5 APIs
A service exposes operations to its consumers via a set of interfaces implemented by its business logic. As remote clients can’t access these directly, adapters — which make up the service’s application programming interface (API) — translate messages received from IPC mechanisms to interface calls, as shown in Figure 5.1.
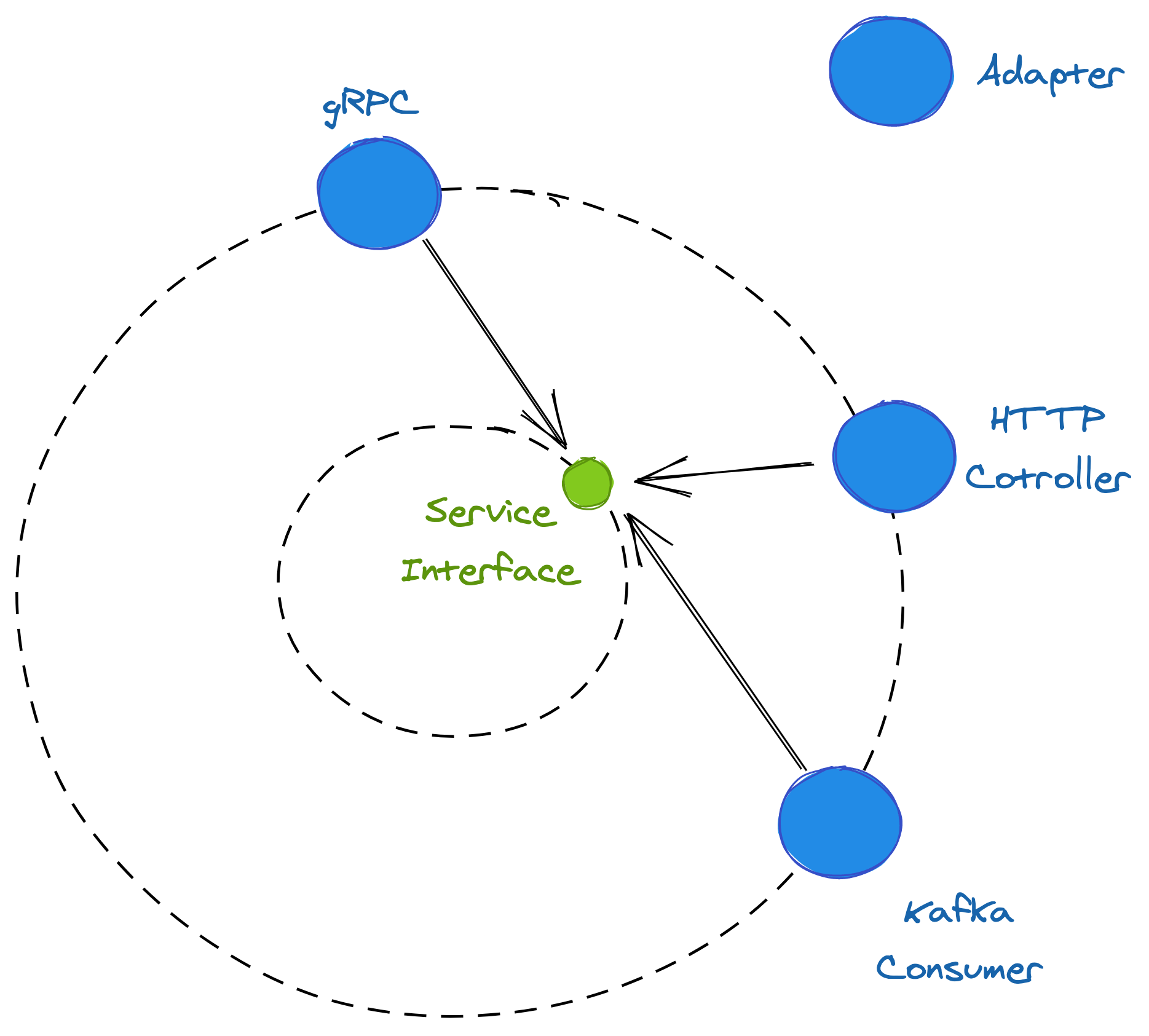
Figure 5.1: Adapters translate messages received from IPC mechanisms to interface calls.
The communication style between a client and a service can be direct or indirect, depending on whether the client communicates directly with the service or indirectly with it through a broker. Direct communication requires that both processes are up and running for the communication to succeed. However, sometimes this guarantee is either not needed or very hard to achieve, in which case indirect communication can be used.
In this chapter, we will focus our attention on a direct communication style called request-response, in which a client sends a request message to the service, and the service replies back with a response message. This is similar to a function call, but across process boundaries and over the network.
The request and response messages contain data that is serialized in a language-agnostic format. The format impacts a message’s serialization and deserialization speed, whether it’s human-readable, and how hard it is to evolve it over time. A textual format like JSON is self-describing and human-readable, at the expense of increased verbosity and parsing overhead. On the other hand, a binary format like Protocol Buffers is leaner and more performant than a textual one at the expense of human readability.
When a client sends a request to a service, it can block and wait for the response to arrive, making the communication synchronous. Alternatively, it can ask the outbound adapter to invoke a callback when it receives the response, making the communication asynchronous.
Synchronous communication is inefficient, as it blocks threads that could be used to do something else. Some languages, like JavaScript and C#, can completely hide callbacks through language primitives such as async/await. These primitives make writing asynchronous code as straightforward as writing a synchronous one.
The most commonly used IPC technologies for request-response interactions are gRPC, REST, and GraphQL. Typically, internal APIs used for service-to-service communications within an organization are implemented with a high-performance RPC framework like gRPC. In contrast, external APIs available to the public tend to be based on REST. In the rest of the chapter, we will walk through the process of creating a RESTful HTTP API.
5.1 HTTP
HTTP is a request-response protocol used to encode and transport information between a client and a server. In an HTTP transaction, the client sends a request message to the server’s API endpoint, and the server replies back with a response message, as shown in Figure 5.2.
In HTTP 1.1, a message is a textual block of data that contains a start line, a set of headers, and an optional body:
- In a request message, the start line indicates what the request is for, and in a response message, it indicates what the response’s result is.
- The headers are key-value pairs with meta-information that describe the message.
- The message’s body is a container for data.
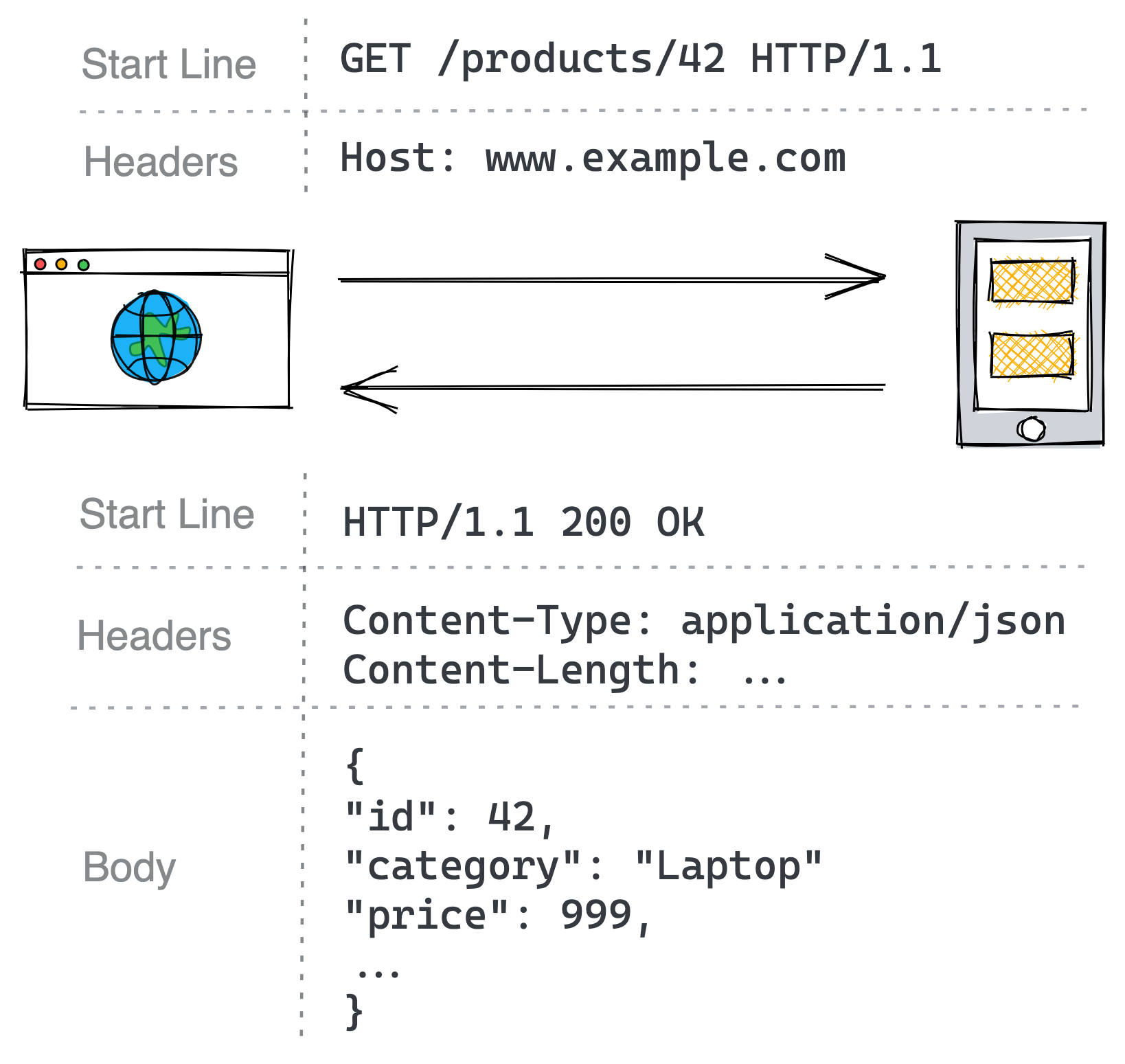
Figure 5.2: An example HTTP transaction between a browser and a web server.
HTTP is a stateless protocol, which means that everything needed by a server to process a request needs to be specified within the request itself, without context from previous requests. HTTP uses TCP for the reliability guarantees discussed in chapter 2. When it rides on top of TLS, it’s also referred to as HTTPS. Needless to say, you should use HTTPS by default.
HTTP 1.1 keeps a connection to a server open by default to avoid creating a new one when the next transaction occurs. Unfortunately, a new request can’t be issued until the response of the previous one has been received; in other words, the transactions have to be serialized. For example, a browser that needs to fetch several images to render an HTML page has to download them one at the time, which can be very inefficient.
Although HTTP 1.1 technically allows some type of requests to be pipelined, it has never been widely adopted due to its limitations. With HTTP 1.1, the typical way to improve the throughput of outgoing requests is by creating multiple connections. Although it comes with a price because connections consume resources like memory and sockets.
HTTP 2 was designed from the ground up to address the main limitations of HTTP 1.1. It uses a binary protocol rather than a textual one, which allows HTTP 2 to multiplex multiple concurrent request-response transactions on the same connection. In early 2020 about half of the most-visited websites on the Internet were using the new HTTP 2 standard. HTTP 3 is the latest iteration of the HTTP standard, which is slowly being rolled out to browsers as I write this — it’s based on UDP and implements its own transport protocol to address some of TCP’s shortcomings.
Given that neither HTTP 2 nor HTTP 3 are ubiquitous yet, you still need to be familiar with HTTP 1.1, which is the standard the book uses going forward as its plain text format is easier to depict.
5.2 Resources
Suppose we are responsible for implementing a service to manage the product catalog of an e-commerce application. The service must allow users to browse the catalog and admins to create, update, or delete products. Sounds simple enough; the interface of the service could be defined like this:
interface CatalogService
{
List<Product> GetProducts(...);
Product GetProduct(...);
void AddProduct(...);
void DeleteProduct(...);
void UpdateProduct(...)
}External clients can’t invoke interface methods directly, which is where the HTTP adapter comes in. It handles an HTTP request by invoking the methods defined in the service interface and converts their return values into HTTP responses. But to perform this mapping, we first need to understand how to model the API with HTTP in the first place.
An HTTP server hosts resources. A resource is an abstraction of information, like a document, an image, or a collection of other resources. It’s identified by a URL, which describes the location of the resource on the server.
In our catalog service, the collection of products is a type of resource, which could be accessed with a URL like https://www.example.com/products?sort=price, where:
- https is the protocol;
- www.example.com is the hostname;
- products is the name of the resource;
- ?sort=price is the query string, which contains additional parameters that affect the way the request is handled by the service; in this case, the sort order of the list of products returned in the response.
The URL without the query string is also referred to as the API’s /products endpoint.
HTTP gives us a lot of flexibility on how to design our API. Nothing forbids us from creating a resource name that looks like a remote procedure, like /getProducts, which expects the additional parameters to be specified in the request’s body, rather than in the query string. But if we were to do this, we could no longer cache the list of products by its URL. This is where REST comes in — it’s a set of conventions and constraints for designing elegant and scalable HTTP APIs. In the rest of this chapter, we will use REST principles where it makes sense.
How should we model relationships? For example, a specific product is a resource that belongs to the collection of products, and that should ideally be reflected in its URL. Hence, the product with the unique identifier 42 could be identified with the relative URL /products/42. The product could also have a list of reviews associated with it, which we can model by appending the nested resource name, reviews, after the parent one, /products/42, e.g., /products/42/reviews. If we were to continue to add more nested resources, the API would become complex. As a rule of thumb, URLs should be kept simple, even if it means that the client might have to perform multiple requests to get the information it needs.
Now that we know how to refer to resources, let’s see how to represent them on the wire when they are transmitted in the body of request and response messages. A resource can be represented in different ways; for example, a product can be represented either with an XML or a JSON document. JSON is typically used to represent non-binary resources in REST APIs:
{
"id": 42,
"category": "Laptop",
"price": 999,
}When a client sends a request to a server to get a resource, it adds several headers to the message to describe its preferred representation. The server uses these headers to pick the most appropriate representation for the resource and decorates the response message with headers that describe it.
5.3 Request methods
HTTP requests can create, read, update, and delete (CRUD) resources by using request methods. When a client makes a request to a server for a particular resource, it specifies which method to use. You can think of a request method as the verb or action to use on a resource.
The most commonly used methods are POST, GET, PUT, and DELETE. For example, the API of our catalog service could be defined as follows:
- POST /products — Create a new product and return the URI of the new resource.
- GET /products — Retrieve a list of products. The query string can be used to filter, paginate, and sort the collection. Pagination should be used to return a limited number of resources per call to prevent denial of service attacks.
- GET /products/42 — Retrieve product 42.
- PUT /products/42 — Update product 42.
- DELETE /products/42 — Delete product 42.
Request methods can be classified depending on whether they are safe and idempotent. A safe method should not have any visible side effects and can be safely cached. An idempotent method can be executed multiple times, and the end result should be the same as if it was executed just a single time.
| Method | Safe | Idempotent |
|---|---|---|
| GET | Yes | Yes |
| PUT | No | Yes |
| POST | No | No |
| DELETE | No | Yes |
The concept of idempotency is crucial and will come up repeatedly in the rest of the book, not just in the context of HTTP requests. An idempotent request makes it possible to safely retry requests that have succeeded, but for which the client never received a response; for example, because it crashed and restarted before receiving it.
5.4 Response status codes
After the service has received a request, it needs to send a response back to the client. The HTTP response contains a status code to communicate to the client whether the request succeeded or not. Different status code ranges have different meanings.
Status codes between 200 and 299 are used to communicate success. For example, 200 (OK) means that the request succeeded, and the body of the response contains the requested resource.
Status codes between 300 and 399 are used for redirection. For example, 301 (Moved Permanently) means that the requested resource has been moved to a different URL, specified in the response message Location header.
Status codes between 400 and 499 are reserved for client errors. A request that fails with a client error will usually continue to return the same error if it’s retried, as the error is caused by an issue with the client, not the server. Because of that, it shouldn’t be retried. These client errors are common:
- 400 (Bad Request) — Validating the client-side input has failed.
- 401 (Unauthorized) — The client isn’t authorized to access a resource.
- 403 (Forbidden) — The user is authenticated, but it’s not allowed to access a resource.
- 404 (Not Found) — The server couldn’t find the requested resource.
Status codes between 500 and 599 are reserved for server errors. A request that fails with a server error can be retried as the issue that caused it to fail might be fixed by the time the retry is processed by the server. These are some typical server status codes:
- 500 (Internal Server Error) — A generic server error.
- 502 (Bad Gateway) — Indicates an invalid response from an upstream server.
- 503 (Service Unavailable) — Indicates that the server can’t currently serve the request, but might be able to in the future.
5.5 OpenAPI
Now that we have learned how to map the operations defined by our service’s interface onto RESTful HTTP endpoints, we can formally define the API with an interface definition language (IDL), a language independent description of it. The IDL definition can be used to generate boilerplate code for the IPC adapter and client SDKs in your languages of choice.
The OpenAPI specification, which evolved from the Swagger project, is one of the most popular IDL for RESTful APIs based on HTTP. With it, we can formally describe our API in a YAML document, including the available endpoints, supported request methods and response status codes for each endpoint, and the schema of the resources’ JSON representation.
For example, this is how part of the /products endpoint of the catalog service’s API could be defined:
openapi: 3.0.0
info:
version: "1.0.0"
title: Catalog Service API
paths:
/products:
get:
summary: List products
parameters:
- in: query
name: sort
required: false
schema:
type: string
responses:
'200':
description: list of products in catalog
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/ProductItem'
'400':
description: bad input
components:
schemas:
ProductItem:
type: object
required:
- id
- name
- category
properties:
id:
type: number
name:
type: string
category:
type: stringAlthough this is a very simple example and we won’t spend time describing OpenAPI further as it’s mostly an implementation detail, it should give you an idea of its expressiveness. With this definition, we can then run a tool to generate the API’s documentation, boilerplate adapters, and client SDKs for our languages of choice.
5.6 Evolution
APIs start out as beautifully-designed interfaces. Slowly, but surely, they will need to change over time to adapt to new use cases. The last thing you want to do when evolving your API is to introduce a breaking change that requires modifying all the clients in unison, some of which you might have no control over in the first place.
There are two types of changes that can break compatibility, one at the endpoint level and another at the message level. For example, if you were to change the /products endpoint to /fancy-products, it would obviously break clients that haven’t been updated to support the new endpoint. The same goes when making a previously optional query parameter mandatory.
Changing the schema of request and response messages in a backward incompatible way can also wreak havoc. For example, changing the type of the category property in the Product schema from string to number is a breaking change as the old deserialization logic would blow up in clients. Similar arguments can be made for messages represented with other serialization formats, like Protocol Buffers.
To support breaking changes, REST APIs should be versioned by either prefixing a version number in the URLs (e.g., /v1/products/), using a custom header (e.g., Accept-Version: v1) or the Accept header with content negotiation (e.g., Accept: application/vnd.example.v1+json).
As a general rule of thumb, you should try to evolve your API in a backwards-compatible way unless you have a very good reason, in which case you need to be prepared to deal with the consequences. Backwards-compatible APIs tend to be not particularly elegant, but they are a necessary evil. There are tools that can compare the IDL specifications of your API and check for breaking changes; use them in your continuous integration pipelines.