10 Replication
Data replication is a fundamental building block of distributed systems. One reason to replicate data is to increase availability. If some data is stored exclusively on a single node, and that node goes down, the data won’t be accessible anymore. But if the data is replicated instead, clients can seamlessly switch to a replica. Another reason for replication is to increase scalability and performance; the more replicas there are, the more clients can access the data concurrently without hitting performance degradations.
Unfortunately replicating data is not simple, as it’s challenging to keep replicas consistent with one another. In this chapter, we will explore Raft’s replication algorithm, which is one of the algorithms that provide the strongest consistency guarantee possible — the guarantee that to the clients, the data appears to be located on a single node, even if it’s actually replicated.
Raft is based on a technique known as state machine replication. The main idea behind it is that a single process, the leader, broadcasts the operations that change its state to other processes, the followers. If the followers execute the same sequence of operations as the leader, then the state of each follower will match the leader’s. Unfortunately, the leader can’t simply broadcast operations to the followers and call it a day, as any process can fail at any time, and the network can lose messages. This is why a large part of the algorithm is dedicated to fault-tolerance.
10.1 State machine replication
When the system starts up, a leader is elected using Raft’s leader election algorithm, which we discussed in chapter 9. The leader is the only process that can make changes to the replicated state. It does so by storing the sequence of operations that alter the state into a local ordered log, which it then replicates to the followers; it’s the replication of the log that allows the state to be replicated across processes.
As shown in Figure 10.1, a log is an ordered list of entries where each entry includes:
- the operation to be applied to the state, like the assignment of 3 to x;
- the index of the entry’s position in the log;
- and the term number (the number in each box).
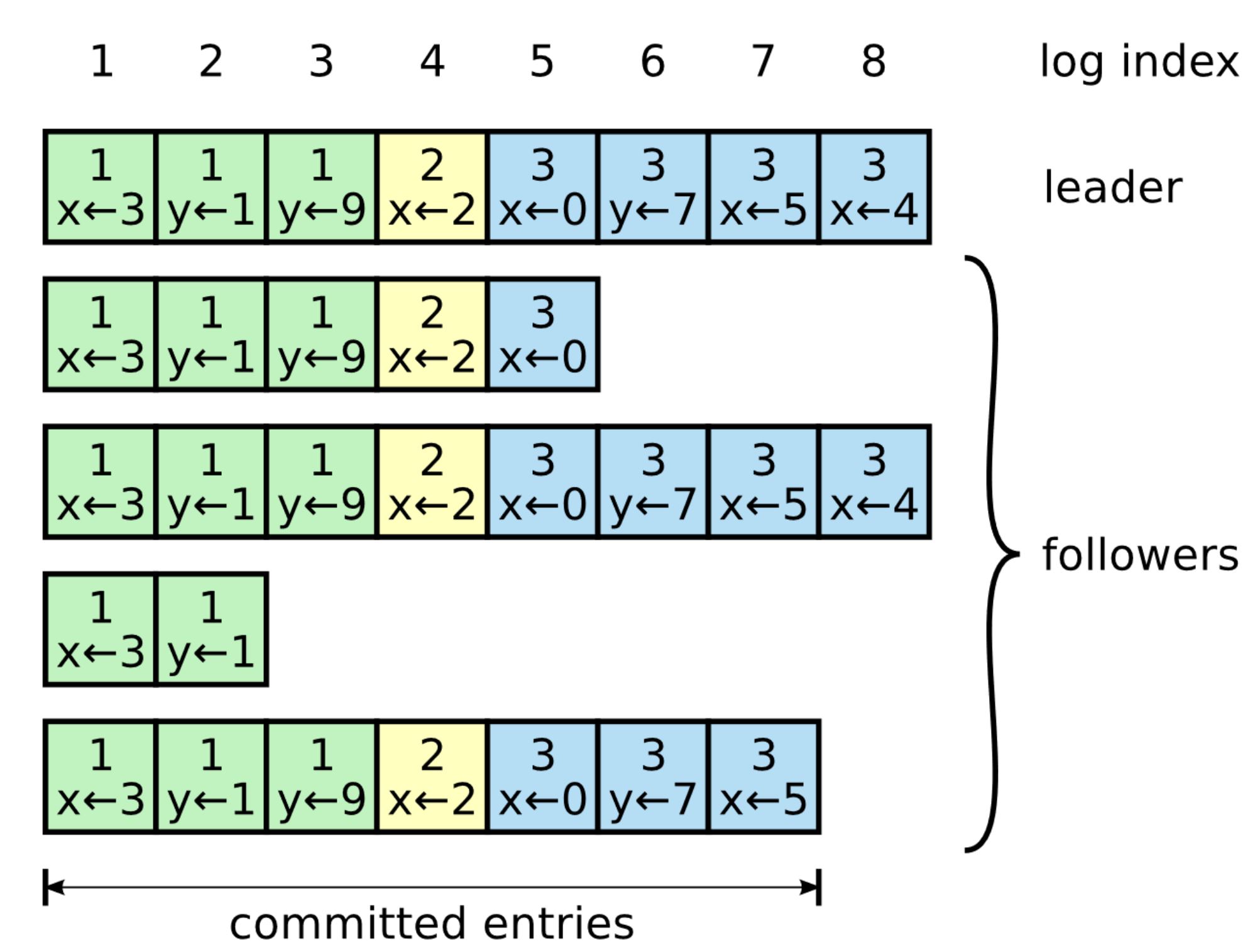
Figure 10.1: The leader’s log is replicated to its followers. This figure appears in Raft’s paper.
When the leader wants to apply an operation to its local state, it first appends a new log entry for the operation into its log. At this point, the operation hasn’t been applied to the local state just yet; it has only been logged.
The leader then sends a so-called AppendEntries request to each follower with the new entry to be added. This message is also sent out periodically, even in the absence of new entries, as it acts as a heartbeat for the leader.
When a follower receives an AppendEntries request, it appends the entry it received to its log and sends back a response to the leader to acknowledge that the request was successful. When the leader hears back successfully from a majority of followers, it considers the entry to be committed and executes the operation on its local state.
The committed log entry is considered to be durable and will eventually be executed by all available followers. The leader keeps track of the highest committed index in the log, which is sent in all future AppendEntries requests. A follower only applies a log entry to its local state when it finds out that the leader has committed the entry.
Because the leader needs to wait only for a majority of followers, it can make progress even if some processes are down, i.e., if there are followers, the system can tolerate up to failures. The algorithm guarantees that an entry that is committed is durable and will eventually be executed by all the processes in the system, not just those that were part of the original majority.
So far, we have assumed there are no failures, and the network is reliable. Let’s relax these assumptions. If the leader fails, a follower is elected as the new leader. But, there is a caveat: because the replication algorithm only needs a majority of the processes to make progress, it’s possible that when a leader fails, some processes are not up-to-date.
To avoid that an out-of-date process becomes the leader, a process can’t vote for one with a less up-to-date log. In other words, a process can’t win an election if it doesn’t contain all committed entries. To determine which of two processes’ logs is more up-to-date, the index and term of their last entries are compared. If the logs end with different terms, the log with the later term is more up-to-date. If the logs end with the same term, whichever log is longer is more up-to-date. Since the election requires a majority vote, and a candidate’s log must be at least as up-to-date as any other process in that majority to win the election, the elected process will contain all committed entries.
What if a follower fails? If an AppendEntries request can’t be delivered to one or more followers, the leader will retry sending it indefinitely until a majority of the followers successfully appended it to their logs. Retries are harmless as AppendEntries requests are idempotent, and followers ignore log entries that have already been appended to their logs.
So what happens when a follower that was temporarily unavailable comes back online? The resurrected follower will eventually receive an AppendEntries message with a log entry from the leader. The AppendEntries message includes the index and term number of the entry in the log that immediately precedes the one to be appended. If the follower can’t find a log entry with the same index and term number, it rejects the message, ensuring that an append to its log can’t create a hole. It’s as if the leader is sending a puzzle piece that the follower can’t fit in its version of the puzzle.
When the AppendEntries request is rejected, the leader retries sending the message, this time including the last two log entries — this is why we referred to the request as AppendEntries, and not as AppendEntry. This dance continues until the follower finally accepts a list of log entries that can be appended to its log without creating a hole. Although the number of messages exchanged can be optimized, the idea behind it is the same: the follower waits for a list of puzzle pieces that perfectly fit its version of the puzzle.
10.2 Consensus
State machine replication can be used for much more than just replicating data since it’s a solution to the consensus problem. Consensus is a fundamental problem studied in distributed systems research, which requires a set of processes to agree on a value in a fault-tolerant way so that:
- every non-faulty process eventually agrees on a value;
- the final decision of every non-faulty process is the same everywhere;
- and the value that has been agreed on has been proposed by a process.
Consensus has a large number of practical applications. For example, a set of processes agreeing which one should hold a lock or commit a transaction are consensus problems in disguise. As it turns out, deciding on a value can be solved with state machine replication. Hence, any problem that requires consensus can be solved with state machine replication too.
Typically, when you have a problem that requires consensus, the last thing you want to do is to solve it from scratch by implementing an algorithm like Raft. While it’s important to understand what consensus is and how it can be solved, many good open-source projects implement state machine replication and expose simple APIs on top of it, like etcd and ZooKeeper.
10.3 Consistency models
Let’s take a closer look at what happens when a client sends a request to a replicated store. In an ideal world, the request executes instantaneously, as shown in Figure 10.2.
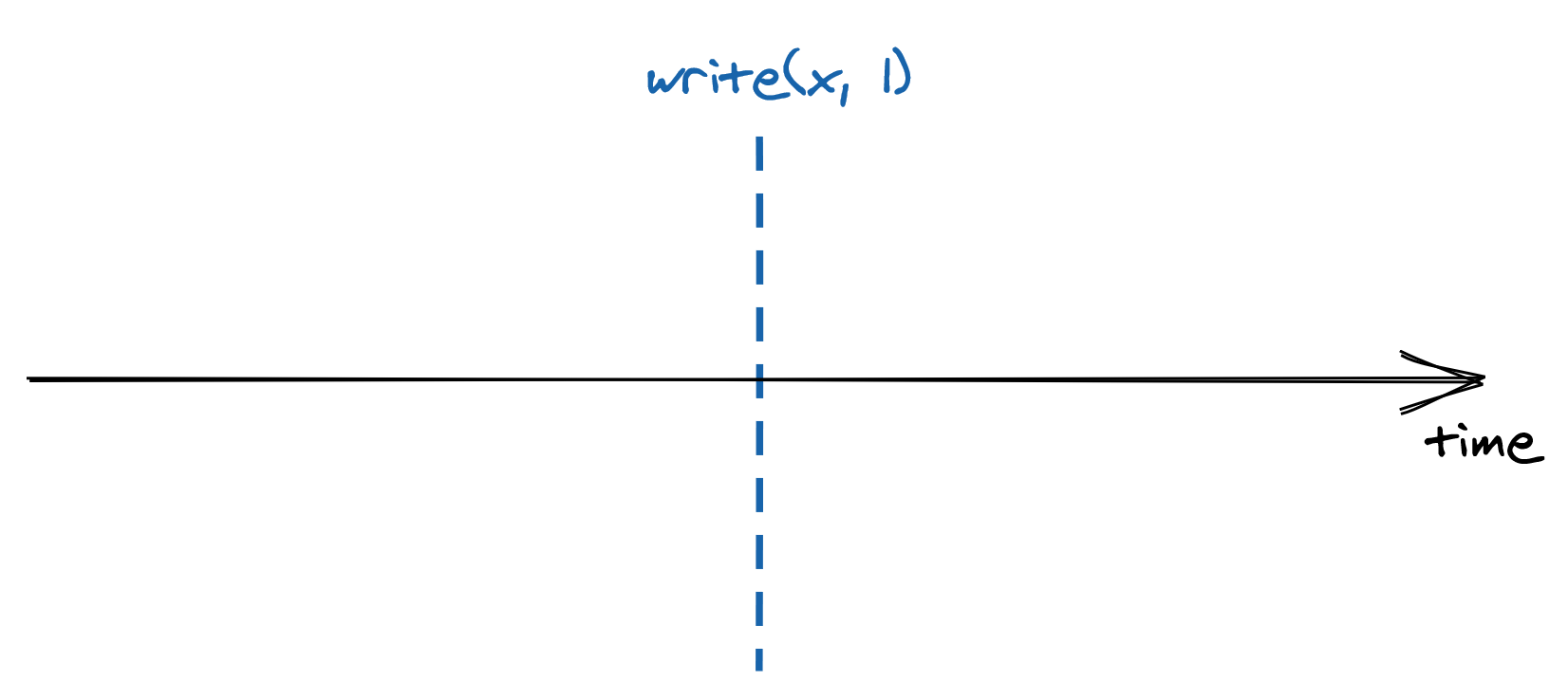
Figure 10.2: A write request executing instantaneously.
But in reality, things are quite different — the request needs to reach the leader, which then needs to process it and finally send back a response to the client. As shown in Figure 10.3, all these actions take time and are not instantaneous.
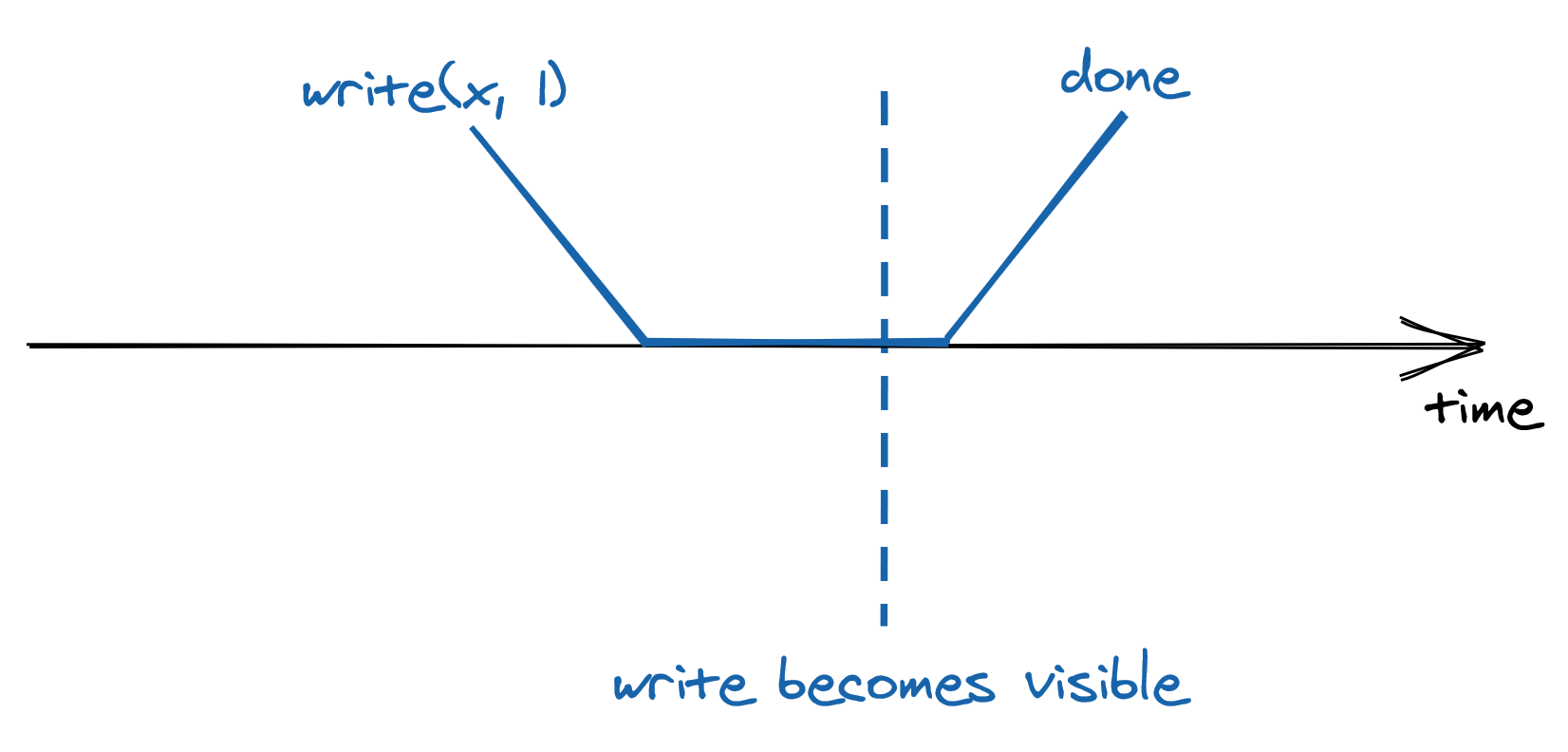
Figure 10.3: A write request can’t execute instantaneously because it takes time to reach the leader and be executed.
The best guarantee the system can provide is that the request executes somewhere between its invocation and completion time. You might think that this doesn’t look like a big deal; after all, it’s what you are used to when writing single-threaded applications. If you assign 1 to x and read its value right after, you expect to find 1 in there, assuming there is no other thread writing to the same variable. But, once you start dealing with systems that replicate their state on multiple nodes for high availability and scalability, all bets are off. To understand why that’s the case, we will explore different ways to implement reads in our replicated store.
In section 10.1, we looked at how Raft replicates the leader’s state to its followers. Since only the leader can make changes to the state, any operation that modifies it needs to necessarily go through the leader. But what about reads? They don’t necessarily have to go through the leader as they don’t affect the system’s state. Reads can be served by the leader, a follower, or a combination of leader and followers. If all reads were to go through the leader, the read throughput would be limited by that of a single process. But, if reads can be served by any follower instead, then two clients, or observers, can have a different view of the system’s state, since followers can lag behind the leader.
Intuitively, there is a trade-off between how consistent the observers’ views of the system are, and the system’s performance and availability. To understand this relationship, we need to define precisely what we mean by consistency. We will do so with the help of consistency models, which formally define the possible views of the system’s state observers can experience.
10.3.1 Strong consistency
If clients send writes and reads exclusively to the leader, then every request appears to take place atomically at a very specific point in time as if there was a single copy of the data. No matter how many replicas there are or how far behind they are lagging, as long as the clients always query the leader directly, from their point of view there is a single copy of the data.
Because a request is not served instantaneously, and there is a single process serving it, the request executes somewhere between its invocation and completion time. Another way to think about it is that once a request completes, it’s side-effects are visible to all observers as shown in Figure 10.4.
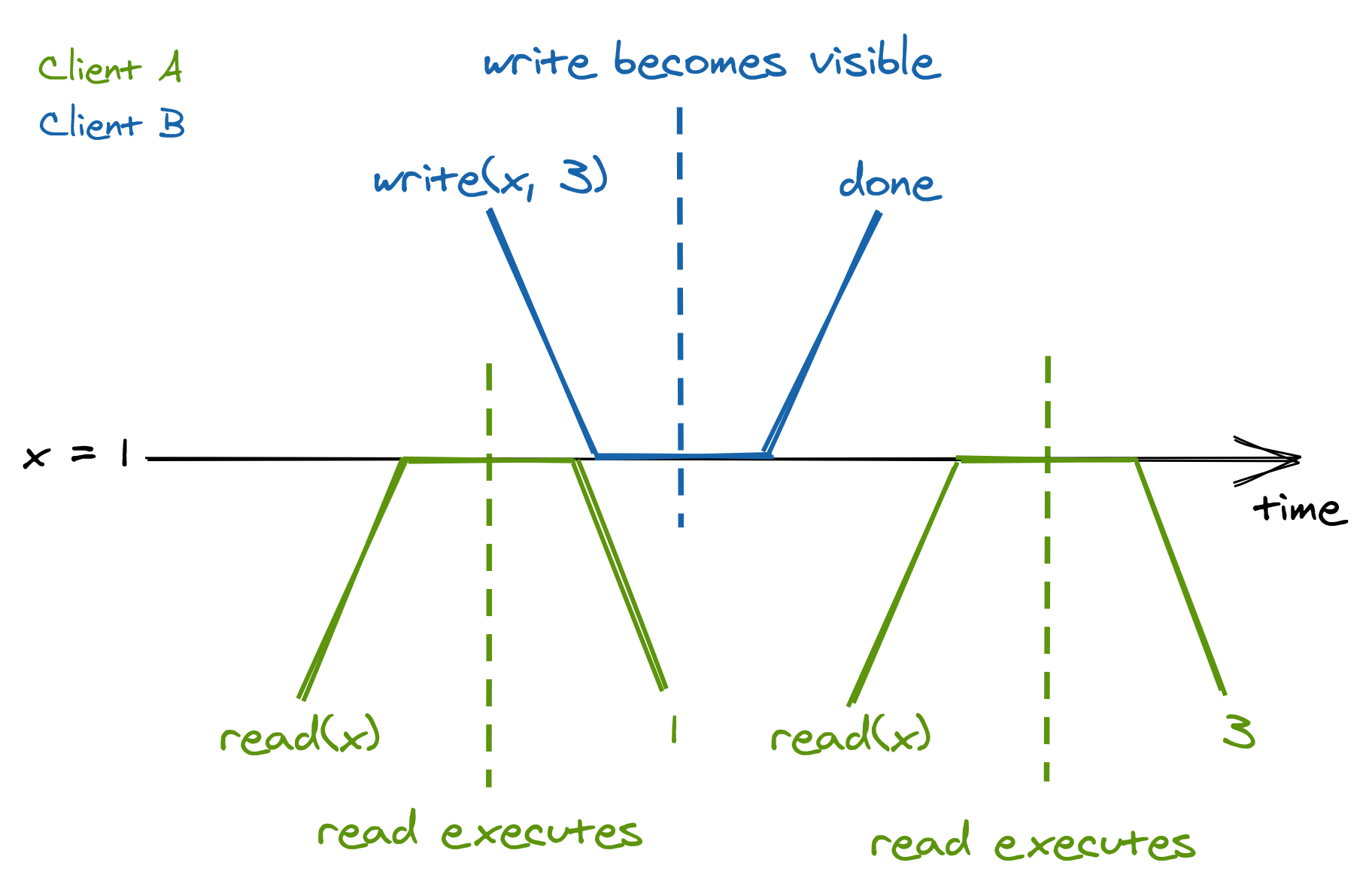
Figure 10.4: The side-effects of a strongly consistent operation are visible to all observers once it completes.
Since a request becomes visible to all other participants between its invocation and completion time, there is a real-time guarantee that must be enforced; this guarantee is formalized by a consistency model called linearizability, or strong consistency. Linearizability is the strongest consistency guarantee a system can provide for single-object requests.
What if the client sends a read request to the leader and by the time the request gets there, the server assumes it’s the leader, but it actually was just deposed? If the ex-leader was to process the request, the system would no longer be strongly consistent. To guard against this case, the presumed leader first needs to contact a majority of the replicas to confirm whether it still is the leader. Only then it’s allowed to execute the request and send back the response to the client. This considerably increases the time required to serve a read.
10.3.2 Sequential consistency
So far, we have discussed serializing all reads through the leader. But doing so creates a single choke point, which limits the system’s throughput. On top of that, the leader needs to contact a majority of followers to handle a read, which increases the time it takes to process a request. To increase the read performance, we could allow the followers to handle requests as well.
Even though a follower can lag behind the leader, it will always receive new updates in the same order as the leader. Suppose a client only ever queries follower 1, and another only ever queries follower 2. In that case, the two clients will see the state evolving at different times, as followers are not entirely in sync (see Figure 10.5).
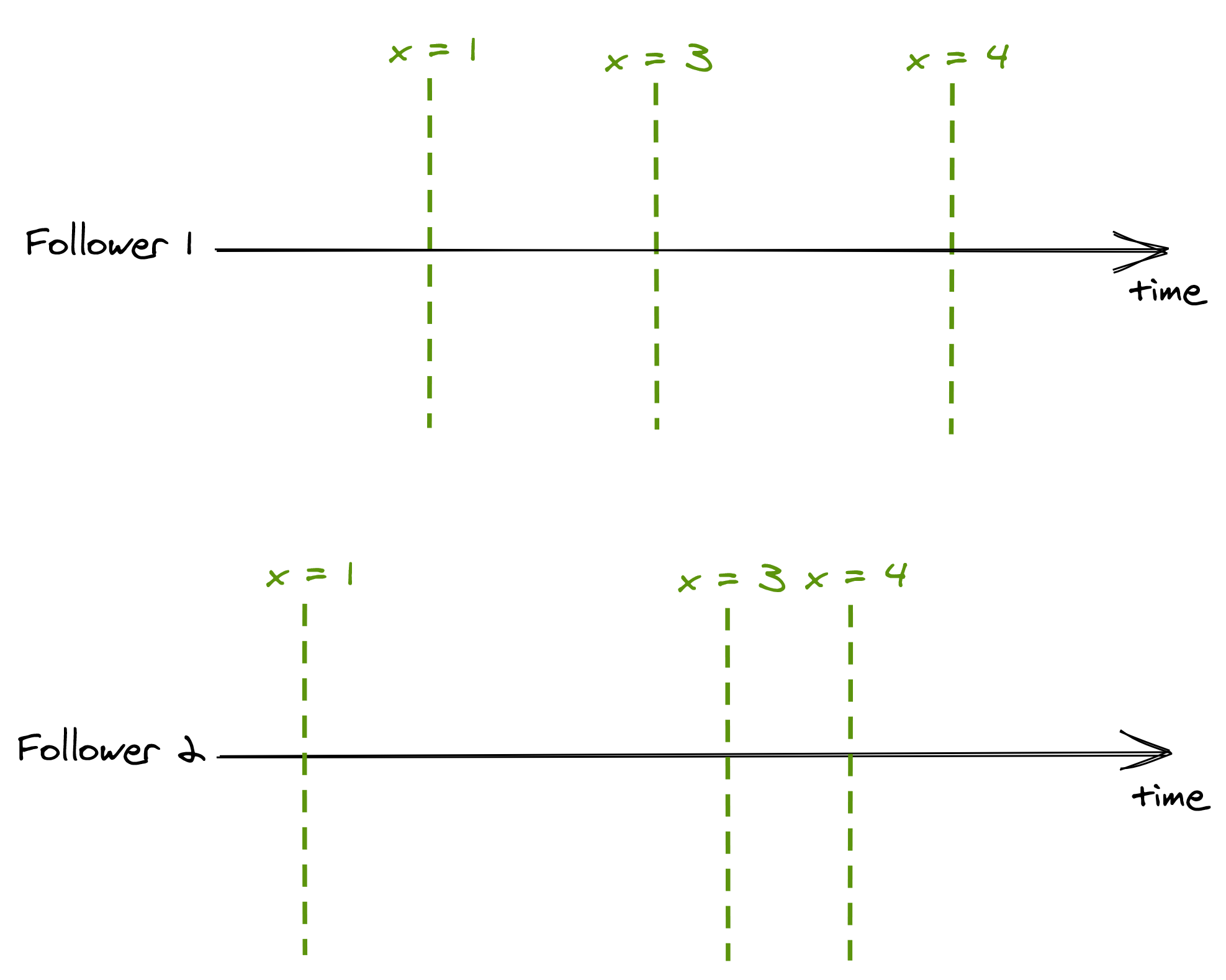
Figure 10.5: Although followers have a different view of the systems’ state, they process updates in the same order.
The consistency model in which operations occur in the same order for all observers, but doesn’t provide any real-time guarantee about when an operation’s side-effect becomes visible to them, is called sequential consistency. The lack of real-time guarantees is what differentiates sequential consistency from linearizability.
A producer/consumer system synchronized with a queue is an example of this model you might be familiar with; a producer process writes items to the queue, which a consumer reads. The producer and the consumer see the items in the same order, but the consumer lags behind the producer.
10.3.3 Eventual consistency
Although we managed to increase the read throughput, we had to pin clients to followers — what if a follower goes down? We could increase the availability of the store by allowing a client to query any follower. But, this comes at a steep price in terms of consistency. Say there are two followers, 1 and 2, where follower 2 lags behind follower 1. If a client queries follower 1 and right after follower 2, it will see a state from the past, which can be very confusing. The only guarantee the client has is that eventually, all followers will converge to the final state if the writes to the system stop. This consistency model is called eventual consistency.
It’s challenging to build applications on top of an eventually consistent data store because the behavior is different from the one you are used to when writing single-threaded applications. Subtle bugs can creep up that are hard to debug and reproduce. Yet, in eventual consistency’s defense, not all applications require linearizability. You need to make the conscious choice whether the guarantees offered by your data store, or lack thereof, satisfy your application’s requirements.
An eventually consistent store is perfectly fine if you want to keep track of the number of users visiting your website, as it doesn’t really matter if a read returns a number that is slightly out of date. But for a payment processor, you definitely want strong consistency.
10.3.4 CAP theorem
When a network partition happens, parts of the system become disconnected from each other. For example, some clients might no longer be able to reach the leader. The system has two choices when this happens, it can either:
- remain available by allowing followers to serve reads, sacrificing strong consistency;
- or guarantee strong consistency by failing reads that can’t reach the leader.
This concept is expressed by the CAP theorem, which can be summarized as: “strong consistency, availability and partition tolerance: pick two out of three.” In reality, the choice really is only between strong consistency and availability, as network faults are a given and can’t be avoided.
Even though network partitions can happen, they are usually rare. But, there is a trade-off between consistency and latency in the absence of a network partition. The stronger the consistency guarantee is, the higher the latency of individual operations must be. This relationship is expressed by the PACELC theorem. It states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C).
10.4 Practical considerations
To provide high availability and performance, off-the-shelf distributed data stores — sometimes referred to as NoSQL stores — come with counter-intuitive consistency guarantees. Others have knobs that allow you to choose whether you want better performance or stronger consistency guarantees, like Azure’s Cosmos DB and Cassandra. Because of that, you need to know what the trade-offs are. With what you have learned here, you will be in a much better place to understand why the trade-offs are there in the first place and what they mean for your application.