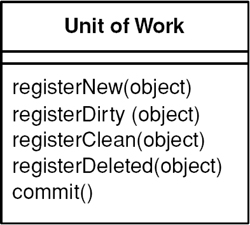
Maintains a list of objects affected by a business transaction and coordinates the writing out of changes and the resolution of concurrency problems.
When you’re pulling data in and out of a database, it’s important to keep track of what you’ve changed; otherwise, that data won’t be written back into the database. Similarly you have to insert new objects you create and remove any objects you delete.
You can change the database with each change to your object model, but this can lead to lots of very small database calls, which ends up being very slow. Furthermore it requires you to have a transaction open for the whole interaction, which is impractical if you have a business transaction that spans multiple requests. The situation is even worse if you need to keep track of the objects you’ve read so you can avoid inconsistent reads.
A Unit of Work keeps track of everything you do during a business transaction that can affect the database. When you’re done, it figures out everything that needs to be done to alter the database as a result of your work.
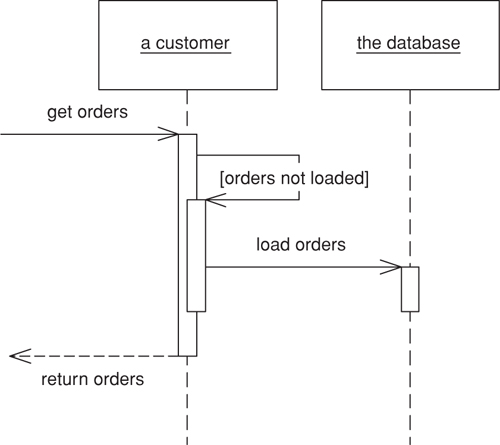
The obvious things that cause you to deal with the database are changes: new object created and existing ones updated or deleted. Unit of Work is an object that keeps track of these things. As soon as you start doing something that may affect a database, you create a Unit of Work to keep track of the changes. Every time you create, change, or delete an object you tell the Unit of Work. You can also let it know about objects you’ve read so that it can check for inconsistent reads by verifying that none of the objects changed on the database during the business transaction.
The key thing about Unit of Work is that, when it comes time to commit, the Unit of Work decides what to do. It opens a transaction, does any concurrency checking (using Pessimistic Offline Lock (426) or Optimistic Offline Lock (416)), and writes changes out to the database. Application programmers never explicitly call methods for database updates. This way they don’t have to keep track of what’s changed or worry about how referential integrity affects the order in which they need to do things.
Of course for this to work the Unit of Work needs to know what objects it should keep track of. You can do this either by the caller doing it or by getting the object to tell the Unit of Work.
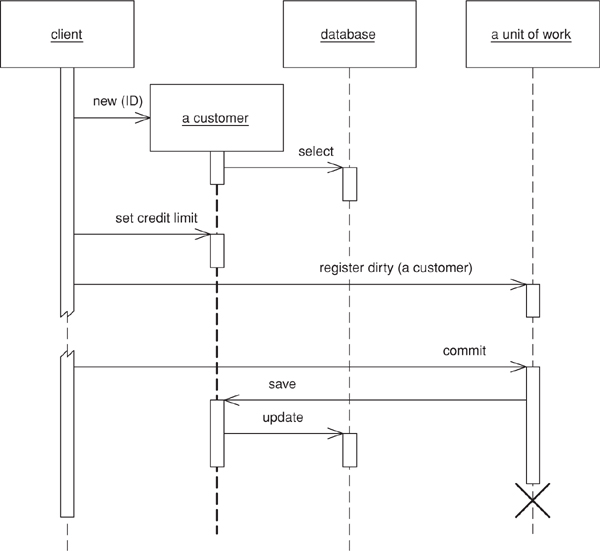
With caller registration (Figure 11.1), the user of an object has to remember to register the object with the Unit of Work for changes. Any objects that aren’t registered won’t be written out on commit. Although this allows forgetfulness to cause trouble, it does give flexibility in allowing people to make in-memory changes that they don’t want written out. Still, I would argue that it’s going to cause far more confusion than would be worthwhile. It’s better to make an explicit copy for that purpose.
Figure 11.1. Having the caller register a changed object.
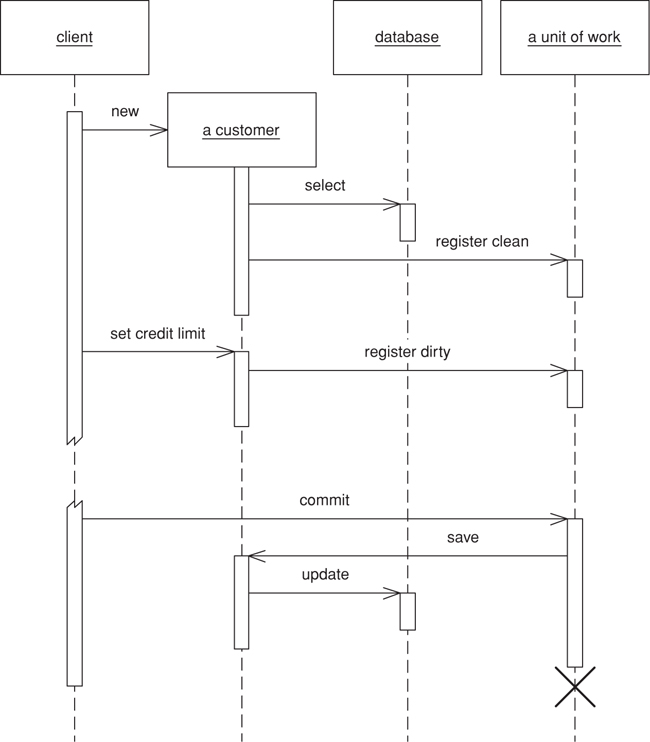
With object registration (Figure 11.2), the onus is removed from the caller. The usual trick here is to place registration methods in object methods. Loading an object from the database registers the object as clean; the setting methods register the object as dirty. For this scheme to work the Unit of Work needs either to be passed to the object or to be in a well-known place. Passing the Unit of Work around is tedious but usually no problem to have it present in some kind of session object.
Figure 11.2. Getting the receiver object to register itself.
Even object registration leaves something to remember; that is, the developer of the object has to remember to add a registration call in the right places. The consistency becomes habitual, but is still an awkward bug when missed.
This is a natural place for code generation to generate appropriate calls, but that only works when you can clearly separate generated and nongenerated code. This problem turns out to be particularly suited to aspect-oriented programming. I’ve also come across post-processing of the object files to pull this off. In this example a post-processor examined all the Java .class files, looked for the appropriate methods and inserted registration calls into the byte code. Such finicking around feels dirty, but it separates the database code from the regular code. Aspect-oriented programming will do this more cleanly with source code, and as its tools become more commonplace I expect to see this strategy being used.
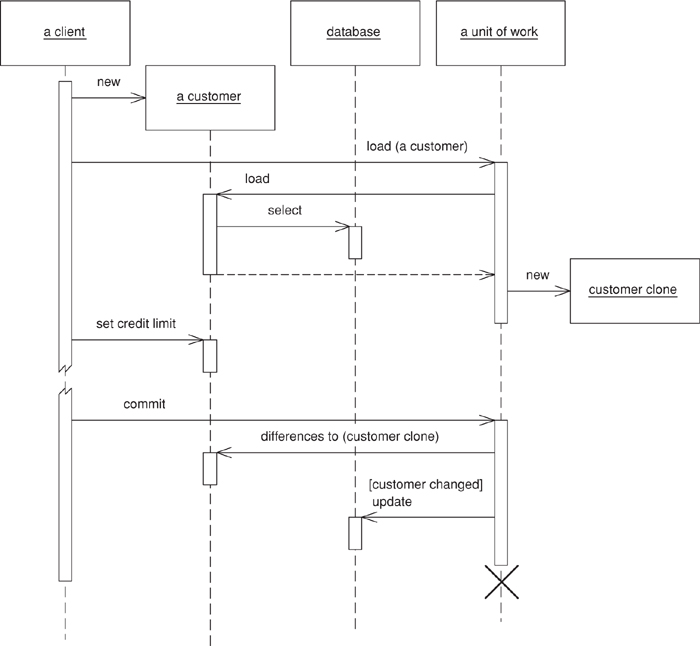
Another technique I’ve seen is unit of work controller (Figure 11.3), which the TOPLink product uses. Here the Unit of Work handles all reads from the database and registers clean objects whenever they’re read. Rather than marking objects as dirty the Unit of Work takes a copy at read time and then compares the object at commit time. Although this adds overhead to the commit process, it allows a selective update of only those fields that were actually changed; it also avoids registration calls in the domain objects. A hybrid approach is to take copies only of changed objects. This requires registration, but it supports selective update and greatly reduces the overhead of the copy if there are many more reads than updates.
Figure 11.3. Using the Unit of Work as the controller for database access.
Object creation is often a special time to consider caller registration. It’s not uncommon for people to create objects that are only supposed to be transient. A good example of this is in testing domain objects, where the tests run much faster without database writes. Caller registration can make this apparent. However, there are other solutions, such as providing a transient constructor that doesn’t register with the Unit of Work or, better still, providing a Special Case (496)Unit of Work that does nothing with a commit.
Another area where a Unit of Work can be helpful is in update order when a database uses referential integrity. Most of the time you can avoid this issue by ensuring that the database only checks referential integrity when the transaction commits rather than with each SQL call. Most databases allow this, and if available there’s no good reason not to do it. If not, the Unit of Work is the natural place to sort out the update order. In smaller systems this can be done with explicit code that contains details about which tables to write first based on the foreign key dependencies. In a larger application it’s better to use metadata to figure out which order to write to the database. How you do that is beyond the scope of this book, and it’s a common reason to use a commercial tool. If you have to do it yourself, I’m told the key to the puzzle is a topological sort.
You can use a similar technique to minimize deadlocks. If every transaction uses the same sequence of tables to edit, you greatly reduce the risk of deadlocks. The Unit of Work is an ideal place to hold a fixed sequence of table writes so that you always touch the tables in the same order.
Objects need to be able to find their current Unit of Work. A good way to do this is with a thread-scoped Registry (480). Another way is to pass the Unit of Work to objects that need it, either in method calls or when you create an object. In either case make sure that more than one thread can’t get access to a Unit of Work—there lies the way to madness.
Unit of Work makes an obvious point of handling batch updates. The idea behind a batch update is to send multiple SQL commands as a single unit so that they can be processed in a single remote call. This is particularly important when many updates, inserts, and deletes are sent in rapid succession. Different environments provide different levels of support for batch updates. JDBC has a facility that allows you to batch individual statements. If you don’t have this feature, you can mimic it by building up a string that has multiple SQL statements and then submitting as one statement. [Nilsson] describes an example of this for Microsoft platforms. However, if you do this check to see if it interferes with statement precompilation.
Unit of Work works with any transactional resource, not just databases, so you can also use it to coordinate with message queues and transaction monitors.
.NET Implementation
In .NET the Unit of Work is done by the disconnected data set. This makes it a slightly different pattern from the classical variety. Most Units of Work I’ve come across register and track changes to objects. .NET reads data from the database into a data set, which is a series of objects arranged like database tables, rows, and columns. The data set is essentially an in-memory mirror image of the result of one or more SQL queries. Each data row has the concept of a version (current, original, proposed) and a state (unchanged, added, deleted, modified), which, together with the fact that the data set mimics the database structure, makes for straightforward writing of changes to the database.
The fundamental problem that Unit of Work deals with is keeping track of the various objects you’ve manipulated so that you know which ones you need to consider to synchronize your in-memory data with the database. If you’re able to do all your work within a system transaction, the only objects you need to worry about are those you alter. Although Unit of Work is generally the best way of doing this, there are alternatives.
Perhaps the simplest alternative is to explicitly save any object whenever you alter it. The problem here is that you may get many more database calls than you want since, if you alter one object at three different points in your work, you get three calls rather than one call in its final state.
To avoid multiple database calls, you can leave all your updates to the end. To do this you need to keep track of all the objects that have changed. You can use variables in your code for this, but they soon become unmanageable once you have more than a few. Variables often work fine with a Transaction Script (110), but they can be very difficult with a Domain Model (116).
Rather than keep objects in variables you can give each object a dirty flag that you set when the object changes. Then you need to find all the dirty objects at the end of your transaction and write them out. The value of this technique hinges on how easy it is to find the dirty objects. If all of them are in a single hierarchy, then you can traverse the hierarchy and write out any that have been changed. However, a more general object network, such as a Domain Model (116), is harder to traverse.
The great strength of Unit of Work is that it keeps all this information in one place. Once you have it working for you, you don’t have to remember to do much in order to keep track of your changes. Also, Unit of Work is a firm platform for more complicated situations, such as handling business transactions that span several system transactions using Optimistic Offline Lock (416) and Pessimistic Offline Lock (426).
Here’s a Unit of Work that can track all changes for a given business transaction and then commit them to the database when instructed to do so. Our domain layer has a Layer Supertype (475), DomainObject, with which the Unit of Work will interact. To store the change set we use three lists: new, dirty, and removed domain objects.
class UnitOfWork...
private List newObjects = new ArrayList();
private List dirtyObjects = new ArrayList();
private List removedObjects = new ArrayList();
The registration methods maintain the state of these lists. They must perform basic assertions such as checking that an ID isn’t null or that a dirty object isn’t being registered as new.
class UnitOfWork...
public void registerNew(DomainObject obj) {
Assert.notNull("id not null", obj.getId());
Assert.isTrue("object not dirty", !dirtyObjects.contains(obj));
Assert.isTrue("object not removed", !removedObjects.contains(obj));
Assert.isTrue("object not already registered new", !newObjects.contains(obj));
newObjects.add(obj);
}
public void registerDirty(DomainObject obj) {
Assert.notNull("id not null", obj.getId());
Assert.isTrue("object not removed", !removedObjects.contains(obj));
if (!dirtyObjects.contains(obj) && !newObjects.contains(obj)) {
dirtyObjects.add(obj);
}
}
public void registerRemoved(DomainObject obj) {
Assert.notNull("id not null", obj.getId());
if (newObjects.remove(obj)) return;
dirtyObjects.remove(obj);
if (!removedObjects.contains(obj)) {
removedObjects.add(obj);
}
}
public void registerClean(DomainObject obj) {
Assert.notNull("id not null", obj.getId());
}
Notice that registerClean() doesn’t do anything here. A common practice is to place an Identity Map (195) within a Unit of Work. An Identity Map (195) is necessary almost any time you store domain object state in memory because multiple copies of the same object would result in undefined behavior. Were an Identity Map (195) in place, registerClean() would put the registered object in it. Likewise registerNew() would put a new object in the map and registerRemoved() would remove a deleted object from the map. Without the Identity Map (195) you have the option of not including registerClean() in your Unit of Work. I’ve seen implementations of this method that remove changed objects from the dirty list, but partially rolling back changes is always tricky. Be careful when reversing any state in the change set.
commit() will locate the Data Mapper (165) for each object and invoke the appropriate mapping method. updateDirty() and deleteRemoved() aren’t shown, but they would behave like insertNew(), which is as expected.
class UnitOfWork...
public void commit() {
insertNew();
updateDirty();
deleteRemoved();
}
private void insertNew() {
for (Iterator objects = newObjects.iterator(); objects.hasNext();) {
DomainObject obj = (DomainObject) objects.next();
MapperRegistry.getMapper(obj.getClass()).insert(obj);
}
}
Not included in this Unit of Work is the tracking of any objects we’ve read and want to check for inconsistent read errors upon commit. This is addressed in Optimistic Offline Lock (416).
Next we need to facilitate object registration. First each domain object needs to find the Unit of Work serving the current business transaction. Since that Unit of Work will be needed by the entire domain model, passing it around as a parameter is probably unreasonable. As each business transaction executes within a single thread we can associate the Unit of Work with the currently executing thread using the java.lang. ThreadLocal class. Keeping things simple, we’ll add this functionality by using static methods on our Unit of Work class. If we already have some sort of session object associated with the business transaction execution thread we should place the current Unit of Work on that session object rather than add the management overhead of another thread mapping. Besides, the Unit of Work logically belongs to the session.
class UnitOfWork...
private static ThreadLocal current = new ThreadLocal();
public static void newCurrent() {
setCurrent(new UnitOfWork());
}
public static void setCurrent(UnitOfWork uow) {
current.set(uow);
}
public static UnitOfWork getCurrent() {
return (UnitOfWork) current.get();
}
Now we can give our abstract domain object the marking methods to register itself with the current Unit of Work.
class DomainObject...
protected void markNew() {
UnitOfWork.getCurrent().registerNew(this);
}
protected void markClean() {
UnitOfWork.getCurrent().registerClean(this);
}
protected void markDirty() {
UnitOfWork.getCurrent().registerDirty(this);
}
protected void markRemoved() {
UnitOfWork.getCurrent().registerRemoved(this);
}
Concrete domain objects need to remember to mark themselves new and dirty where appropriate.
class Album...
public static Album create(String name) {
Album obj = new Album(IdGenerator.nextId(), name);
obj.markNew();
return obj;
}
public void setTitle(String title) {
this.title = title;
markDirty();
}
Not shown is that the registration of removed objects can be handled by a remove() method on the abstract domain object. Also, and if you’ve implemented registerClean() your Data Mappers (165) will need to register any newly loaded object as clean.
The final piece is to register and commit the Unit of Work where appropriate. This can be done either explicitly or implicitly. Here’s what explicit Unit of Work management looks like:
class EditAlbumScript...
public static void updateTitle(Long albumId, String title) {
UnitOfWork.newCurrent();
Mapper mapper = MapperRegistry.getMapper(Album.class);
Album album = (Album) mapper.find(albumId);
album.setTitle(title);
UnitOfWork.getCurrent().commit();
}
Beyond the simplest of applications, implicit Unit of Work management is more appropriate as it avoids repetitive, tedious coding. Here’s a servlet Layer Supertype (475) that registers and commits the Unit of Work for its concrete subtypes. Subtypes will implement handleGet() rather than override doGet(). Any code executing within handleGet() will have a Unit of Work with which to work.
class UnitOfWorkServlet...
final protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
try {
UnitOfWork.newCurrent();
handleGet(request, response);
UnitOfWork.getCurrent().commit();
} finally {
UnitOfWork.setCurrent(null);
}
}
abstract void handleGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException;
The above servlet example is obviously a bit simplistic, in that it skips system transaction control. If you were using Front Controller (344), you would be more likely to wrap Unit of Work management around your commands rather than doGet(). Similar wrapping can be done with just about any execution context.
Ensures that each object gets loaded only once by keeping every loaded object in a map. Looks up objects using the map when referring to them.
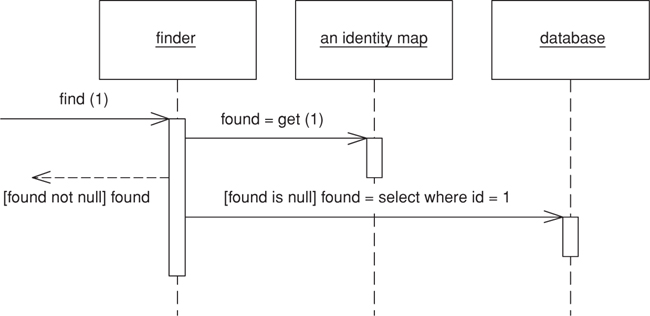
An old proverb says that a man with two watches never knows what time it is. If two watches are confusing, you can get in an even bigger mess with loading objects from a database. If you aren’t careful you can load the data from the same database record into two different objects. Then, when you update them both you’ll have an interesting time writing the changes out to the database correctly.
Related to this is an obvious performance problem. If you load the same data more than once you’re incurring an expensive cost in remote calls. Thus, not loading the same data twice doesn’t just help correctness, but can also speed up your application.
An Identity Map keeps a record of all objects that have been read from the database in a single business transaction. Whenever you want an object, you check the Identity Map first to see if you already have it.
The basic idea behind the Identity Map is to have a series of maps containing objects that have been pulled from the database. In a simple case, with an isomorphic schema, you’ll have one map per database table. When you load an object from the database, you first check the map. If there’s an object in it that corresponds to the one you’re loading, you return it. If not, you go to the database, putting the objects into the map for future reference as you load them.
There are a number of implementation choices to worry about. Also, since Identity Maps interact with concurrency management, so you should consider Optimistic Offline Lock (416) as well.
The first thing to consider is the key for the map. The obvious choice is the primary key of the corresponding database table. This works well if the key is a single column and immutable. A surrogate primary key fits in very well with this approach because you can use it as the key in the map. The key will usually be a simple data type so the comparison behavior will work nicely.
You have to choose whether to make the Identity Map explicit or generic. An explicit Identity Map is accessed with distinct methods for each kind of object you need: such as findPerson(1). A generic map uses a single method for all kinds of objects, with perhaps a parameter to indicate which kind of object you need, such as find("Person", 1). The obvious advantage is that you can support a generic map with a generic and reusable object. It’s easy to construct a reusable Registry (480) that work for all kinds of objects and doesn’t need updating when you add a new map.
However, I prefer an explicit Identity Map. For a start this gives you compile-time checking in a strongly typed language. But more than that, it has all the other advantages of an explicit interface: it’s easier to see what maps are available and what they’re called. It does mean adding a method each time you add a new map, but that is a small overhead for the virtue of explicitness.
Your type of key affects the choice. You can only use a generic map if all your objects have the same type of key. This is a good argument for encapsulating different kinds of database key behind a single key object. (See Identity Field (216) for detail.)
Here the decision varies between one map per class and one map for the whole session. A single map for the session works only if you have database-unique keys (see the discussion in Identity Field (216) for the trade-offs on that.) Once you have one Identity Map, the benefit is that you have only one place to go and no awkward decisions about inheritance.
If you have multiple maps, the obvious route is one map per class or per table, which works well if your database schema and object models are the same. If they look different, it’s usually easier to base the maps on your objects rather than on your tables, as the objects shouldn’t really know about the intricacies of the mapping.
Inheritance rears an ugly head here. If you have cars as a subtype of vehicle, do you have one map or separate maps? Keeping them separate can make polymorphic references much more awkward, since any lookup needs to know to look in all maps. As a result I prefer to use a single map for each inheritance tree, but that means that you should also make your keys unique across inheritance trees, which can be awkward if you use Concrete Table Inheritance (293).
An advantage of a single map is that you don’t have to add new ones when you add database tables. However, tying your maps to your Data Mappers (165) (see below) won’t be any extra burden.
Identity Maps need to be somewhere where they’re easy to find. They’re also tied to the process context you’re working in. You need to ensure that each session gets it’s own instance that’s isolated from any other session’s instance. Thus, you need to put the Identity Map on a session-specific object. If you’re using Unit of Work (184) that’s by far the best place for the Identity Maps since the Unit of Work (184) is the main place for keeping track of data coming in or out of the database. If you don’t have a Unit of Work (184), the best bet is a Registry (480) that’s tied to the session.
As I’ve implied here, you usually see a single Identity Map for a session; otherwise, you need to provide transactional protection for your map, which is more work than any sane developer wants to do. However, there are a couple of exceptions. The biggest one is to use an object database as a transactional cache, even if you use a relational database for record data. While I haven’t seen any independent performance studies, the possibilities suggest that it’s worth taking a look at. Many people I respect are big fans of a transactional cache as a way to improve performance.
The other exception is for objects that are read-only in all cases. If an object can never be modified, there’s no need to worry about it being shared across sessions. In performance-intensive systems it can be very beneficial to load in all read-only data once and have it available to the whole process. In this case you have your read-only Identity Maps held in a process context and your updatable Identity Maps in a session context. This also applies to objects that aren’t completely read-only but are updated so rarely that you don’t mind flushing the process-wide Identity Map and potentially bouncing the server when it happens.
Even if you’re inclined to have only one Identity Map you can split it in two along read-only and updatable lines. You can avoid clients having to know which is which by providing an interface that checks both maps.
In general you use an Identity Map to manage any object brought from a database and modified. The key reason is that you don’t want a situation where two in-memory objects correspond to a single database record—you might modify the two records inconsistently and thus confuse the database mapping.
Another value in Identity Map is that it acts as a cache for database reads, which means that you can avoid going to the database each time you need some data.
You may not need an Identity Map for immutable objects. If you can’t change an object, then you don’t have to worry about modification anomalies. Since Value Objects (486) are immutable, it follows that you don’t need Identity Map for them. Still, Identity Map has advantages here, the most important of which is the performance advantages of the cache, another is that it helps to prevent the use of the wrong form of equality test, a problem prevalent in Java, where you can’t override ==.
You don’t need an Identity Map for a Dependent Mapping (262). Since dependent objects have their persistence controlled by their parent, there’s no need for a map to maintain identity. However, although you don’t need a map, you may want to provide one if you need to access the object through a database key. In this case the map is merely an index, so it’s arguable whether it really counts as a map at all.
Identity Map helps avoid update conflicts within a single session, but it doesn’t do anything to handle conflicts that cross sessions. This is a complex problem that we discuss further in Optimistic Offline Lock (416) and Pessimistic Offline Lock (426).
For each Identity Map we have a map field and accessors.
private Map people = new HashMap();
public static void addPerson(Person arg) {
soleInstance.people.put(arg.getID(), arg);
}
public static Person getPerson(Long key) {
return (Person) soleInstance.people.get(key);
}
public static Person getPerson(long key) {
return getPerson(new Long(key));
}
One of the annoyances of Java is the fact that long isn’t an object so you can’t use it as an index for a map. This isn’t as annoying as it could have been since we don’t actually do any arithmetic on the index. The one place where it really hurts, though, is when you want to retrieve an object with a literal. You hardly ever need to do that in production code, but you often do in test code, so I’ve included a getting method that takes a long to make testing easier.
An object that doesn’t contain all of the data you need but knows how to get it.
For loading data from a database into memory it’s handy to design things so that as you load an object of interest you also load the objects that are related to it. This makes loading easier on the developer using the object, who otherwise has to load all the objects he needs explicitly.
However, if you take this to its logical conclusion, you reach the point where loading one object can have the effect of loading a huge number of related objects—something that hurts performance when only a few of the objects are actually needed.
A Lazy Load interrupts this loading process for the moment, leaving a marker in the object structure so that if the data is needed it can be loaded only when it is used. As many people know, if you’re lazy about doing things you’ll win when it turns out you don’t need to do them at all.
There are four main ways you can implement Lazy Load: lazy initialization, virtual proxy, value holder, and ghost.
Lazy initialization [Beck Patterns] is the simplest approach. The basic idea is that every access to the field checks first to see if it’s null. If so, it calculates the value of the field before returning the field. To make this work you have to ensure that the field is self-encapsulated, meaning that all access to the field, even from within the class, is done through a getting method.
Using a null to signal a field that hasn’t been loaded yet works well, unless null is a legal value field value. In this case you need something else to signal that the field hasn’t been loaded, or you need to use a Special Case (496) for the null value.
Using lazy initialization is simple, but it does tend to force a dependency between the object and the database. For that reason it works best for Active Record (160), Table Data Gateway (144), and Row Data Gateway (152). If you’re using Data Mapper (165), you’ll need an additional layer of indirection, which you can obtain by using a virtual proxy [Gang of Four]. A virtual proxy is an object that looks like the object that should be in the field, but doesn’t actually contain anything. Only when one of its methods is called does it load the correct object from the database.
The good thing about a virtual proxy is that it looks exactly like the object that’s supposed to be there. The bad thing is that it isn’t that object, so you can easily run into a nasty identity problem. Furthermore you can have more than one virtual proxy for the same real object. All of these proxies will have different object identities, yet they represent the same conceptual object. At the very least you have to override the equality method and remember to use it instead of an identity method. Without that, and discipline, you’ll run into some very hard-to-track bugs.
In some environments another problem is that you end up having to create lots of virtual proxies, one for each class you’re proxying. You can usually avoid this in dynamically typed languages, but in statically typed languages things often get messy. Even when the platform provides handy facilities, such as Java’s proxies, other inconveniences can come up.
These problem don’t hit you if you only use virtual proxies for collections classes, such as lists. Since collections are Value Objects (486), their identity doesn’t matter. Additionally you only have a few collection classes to write virtual collections for.
With domain classes you can get around these problems by using a value holder. This concept, which I first came across in Smalltalk, is an object that wraps some other object. To get the underlying object you ask the value holder for its value, but only on the first access does it pull the data from the database. The disadvantages of the value holder are that the class needs to know that it’s present and that you lose the explicitness of strong typing. You can avoid identity problems by ensuring that the value holder is never passed out beyond its owning class.
A ghost is the real object in a partial state. When you load the object from the database it contains just its ID. Whenever you try to access a field it loads its full state. Think of a ghost as an object, where every field is lazy-initialized in one fell swoop, or as a virtual proxy, where the object is its own virtual proxy. Of course, there’s no need to load all the data in one go; you may group it in groups that are commonly used together. If you use a ghost, you can put it immediately in its Identity Map (195). This way you maintain identity and avoid all problems due to cyclic references when reading in data.
A virtual proxy/ghost doesn’t need to be completely devoid of data. If you have some data that’s quick to get hold of and commonly used, it may make sense to load it when you load the proxy or ghost. (This is sometimes referred to as a “light object.”)
Inheritance often poses a problem with Lazy Load. If you’re going to use ghosts, you’ll need to know what type of ghost to create, which you often can’t tell without loading the thing properly. Virtual proxies can suffer from the same problem in statically typed languages.
Another danger with Lazy Load is that it can easily cause more database accesses than you need. A good example of this ripple loading is if you fill a collection with Lazy Loads and then look at them one at a time. This will cause you to go to the database once for each object instead of reading them all in at once. I’ve seen ripple loading cripple the performance of an application. One way to avoid it is never to have a collection of Lazy Loads but, rather make the collection itself a Lazy Load and, when you load it, load all the contents. The limitation of this tactic is when the collection is very large, such as all the IP addresses in the world. These aren’t usually linked through associations in the object model, so that doesn’t happen very often, but when it does you’ll need a Value List Handler [Alur et al.].
Lazy Load is a good candidate for aspect-oriented programming. You can put Lazy Load behavior into a separate aspect, which allows you to change the lazy load strategy separately as well as freeing the domain developers from having to deal with lazy loading issues. I’ve also seen a project post-process Java bytecode to implement Lazy Load in a transparent way.
Often you’ll run into situations where different use cases work best with different varieties of laziness. Some need one subset of the object graph; others need another subset. For maximum efficiency you want to load the right subgraph for the right use case.
The way to deal with this is to have separate database interaction objects for the different use cases. Thus, if you use Data Mapper (165), you may have two order mapper objects: one that loads the line items immediately and one that loads them lazily. The application code chooses the appropriate mapper depending on the use case. A variation on this is to have the same basic loader object but defer to a strategy object to decide the loading pattern. This is a bit more sophisticated, but it can be a better way to factor behavior.
In theory you might want a range of different degrees of laziness, but in practice you really need only two: a complete load and enough of a load for identification purposes in a list. Adding more usually adds more complexity than is worthwhile.
Deciding when to use Lazy Load is all about deciding how much you want to pull back from the database as you load an object, and how many database calls that will require. It’s usually pointless to use Lazy Load on a field that’s stored in the same row as the rest of the object, because most of the time it doesn’t cost any more to bring back extra data in a call, even if the data field is quite large—such as a Serialized LOB (272). That means it’s usually only worth considering Lazy Load if the field requires an extra database call to access.
In performance terms it’s about deciding when you want to take the hit of bringing back the data. Often it’s a good idea to bring everything you’ll need in one call so you have it in place, particularly if it corresponds to a single interaction with a UI. The best time to use Lazy Load is when it involves an extra call and the data you’re calling isn’t used when the main object is used.
Adding Lazy Load does add a little complexity to the program, so my preference is not to use it unless I actively think I’ll need it.
The essence of lazy initialization is code like this:
class Supplier...
public List getProducts() {
if (products == null) products = Product.findForSupplier(getID());
return products;
}
In this way the first access of the products field causes the data to be loaded from the database.
The key to the virtual proxy is providing a class that looks like the actual class you normally use but that actually holds a simple wrapper around the real class. Thus, a list of products for a supplier would be held with a regular list field.
class SupplierVL...
private List products;
The most complicated thing about producing a list proxy like this is setting it up so that you can provide an underlying list that’s created only when it’s accessed. To do this we have to pass the code that’s needed to create the list into the virtual list when it’s instantiated. The best way to do this in Java is to define an interface for the loading behavior.
public interface VirtualListLoader {
List load();
}
Then we can instantiate the virtual list with a loader that calls the appropriate mapper method.
class SupplierMapper...
public static class ProductLoader implements VirtualListLoader {
private Long id;
public ProductLoader(Long id) {
this.id = id;
}
public List load() {
return ProductMapper.create().findForSupplier(id);
}
}
During the load method we assign the product loader to the list field.
class SupplierMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
String nameArg = rs.getString(2);
SupplierVL result = new SupplierVL(id, nameArg);
result.setProducts(new VirtualList(new ProductLoader(id)));
return result;
}
The virtual list’s source list is self-encapsulated and evaluates the loader on first reference.
class VirtualList...
private List source;
private VirtualListLoader loader;
public VirtualList(VirtualListLoader loader) {
this.loader = loader;
}
private List getSource() {
if (source == null) source = loader.load();
return source;
}
The regular list methods to delegate are then implemented to the source list.
class VirtualList...
public int size() {
return getSource().size();
}
public boolean isEmpty() {
return getSource().isEmpty();
}
// ... and so on for rest of list methods
This way the domain class knows nothing about how the mapper class does the Lazy Load. Indeed, the domain class isn’t even aware that there is a Lazy Load.
A value holder can be used as a generic Lazy Load. In this case the domain type is aware that something is afoot, since the product field is typed as a value holder. This fact can be hidden from clients of the supplier by the getting method.
class SupplierVH...
private ValueHolder products;
public List getProducts() {
return (List) products.getValue();
}
The value holder itself does the Lazy Load behavior. It needs to be passed the necessary code to load its value when it’s accessed. We can do this by defining a loader interface.
class ValueHolder...
private Object value;
private ValueLoader loader;
public ValueHolder(ValueLoader loader) {
this.loader = loader;
}
public Object getValue() {
if (value == null) value = loader.load();
return value;
}
public interface ValueLoader {
Object load();
}
A mapper can set up the value holder by creating an implementation of the loader and putting it into the supplier object.
class SupplierMapper...
protected DomainObject doLoad(Long id, ResultSet rs) throws SQLException {
String nameArg = rs.getString(2);
SupplierVH result = new SupplierVH(id, nameArg);
result.setProducts(new ValueHolder(new ProductLoader(id)));
return result;
}
public static class ProductLoader implements ValueLoader {
private Long id;
public ProductLoader(Long id) {
this.id = id;
}
public Object load() {
return ProductMapper.create().findForSupplier(id);
}
}
Much of the logic for making objects ghosts can be built into Layer Supertypes (475). As a consequence, if you use ghosts you tend to see them used everywhere. I’ll begin our exploration of ghosts by looking at the domain object Layer Supertype (475). Each domain object knows if it’s a ghost or not.
class Domain Object...
LoadStatus Status;
public DomainObject (long key) {
this.Key = key;
}
public Boolean IsGhost {
get {return Status == LoadStatus.GHOST;}
}
public Boolean IsLoaded {
get {return Status == LoadStatus.LOADED;}
}
public void MarkLoading() {
Debug.Assert(IsGhost);
Status = LoadStatus.LOADING;
}
public void MarkLoaded() {
Debug.Assert(Status == LoadStatus.LOADING);
Status = LoadStatus.LOADED;
}
enum LoadStatus {GHOST, LOADING, LOADED};
Domain objects can be in three states: ghost, loading, and loaded. I like to wrap status information with read-only properties and explicit status change methods.
The most intrusive element of ghosts is that every accessor needs to be modified so that it will trigger a load if the object actually is a ghost.
class Employee...
public String Name {
get {
Load();
return _name;
}
set {
Load();
_name = value;
}
}
String _name;
class Domain Object...
protected void Load() {
if (IsGhost)
DataSource.Load(this);
}
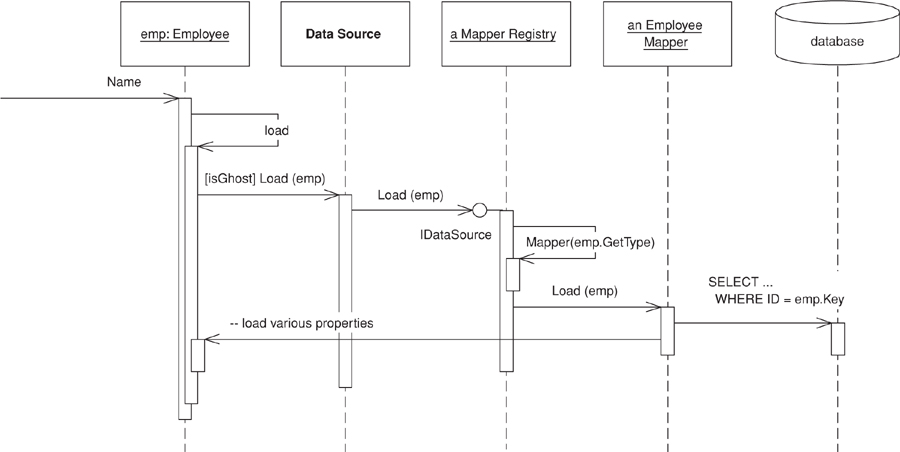
Such a need, which is annoying to remember, is an ideal target for aspect-oriented programming for post-processing the bytecode.
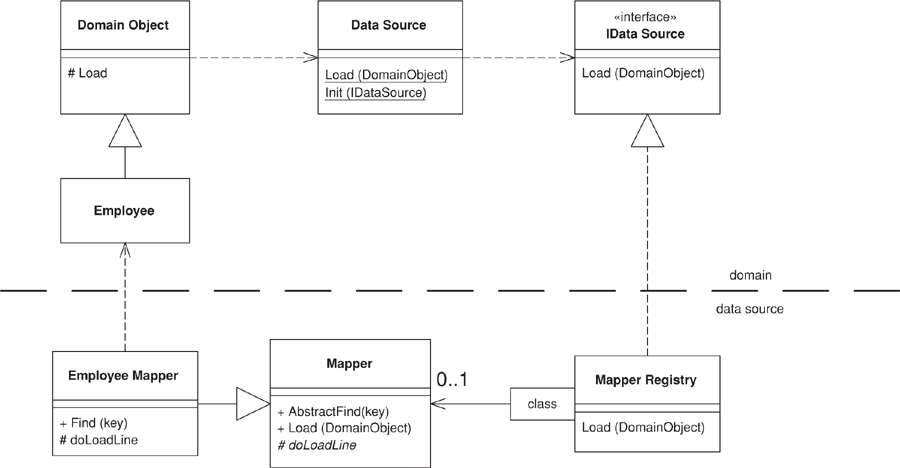
In order for the loading to work, the domain object needs to call the correct mapper. However, my visibility rules dictate that the domain code may not see the mapper code. To avoid the dependency, I need to use an interesting combination of Registry (480) and Separated Interface (476) (Figure 11.4). I define a Registry (480) for the domain for data source operations.
class DataSource...
public static void Load (DomainObject obj) {
instance.Load(obj);
}
Figure 11.4. Classes involved in loading a ghost.
The instance of the data source is defined using an interface.
class DataSource...
public interface IDataSource {
void Load (DomainObject obj);
}
A registry of mappers, defined in the data source layer, implements the data source interface. In this case I’ve put the mappers in a dictionary indexed by domain type. The load method finds the correct mapper and tells it to load the appropriate domain object.
class MapperRegistry : IDataSource...
public void Load (DomainObject obj) {
Mapper(obj.GetType()).Load (obj);
}
public static Mapper Mapper(Type type) {
return (Mapper) instance.mappers[type];
}
IDictionary mappers = new Hashtable();
The preceding code shows how the domain objects interact with the data source. The data source logic uses Data Mappers (165). The update logic on the mappers is the same as in the case with no ghosts—the interesting behavior for this example lies in the finding and loading behavior.
Concrete mapper classes have their own find methods that use an abstract method and downcast the result.
class EmployeeMapper...
public Employee Find (long key) {
return (Employee) AbstractFind(key);
}
class Mapper...
public DomainObject AbstractFind (long key) {
DomainObject result;
result = (DomainObject) loadedMap[key];
if (result == null) {
result = CreateGhost(key);
loadedMap.Add(key, result);
}
return result;
}
IDictionary loadedMap = new Hashtable();
public abstract DomainObject CreateGhost(long key);
class EmployeeMapper...
public override DomainObject CreateGhost(long key) {
return new Employee(key);
}
As you can see, the find method returns an object in its ghost state. The actual data does not come from the database until the load is triggered by accessing a property on the domain object.
class Mapper...
public void Load (DomainObject obj) {
if (! obj.IsGhost) return;
IDbCommand comm = new OleDbCommand(findStatement(), DB.connection);
comm.Parameters.Add(new OleDbParameter("key",obj.Key));
IDataReader reader = comm.ExecuteReader();
reader.Read();
LoadLine (reader, obj);
reader.Close();
}
protected abstract String findStatement();
public void LoadLine (IDataReader reader, DomainObject obj) {
if (obj.IsGhost) {
obj.MarkLoading();
doLoadLine (reader, obj);
obj.MarkLoaded();
}
}
protected abstract void doLoadLine (IDataReader reader, DomainObject obj);
As is common with these examples, the Layer Supertype (475) handles all of the abstract behavior and then calls an abstract method for a particular subclass to play its part. For this example I’ve used a data reader, a cursor-based approach that’s the more common for the various platforms at the moment. I’ll leave it to you to extend this to a data set, which would actually be more suitable for most cases in .NET.
For this employee object, I’ll show three kinds of property: a name that’s a simple value, a department that’s a reference to another object, and a list of timesheet records that shows the case of a collection. All are loaded together in the subclass’s implementation of the hook method.
class EmployeeMapper...
protected override void doLoadLine (IDataReader reader, DomainObject obj) {
Employee employee = (Employee) obj;
employee.Name = (String) reader["name"];
DepartmentMapper depMapper =
(DepartmentMapper) MapperRegistry.Mapper(typeof(Department));
employee.Department = depMapper.Find((int) reader["departmentID"]);
loadTimeRecords(employee);
}
The name’s value is loaded simply by reading the appropriate column from the data reader’s current cursor. The department is read by using the find method on the department’s mapper object. This will end up setting the property to a ghost of the department; the department’s data will only be read when the department object itself is accessed.
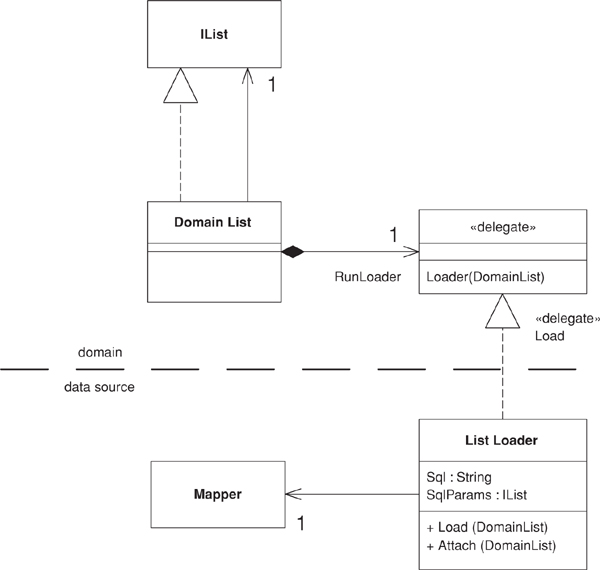
The collection is the most complicated case. To avoid ripple loading, it’s important to load all the time records in a single query. For this we need a special list implementation that acts as a ghost list. This list is just a thin wrapper around a real list object, to which all the real behavior is just delegated. The only thing the ghost does is ensure that any accesses to the real list triggers a load.
class DomainList...
IList data {
get {
Load();
return _data;
}
set {_data = value;}
}
IList _data = new ArrayList();
public int Count {
get {return data.Count;}
}
The domain list class is used by domain objects and is part of the domain layer. The actual loading needs access to SQL commands, so I use a delegate to define a loading function than can be supplied by the mapping layer.
class DomainList...
public void Load () {
if (IsGhost) {
MarkLoading();
RunLoader(this);
MarkLoaded();
}
}
public delegate void Loader(DomainList list);
public Loader RunLoader;
Think of a delegate as a special variety of Separated Interface (476) for a single function. Indeed, declaring an interface with a single function in it is a reasonable alternative way of doing this.
Figure 11.5. The load sequence for a ghost.
Figure 11.6. Classes for a ghost list. As yet there’s no accepted standard for showing delegates in UML models. This is my current approach.
The loader itself has properties to specify the SQL for the load and mapper to use for mapping the time records. The employee’s mapper sets up the loader when it loads the employee object.
class EmployeeMapper...
void loadTimeRecords(Employee employee) {
ListLoader loader = new ListLoader();
loader.Sql = TimeRecordMapper.FIND_FOR_EMPLOYEE_SQL;
loader.SqlParams.Add(employee.Key);
loader.Mapper = MapperRegistry.Mapper(typeof(TimeRecord));
loader.Attach((DomainList) employee.TimeRecords);
}
class ListLoader...
public String Sql;
public IList SqlParams = new ArrayList();
public Mapper Mapper;
Since the syntax for the delegate assignment is a bit complicated, I’ve given the loader an attach method.
class ListLoader...
public void Attach (DomainList list) {
list.RunLoader = new DomainList.Loader(Load);
}
When the employee is loaded, the time records collection stays in a ghost state until one of the access methods fires to trigger the loader. At this point the loader executes the query to fill the list.
class ListLoader...
public void Load (DomainList list) {
list.IsLoaded = true;
IDbCommand comm = new OleDbCommand(Sql, DB.connection);
foreach (Object param in SqlParams)
comm.Parameters.Add(new OleDbParameter(param.ToString(),param));
IDataReader reader = comm.ExecuteReader();
while (reader.Read()) {
DomainObject obj = GhostForLine(reader);
Mapper.LoadLine(reader, obj);
list.Add (obj);
}
reader.Close();
}
private DomainObject GhostForLine(IDataReader reader) {
return Mapper.AbstractFind((System.Int32)reader[Mapper.KeyColumnName]);
}
Using ghost lists like this is important to reduce ripple loading. It doesn’t completely eliminate it, as there are other cases where it appears. In this example, a more sophisticated mapping could load the department’s data in a single query with the employee. However, always loading all the elements in a collection together helps eliminate the worst cases.