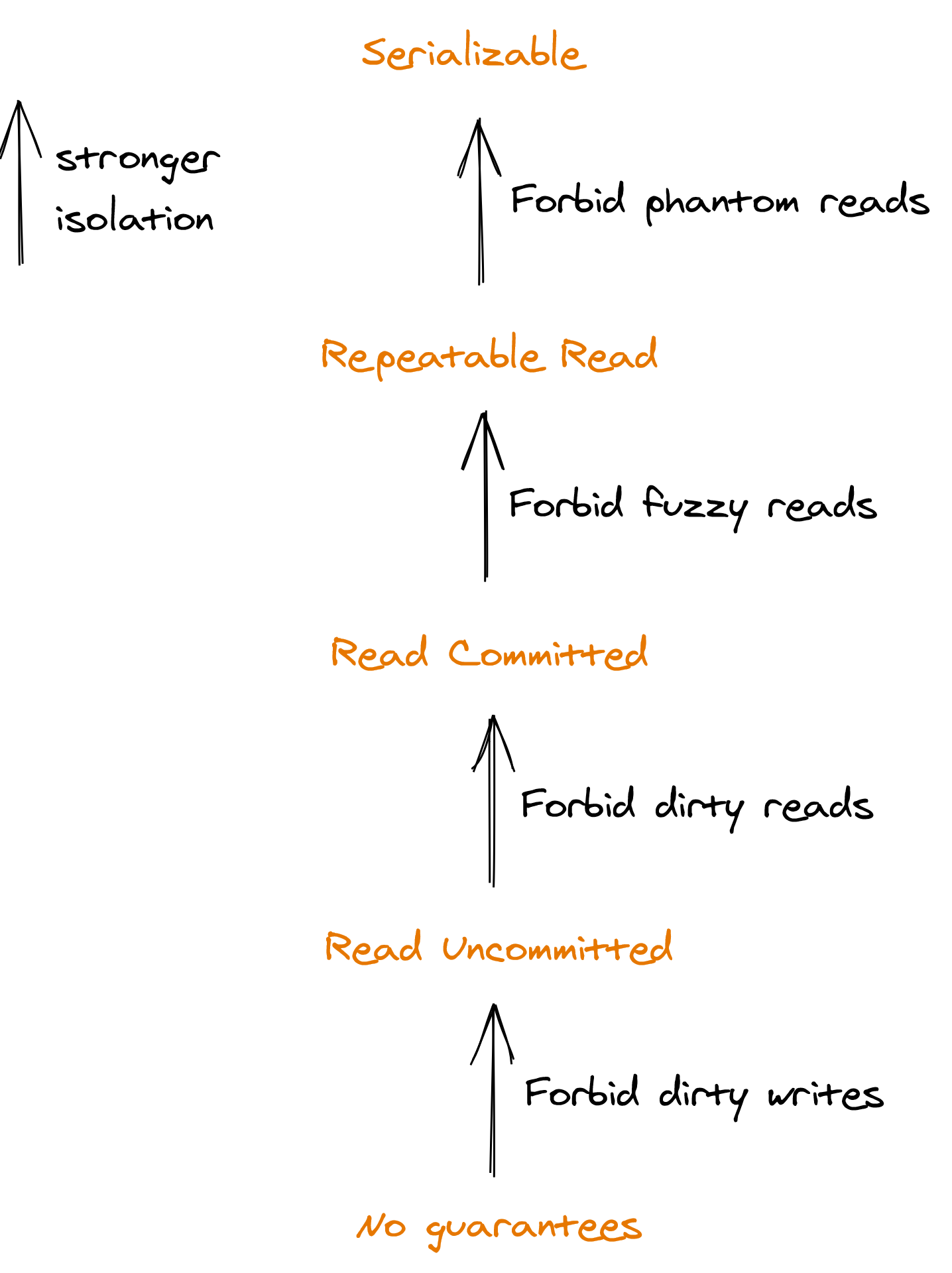
Figure 11.1: Isolation levels define which race conditions they forbid.
Serializability is the only isolation level that guards against all possible race conditions. It guarantees that the side effects of executing a set of transactions appear to be the same as if they had executed sequentially, one after the other. But, we still have a problem — there are many possible orders that the transactions can appear to be executed in, as serializability doesn’t say anything about which one to pick.
Suppose we have two transactions A and B, and transaction B completes 5 minutes after transaction A. A system that guarantees serializability can reorder them so that B’s changes are applied before A’s. To add a real-time requirement on the order of transactions, we need a stronger isolation level: strict serializability. This level combines serializability with the real-time guarantees that linearizability provides so that when a transaction completes, its side effects become immediately visible to all future transactions.
(Strict) serializability is slow as it requires coordination, which creates contention in the system. As a result, there are many different isolation levels that are simpler to implement and also perform better. Your application might not need serializability, but you need to consciously decide which isolation level to use and understand its implications, or your data store will silently make the decision for you; for example, PostgreSQL’s default isolation is read committed. When in doubt, choose strict serializability.
There are more isolation levels and race conditions than the ones we discussed here. Jepsen provides a good formal reference of the existing isolation levels, how they relate to one another, and which guarantees they offer. Although vendors typically document the isolation levels their products offer, these specifications don’t always match the formal definitions.
Now that we know what serializability is, let’s look at how it can be implemented and why it’s so expensive in terms of performance. Serializability can be achieved either with a pessimistic or an optimistic concurrency control mechanism.
11.2.1 Concurrency control
Pessimistic concurrency control uses locks to block other transactions from accessing a data item. The most popular pessimistic protocol is two-phase locking (2PL). 2PL has two types of locks, one for reads and one for writes. A read lock can be shared by multiple transactions that access the data item in read-only mode, but it blocks transactions trying to acquire a write lock. The latter can be held only by a single transaction and blocks anyone else trying to acquire either a read or write lock on the data item.
There are two phases in 2PL, an expanding and a shrinking one. In the expanding phase, the transaction is allowed only to acquire locks, but not to release them. In the shrinking phase, the transaction is permitted only to release locks, but not to acquire them. If these rules are obeyed, it can be formally proven that the protocol guarantees serializability.
The optimistic approach to concurrency control doesn’t block, as it checks for conflicts only at the very end of a transaction. If a conflict is detected, the transaction is aborted or restarted from the beginning. Generally, optimistic concurrency control is implemented with multi-version concurrency control (MVCC). With MVCC, the data store keeps multiple versions of a data item. Read-only transactions aren’t blocked by other transactions, as they can keep reading the version of the data that was committed at the time the transaction started. But, a transaction that writes to the store is aborted or restarted when a conflict is detected. While MVCC per se doesn’t guarantee serializability, there are variations of it that do, like Serializable Snapshot Isolation (SSI).
Optimistic concurrency makes sense when you have read-heavy workloads that only occasionally perform writes, as reads don’t need to take any locks. For write-heavy loads, a pessimistic protocol is more efficient as it avoids retrying the same transactions repeatedly.
I have deliberately not spent much time describing 2PL and MVCC, as it’s unlikely you will have to implement them in your systems. But, the commercial data stores your systems depend on use one or the other technique to isolate transactions, so you must have a basic grasp of the tradeoffs.
11.3 Atomicity
Going back to our original example of sending money from one bank account to another, suppose the two accounts belong to two different banks that use separate data stores. How should we go about guaranteeing atomicity across the two accounts? We can’t just run two separate transactions to respectively withdraw and deposit the funds — if the second transaction fails, then the system is left in an inconsistent state. We need atomicity: the guarantee that either both transactions succeed and their changes are committed, or that they fail without any side effects.
11.3.1 Two-phase commit
Two-phase commit (2PC) is a protocol used to implement atomic transaction commits across multiple processes. The protocol is split into two phases, prepare and commit. It assumes a process acts as coordinator and orchestrates the actions of the other processes, called participants. Generally, the client application that initiates the transaction acts as the coordinator for the protocol.
When a coordinator wants to commit a transaction to the participants, it sends a prepare request asking the participants whether they are prepared to commit the transaction (see Figure 11.2). If all participants reply that they are ready to commit, the coordinator sends out a commit message to all participants ordering them to do so. In contrast, if any process replies that it’s unable to commit, or doesn’t respond promptly, the coordinator sends an abort request to all participants.
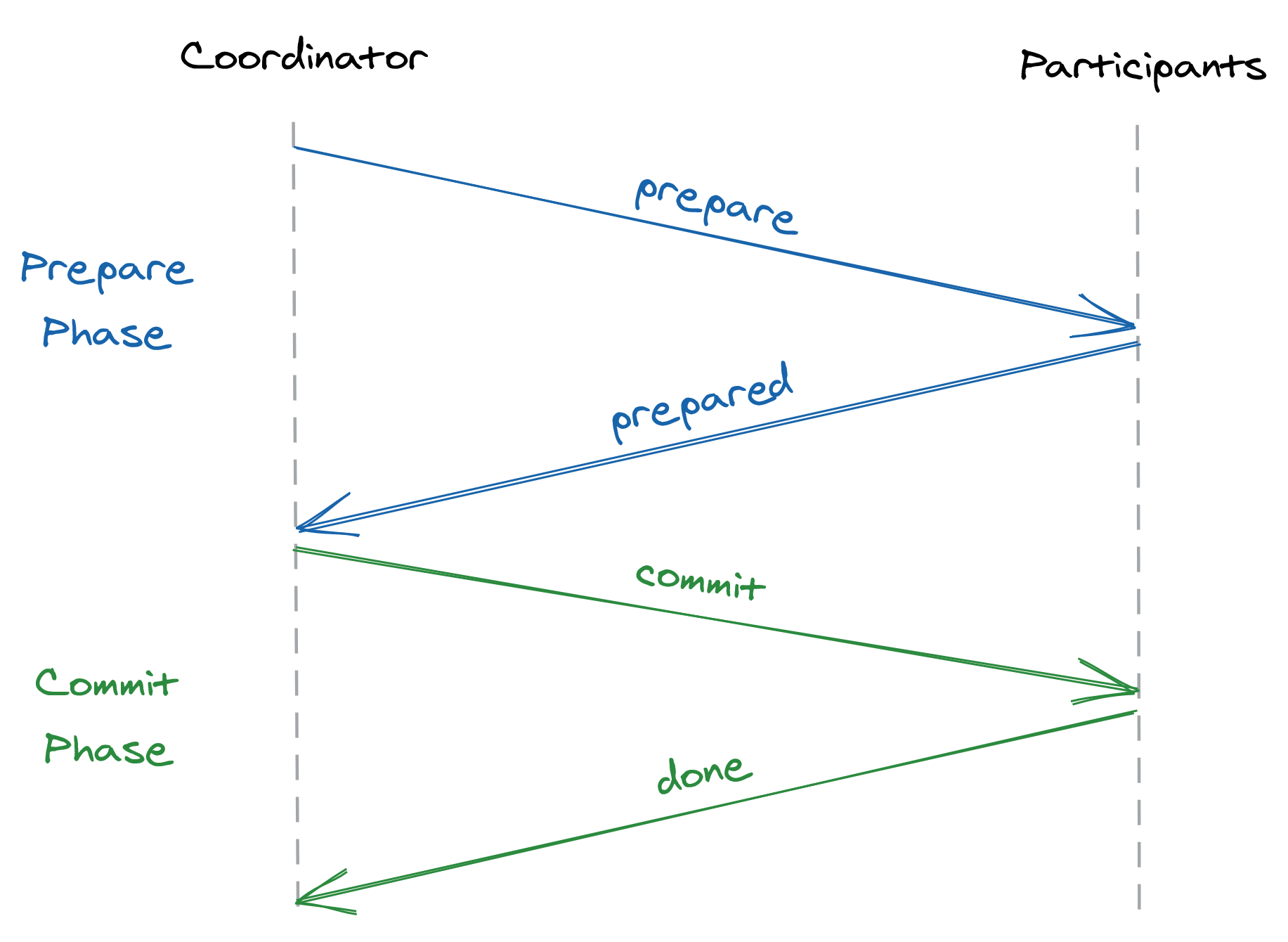
Figure 11.2: The two-phase commit protocol consists of a prepare and a commit phase.
There are two points of non-return in the protocol. If a participant replies to a prepare message that it’s ready to commit, it will have to do so later, no matter what. The participant can’t make progress from that point onward until it receives a message from the coordinator to either commit or abort the transaction. This means that if the coordinator crashes, the participant is completely blocked.
The other point of non-return is when the leader decides to commit or abort the transaction after receiving a response to its prepare message from all participants. Once the coordinator makes the decision, it can’t change its mind later and has to see through that the transaction is committed or aborted, no matter what. If a participant is temporarily down, the coordinator will keep retrying until the request eventually succeeds.
Two-phase commit has a mixed reputation. It’s slow, as it requires multiple round trips to complete a transaction and blocks when there is a failure. If either the coordinator or a participant fails, then all processes part of the transactions are blocked until the failing process comes back online. On top of that, the participants need to implement the protocol; you can’t just take PostgreSQL and Cassandra and expect them to play ball with each other.
If we are willing to increase complexity, there is a way to make the protocol more resilient to failures. Atomically committing a transaction is a form of consensus, called “uniform consensus,” where all the processes have to agree on a value, even the faulty ones. In contrast, the general form of consensus introduced in section 10.2 only guarantees that all non-faulty processes agree on the proposed value. Therefore, uniform consensus is actually harder than consensus.
Yet, an off-the-shelf consensus implementation can still be used to make 2PC more robust to failures. For example, replicating the coordinator with a consensus algorithm like Raft makes 2PC resilient to coordinator failures. Similarly, the participants could also be replicated.
As a historical side-note, the first versions of modern large-scale data stores that came out in the late 2000s used to be referred to as NoSQL stores as their core features were focused entirely on scalability and lacked the guarantees of traditional relational databases, such as ACID transactions. But in recent years, that has mostly changed as distributed data stores have continued to add features that only traditional databases offered, and ACID transactions have become the norm rather than the exception. For example, Google’s Spanner implements transactions across partitions using a combination of 2PC and state machine replication.
11.4 Asynchronous transactions
2PC is a synchronous blocking protocol; if any of the participants isn’t available, the transaction can’t make any progress, and the application blocks completely. The assumption is that the coordinator and the participants are available and that the duration of the transaction is short-lived. Because of its blocking nature, 2PC is generally combined with a blocking concurrency control mechanism, like 2PL, to provide isolation.
But, some types of transactions can take hours to execute, in which case blocking just isn’t an option. And some transactions don’t need isolation in the first place. Suppose we were to drop the isolation requirement and the assumption that the transactions are short-lived. Can we come up with an asynchronous non-blocking solution that still provides atomicity?
11.4.1 Log-based transactions
A typical pattern in modern applications is replicating the same data in different data stores tailored to different use cases, like search or analytics. Suppose we own a product catalog service backed by a relational database, and we decided to offer an advanced full-text search capability in its API. Although some relational databases offer basic full-text search functionality, a dedicated database such as Elasticsearch is required for more advanced use cases.
To integrate with the search index, the catalog service needs to update both the relational database and the search index when a new product is added or an existing product is modified or deleted. The service could just update the relational database first, and then the search index; but if the service crashes before updating the search index, the system would be left in an inconsistent state. As you can guess by now, we need to wrap the two updates into a transaction somehow.
We could consider using 2PC, but while the relational database supports the X/Open XA 2PC standard, the search index doesn’t, which means we would have to implement that functionality from scratch. We also don’t want the catalog service to block if the search index is temporarily unavailable. Although we want the two data stores to be in sync, we can accept some temporary inconsistencies. In other words, eventual consistency is acceptable for our use case.
To solve this problem, let’s introduce an message log in our application. A log is an append-only, totally ordered sequence of messages, in which each message is assigned a unique sequential index. Messages are appended at the end of the log, and consumers read from it in order. Kafka and Azure Event Hubs are two popular implementations of logs.
Now, when the catalog service receives a request from a client to create a new product, rather than writing to the relational database, or the search index, it appends a product creation message to the message log. The append acts as the atomic commit step for the transaction. The relational database and the search index are asynchronous consumers of the message log, reading entries in the same order as they were appended and updating their state at their own pace (see Figure 11.3). Because the message log is ordered, it guarantees that the consumers see the entries in the same order.
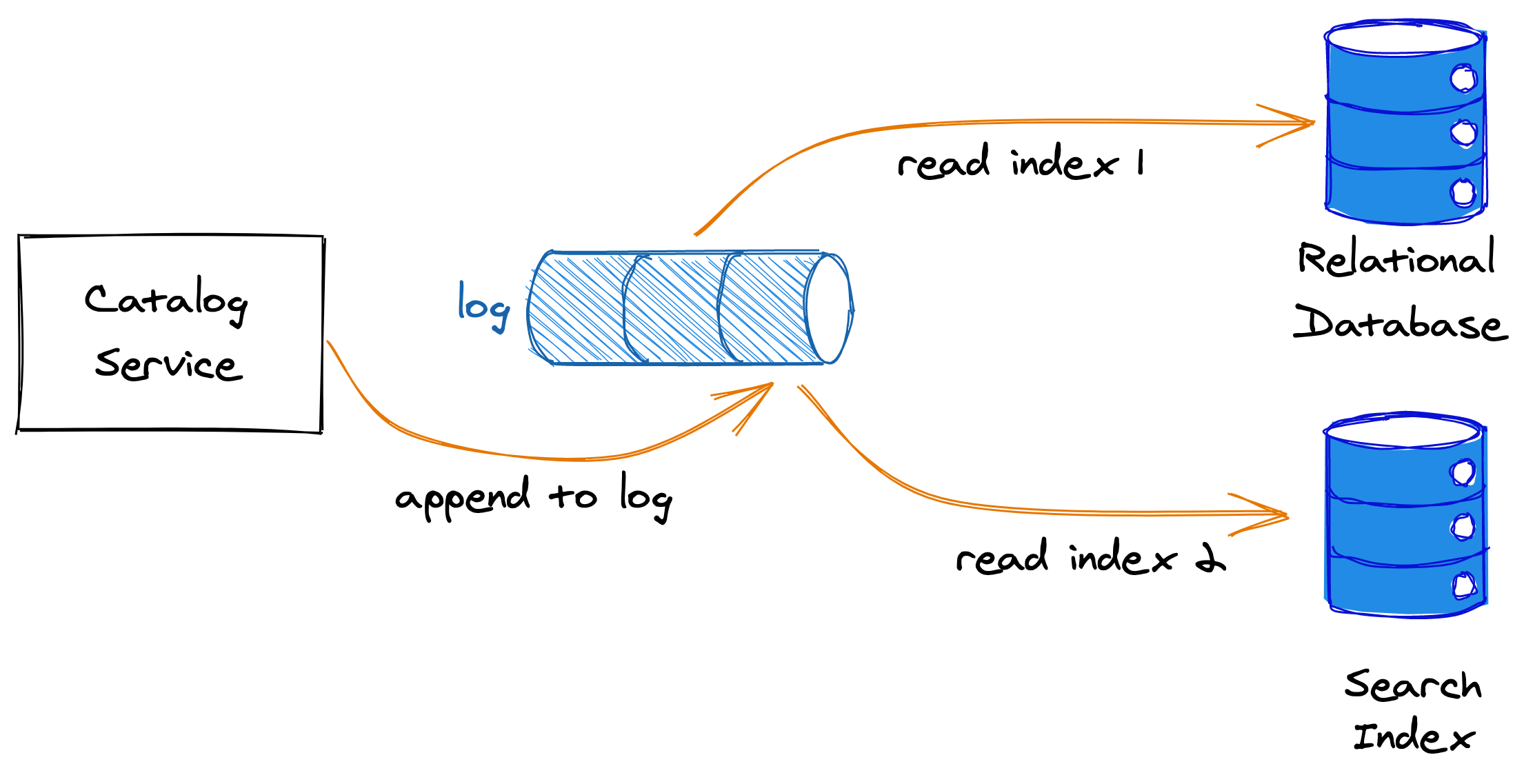
Figure 11.3: The producer appends entries at the end of the log, while the consumers read the entries at their own pace.
The consumers periodically checkpoint the index of the last message they processed. If a consumer crashes and comes back online after some time, it reads the last checkpoint and resumes reading messages from where it left off. Doing so ensures there is no data loss even if the consumer was offline for some time.
But, there is a problem as the consumer can potentially read the same message multiple times. For example, the consumer could process a message and crash before checkpointing its state. When it comes back online, it will eventually re-read the same message. Therefore, messages need to be idempotent so that no matter how many times they are read, the effect should be the same as if they had been processed only once. One way to do that is to decorate each message with a unique ID and ignore messages with duplicate IDs at read time.
We have already encountered the log abstraction in chapter 10 when discussing state machine replication. If you squint a little, you will see that what we have just implemented here is a form of state machine replication, where the state is represented by all products in the catalog, and the replication happens across the relational database and the search index.
Message logs are part of a more general communication interaction style referred to as messaging. In this model, the sender and the receiver don’t communicate directly with each other; they exchange messages through a channel that acts as a broker. The sender sends messages to the channel, and on the other side, the receiver reads messages from it.
A message channel acts as a temporary buffer for the receiver. Unlike the direct request-response communication style we have been using so far, messaging is inherently asynchronous as sending a message doesn’t require the receiving service to be online.
A message has a well-defined format, consisting of a header and a body. The message header contains metadata, such as a unique message ID, while its body contains the actual content. Typically, a message can either be a command, which specifies an operation to be invoked by the receiver, or an event, which signals the receiver that something of interest happened in the sender.
Services use inbound adapters to receive messages from messaging channels, which are part of their API surface, and outbound adapters to send messages, as shown in Figure 11.4. The log abstraction we have used earlier is just one form of messaging channel. Later in the book, we will encounter other types of channels, like queues, that don’t guarantee any ordering of the messages.
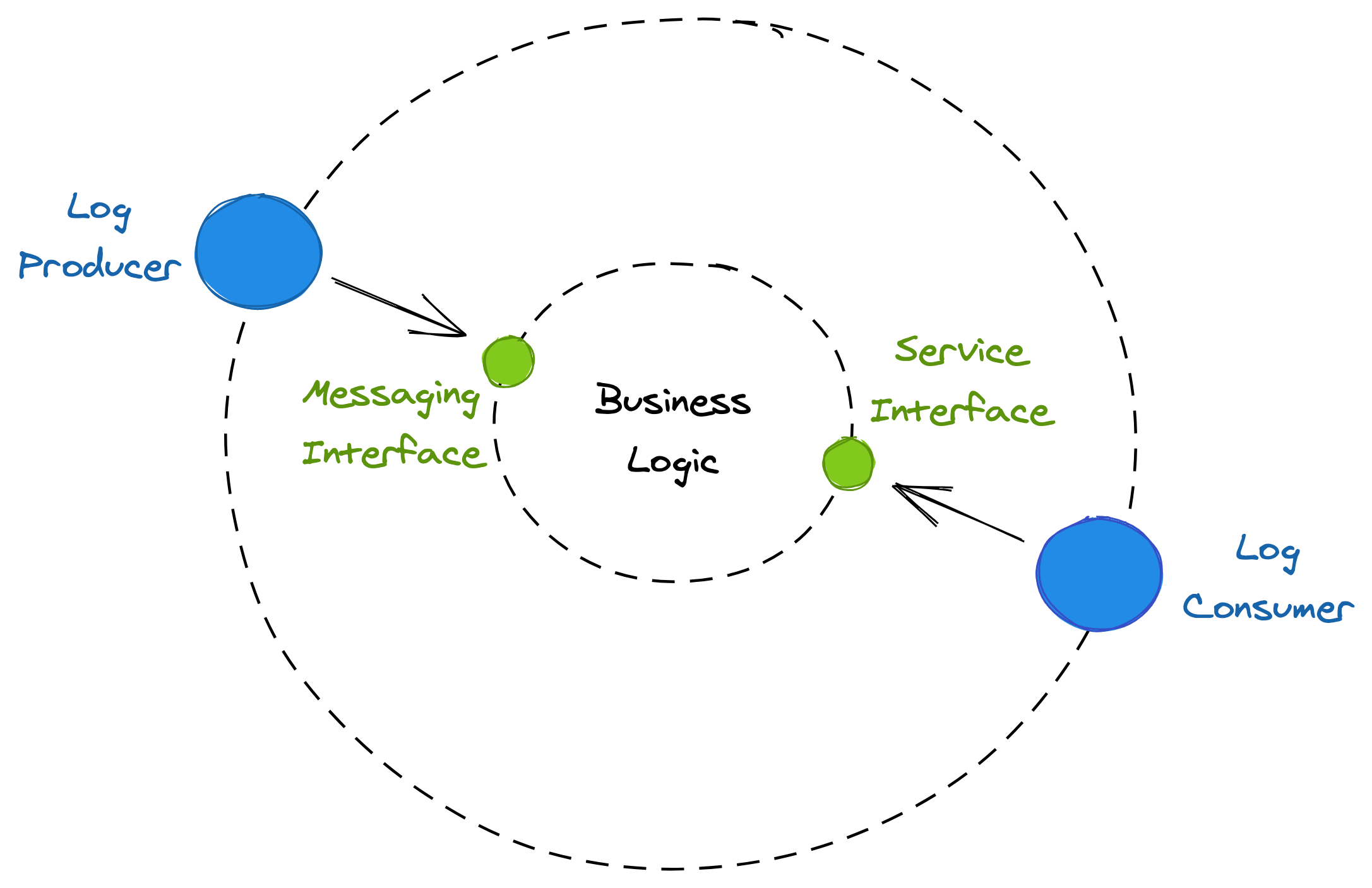
Figure 11.4: Inbound messaging adapters are part of a service’s API surface.
11.4.2 Sagas
Suppose we own a travel booking service. To book a trip, the travel service has to atomically book a flight through a dedicated service and a hotel through another. However, either of these services can fail their respective requests. If one booking succeeds, but the other fails, then the former needs to be canceled to guarantee atomicity. Hence, booking a trip requires multiple steps to complete, some of which are only required in case of failure. Since appending a single message to a log is no longer sufficient to commit the transaction, we can’t use the simple log-oriented solution presented earlier.
The Saga pattern provides a solution to this problem. A saga is a distributed transaction composed of a set of local transactions , where has a corresponding compensating local transaction used to undo its changes. The Saga guarantees that either all local transactions succeed, or in case of failure, that the compensating local transactions undo the partial execution of the transaction altogether. This guarantees the atomicity of the protocol; either all local transactions succeed, or none of them do. A Saga can be implemented with an orchestrator, the transaction’s coordinator, that manages the execution of the local transactions across the processes involved, the transaction’s participants.
In our example, the travel booking service is the transaction’s coordinator, while the flight and hotel booking services are the transaction’s participants. The Saga is composed of three local transactions: books a flight, books a hotel, and cancels the flight booked with .
At a high level, the Saga can be implemented with the workflow depicted in Figure 11.5:
- The coordinator initiates the transaction by sending a booking request to the flight service (). If the booking fails, no harm is done, and the coordinator marks the transaction as aborted.
- If the flight booking succeeds, the coordinator sends a booking request to the hotel service (). If the request succeeds, the transaction is marked as successful, and we are all done.
- If the hotel booking fails, the transaction needs to be aborted. The coordinator sends a cancellation request to the flight service to cancel the flight it previously booked (). Without the cancellation, the transaction would be left in an inconsistent state, which would break its atomicity guarantee.
The coordinator can communicate asynchronously with the participants via message channels to tolerate temporarily unavailable ones. As the transaction requires multiple steps to succeed, and the coordinator can fail at any time, it needs to persist the state of the transaction as it advances. By modeling the transaction as a state machine, the coordinator can durably checkpoint its state to a database as it transitions from one state to the next. This ensures that if the coordinator crashes and restarts, or another process is elected as the coordinator, it can resume the transaction from where it left off by reading the last checkpoint.
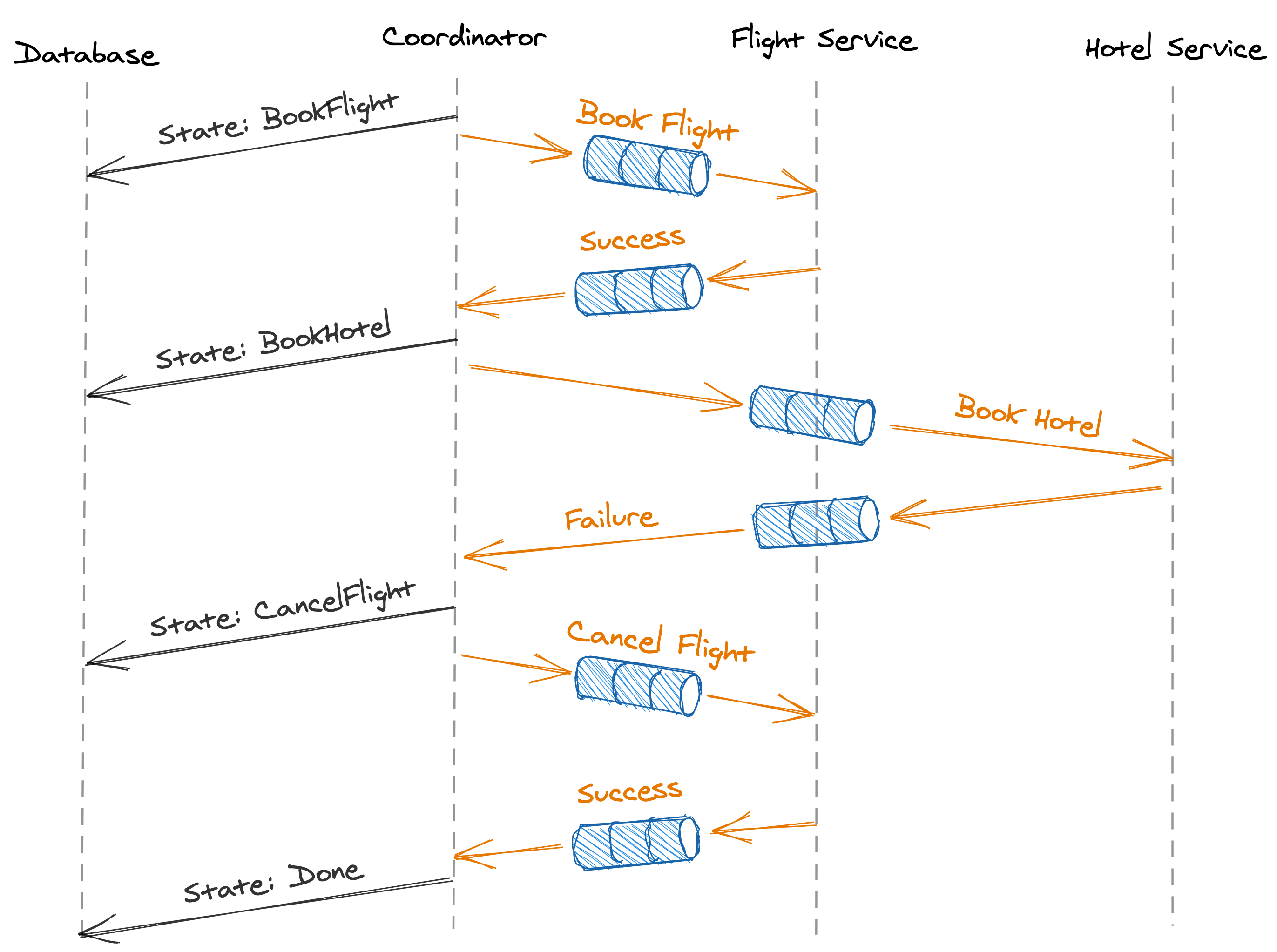
Figure 11.5: A workflow implementing an asynchronous transaction.
There is a caveat, though; if the coordinator crashes after sending a request but before backing up its state, it will have to re-send the request when it comes back online. Similarly, if sending a request times-out, the coordinator will have to retry it, causing the message to appear twice at the receiving end. Hence, the participants have to de-duplicate the messages they receive to make them idempotent.
In practice, you don’t need to build orchestration engines from scratch to implement such workflows. Serverless cloud compute services such as AWS Step Functions or Azure Durable Functions make it easy to create fully-managed workflows.
11.4.3 Isolation
We started our journey into asynchronous transactions as a way to design around the blocking nature of 2PC. To get here, we had to sacrifice the isolation guarantee that traditional ACID transactions provide. As it turns out, we can work around the lack of isolation as well. For example, one way to do that is with the use of semantic locks. The idea is that any data the Saga modifies is marked with a dirty flag. This flag is only cleared at the end of the transaction when it completes. Another transaction trying to access a dirty record can either fail and roll back its changes, or block until the dirty flag is cleared. The latter approach can introduce deadlocks, though, which requires a strategy to mitigate them.