9.3 Formal Models of Secure Systems
Protection matrices, such as that of Fig. 9-4, are not static. They frequently change as new objects are created, old objects are destroyed, and owners decide to increase or restrict the set of users for their objects. A considerable amount of attention has been paid to modeling protection systems in which the protection matrix is constantly changing. We will now touch briefly upon some of this work.
Decades ago, Harrison et al. (1976) identified six primitive operations on the protection matrix that can be used as a base to model any protection system. These primitive operations are create object, delete object, create domain, delete domain, insert right, and remove right. The two latter primitives insert and remove rights from specific matrix elements, such as granting domain 1 permission to read File6.
These six primitives can be combined into protection commands. It is these protection commands that user programs can execute to change the matrix. They may not execute the primitives directly. For example, the system might have a command to create a new file, which would test to see if the file already existed, and if not, create a new object and give the owner all rights to it. There might also be a command to allow the owner to grant permission to read the file to everyone in the system, in effect, inserting the ‘‘read’’ right in the new file’s entry in every domain.
At any instant, the matrix determines what a process in any domain can do, not what it is authorized to do. The matrix is what is enforced by the system; authorization has to do with management policy. As an example of this distinction, let us consider the simple system of Fig. 9-10 in which domains correspond to users. In Fig. 9-10(a), we see the intended protection policy: Henry can read and write mailbox7, Roberta can read and write secret, and all three users can read and execute compiler.
Figure 9-10
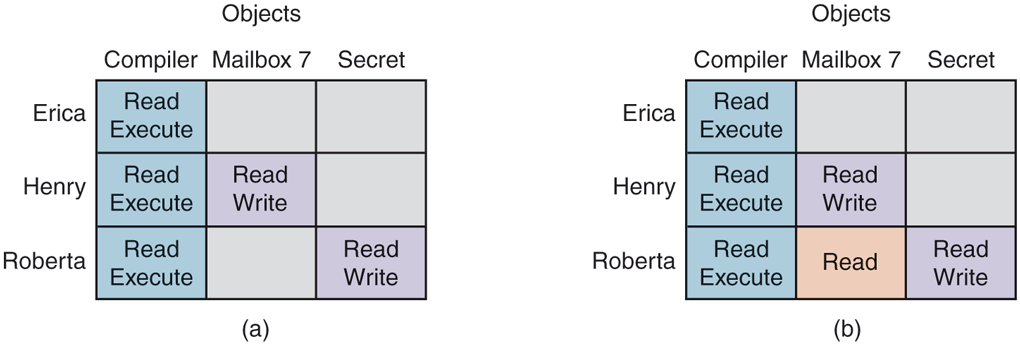
(a) An authorized state. (b) An unauthorized state.
Now imagine that Roberta is very clever and has found a way to issue commands to have the matrix changed to Fig. 9-10(b). She has now gained illicit access to mailbox7, something she is forbidden from having. If she tries to read it, the system will carry out her request because it does not know that the state of Fig. 9-10(b) is unauthorized.
It should now be clear that the set of all possible matrices can be partitioned into two disjoint sets: the set of all authorized states and the set of all unauthorized states. A question around which much theoretical research has revolved is this: ‘‘Given an initial authorized state and a set of commands, can it be proven that the system can never reach an unauthorized state?’’
In effect, we are asking if the available mechanism (the protection commands) is adequate to enforce some protection policy. Given this policy, some initial state of the matrix, and the set of commands for modifying the matrix, what we would like is a way to prove that the system is secure. Such a proof turns out quite difficult to acquire; many general-purpose systems are not theoretically secure. Harrison et al. (1976) proved that in the case of an arbitrary configuration for an arbitrary protection system, security is theoretically undecidable. However, for a specific system, it may be possible to prove whether the system can ever move from an authorized state to an unauthorized state. For more information, see Landwehr (1981).
9.3.1 Multilevel Security
Most operating systems allow individual users to determine who may read and write their files and other objects. This policy is called discretionary access control. In many environments this model works fine, but there are other environments where much tighter security is required, such as the military, corporate patent departments, and hospitals. In the latter environments, the organization has stated rules about who can see what, and these may not be modified by individual soldiers, lawyers, or doctors, at least not without getting special permission from the boss (and probably from the boss’ lawyers as well). These environments need mandatory access controls to ensure that the stated security policies are enforced by the system, in addition to the standard discretionary access controls. What these mandatory access controls do is regulate the flow of information, to make sure that it does not leak out in a way it is not supposed to. Not even if a malicious user tries to leak it.
The Bell-LaPadula Model
The most widely used multilevel security model is the Bell-LaPadula model so we will start there (Bell and LaPadula, 1973). This model was designed for handling military security, but it is also applicable to other organizations. In the military world, documents (objects) can have a security level, such as unclassified, confidential, secret, and top secret. People are also assigned these levels, depending on which documents they are allowed to see. A general might be allowed to see all documents, whereas a lieutenant might be restricted to documents cleared as confidential and lower. A process running on behalf of a user acquires the user’s security level. Since there are multiple security levels, this scheme is called a multilevel security system.
The Bell-LaPadula model has rules about how information can flow:
The simple security property: A process running at security level k can read only objects at its level or lower. For example, a general can read a lieutenant’s documents but a lieutenant cannot read a general’s documents.
The * property: A process running at security level k can write only objects at its level or higher. For example, a lieutenant can append a message to a general’s mailbox telling everything he knows, but a general cannot append a message to a lieutenant’s mailbox telling everything she knows because the general may have seen top-secret documents that may not be disclosed to a lieutenant.
Roughly summarized, processes can read down and write up, but not the reverse. If the system rigorously enforces these two properties, it can be shown that no information can leak out from a higher security level to a lower one. The * property was so named because in the original report, the authors could not think of a good name for it and used * as a temporary placeholder until they could devise a better name. They never did and the report was printed with the *. In this model, processes read and write objects, but do not communicate with each other directly. The Bell-LaPadula model is illustrated graphically in Fig. 9-11.
Figure 9-11
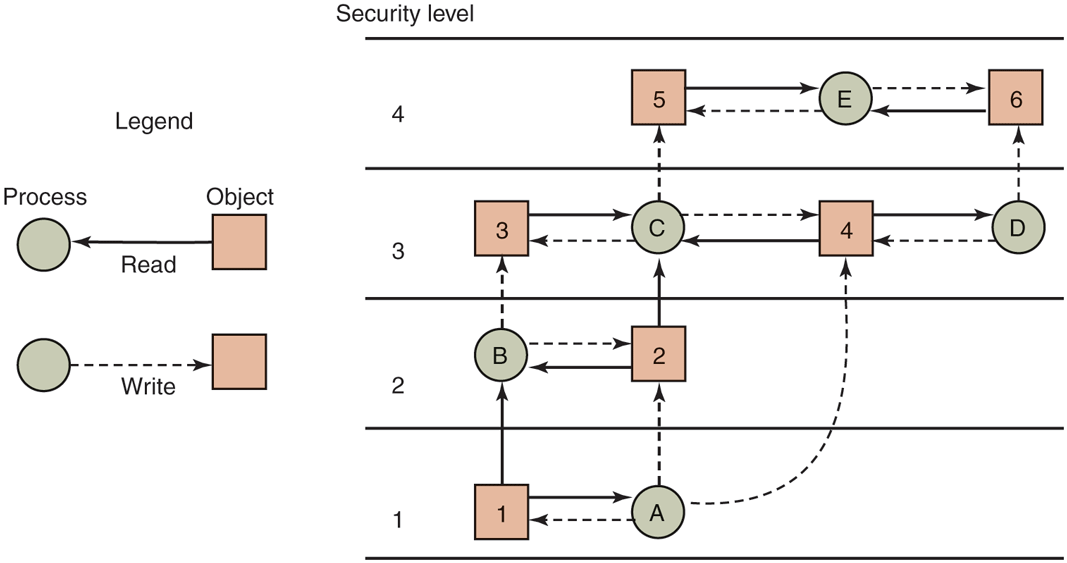
The Bell-LaPadula multilevel security model.
In this figure, a (solid) arrow from an object to a process indicates that the process is reading the object, that is, information is flowing from the object to the process. Similarly, a (dashed) arrow from a process to an object indicates that the process is writing into the object, that is, information is flowing from the process to the object. Thus all information flows in the direction of the arrows. For example, process B can read from object 1 but not from object 3.
The simple security property says that all solid (read) arrows go sideways or upward. The * property says that all dashed (write) arrows also go sideways or upward. Since information flows only horizontally or upward, any information that starts out at level k can never appear at a lower level. In other words, there is never a path that moves information downward, thus guaranteeing the security of the model.
The Bell-LaPadula model refers to organizational structure, but ultimately has to be enforced by the operating system. One way this could be done is by assigning each user a security level, to be stored along with other user-specific data such as the UID and GID. Upon login, the user’s shell would acquire the user’s security level and this would be inherited by all its children. If a process running at security level k attempted to open a file or other object whose security level is greater than k, the operating system should reject the open attempt. Similarly attempts to open any object of security level less than k for writing must fail. This is extremely simple and easy to enforce. Just add two if statements to the code and, bingo, a secure system—at least for the military.
The Biba Model
To summarize the Bell-LaPadula model in military terms, a lieutenant can ask a private to reveal all he knows and then copy this information into a general’s file without violating security. Now let us put the same model in civilian terms. Imagine a company in which janitors have security level 1, computer programmers have security level 3, and the president of the company has security level 5. Using Bell-LaPadula, a programmer can query a janitor about the company’s future plans and then overwrite the president’s files that contain corporate strategy. Not all companies might be equally enthusiastic about this model.
The problem with the Bell-LaPadula model is that it was devised to keep secrets, not guarantee the integrity of the data. For the latter, we need precisely the reverse properties (Biba, 1977):
The simple integrity property: A process running at security level k can write only objects at its level or lower (no write up).
The integrity * property: A process running at security level k can read only objects at its level or higher (no read down).
Together, these properties ensure that the programmer can update the janitor’s files with information acquired from the president, but not vice versa. Of course, some organizations want both the Bell-LaPadula properties and the Biba properties, but these are in direct conflict so they are hard to achieve simultaneously.
9.3.2 Cryptography
Formal approaches and mathematical rigor can also be found in cryptography. Operating systems use cryptographic solutions in many places. For instance, some file systems encrypt all the data on disk, while protocols such as IPSec can encrypt or sign the content of network packets. Even so, cryptography itself is to operating system developers as the internal combustion engine or electric motor is to drivers: you do not really need to understand the details, as long as you can use it. In this section, we will limit ourselves to a bird’s-eye view of cryptography.
The purpose of cryptography is to take a message or file, called the plaintext, and encrypt it into ciphertext in such a way that only authorized people know how to convert it back to plaintext. For all others, the ciphertext is just an incomprehensible pile of bits. Strange as it may sound to beginners in the area, the encryption and decryption algorithms (functions) should always be public. Trying to keep them secret almost never works and gives the people trying to keep the secrets a false sense of security. In the trade, this tactic is called security by obscurity and is employed only by security amateurs. Oddly enough, the category of amateurs also includes many huge multinational corporations that really should know better. As mentioned earlier, this is just Kerckhoffs’ principle.
Instead, the secrecy depends on parameters to the algorithms called keys. If P is the plaintext file, is the encryption key, C is the ciphertext, and E is the encryption algorithm (i.e., function), then This is the definition of encryption. It says that the ciphertext is obtained by using the (known) encryption algorithm, E, with the plaintext, P, and the (secret) encryption key, as parameters. The idea that the algorithms should all be public and the secrecy should reside exclusively in the keys is called Kerckhoffs’ principle, as mentioned earlier. All serious cryptographers subscribe to this idea.
Similarly, where D is the decryption algorithm and is the decryption key. This says that to get the plaintext, P, back from the ciphertext, C, and the decryption key, one runs the algorithm D with C and as parameters. The relation between the various pieces is shown in Fig. 9-12.
Figure 9-12
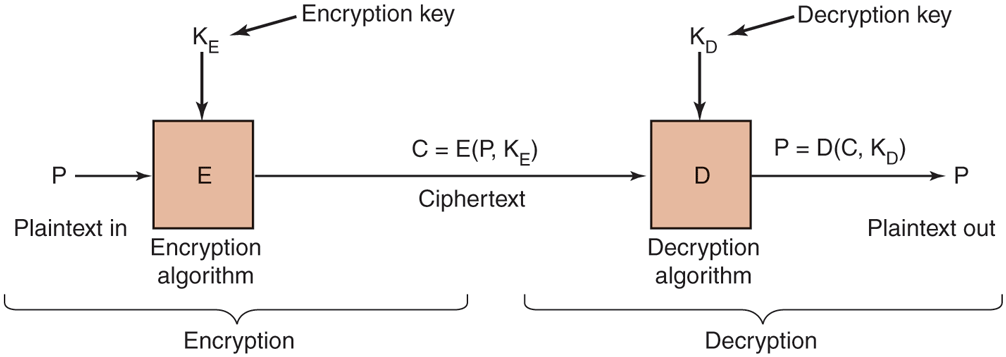
Relationship between the plaintext and the ciphertext.
Secret-Key Cryptography
To make this clearer, consider an encryption algorithm in which each letter is replaced by a different letter, for example, all As are replaced by Qs, all Bs are replaced by Ws, all Cs are replaced by Es, and so on like this:
plaintext: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
cipheetext: Q W E R T Y U I O P A S D F G H J K L Z X C V B N M
This general system is called a monoalphabetic substitution, with the key being the 26-letter string corresponding to the full alphabet. The encryption key in this example is QWERTYUIOPASDFGHJKLZXCVBNM. For the key given above, the plaintext ATTACK would be transformed into the ciphertext QZZQEA. The decryption key tells how to get back from the ciphertext to the plaintext. In this example, the decryption key is KXVMCNOPHQRSZYIJADLEGWBUFT because an A in the ciphertext is a K in the plaintext, a B in the ciphertext is an X in the plaintext, etc.
While the encryption is extremely simple to break, it serves a nice illustration of an important class of cryptographic systems. When it is easy to obtain the decryption key from the encryption, like in this case, it is called secret-key cryptography or symmetric-key cryptography. Although monoalphabetic substitution ciphers are completely worthless, other symmetric key algorithms are known and are relatively secure if the keys are long enough. For serious security, minimally 256-bit keys should be used, giving a search space of keys. For reference, the number of atoms in the entire observable universe, in all the galaxies combined, is estimated to be in the ballpark of only 10x bigger, so is a rather large number. Shorter keys may thwart amateurs, but certainly not major governments.
Public-Key Cryptography
Secret-key systems are efficient because the amount of computation required to encrypt or decrypt a message is manageable, but they have a big drawback: the sender and receiver must both be in possession of the shared secret key. They may even have to get together physically for one to give it to the other. To get around this problem, public-key cryptography is used (Diffie and Hellman, 1976). This system has the property that distinct keys are used for encryption and decryption and that given a well-chosen encryption key, it is virtually impossible to discover the corresponding decryption key. Under these circumstances, the encryption key can be made public and only the private decryption key kept secret.
Just to give a feel for public-key cryptography, consider the following two questions:
Question 1: How much is ?
Question 2: What is the square root of 3912571506419387090594828508241?
Most sixth graders, if given a pencil, paper, and the promise of a really big ice cream sundae for the correct answer, could answer question 1 in an hour or two. Most adults given a pencil, paper, and the promise of a lifetime 50% tax cut could not solve question 2 at all without using a calculator, computer, or other external help. Although squaring and square rooting are inverse operations, they differ enormously in their computational complexity. This kind of asymmetry forms the basis of public-key cryptography. Encryption makes use of the easy operation but decryption without the key requires you to perform the hard operation.
As an example, a popular public-key system called RSA (named after the designers, Ron Rivest, Adi Shamir, and Len Adelson) exploits the fact that multiplying really big numbers is much easier for a computer to do than factoring really big numbers, especially when all arithmetic is done using modulo arithmetic and all the numbers involved have hundreds of digits (Rivest et al., 1978).
The way public-key cryptography works is that everyone picks a (public key, private key) pair and publishes the public key. The public key is the encryption key; the private key is the decryption key. Usually, the key generation is automated, possibly with a user-selected password fed into the algorithm as a seed. To send a secret message to a user, a correspondent encrypts the message with the receiver’s public key. Since only the receiver has the private key, only the receiver can decrypt the message.
Public-key cryptography is great because you can just publish your public key and everyone can use it and be sure that you alone can read the message. In contrast, with secret-key cryptography you have to worry about getting the key to the communicating parties in a secure manner. Why would anyone ever use it? The answer is simple. The main problem with public-key cryptography is that it is a thousand times slower than symmetric cryptography.
Digital Signatures
Frequently it is necessary to sign a document digitally. For example, suppose a bank customer instructs the bank to buy some stock for him by sending the bank an email message. An hour after the order has been sent and executed, the stock crashes. The customer now denies ever having sent the email. The bank can produce the email, of course, but the customer can claim the bank forged it in order to get a commission. How does a judge know who is telling the truth?
Digital signatures make it possible to sign emails and other digital documents in such a way that they cannot be repudiated by the sender later. One common way is to first run the document through a one-way cryptographic hash algorithm. Such a function has the property that given f and its parameter x, computing is easy to do, but given only finding x is computationally infeasible. The hash function typically produces a fixed-length result independent of the original document size. Popular hash functions are SHA-256 and SHA-512, which produce 32-byte and 64-byte results, respectively.
The next step assumes the use of public-key cryptography as described above. The document owner then applies his private key to the hash to get D(hash). This value, called the signature block, is appended to the document and sent to the receiver, as shown in Fig. 9-13.
Figure 9-13
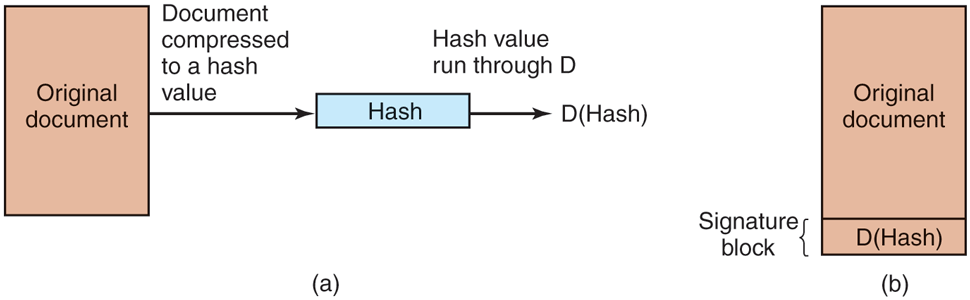
(a) Computing a signature block. (b) What the receiver gets.
When the document and hash arrive, the receiver first computes the hash of the document using SHA-256 or whatever cryptographic hash function has been agreed upon in advance. The receiver then applies the sender’s public key to the signature block to get E(D(hash)), getting back the original hash. Note that this assumes a cryptographic system where Fortunately, RSA has that property. If the computed hash does not match the hash from the signature block, the document, the signature block, or both have been tampered with (or changed by accident). The value of this scheme is that it applies (very slow) public-key cryptography only to a relatively small piece of data, the hash. To use this signature scheme, the receiver must know the sender’s public key. Many users therefore publish their public key on their Web page.
9.3.3 Trusted Platform Modules
All cryptography requires keys. If the keys are compromised, all the security based on them is also compromised. Storing the keys securely is thus essential. How does one store keys securely on a system that is not secure?
One proposal that the industry has come up with is a chip called the TPM (Trusted Platform Module), which is a cryptoprocessor with some nonvolatile storage inside it for keys. The TPM can perform cryptographic operations such as encrypting blocks of plaintext or decrypting blocks of ciphertext in main memory. It can also verify digital signatures. When all these operations are done in specialized hardware, they become much faster and are likely to be used more widely. Many computers already have TPM chips and many more are likely to have them in the future.
TPM is controversial because different parties have different ideas about who will control the TPM and what it will protect from whom. Microsoft has been a big advocate of this concept and has developed a series of technologies to use it, including Palladium, NGSCB, and BitLocker. In its view, the operating system controls the TPM and uses it for instance to encrypt the disk. However, it also wants to use the TPM to prevent unauthorized software from being run. ‘‘Unauthorized software’’ might be pirated (i.e., illegally copied) software or just software the operating system does not authorize. If the TPM is involved in the booting process, it might start only operating systems signed by a secret key placed inside the TPM by the manufacturer and disclosed only to selected operating system vendors (e.g., Microsoft). Thus the TPM could be used to limit users’ choices of software to those approved by the computer manufacturer (possibly in return for a large fee).
The music and movie industries are also very keen on TPM as it could be used to prevent piracy of their content. It could also open up new business models, such as renting songs or movies for a specific period of time by refusing to decrypt them after the expiration date.
One interesting use for TPMs is known as remote attestation. It allows an external party to verify that the computer with the TPM runs the software it should be running, and not something that cannot be trusted. We will look at remote attestation later when we introduce secure booting.
TPM has a variety of other uses that we do not have space to get into. Interestingly enough, the one thing TPM does not do is make computers more secure against external attacks. What it really focuses on is using cryptography to prevent users from doing anything not approved directly or indirectly by whoever controls the TPM. If you would like to learn more about this subject, the article on Trusted Computing in the Wikipedia is a good place to start.