In organizing domain logic I’ve separated it into three primary patterns: Transaction Script (110), Domain Model (116), and Table Module (125).
The simplest approach to storing domain logic is the Transaction Script (110). A Transaction Script (110) is essentially a procedure that takes the input from the presentation, processes it with validations and calculations, stores data in the database, and invokes any operations from other systems. It then replies with more data to the presentation, perhaps doing more calculation to help organize and format the reply. The fundamental organization is of a single procedure for each action that a user might want to do. Hence, we can think of this pattern as being a script for an action, or business transaction. It doesn’t have to be a single inline procedure of code. Pieces get separated into subroutines, and these subroutines can be shared between different Transaction Scripts (110). However, the driving force is still that of a procedure for each action, so a retailing system might have Transaction Scripts (110) for checkout, for adding something to the shopping cart, for displaying delivery status, and so on.
A Transaction Script (110) offers several advantages:
• It’s a simple procedural model that most developers understand.
• It works well with a simple data source layer using Row Data Gateway (152) or Table Data Gateway (144).
• It’s obvious how to set the transaction boundaries: Start with opening a transaction and end with closing it. It’s easy for tools to do this behind the scenes.
Sadly, there are also plenty of disadvantages, which tend to appear as the complexity of the domain logic increases. Often there will be duplicated code as several transactions need to do similar things. Some of this can be dealt with by factoring out common subroutines, but even so much of the duplication is tricky to remove and harder to spot. The resulting application can end up being quite a tangled web of routines without a clear structure.
Of course, complex logic is where objects come in, and the object-oriented way to handle this problem is with a Domain Model (116). With a Domain Model (116) we build a model of our domain which, at least on a first approximation, is organized primarily around the nouns in the domain. Thus, a leasing system would have classes for lease, asset, and so forth. The logic for handling validations and calculations would be placed into this domain model, so shipment object might contain the logic to calculate the shipping charge for a delivery. There might still be routines for calculating a bill, but such a procedure would quickly delegate to a Domain Model (116) method.
Using a Domain Model (116) as opposed to a Transaction Script (110) is the essence of the paradigm shift that object-oriented people talk about so much. Rather than one routine having all the logic for a user action, each object takes a part of the logic that’s relevant to it. If you’re not used to a Domain Model (116), learning to work with one can be very frustrating as you rush from object to object trying to find where the behavior is.
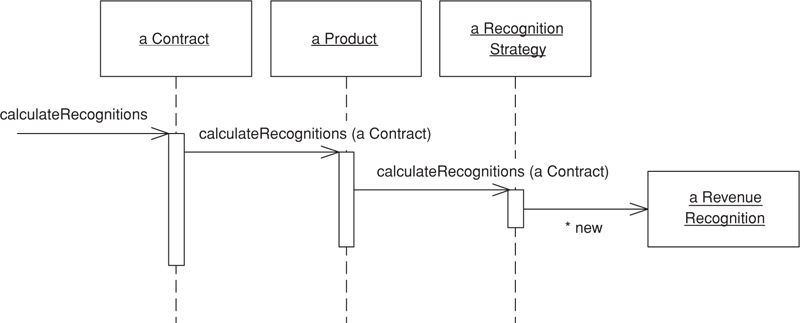
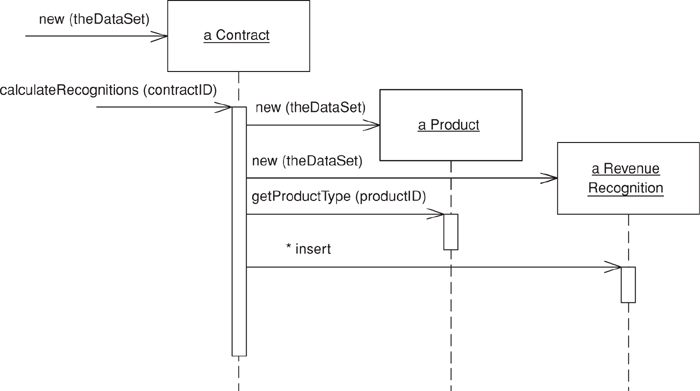
It’s hard to capture the essence of the difference between the two patterns with a simple example, but in the discussions of the patterns I’ve tried to do that by building a simple piece of domain logic both ways. The easiest way to see the difference is to look at sequence diagrams for the two approaches (Figures 2.1 and 2.2). The essential problem is that different kinds of product have different algorithms for recognizing revenue on a given contract (see Chapter 9, page 109, for more background). The calculation method has to determine what kind of product a given contract is for, apply the correct algorithm, and then create revenue recognition objects to capture the results of the calculation. (For simplicity I’m ignoring the database interaction issues.)
Figure 2.1. A Transaction Script’s (110) way of calculating revenue recognitions.
Figure 2.2. A Domain Model’s (116) way of calculating revenue recognitions.
In Figure 2.1, Transaction Script’s (110) method does all the work. The underlying objects are just Table Data Gateways (144), and all they do is pass data to the transaction script.
In contrast, Figure 2.2 shows multiple objects, each forwarding part of the behavior to another until a strategy object creates the results.
The value of a Domain Model (116) lies in the fact that once you’ve gotten used to things, there are many techniques that allow you to handle increasingly complex logic in a well-organized way. As we get more and more algorithms for calculating revenue recognition, we can add these by adding new recognition strategy objects. With Transaction Script (110) we’re adding more conditions to the conditional logic of the script. Once your mind is as warped to objects as mine is, you’ll find you prefer a Domain Model (116) even in fairly simple cases.
The costs of a Domain Model (116) come from the complexity of using it and the complexity of your data source layer. It takes time for people new to rich object models to get used to a rich Domain Model (116). Often developers may need to spend several months working on a project that uses this pattern before their paradigms are shifted. However, when you’re used to Domain Model (116) you’re usually infected for life and it becomes easy to work with in the future—that’s how object bigots like me are made. However, a significant minority of developers seem to be unable to make the shift.
Even once you’ve made the shift, you still have to deal with the database mapping. The richer your Domain Model (116), the more complex your mapping to a relational database (usually with Data Mapper (165)). A sophisticated data source layer is much like a fixed cost—it takes a fair amount of money (if you buy) or time (if you build) to get a good one, but once you have it you can do a lot with it.
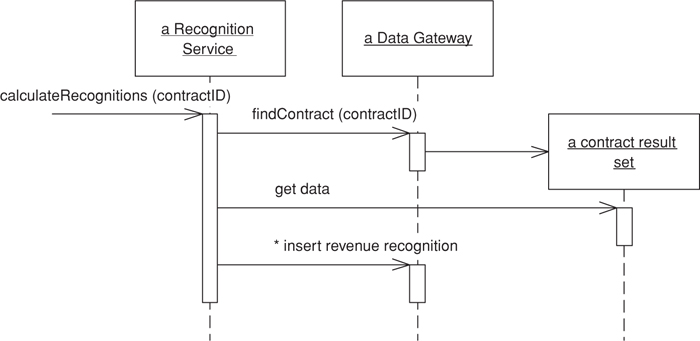
There’s a third choice for structuring domain logic, Table Module (125). At very first blush the Table Module (125) looks like a Domain Model (116) since both have classes for contracts, products, and revenue recognitions. The vital difference is that a Domain Model (116) has one instance of contract for each contract in the database whereas a Table Module (125) has only one instance. A Table Module (125) is designed to work with a Record Set (508). Thus, the client of a contract Table Module (125) will first issue queries to the database to form a Record Set (508) and will create a contract object and pass it the Record Set (508) as an argument. The client can then invoke operations on the contract to do various things (Figure 2.3). If it wants to do something to an individual contract, it must pass in an ID.
Figure 2.3. Calculating revenue recognitions with a Table Module (125).
A Table Module (125) is in many ways a middle ground between a Transaction Script (110) and a Domain Model (116). Organizing the domain logic around tables rather than straight procedures provides more structure and makes it easier to find and remove duplication. However, you can’t use a number of the techniques that a Domain Model (116) uses for finer grained structure of the logic, such as inheritance, strategies, and other OO patterns.
The biggest advantage of a Table Module (125) is how it fits into the rest of the architecture. Many GUI environments are built to work on the results of a SQL query organized in a Record Set (508). Since a Table Module (125) also works on a Record Set (508), you can easily run a query, manipulate the results in the Table Module (125), and pass the manipulated data to the GUI for display. You can also use the Table Module (125) on the way back for further validations and calculations. A number of platforms, particularly Microsoft’s COM and .NET, use this style of development.
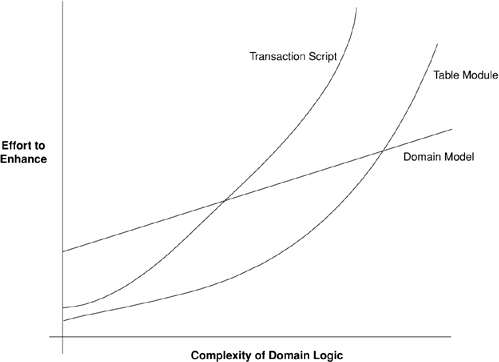
So, how do you choose between the three patterns? It’s not an easy choice, and it very much depends on how complex your domain logic is. Figure 2.4 is one of those nonscientific graphs that really irritate me in PowerPoint presentations because they have utterly unquantified axes. However, it helps to visualize my sense of how the three compare. With simple domain logic the Domain Model (116) is less attractive because the cost of understanding it and the complexity of the data source add a lot of effort to developing it that won’t be paid back. Nevertheless, as the complexity of the domain logic increases, the other approaches tend to hit a wall where adding more features becomes exponentially more difficult.
Figure 2.4. A sense of the relationships between complexity and effort for different domain logic styles.
Your problem, of course, is to figure out where on that x axis your application lies. The good news is that I can say that you should use a Domain Model (116) whenever the complexity of your domain logic is greater than 7.42. The bad news is that nobody knows how to measure the complexity of domain logic. In practice, then, all you can do is find some experienced people who can do an initial analysis of the requirements and make a judgment call.
There are some factors that alter the curves a bit. A team that’s familiar with Domain Model (116) will lower the initial cost of using this pattern. It won’t lower it to same starting point as the others because of the data source complexity. Still, the better the team is, the more I’m inclined to use a Domain Model (116).
The attractiveness of a Table Module (125) depends very much on the support for a common Record Set (508) structure in your environment. If you have an environment like .NET or Visual Studio, where lots of tools work around a Record Set (508), then that makes a Table Module (125) much more attractive. Indeed, I don’t see a reason to use Transaction Scripts (110) in a .NET environment. However, if there’s no special tooling for Record Sets (508), I wouldn’t bother with Table Module (125).
Once you’ve made it, your decision isn’t completely cast in stone, but it is more tricky to change. So it’s worth some upfront thought to decide which way to go. If you find you went the wrong way, then, if you started with Transaction Script (110), don’t hesitate to refactor toward Domain Model (116). If you started with Domain Model (116), however, going to Transaction Script (110) is usually less worthwhile unless you can simplify your data source layer.
These three patterns are not mutually exclusive choices. Indeed, it’s quite common to use Transaction Script (110) for some of the domain logic and Table Module (125) or Domain Model (116) for the rest.
A common approach in handling domain logic is to split the domain layer in two. A Service Layer (133) is placed over an underlying Domain Model (116) or Table Module (125). Usually you only get this with a Domain Model (116) or Table Module (125) since a domain layer that uses only Transaction Script (110) isn’t complex enough to warrant a separate layer. The presentation logic interacts with the domain purely through the Service Layer (133), which acts as an API for the application.
As well as providing a clear API, the Service Layer (133) is also a good spot to place such things as transaction control and security. This gives you a simple model of taking each method in the Service Layer (133) and describing its transactional and security characteristics. A separate properties file is a common choice for this, but .NET’s attributes provide a nice way of doing it directly in the code.
When you see a Service Layer (133), a key decision is how much behavior to put in it. The minimal case is to make the Service Layer (133) a facade so that all of the real behavior is in underlying objects and all the Service Layer (133) does is forward calls on the facade to lower-level objects. In that case the Service Layer (133) provides an API that’s easier to use because it’s typically oriented around use cases. It also makes a convenient point for adding transactional wrappers and security checks.
At the other extreme, most business logic is placed in Transaction Scripts (110) inside the Service Layer (133). The underlying domain objects are very simple; if it’s a Domain Model (116) it will be one-to-one with the database and you can thus use a simpler data source layer such as Active Record (160).
Midway between these alternatives is a more even mix of behavior: the controller-entity style. This name comes from a common practice influenced heavily by [Jacobson et al.]. The point here is to have logic that’s particular to a single transaction or use case placed in Transaction Scripts (110), which are commonly referred to as controllers or services. These are different controllers to the input controller in Model View Controller (330) or Application Controller (379) that we’ll meet later, so I use the term use-case controller. Behavior that’s used in more than one use case goes on the domain objects, which are called entities.
Although the controller-entity approach is a common one, it’s not one that I’ve ever liked much. The use case controllers, like any Transaction Script (110), tend to encourage duplicate code. My view is that, if you decide to use a Domain Model (116) at all, you really should go whole hog and make it dominant. The one exception to this is if you’ve started with a design that uses Transaction Script (110) with Row Data Gateway (152). Then it makes sense to move duplicated behavior to the Row Data Gateways (152), which will turn them into a simple Domain Model (116) using Active Record (160). However, I wouldn’t start that way. I would only do that to improve a design that’s showing cracks.
I’m saying not that you should never have service objects that contain business logic, but that you shouldn’t necessarily make a fixed layer of them. Procedural service objects can sometimes be a very useful way to factor logic, but I tend to use them as needed rather than as an architectural layer.
My preference is thus to have the thinnest Service Layer (133) you can, if you even need one. My usual approach is to assume that I don’t need one and only add it if it seems that the application needs it. However, I know many good designers who always use a Service Layer (133) with a fair bit of logic, so feel free to ignore me on this one. Randy Stafford has had a lot of success with a rich Service Layer (133), which is why I asked him to write the Service Layer (133) pattern for this book.