7 Failure detection
Several things can go wrong when a client sends a request to a server. In the happy path, the client sends a request and receives a response back. But, what if no response comes back after some time? In that case, it’s impossible to tell whether the server is just very slow, it crashed, or a message couldn’t be delivered because of a network issue (see Figure 7.1).
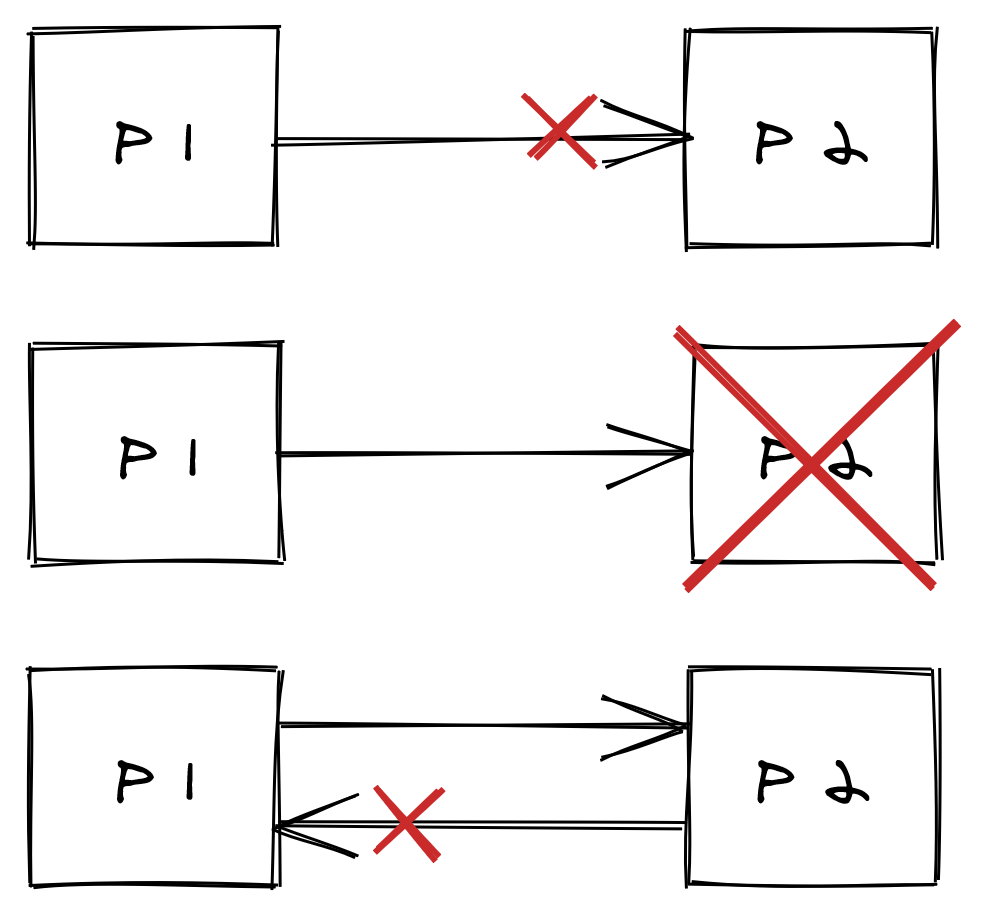
Figure 7.1: P1 can’t tell whether P2 is slow, crashed or a message was delayed/dropped because of a network issue.
In the worst case, the client will wait forever for a response that will never arrive. The best it can do is make an educated guess on whether the server is likely to be down or unreachable after some time has passed. To do that, the client can configure a timeout to trigger if it hasn’t received a response from the server after a certain amount of time. If and when the timeout triggers, the client considers the server unavailable and throws an error.
The tricky part is defining how long the amount of time that triggers this timeout should be. If it’s too short and the server is reachable, the client will wrongly consider the server dead; if it’s too long and the server is not reachable, the client will block waiting for a response. The bottom line is that it’s not possible to build a perfect failure detector.
A process doesn’t necessarily need to wait to send a message to find out that the destination is not reachable. It can also actively try to maintain a list of processes that are available using pings or heartbeats.
A ping is a periodic request that a process sends to another to check whether it’s still available. The process expects a response to the ping within a specific time frame. If that doesn’t happen, a timeout is triggered that marks the destination as dead. However, the process will keep regularly sending pings to it so that if and when it comes back online, it will reply to a ping and be marked as available again.
A heartbeat is a message that a process periodically sends to another to inform it that it’s still up and running. If the destination doesn’t receive a heartbeat within a specific time frame, it triggers a timeout and marks the process that missed the heartbeat as dead. If that process comes later back to life and starts sending out heartbeats, it will eventually be marked as available again.
Pings and heartbeats are typically used when specific processes frequently interact with each other, and an action needs to be taken as soon as one of them is no longer reachable. If that’s not the case, detecting failures just at communication time is good enough.