9 Leader election
Sometimes a single process in the system needs to have special powers, like being the only one that can access a shared resource or assign work to others. To grant a process these powers, the system needs to elect a leader among a set of candidate processes, which remains in charge until it crashes or becomes otherwise unavailable. When that happens, the remaining processes detect that the leader is no longer available and elect a new one.
A leader election algorithm needs to guarantee that there is at most one leader at any given time and that an election eventually completes. These two properties are also referred to as safety and liveness, respectively. This chapter explores how a specific algorithm, the Raft leader election algorithm, guarantees these properties.
9.1 Raft leader election
Raft’s leader election algorithm is implemented with a state machine in which a process is in one of three states (see Figure 9.1):
- the follower state, in which the process recognizes another one as the leader;
- the candidate state, in which the process starts a new election proposing itself as a leader;
- or the leader state, in which the process is the leader.
In Raft, time is divided into election terms of arbitrary length. An election term is represented with a logical clock, a numerical counter that can only increase over time. A term begins with a new election, during which one or more candidates attempt to become the leader. The algorithm guarantees that for any term there is at most one leader. But what triggers an election in the first place?
When the system starts up, all processes begin their journey as followers. A follower expects to receive a periodic heartbeat from the leader containing the election term the leader was elected in. If the follower doesn’t receive any heartbeat within a certain time period, a timeout fires and the leader is presumed dead. At that point, the follower starts a new election by incrementing the current election term and transitioning to the candidate state. It then votes for itself and sends a request to all the processes in the system to vote for it, stamping the request with the current election term.
The process remains in the candidate state until one of three things happens: it wins the election, another process wins the election, or some time goes by with no winner:
- The candidate wins the election — The candidate wins the election if the majority of the processes in the system vote for it. Each process can vote for at most one candidate in a term on a first-come-first-served basis. This majority rule enforces that at most one candidate can win a term. If the candidate wins the election, it transitions to the leader state and starts sending out heartbeats to the other processes.
- Another process wins the election — If the candidate receives a heartbeat from a process that claims to be the leader with a term greater than, or equal the candidate’s term, it accepts the new leader and returns to the follower state. If not, it continues in the candidate state. You might be wondering how that could happen; for example, if the candidate process was to stop for any reason, like for a long GC pause, by the time it resumes another process could have won the election.
- A period of time goes by with no winner — It’s unlikely but possible that multiple followers become candidates simultaneously, and none manages to receive a majority of votes; this is referred to as a split vote. When that happens, the candidate will eventually time out and start a new election. The election timeout is picked randomly from a fixed interval to reduce the likelihood of another split vote in the next election.
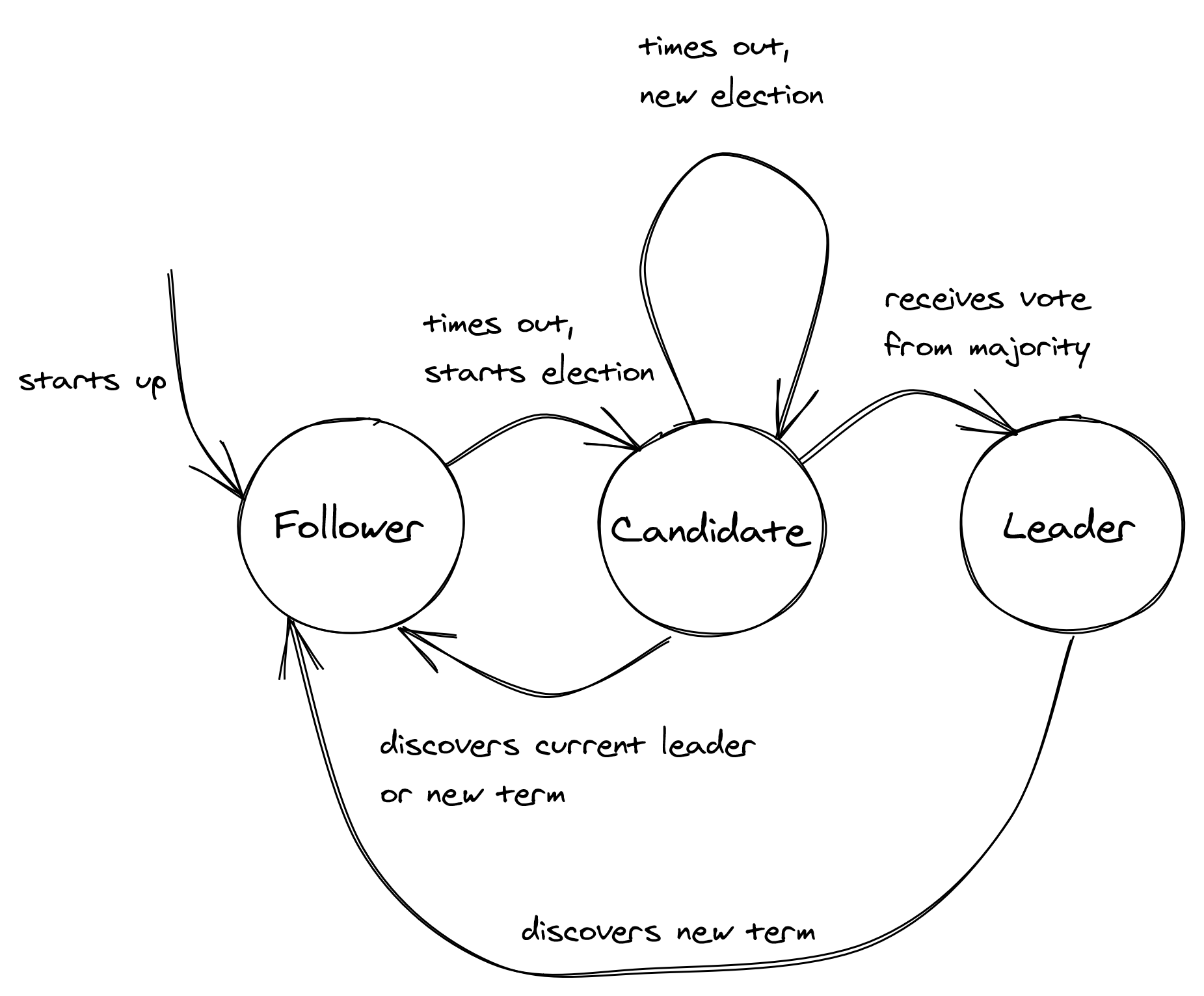
Figure 9.1: Raft’s leader election algorithm represented as a state machine.
9.2 Practical considerations
There are many more leader election algorithms out there than the one presented here, but Raft’s implementation is a modern take on the problem optimized for simplicity and understandability, which is why I chose it. That said, you will rarely need to implement leader election from scratch, as you can leverage linearizable key-value stores, like etcd or ZooKeeper, which offer abstractions that make it easy to implement leader election. The abstractions range from basic primitives like compare-and-swap to full-fledged distributed mutexes.
Ideally, the external store should at the very least offer an atomic compare-and-swap operation with an expiration time (TTL). The compare-and-swap operation updates the value of a key if and only if the value matches the expected one; the expiration time defines the time to live for a key, after which the key expires and is removed from the store if the lease hasn’t been extended. The idea is that each competing process tries to acquire a lease by creating a new key with compare-and-swap using a specific TTL. The first process to succeed becomes the leader and remains such until it stops renewing the lease, after which another process can become the leader.
The TTL expiry logic can also be implemented on the client-side, like this locking library for DynamoDB does, but the implementation is more complex, and it still requires the data store to offer a compare-and-swap operation.
You might think that’s enough to guarantee there can’t be more than one leader in your application. Unfortunately, that’s not the case.
To see why, suppose there are multiple processes that need to update a file on a shared blob store, and you want to guarantee that only a single process at a time can do so to avoid race conditions. To achieve that, you decide to use a distributed mutex, a form of leader election. Each process tries to acquire the lock, and the one that does so successfully reads the file, updates it in memory, and writes it back to the store:
if lock.acquire():
try:
content = store.read(blob_name)
new_content = update(content)
store.write(blob_name, new_content)
except:
lock.release()The problem here is that by the time the process writes the content to the store, it might no longer be the leader and a lot might have happened since it was elected. For example, the operating system might have preempted and stopped the process, and several seconds will have passed by the time it’s running again. So how can the process ensure that it’s still the leader then? It could check one more time before writing to the store, but that doesn’t eliminate the race condition, it just makes it less likely.
To avoid this issue, the data store downstream needs to verify that the request has been sent by the current leader. One way to do that is by using a fencing token. A fencing token is a number that increases every time that a distributed lock is acquired — in other words, it’s a logical clock. When the leader writes to the store, it passes down the fencing token to it. The store remembers the value of the last token and accepts only writes with a greater value:
success, token = lock.acquire()
if success:
try:
content = store.read(blob_name)
new_content = update(content)
store.write(blob_name, new_content, token)
except:
lock.release()This approach adds complexity as the downstream consumer, the blob store, needs to support fencing tokens. If it doesn’t, you are out of luck, and you will have to design your system around the fact that occasionally there will be more than one leader. For example, if there are momentarily two leaders and they both perform the same idempotent operation, no harm is done.
Although having a leader can simplify the design of a system as it eliminates concurrency, it can become a scaling bottleneck if the number of operations performed by the leader increases to the point where it can no longer keep up. When that happens, you might be forced to re-design the whole system.
Also, having a leader introduces a single point of failure with a large blast radius; if the election process stops working or the leader isn’t working as expected, it can bring down the entire system with it.
You can mitigate some of these downsides by introducing partitions and assigning a different leader per partition, but that comes with additional complexity. This is the solution many distributed data stores use.
Before considering the use of a leader, check whether there are other ways of achieving the desired functionality without it. For example, optimistic locking is one way to guarantee mutual exclusion at the cost of wasting some computing power. Or perhaps high availability is not a requirement for your application, in which case having just a single process that occasionally crashes and restarts is not a big deal.
As a rule of thumb, if you must use leader election, you have to minimize the work it performs and be prepared to occasionally have more than one leader if you can’t support fencing tokens end-to-end.