map and flatMapValidation data type to remove complex branching logic::)The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.
In chapter 4, you learned how function composition leads to fluent, compact, and declarative code when you use compose to chain your function’s inputs and outputs as data passes through them. Composition has a lot of benefits because it uses JavaScript’s strongest feature, as I’ve said many times: higher-order functions. With functions, you can achieve low-level composition at the lowest unit of abstraction. But a higher-kinded composition also exists in the way objects compose. Making objects compose as strongly as functions do is a key idea that we’ll discuss in section 5.3.
The type of composable object pattern you’ll learn about in this chapter is known as the Algebraic Data Type (ADT) pattern. An ADT is an object with a particular, well-known interface that allows a similar abstraction to compose to chain multiple ADTs together. Much like any class, ADTs can also contain or store other objects, but they are much simpler than a class in that they model a single concept, such as validation, error handling, null checking, or sequences. Because you’ve learned about function composition, you can see that it’s simple to compose functions in a world where nothing fails and all the inputs and outputs of your functions are well-defined. It’s a different story when you also need to validate data and catch exceptions while taking advantage of this pattern. Learning to use ADTs is extremely beneficial for this purpose because they provide concise APIs that allow you to build whole programs from simpler parts—composition at its core.
Take a moment to reflect on some of the problems we tackled in chapter 4. Given a user’s digital wallet address, for example, we computed the total amount of Bitcoin in the blockchain. But what would happen if the provided address was null? Well, in that case, the program would fail because we didn’t add any guards against this possibility.
More generally, how can we deal with invalid data (null, undefined) flowing through a composition sequence? The syntax of compose doesn’t give you much room to insert imperative conditional validation statements between functions. Rather than clutter each function with common validation logic, your best bet is to extract it, as shown in the following listing.
Listing 5.1 Embedding validation checks before each composed function
compose(f3, validate, f2, validate, f1, validate);
function validate(data) {
if(data !== null) {
return data; ❶
}
throw new TypeError(`Received invalid data ${data}`); ❷
}
❶ Pass the data along to the next function in the chain.
❷ Otherwise, exit with an error.
This process doesn’t work, however, because
You lose the context in which validation takes place, which means that you can’t apply specific rules or exit with a proper validation message in the event of a failure.
As far as the last point is concerned, if the first function fails to produce a useful result, chances are that the rest of the flow shouldn’t be allowed to continue. The same thing happens when you’re working with some third-party code that may throw exceptions. In the imperative world, you would add try/catch guards. But again, try/catch is not something you can easily plug into compose; it’s an impedance mismatch between FP and OO, and you’d be fighting against FP to try to keep things linear and point-free. Take a look at the next listing.
Listing 5.2 The inconvenience of mixing try/catch with compose
compose(
c => {
try {
return f3(c); ❶
}
catch(e) {
handleError(e);
}
},
b => {
try {
return f2(b); ❶
}
catch(e) {
handleError(e);
}
},
a => {
try {
return f1(a); ❶
}
catch(e) {
handleError(e);
}
}
)
❶ Because each function is surrounded by imperative error handling code, you can’t take advantage of a declarative, point-free style (chapter 4).
This poor design is a result of combining paradigms the wrong way. Instead of throwing an error abruptly, we might like to handle this task in a way that mitigates the side effect. To fix this problem, we need to add the necessary guardrails or wrappers that can control the context in which a function and its validation operation execute, yet keep things separate, compact, and declarative. Does that sound like a tall order? It is if we don’t have the necessary techniques in place. This chapter teaches these techniques, all of which revolve around higher-order functions, with the help of some more FP principles.
ADTs expose a well-known, universal API that facilitates composability. You’ll learn that the map interface (in the same spirit as Array#map) indicates that a particular object behaves like a functor. Similarly, the flatMap interface indicates that an object behaves like a monad. We’ll unpack both of these terms soon. Both of these interfaces allow an ADT to compose with others.
NOTE The terms functor and monad originate from category theory, but you don’t need to understand mathematics to learn and use them in practice.
After teaching some of the fundamentals, this chapter works its way up to creating an ADT from scratch, tackling the complexity behind validating or checking the contents of a block, transaction, and even the entire blockchain data structure. By the end, you’ll understand what code like this does:
Validation.of(block) .flatMap(checkLength(64)) .flatMap(checkTampering) .flatMap(checkDifficulty) .flatMap(checkLinkage(previousHash)) .flatMap(checkTimestamps(previousTimestamp));
This code addresses all the concerns we raised earlier, although how may not be obvious yet. The code removes repetition, creates no additional side effects, and (best of all) is declarative and point-free. This type of abstraction Validation creates a closed context around the validation logic. Let’s begin by understanding what we mean by closed context.
When we write functions, it would be ideal to assume the perfect application state. That is, all the data coming in and out of our functions is always correct and valid, and none of the objects in our system have a null or undefined value. This state would allow us to reduce the boilerplate of data checks everywhere. Sadly, this situation is never the case. Alternatively, we could think about wrapping functions with some abstraction that always checks for invalid data of any nature. In this section, we’ll create a simple abstraction to start getting used to the pattern presented in this book. In section 5.5, we’ll build on that pattern to build an actual ADT.
Functions can become complex when we interleave their business logic with side work such as data validation, error handling, or logging. We can say that these concerns are tangential to the task at hand, yet they are important parts of the working application. Other tasks may include handling exceptions or logging to a file. We’ll call these tasks effects.
NOTE An effect is not to be confused with a side effect. A side effect may be a type of effect, as used in this context, but an effect is more of an arbitrary task.
Let’s focus on one of these effects: data validation. Suppose that you’re writing a small algorithm, using a sequence of functions. At each step, you want to make sure that the arguments each function receives are valid (not null, greater than zero, not empty, and so on). These are important to ensure that the algorithm is correct from a practical point of view but are not essential parts of the algorithm itself. Instead of cluttering each function, you remove or wrap this effect in some form of abstraction.
Suppose that this hypothetical algorithm has three steps: f1, f2, and f3. You already saw the interleaving happening in this code in listing 5.1:
compose(f3, validate, f2, validate, f1, validate);
The data is validated before each function runs. Let’s improve this code to remove the repetition. Using the lessons of chapter 4, we’ll wrap these functions (close over them), using a higher-order function that accepts the function being executed as input and the data in curried form. Higher-order functions are great at converting some body of code into callable form. This approach would allow validate to decide whether to apply the function based on the validity of the data provided.
To illustrate a possible solution, let’s make our problem more concrete by focusing only on calling functions, with the condition that the null check is successful (not null). Consider a function such as applyIfNotNull:
function applyIfNotNull(fn) {
return data => {
if (data !== null) {
return data;
}
throw new Error(`Received invalid data: ${data}`);
}
}
compose(applyIfNotNull(f3), applyIfNotNull(f2), applyIfNotNull(f1));
As you can see, the null check is repeated around every function call. Because applyIfNotNull is curried manually, we can remove duplication by mapping it over the functions that make up your business logic, as shown in the next listing.
Listing 5.3 Applying multiple functions to compose with map
compose(...[f3, f2, f1].map(applyIfNotNull)); ❶
❶ Applies applyIfNotNull to every function and then spreads the resulting array as arguments to compose
This step gets us closer to a more declarative, expression-oriented code instead of imperative branching logic, but we still need to account for two items:
A null check is not the only form of validation we’ll need in the real world. We need to support more kinds of logic.
We’re using an exception, which is itself a side effect, to break out of the logic in a dramatic fashion.
We need to increase the level of abstraction from a function to some form of contextual data structure that can somehow keep track of the validation results along the way and apply the functions accordingly. One way is to use a wrapper object that encapsulates data and abstracts the application of an effect to this data as part of exercising its business logic, much as applyIfNotNull did earlier, in an immutable way without leaking side effects.
Possibly the simplest type of container data structure in JavaScript is Array, which among its comprehensive set of methods has a few that we can use for this type of abstraction:
A static function to construct new containers with a value — For a class C, this function is usually called C.of or C.unit. The function, which is similar to Array.of, is also called a type-lifting function as it allows you to bring some typed variable into a context on which you will perform operations. Lifting some object and placing it in a box is a good analogy.
A function to transform this data — This transformation is usually done via a map method on the object with a specific contract. map is shared by all instances, so it should be defined at prototype level (C.prototype.map).
A function to extract the result from the container — This function is implementation-specific. For arrays, you can use something like Array#pop.
Anything beyond this protocol depends on what additional logic you need for the specific wrapper.
Before we start implementing our own wrappers, let’s continue down the path of using an array to represent encapsulation and immutability. This practice will help us warm up on the coding patterns used by ADTs.
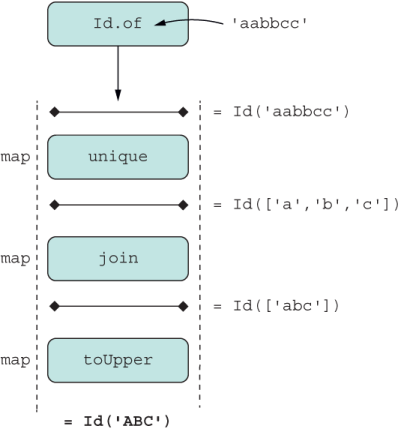
Wrapping a value inside some container, such as an array literal, gives you automatic fluent-coding capabilities on several values, not just one. For the sake of this discussion, let’s focus on one value. Consider this example. Given a string, suppose that you want to remove duplicate characters and capitalize the final string. With input of "aabbcc", for example, the result should be "ABC".
Simple enough. As you know, the best way to apply a sequence of computations to an array of elements is through map, which is a stateless method, so you’re never changing the original array that called it or its elements. This situation satisfies the immutability requirement. Also, we need methods to put a value inside the array and then a way to extract the data. For this task, we can use lifting operations Array.of and Array#pop, respectively, as shown in the next listing.
Listing 5.4 Mapping functions on an array
const unique = letters => Array.from(new Set(letters)); ❶ const join = arr => arr.join(''); const toUpper = str => str.toUpperCase(); const letters = ['aabbcc'] .map(unique) // [['a', 'b', 'c']] .map(join) // ['abc'] .map(toUpper) // ['ABC'] .pop(); ❷ letters; // 'ABC'
❶ Uses the capabilities of Set, which accepts an iterable object, to remove duplicates
❷ Could have also used Array.prototype.shift or [0]
JavaScript gives us some syntactic improvement (in the shape of a box) by using the array literal directly:
['aabbcc'] .map(unique) .map(join) .map(toUpper) .pop(); // 'ABC'
If you want to be a little more precise, you can use the Array.of as a generic constructor function:
Array.of('aabbcc')
.map(unique)
.map(join)
.map(toUpper)
.pop(); // 'ABC'
NOTE When you construct a new array, using the Array constructor function with new is not the best way to go about it. This function has unpredictable behavior, depending on the type used. The function new Array('aabbcc'), for example, creates an array with the single element ['aabbcc'], as we’d expect. But new Array(3) creates an empty array with three empty slots: [ , , ]. The Array.of API corrects for this situation, but in most cases, the simplest approach is to use array literal notation directly: ['aabbcc'].
The container that results from using an array is analogous to what we call an identity context. This term comes from the simple yet popular identity function (const identity = a => a), which you learned about in chapter 4. This function is commonly used in functional programs and echoes the value it’s given. In FP, identity means that some value is left untouched.
Similarly, an identity context would not have any computational logic of its own. It wraps a single value and doesn’t do any additional processing beyond what you provide in your mapping functions; it has no effect on the data. We say that it’s contextless, or side-effect-free.
Let’s take the array example a bit further. One way we could easily implement an Id class in JavaScript is to extend from Array, as shown in listing 5.5. This example is meant only to illustrate how the map operator could apply generically over simple containers that enclose a single value. Normally, I don’t recommend extending (monkey-patching) from standard types; this example is for teaching purposes, and its use will become clearer later.
Listing 5.5 Implementing a contextless container by extending from Array
class Id extends Array {
constructor(value) {
super(1); ❶
this.fill(value);
}
}
Id.of('aabbcc') ❷
.map(unique)
.map(join)
.map(toUpper)
.pop(); // 'ABC' ❸
❶ Initializes the underlying array with a size of 1 because we need to wrap only a single value
❷ Inherits Array.of as the type-lifting function
❸ Inherits Array#pop to extract the value from the container
Both Id and [] (empty array) are examples of closed contexts. Although this example may not look exciting, there’s more than meets the eye here. Concretely, Id
Enables a fluent data transformation API in which each stage performs a predictable transformation toward the end result, as in an assembly line.
Performs all operations in an immutable fashion because every stage of the process returns a new container with a new value. The mapped function may transform the data inside Id to any shape, as long as it advances our logic toward the final outcome. We say that the mapping function is any function from a -> b (a and b are any objects) that changes the container from Id(a) to a new Id(b).
Conceptually, programming with containers metaphorically resembles an assembly line or a railway, as shown in figure 5.1.
Figure 5.1 Assembly-style computing with containers. In this case, every step of the line maps a different transformation, creating a new intermediate result along the way until reaching the desired product.
NOTE In section 5.5.4, you’ll see that implementing validation (which is a binary operation) with wrappers will result in two paths or railways.
This last point, which refers to creating new containers as a result of applying functions, is the most important one to guarantee that the mapped functions are pure. Remember that purity is the key ingredient to make your code simple to reason about. Take as examples Array’s sort and reverse, which modify the original object in place. These APIs are harder to use because they can lead to unexpected behavior. On the other hand, immutable APIs like the ones in section 5.2 are much safer to use.
Array#{flat, flatMap} are two major additions to the almighty, all-encompassing JavaScript Array object. You saw these methods used briefly toward the end of chapter 4. Both of these methods allow you to manage multidimensional arrays easily:
[['aa'], ['bb'], ['cc']].flat(); // ['aa', 'bb', 'cc'] [[2], [3], [4]].flatMap(x => x ** 2); // [4, 9, 16]
Like all the recently added Array methods, these operations are immutable; instead of changing the original, they create new ones. Let’s start with flat.
Array#flat allows you to work with multiple array dimensions without having to break out of your lean and fluent pattern. Here are a few examples:
[['aa'], ['bb'], ['cc']].flat().map(toUpper); // ['AA', 'BB', 'CC']
The method even has the built-in smarts to skip nested nonarray objects. Empty slots in the array are left untouched:
[['aa'], , ['bb'], , ['cc']].flat().map(toUpper); // ['AA', 'BB', 'CC']
A fun fact about flat is that you can collapse structures of infinite depth:
[[[[['down here!']]]]].flat(Infinity); // ['down here!']
flat also allows you to work with functions that themselves return arrays. Recall from listing 5.4 that unique takes a string and returns an array with all letters minus duplicates. Mapping unique over ['aa', 'bb', 'cc'], for example, would produce a nested structure [['a'], ['b'], ['c']], which we can easily flatten at the end:
const unique = letters => Array.from(new Set([...letters])); ['aa', 'bb', 'cc'].map(unique).flat(); // ['a', 'b', 'c']
Because map and flat are often used together, JavaScript provides an API that takes care of both methods.
The map-then-flat sequence is used frequently in regular day-to-day coding. You might iterate over all blocks in the chain and then iterate over all transactions within each block, for example. Fortunately, a shortcut called flatMap calls both operations at the same time, as shown in the following listing.
Listing 5.6 Basic use of flatMap
['aa', 'bb', 'cc'].flatMap(unique); ❶
// ['a', 'b', 'c']
❶ unique returns an array. Instead of producing a nested array, flatMap runs the built-in flat logic after mapping the callback function to all elements.
We all understand map and flatMap as operations that allow you to apply callback functions to an array. Conceptually, however, these operations extend beyond arrays. If you’ve read chapter 4 and understand the basics of functional programming, code of this form should resemble a familiar pattern:
Id.of('aabbcc')
.map(unique)
.map(join)
.map(toUpper);
Would you say that this code looks like composition? As a matter of fact, the following code produces the same result ('ABC') as the previous one:
const uniqueUpperCaseOf = compose(toUpper, join, unique)
uniqueUpperCaseOf('aabbcc') // 'ABC'
How is it that map and compose lead to the same result? Except for minor syntactic differences compared with compose, map and flatMap represent contextual composition and are largely equivalent.
In section 5.1, I said that map allows objects (like Id and others) to apply functions. This statement applies equally to flatMap. In this section, you’ll learn that at a fundamental level, both of these operators behave like compose, so in essence, using map is nothing more than function composition, which cements the mental model of functional programming.
This equivalence is also important technically speaking, because you get all of the benefits of using compose that we covered in chapter 4, but now applied to objects. Let’s demonstrate this equivalence by defining map in terms of compose:
Function.prototype.map = function (f) {
return compose(
f,
this
);
};
Now all functions inherit map automatically. Using it reveals once again the close correspondence between the two:
compose(toUpper, join, unique)('aabbcc'); // 'ABC'
unique.map(join).map(toUpper) ('aabbcc'); // 'ABC'
What this correspondence tells us is that all the benefits that you gain with the composition of functions can easily be applied to composite types. In our simple use cases, map is an interface that allows both Array and Id to compose functions, and it will allow any ADT you use to compose functions.
Now that you’ve seen how these concepts intertwine, let’s define a universal interface for map that allows any object that implements it to compose together.
In the examples earlier in this chapter, you probably noticed that map and flatMap preserve the same caller type. For arrays, both return new arrays; for functions, both return new functions. This fact can’t be taken for granted. It’s a core part of the map interface, one that is universally accepted and allows your objects to work with other functional libraries, such as Ramda (https://ramdajs.com) or Crocks (https://crocks.dev). In this section, you’ll learn a little bit about the theory behind patterns such as functors and monads and how they are implemented in JavaScript.
The full theory on ADTs is extensive and better covered in books dedicated to functional programming or abstract algebra. I’ll cover enough here so that you can unlock the FP patterns that enable composable software, beginning with functors.
A book that focuses on the joy of programming with JavaScript and FP would not be complete without a proper dose of functors, because functors bring out the best in the language by relying on higher-order functions for data transformation.
A functor is anything (such as an object) that can be mapped over or that implements the map interface properly. Arrays in JavaScript are close to being functors, for example, and the map method enables a style of programming that’s superior to and less error-prone than regular for loops. As you learned in section 5.3, compose makes functions functors too, so you’ve used them quite a bit already without realizing it.
For an object to behave like a functor, it needs to follow two simple rules, which follow from the map/compose equivalence (section 5.3). I’ll use arrays again for simplicity to illustrate rules:
Identity — Mapping the identity function over a container yields a new container of the same type, which is also a good indicator that map should be side-effect-free:
['aa','bb','cc'].map(identity); // ['aa', 'bb', 'cc']
Composition — Composing two or more functions, such as f after g, is equivalent to mapping first g and then f. Both statements are equivalent to ['A', 'B', 'C']:
['aa','bb','cc'].map(
compose(
toUpper,
join,
unique
)
);
['aa','bb','cc']
.map(unique)
.map(join)
.map(toUpper);
Notice that I’ve been using the word equivalent loosely. The reason is to avoid eliciting the other forms of equivalence you’re accustomed to, such as the double equals operator (==), which is loosely equivalent to type coercion, and triple equals (===), which is a strict quality in value and type. Equivalent here means referentially transparent; the meaning or result of the program doesn’t change if you substitute an expression for its value.
Implementing a functor involves defining map with these simple rules and creating the contract of a closed context described in section 5.1, such as the implementing of a type-lifting function F.of, as well as a mechanism to extract the value from the container, such as a get method. As you learned in chapter 3, the best way to apply reusable interfaces to any object is to use a mixin. Let’s refactor Id (shown in the next listing) to take advantage of the Functor mixin.
Listing 5.7 Id class with minimal context interface
class Id {
#val;
constructor(value) {
this.#val = value;
}
static of(value) { ❶
return new Id(value);
}
get() { ❷
return this.#val;
}
}
❷ Getter to extract the value from the container
Functor is a mixin that exposes a map method, as shown in the following listing. map is a higher-order function that applies the given function f to the wrapped value and stores the result in the same container, like Array#map.
const Functor = {
map(f = identity) { ❶
return this.constructor.of(f(this.get())); ❷
}
}
❶ map accepts a callback function to apply, using identity as default function argument
❷ Applies the callback function to the value and wraps the result in a new instance of the same container, using the generic type-lifting function
Because the functor contract must preserve the enclosing structure, we can figure out the container instance calling it and invoke its static type-lifting constructor by using this.constructor.of. The fact that we’re using classes makes this procedure simple because it configures the constructor property and makes it easy to discover. Now let’s extend Id with Functor as we did with Transaction back in chapter 3:
Object.assign(Id.prototype, Functor);
Everything continues to work as before. Array#map resembles the same contract as a Functor’s map, so we can use it in the same way, as the next listing shows.
Listing 5.9 Sequential data processing with the Id functor
Id.of('aabbcc')
.map(unique) // Id(['a', 'b', 'c']) ❶
.map(join) // Id(['abc'])
.map(toUpper) // Id('ABC')
.get(); // 'ABC'
❶ Mapping from Id returns new Id objects
Let’s visualize the inner workings of a functor as opening the container to expose its value to the mapped function and then rewrapping the value in a new container, as shown in figure 5.2.
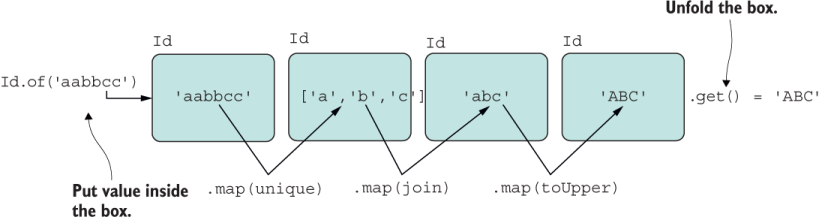
Figure 5.2 The mapping of functions over a container
If you glance once more at listing 5.9, you’ll notice that it’s fairly generic. Except for an implementation of a value-extracting method (Id#get or Array#pop), everything follows the generic functor contracts.
Functors let you map a simple function to transform the wrapped value and put it back in a new container of the same type. Frontend developers probably recognize that the jQuery object behaves like a functor. jQuery is a functor as well and is one of the first JavaScript libraries to popularize this style of coding (https://api.jquery.com/ jquery.map).
Now let’s look at a slightly different case. What would happen if you were to map a function that itself returns a container, such as mapping a function that returns an Id object? From what you’ve learned about arrays in this chapter, an operator like flatMap is designed to solve this problem. To understand why, we’ll study monads.
Monads are designed to tackle composing container-returning operations. Composing functions that return Id can result in an Id inside another Id; when composing Array, you get a multidimensional array, and so on. You get the idea.
An object becomes a monad by implementing the functor specification and the flatMap contract with its own simple protocol. The reason is that we’ll need to map functions that return wrapped data. Suppose that each of the functions in this code snippet returned an Id:
Id.of('aabbcc')
.map(unique)
.map(join)
.map(toUpper)
.get();
The result would look like figure 5.3.
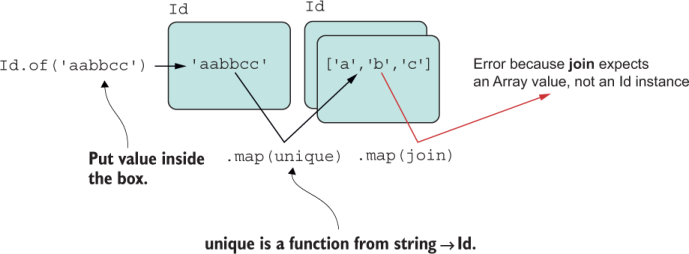
Figure 5.3 Mapping a function that returns an Id containing a wrapped value
Monads take chaining a sequence of computations to the next level so that you can compose functions that work with the same container or other containers. We’re going to stick with the same container for now, because this pattern is the most common one used in practice. For reference, the fantasy-land entry is at https://github.com/ fantasyland/fantasy-land#monad. Consider a monad M and equivalence as defined in section 5.4.2:
Left identity — Type-lifting some value a and then calling flatMap with function f should yield the same result as if you simply called f with a. In code, both expressions are equivalent:
M.of(a).flatMap(f) and f(a)
Let’s showcase left identity with simple arrays:
const f = x => Array.of(x**2); Array.of(2).flatMap(f); // [4] f(2); //[4]
Right identity — Given a monad instance, calling flatMap with the type-lift constructor function should produce an equivalent monad. Given a monad instance m, the snippets in the next listing are equivalent.
Listing 5.10 Array examples that illustrate right identity
m.flatMap(M.of)) and m
Array.of(2).flatMap(x => Array.of(x)); // [2] ❶
Array.of(2); // [2]
❶ Because the implementation of Array.of in JavaScript has multiple arguments, we’re not able to pass the function by name into flatMap; instead, we must use a function x => Array.of(x).
Associativity — As numbers are associative under addition, monads are associative under composition. The precedence instilled by the way you parenthesize an expression doesn’t alter the final result. Given a monad instance m and functions f and g, the following are equivalent:
m.flatMap(f).flatMap(g) and m.flatMap(a => f(a).flatMap(g)) const f = x => [x ** 2]; const g = x => [x * 3]; Array.of(2).flatMap(f).flatMap(g); // [12] Array.of(2).flatMap(a => f(a).flatMap(g)); // [12]
When you work with single values, the action of a map-then-flat can also be understood as returning the result of the mapping function alone, thereby ignoring the outermost layer. Our Monad mixin in the following listing accomplishes that task.
const Monad = {
flatMap(f) {
return this.map(f).get(); ❶
},
chain(f) { ❷
return this.flatMap(f);
},
bind(f) { ❷
return this.flatMap(f);
}
};
❶ Ignores the extra wrapping layer and assumes that the type is a functor
❷ You may also find this method called bind or chain.
This example teaches us that when we’re dealing with JavaScript arrays specifically, flatMap is much more efficient than calling map and then flat manually. This procedure is more efficient in terms of CPU cycles and memory footprint. Keep in mind that every time you call map or flat, a new array is created, so combining them in one fell swoop prevents the additional overhead.
For the sake of completeness, consider a similar example using Id:
const square = x => Id.of(x).map(a => a ** 2); const times3 = x => Id.of(x).map(a => a * 3); Id.of(2) .flatMap(square) .flatMap(times3) .get(); // 12 Id.of(2) .flatMap(a => square(a).flatMap(times3)) .get(); // 12
For this code to work, we will extend Id once more with the monadic behavior integrating that mixin:
Object.assign(Id.prototype, Functor, Monad);
We can continue to optimize this example a little bit more. Earlier, I mentioned that monads are also functors. Following that definition, it makes sense to compose the Functor mixin into the Monad mixin. Consider the Monad definition in the next listing.
Listing 5.12 Defining Monad and Functor
const Monad = Object.assign({}, Functor, {
flatMap(f) {
return this.map(f).get(); ❶
}
//... ❷
});
❷ Omits the other method aliases
This example shows how flexible and versatile composition is. Now you can make a type a Functor or a full Monad with its full contract:
Object.assign(Id.prototype, Monad);
At this point, you’ve learned in a basic way how functors and monads are defined. Although these sets of rules may feel contrived and limiting, they’re giving you immense structure—the same structure you get from using Array#{map, filter, reduce} instead of straight for loops and if conditions.
Functor and monads are universal interfaces (protocols) that can plug generically into many parts of your application. Abide by them, and any third-party code or any other parts of your application that implement or support these types know exactly how to work with it. A good example of how this protocol integrates with other code is the Promise object, which you’re probably familiar with. Promises are modeled, to some extent, after functors and monads; substitute then for map or flatMap, and a lot of these rules discussed in section 5.4 apply. We’ll look at promises more closely in chapter 8.
Monads are not an easy pattern to grok, but it’s important to start learning about them now; more of these patterns are starting to emerge in modern software development, and you don’t want to get caught wrapped in a burrito (https://youtu.be/ dkZFtimgAcM); you want to be ready.
In practice, you will probably never need to implement Id as such in your own applications. I did it to show you how the pattern works and how appending the Functor and Monad mixins endow this class with powerful composable behavior. The real bang for your buck will come from more embellished, smarter types with computational logic of their own within their map and flatMap methods. In section 5.1, I defined a closed context and showed how it models a railway-driven approach to data processing. With the basics behind us, we’re going to kick things up a notch and create our own ADT to implement contextual validation.
An ADT is nothing more than an immutable composite data structure that contains other types. Most ADT in practice implement the monad contract, much like the Id container.
Before we dive in, it’s worth pointing out that an ADT is a different pattern from an Abstract Data Type (which goes by the same acronym): a collection that should hold objects of the same type, such as Array, Set, Stack, and Queue (although JavaScript does not enforce this rule). An Algebraic Data Type pattern, on the other hand, can and usually does contain different types. The Algebraic part of the name comes from the mathematical protocol of identity, composability, and associativity (section 5.4).
In this section, we’ll learn about the fundamentals of ADTs and see how to use the Functor and Monad contracts to solve contextual data validation in a composable manner.
ADTs are more prominent in the strongly typed world, where type information makes code more explicit and rigorous. (For more information on using types with JavaScript, see appendix B.) But there’s still a lot we can do even without type information. This section looks at the two most common kinds of ADTs: Record and Choice. Both of these encapsulate some useful coding patterns.
A record type is a composite that contains a fixed number of (usually primitive) types, called its operands. This is similar to a database record in which the schema describes the types it can hold and has a fixed length. Some JavaScript libraries, such as Immutable.js, provide a Record type that you can import and use. The most common example of a record is an immutable Pair:
const Pair = (left, right) =>
compose(Object.seal, Object.freeze)({
left,
right,
toString: () => `Pair [${left}, ${right}]`
});
A Pair is an immutable object with a cardinality of 2 that can be used to relate two pieces of information (of any type), such as a username and password, a public and private key, a filename with an access mode, or even a key/value entry in a map data structure. Pair is a generic record type of which Money, introduced in chapter 4, or a type like Point(x, y) can be derived implementations.
The best use of a Pair is to return two related values from a function at the same time. Most often, a simple array literal or even a simple object literal is used to express a rudimentary Pair. Then you can take advantage of destructuring to access each field. You could have something like
const [id, block] = blockchain.lookUp(hash);
const {username, password} = getCredentials(user);
Unfortunately, these two approaches don’t work well because they are mutable, and because array is generic, it doesn’t communicate any relationship among its values. A record semantically communicates an AND relationship among its values, implying they must exist or make sense together (such as username AND password).
Records also go by the name of product or tuple. A pair is a 2-tuple, and a triple is a 3-tuple, all the way to an n-tuple. JavaScript has no native tuple or record concept, but an early proposal might bring it to JavaScript in the near future (https://github .com/tc39/proposal-record-tuple).
Whereas a record enforces a logical AND, a choice represents a logical OR relationship among its operands or the values it accepts. A choice is also known as a discriminated union or a sum type. Like a record, a choice type can hold multiple values, but only one of them is used at any point in time. A simple analogy involves using JavaScript’s null coalesce and nullish coalesce operators, respectively. Consider the simple example in the next listing.
Listing 5.13 Null and nullish coalesce operators
const hash = precomputedHash || calculateHash(data); ❶ const hash = precomputedHash ?? calculateHash(data); ❷
❶ Evaluates right side when left side contains a falsy value
❷ Evaluates right side only when left side is null
In the case of the null coalesce operator, if precomputedHash is not a falsy value (null, undefined, empty string, 0, or so on), this expression evaluates the left side of the || operator; otherwise, it evaluates to the right. I recommend that you use the nullish (or nullary) coalesce operator (??), as it evaluates the right side only when the precomputedHash is null or undefined, which is what you intend to do most of the time.
Choice types are often used in cases that involve data checks, data validation, or error handling. The reason is that a choice models mutually exclusive branches such as success/failure, valid/invalid, and ok/error. These cases are simple binary (of cardinality 2) use cases, for which we mistakenly are tempted to abuse Booleans.
If you have experience with TypeScript, for example, an enumeration type or a utility type is a common way to represent an object that could be in one of multiple states. Consider this definition:
type Color = 'Red' | 'Blue';
With minimal tooling, you could also extend JavaScript with types (appendix B) and use enumerations the same way. Another analogy is a switch statement, which is often used to invoke conditional logic with multiple possible states. With two cases, the logic of a choice type would look something like this:
switch(value) {
case A:
// code block
break;
case B:
// code block
break;
default:
// code block
}
Using this structure, consider the hypothetical use case in the next listing that checks for the validity of a certain value.
Listing 5.14 Using a switch statement to perform an action based on one condition
switch(isValid(value)) {
case 'Success':
return doWork(value);
case 'Failure':
logError(...); ❶
default:
return getDefault();
}
❶ return/break intentionally skipped to return default value
You can think of a choice ADT as always keeping track of multiple mutually exclusive states and reacting accordingly. Validating data is no different in that you can have only one of two possible outcomes: success or failure.
Data validation is a common programming task, usually involving a lot of code splitting (if/else/switch statements) that are often duplicated and scattered in several parts of the application. We’re all well aware that code with lots of conditionals gets messy and difficult to abstract over, not to mention hard to read and expensive to maintain. This section teaches you how to implement and use monads to address this issue while keeping your code simple to read, modular, and (most important) composable.
Generally, when implementing an ADT, you must take two dimensions into account. One is the kind (record or choice), and the other is the level of composability needed (functor or monad). In this section, we will create a Validation object as a choice type with monadic behavior so that we can compose sequences of individual validated operations together. By the end, we’ll finish implementing the logic behind the HasValidation mixin and use it to run validation code on every element of the blockchain in a consistent way.
Validation models two states that make up its computation context, Success and Failure, as shown in figure 5.4.
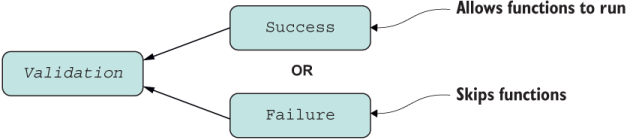
Figure 5.4 Structure of the Validation type. Validation offers a choice of Success or Failure, never both.
We’ll allow the Success branch to apply functions (such as doWork) on the contained value when it’s active. Indeed, this job sounds like one for map and flatMap. Otherwise, in the event of a validation failure, we’ll skip calling the logic and propagate the error encountered. This pattern is useful when you need to bubble up an error that occurred during a complex sequence of operations—something that if/else and even try/catch blocks struggle with.
In addition, think about how many times you have written validation functions that return Boolean. I know I have, but this is a bad habit. By returning a Validation object from your functions, you’re directly forcing users to handle Success and Failure cases properly instead of testing a Boolean. Another clear benefit is that your functions become self-documenting or, in Edsger Dijkstra’s words, “more precise.” In JavaScript, this benefit is important because documentation is often lacking, and you need to trace through the code to see what exceptions are being thrown or any special error values, such as null or undefined. Acknowledging that some operations might fail ahead of time is much better than having your users guess that an error, if any, might occur when invoking a particular function. We can all agree that returning false conveys nothing to the caller about which operation or data in question was invalid; there’s no context.
Finally, another good quality of validation procedures is that they fail-fast. Because composition chains a function’s inputs and outputs, it’s pointless to have functions run with invalid data when an error has already been discovered. Short-circuiting is sensible.
Let’s look at a hypothetical example in blockchains that involves validating whether a block has been tampered with. This check is easily made by recomputing a block’s hash and checking it against its own:
const checkTampering = block =>
block.hash === block.calculateHash()
? Success.of(block)
: Failure.of('Block hash is invalid');
const block = new Block(1, '123456789', ['some data'], 1);
checkTampering(block).isSuccess; // true
block.data = ['data compromised'];
checkTampering(block).isFailure; // true
This function checks for a certain condition and returns a Success wrapper containing the correct value or a Failure object with an error message. This function doesn’t care how the error propagates forward or how it would work as part of a longer composition chain; it focuses on its own task.
Both Success and Failure branches are part of the Validation composite and are the central abstractions that drive a series of validations to a final result or to an error. Success and Failure are closed contexts, modeling the notion of an operation that passes or fails as a first-class citizen of your application. The following listing uses a class to implement this behavior.
Listing 5.15 Parent Validation class
class Validation {
#val; ❶
constructor(value) {
this.#val = value;
if (![Success.name, Failure.name].includes(new.target.name)) { ❷
throw new TypeError(
`Can't directly instantiate a Validation.
Please use constructor Validation.of`
);
}
}
get() { ❸
return this.#val;
}
static of(value) { ❹
return Validation.Success(value);
}
static Success(a) {
return Success.of(a);
}
static Failure(error) {
return Failure.of(error);
}
get isSuccess() { ❺
return false;
}
get isFailure() { ❺
return false;
}
getOrElse(defaultVal) { ❻
return this.isSuccess ? this.#val: defaultVal;
}
toString() {
return `${this.constructor.name} (${this.#val})`;
}
}
❶ Value is private and read-only
❷ Prevents direct instantiation, effectively making Validation an abstract class and forcing its behavior to be accessed through its variant types: Success and Failure
❸ Reads the value from the container
❹ Generic type-lifting function that returns a new instance of Success
❺ Queries the type of container at runtime; set to false as default to indicate that none of the branches is active
❻ Provides a generic way to recover
Extending from this class are the concrete variant choices: Success and Failure. The Success path is what we call the happy path, so there’s not much to differentiate it from the parent. Failure overrides the behavior of some of those inherited methods, as shown in the next listing.
Listing 5.16 Success and Failure branches of Validation
class Success extends Validation {
static of(a) {
return new Success(a);;
}
get isSuccess() {
return true; ❶
}
}
class Failure extends Validation {
get isFailure() { ❶
return true;
}
static of(b) {
return new Failure(b);
}
get() { ❷
throw new TypeError(`Can't extract the value of a Failure`);
}
}
❶ Overrides the type of container
❷ Calling get directly on failure is considered to be a programming error.
It may not be immediately obvious, but given that Validation can hold only a single value at a time (valid value or an error), it’s more memory-efficient than record types, which store all values in the tuple.
Now that we’ve implemented the basic pieces, let’s see them in action.
To show this type in action, let’s refactor countBlocksInFile (started in chapter 4) to a function that also features validation:
const countBlocksInFile = compose(
count,
JSON.parse,
decode('utf8'),
read
);
This function reads from a file to a binary buffer, decodes this buffer to a UTF-8 string, parses this string to an array of blocks, and finally counts it. But this function is missing an important part: checking whether the file exists. If the file doesn’t exist, read will throw an exception. Likewise, without a valid Buffer object, decode will throw an exception, and so on.
Because the critical point of inflexion is whether the file exists, we can use Validation to abstract over this split point. Let’s refactor the read function to return a Validation instance instead in the next listing.
Listing 5.17 Creating a version of read that returns a Validation result
const read = f =>
fs.existsSync(f)
? Success.of(fs.readFileSync(f)) ❶
: Failure.of(`File ${f} does not exist!`); ❷
❶ The conditional expression here models the logical OR to decide which branch to follow.
❷ An array is useful so that you can concatenate more than one error message.
Now this code works as follows:
read('chain.txt'); // Success(<Buffer>)
read('foo.txt'); // Failure('File foo.txt does not exist!')
Executing the rest of the code is a matter of mapping each transformation to each Success container, like any generic functor. The Functor mixin is sufficient:
Object.assign(Success.prototype, Functor);
By doing this, we get the benefit of tightly coupling the validation branches and shared data with the loosely coupled, Lego-style extension of mixins for shared behavior. With map, this code works as it did with compose due to the map/compose equivalence. Once again, you see the deep impact of this ostensibly trivial equivalence:
const countBlocksInFile = f =>
read(f)
.map(decode('utf8'))
.map(JSON.parse)
.map(count);
countBlocksInFile('foo.txt'); // Success(<number>)
Furthermore, it’s a common pattern for choice ADTs to map functions on one side and skip them (no-op) on the other. Validation executes on the success branch, which we’ll call the right side, also known as right-biased. In the previous example, we made Success (the right side) a functor. We also need to account for the Failure branch so that any composed operations are ignored or skipped in the event of a read error. For this purpose, we can create a NoopFunctor mixin with the same shape as the regular Functor, as the next listing shows.
Listing 5.18 Using NoopFunctor in failure cases to skip calling mapped functions
const NoopFunctor = {
map() {
return this; ❶
}
}
❶ Because the data is left untouched, it’s sensible to return the same object to the caller.
Let’s assign NoopFunctor to Failure (the left side):
Object.assign( Failure.prototype, NoopFunctor );
After we account for both case classes, the flow of execution looks like figure 5.5.
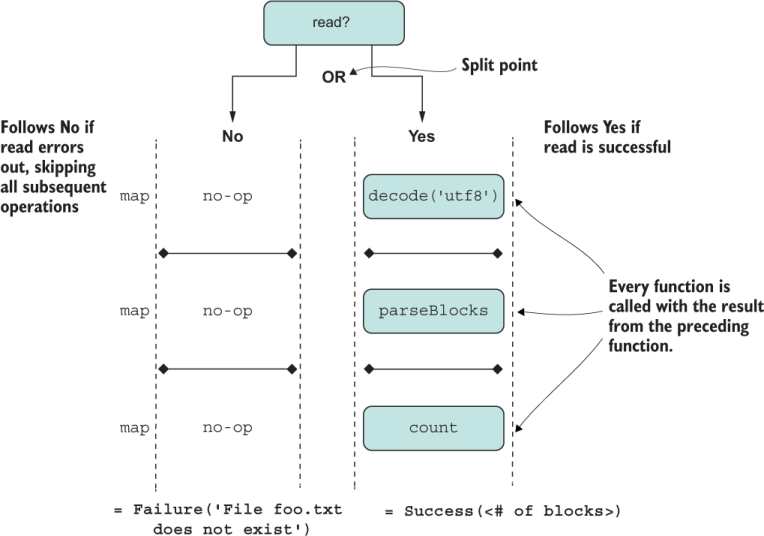
Figure 5.5 Detailed execution of the composition of functions mapped over a Validation type. When the operations are successful, the container allows each operation to map over the wrapped data; otherwise, it skips to a recovery alternative.
First, let’s look at a simple example of a failure branch so that you can understand how this object handles errors.
Suppose that you want to use Validation to abstract over checking for null objects. First, create the function that implements the branching logic (fromNullable):
const fromNullable = value =>
(value === null)
? Failure.of('Expected non-null value')
: Success.of(value);
This abstraction helps us apply functions to data without having to worry about whether the data is defined, as shown in the following listing.
Listing 5.19 Using fromNullable to process valid strings
fromNullable('joj').map(toUpper).toString() // 'Success (JOJ)'
fromNullable(null).map(toUpper).toString() ❶
// 'Failure (Expected non-null value)'
❶ Underlying implementation of map is the NoopFunctor, which ignores the operation when data is invalid
To showcase this type in the real world, let’s use it in our blockchain application. Validating or verifying the contents of a blockchain is such an important part of this technology that companies specialize in implementing this aspect of the protocol. We’re implementing a much more simplified version for this book, of course. Aside from checkTampering (as implemented in section 5.5.3) we must ensure that blocks are in the right position in the chain (checkIndex) and that their timestamps are greater than or equal to that of the previous one (checkTimestamp). Both simple rules look like this:
const checkTimestamps = curry((previousBlockTimestamp, block) =>
block.timestamp >= previousBlockTimestamp
? Success.of(block)
: Failure.of(`Block timestamps out of order`)
);
const checkIndex = curry((previousBlockIndex, block) =>
previousBlockIndex < block.index
? Success.of(block)
: Failure.of(`Block out of order`)
);
We’re going to use currying to make applying these functions easier. Notice that we defined these functions as curried functions (see chapter 4) to facilitate composing them as a validation sequence. Because blocks are linked in a chain, to compare one block, you need to load the previous one (after the genesis block). From any block, this process is always simple because each block has a reference to the previous block’s hash and a reference to the chain of which it is part, as shown in the next listing.
Listing 5.20 isValid method of Block
class Block {
//... omitting for brevity
isValid() {
const {
index: previousBlockIndex, ❶
timestamp: previousBlockTimestamp
} = this.#blockchain.lookUp(this.previousHash);
const validateTimestamps = ❷
checkTimestamps(previousBlockTimestamp, this);
const validateIndex = ❷
checkIndex(previousBlockIndex, this);
const validateTampering = checkTampering(this); ❷
return validateTimestamps.isSuccess &&
validateIndex.isSuccess &&
validateTampering.isSuccess;
}
}
const ledger = new Blockchain();
let block = new Block(ledger.height() + 1, ledger.top.hash, ['some data']);
block = ledger.push(block);
block.isValid(); // true
block.data = ['data compromised']; ❸
block.isValid(); // false ❹
❶ Uses destructuring with variable name change
❷ These functions return either Success or Failure.
❹ Validation check fails due to tamper check
This code seems perfectly fine if we want to return a Boolean result, which lacks any context of the running operation. The best approach here, however, is for isValid to return a Validation object instead of a Boolean. That way, if we want to validate the entire blockchain data structure (not one block), we can compose all the Validation objects together, and in the event of a failure, we could report exactly what the error is.
As we did with Id in section 5.4.2, let’s bestow upon Validation the ability to compose with other objects of the same type and form chains. For this task, we can attach the Monad mixin, which includes Functor as well as the ability to flatMap other Validation-returning functions. For the Success branch, we can assign the Monad mixin:
Object.assign(Success.prototype, Monad);
For Failure, we can apply the logicless NoopMonad:
const NoopMonad = {
flatMap(f) {
return this;
},
chain(f) {
return this.flatMap(f);
},
bind(f) {
return this.flatMap(f);
}
}
Then extending Failure is similar:
Object.assign( Failure.prototype, NoopMonad );
The next listing shows how you can type-lift a block object into Validation. Then the ADT takes over, and all you need to do is chain the validation rules, like building a small rules engine.
Listing 5.21 Block validation with flatMap
class Block {
...
isValid() {
const {
index: previousBlockIndex,
timestamp: previousBlockTimestamp
} = this.#blockchain.lookUp(this.previousHash);
return Validation.of(this)
.flatMap(checkTimestamps(previousBlockTimestamp)) ❶
.flatMap(checkIndex(previousBlockIndex)) ❶
.flatMap(checkTampering); ❶
}
}
❶ The curried form is useful so that the block object (the dynamic argument) is passed into each call to flatMap.
As you can see, this implementation looks a lot more elegant than the previous one and serves as another good example of a hybrid OOP/FP implementation using mixins. To ensure a more rigorous transition from OO to FP land, you could opt to pass a frozen version of the object:
return Validation.of(Object.freeze(this)) .flatMap(checkTimestamps(previousBlockTimestamp)) .flatMap(checkIndex(previousBlockIndex)) .flatMap(checkTampering);
A happy path run of this algorithm looks like figure 5.6.
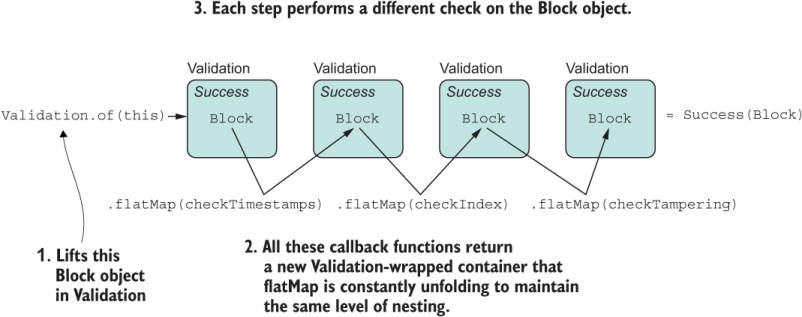
Figure 5.6 Sequential application of different Validation-returning check functions composed together with flatMap
This new version of isValid outputs a Validation result instead of a Boolean, so using in in the Success case looks like this:
block.isValid().isSuccess; // true
If any of the checks fails, Validation will be smart about skipping the rest:
block.isValid().isFailure; // true block.isValid().toString(); // 'Failure (Block hash is invalid)'
Perhaps you’re thinking that although this code looks more succinct, having to call flatMap every time is a bit verbose. Why not try something more point-free? In chapter 4, you learned how to create point-free function compositions with compose and curry. You can also achieve a point-free style with monads in JavaScript. To understand how this could work, first we need to implement a slightly different variation of compose called composeM, which uses flatMap to control the flow of data.
Point-free coding has the advantage of making complex logic much simpler to read at a high level. To allow for point-free coding using monads, we need to build up a little more plumbing. In section 5.3, you learned that composing two functions is equivalent to mapping one over the other. Parting from this idea, the following is also correct:
const compose2 = (f, g) => g.map(f);
Again, you can extend this code to work with a list of functions (instead of only two) by using reduce:
const compose = (...fns) => fns.reduce(compose2);
By a similar reasoning, a correspondence exists that allows flatMap to become the basis of composing two monad-returning functions—in our case, Validation-returning functions. Using code to demonstrate this correspondence follows a similar train of thought of the buildup of compose in chapter 4 and the compose/map equivalence (section 5.3). I’ll spare you the details for the sake of brevity and focus on what’s important. An alternative to compose2 that works with monads, called composeM2, is implemented like this:
const composeM2 = (f, g) => (...args) => g(...args).flatMap(f);
As you can see, this implementation is similar to the map-based implementation of compose2. Because the functions in the pipeline are returning monad instances, flatMap is used to apply the function to the value and automatically flatten the container along the way. Finally, to support more than two functions, we do a similar reduction:
const composeM = (...Ms) => Ms.reduce(composeM2);
Don’t be concerned about understanding all the details or having to implement this code anew every time. Functional JavaScript libraries already have support for both types of composition; one works at a higher level of abstraction than the other. The gist is that you use compose to sequence the execution of functions that return unwrapped (simple) values and composeM for functions that return wrapped values (monads). That is why the former is based on map and the latter is based on flatMap.
Now that we’ve defined composeM, let’s put it to work. composeM orchestrates and chains the logic of each function, and Validation steers the overall result of the entire operation. With the right guardrails in place, you can sequence complex chains of code with automatic, built-in data validation along the way, as shown in the next listing.
Listing 5.22 Block validation with composeM
class Block {
//...
isValid() {
const {
index: previousBlockIndex,
timestamp: previousBlockTimestamp
} = this.#blockchain.lookUp(this.previousHash);
return composeM(
checkTimestamps(previousBlockTimestamp),
checkIndex(previousBlockIndex),
checkTampering,
Validation.of
)(Object.freeze(this));
}
}
There’s no need to test this logic again; you can do this on your own, following the previous examples. If you examine the structure of the composition part, you again see that it retains its point-free nature where all function arguments (except the curried ones) are not directly specified.
At this point, you’ve learned enough functional programming concepts that you can start taking advantage of this paradigm in your day-to-day tasks. Monads are not a simple concept to grok, and many books and articles teach it differently, but when you understand that behind the scenes, it’s all about map (which you do understand from working with arrays), things start to fall into place.
Let’s continue with our blockchain validation scenario. To recap, unlike regular data structures, a blockchain can’t be tampered with or altered in any way. Changing one block would involve recalculating the hashes of all subsequent blocks in the chain. This restriction also ensures that no one can dominate and re-create the entire history of the chain, which prevents the infamous 51% attack, because no single entity would be able to harness 51% of all the necessary computational power to run all these calculations:
Is the integrity of the chain intact, and does each block point to the correct previous block? (To check, we see whether the previousHash of the block equals the hash property of the block that went before it.)
Has the block’s data been tampered with? (To check, we recalculate the hash of each block. If something changed inside a block, the hash of that block changes.)
Is the length of the hash correct (using only 64-character-length hashes in this book)?
class Block {
...
isValid() {
const {
index: previousBlockIndex,
timestamp: previousBlockTimestamp
} = this.#blockchain.lookUp(this.previousHash);
return composeM(
checkTampering,
checkDifficulty,
checkLinkage(previousBlockHash),
checkLength(64),
checkTimestamps(previousBlockTimestamp),
checkIndex(previousBlockIndex),
Validation.of
)(Object.freeze(this));
}
The code in listing 5.22 executed only three validation rules. Observe how this code snippet shines when you scale out to many more rules. You can follow the implementation of each rule in the code accompanying this book. The thing to focus on here is how well-structured and readable the algorithm is. You’ll never sacrifice readability if you want to add even more rules. Point-free coding with monads truly resembles an assembly-line-style, embedded rules engine. This trade of semicolons for commas is the reason why monads are also called programmable commas.
Up until now, we’ve been able to validate only a single block instance. Fortunately, because our code is composable, we can validate any amount of objects needed. Blockchains store billions of objects. You can imagine the work involved in validating billions of these blocks. As you know, blocks contain transactions, which also need to be validated. For this book, it’s simple to think of a blockchain as being a list of lists (blocks with transactions), but in reality it’s a tree. All the elements of this tree need to be vertically traversed and validated. A single error should cause the entire process to halt (fail-fast).
In this section, you’ll learn that having a well-defined, composable interface allows you to reduce complex data structures easily.
To validate all the objects of a blockchain (the blockchain object itself, all its blocks, and all its transactions), we’ll use the HasValidation mixin and assign it to all the objects involved. The logic implemented by this mixin is used to traverse any object of a blockchain and validate its structure, as shown in figure 5.7.
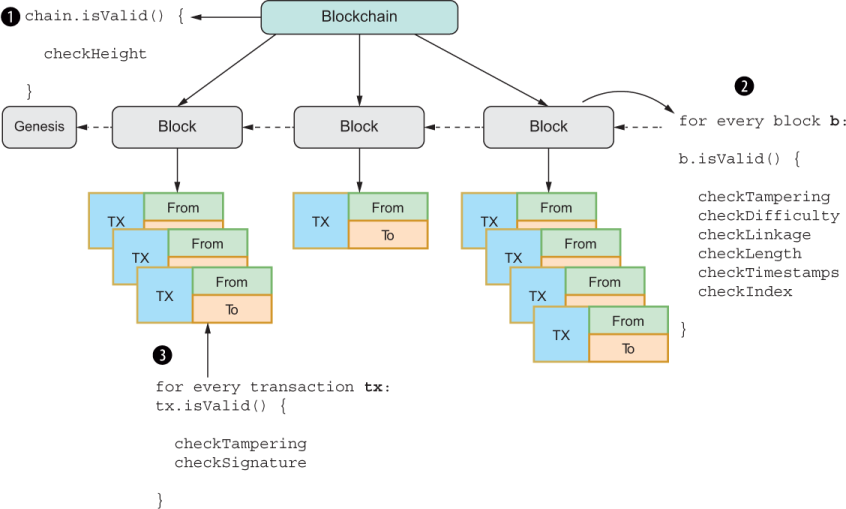
Figure 5.7 Traversing a blockchain’s objects, starting with the Blockchain object itself and moving down to each block’s transactions. You can think of the routine as forming a treelike structure, with the Blockchain object itself as the root, blocks as the second-level nodes, and transactions as the leaves of the tree.
HasValidation augments objects with a new API: validate. Also, HasValidationrequires that every element of the blockchain declare an isValid method (returning an object of type Validation, of course) that knows how to check itself. This interface is the minimal interface required.
isValid is in charge of implementing all the business rules pertaining to the object in question, as you saw with Block in section 5.5.6. The algorithm uses validate recursively and is designed to start verifying a blockchain from any node in the tree.
Before I outline the steps, let me prepare you for the code you’ll see in listing 5.23. Because we’re dealing with a tree-like structure, we’ll use recursion to traverse all its nodes. The first part of the algorithm involves enumerating the object by using the spread operator. Some built-ins are already iterable. We can enumerate all the values inside a map like this:
const map = new Map([[0, 'foo'], [1, 'bar']]); [...map.values()]; // ['foo', 'bar']) [...map.keys()]; // [0, 1])
With JavaScript, you can define how spread behaves in custom objects as well with a special property type known as Symbol.iterator. You may have played with or read code that uses symbols, which are quite powerful. I haven’t covered symbols yet or shown how iteration works; I cover these topics in detail in chapter 7. For now, when you see this idiom [...obj], think of it as returning an array representation of the object, hypothetically as obj.toArray().
Enumerate the object into an array. In the case of blockchain, this step returns an array with all its blocks. For block, it returns all its transactions.
Reduce the array of each object’s isValid result, starting from the object’s own isValid.
Return Validation.Success if all elements validate; otherwise, return Validation.Failure.
Listing 5.23 combines the techniques we’ve been learning about, such as flatMap and reduce, to determine whether all the elements in the chain are valid. Remember from chapter 4 that reduce is a way to think about composition, and by pairing it with flatMap, you achieve composition of objects, not functions. At each step, the algorithm spreads the object being validated (a block will return its list of transactions, for example); then it converts the list of objects to a list of Validation objects by using map. Finally, it uses flatMap as the reducer function to collapse the result to a single Validation object. Recursively, all the levels are collapsed into the final validationResult accumulator variable.
Listing 5.23 HasValidation mixin
const HasValidation = () => ({
validate() {
return [...this] ❶
.reduce((validationResult, nextItem) => ❷
validationResult.flatMap(() => nextItem.validate()),
this.isValid() ❸
);
}
});
❶ Invokes the object's [Symbol.iterator] to enumerate its state through the spread operator
❷ Reduces the result of all validation calls into a single one
❸ Begins with the result of checking the current object in question
Given everything that’s happening in listing 5.23, this algorithm is terse and compact. I’ll explain it again from the point of view of a reduction now that you’ve seen the code because recursion is hard to grok sometimes. Conceptually, you can think of validating an entire data structure as somehow reducing it to a single value. That’s happening here. reduce allows you to specify a starting value: the check of the object that starts validate. From that point on, you start composing a sequence of validation objects, one on top of the other. Then flatMap folds all the levels to a single value as it traverses down the tree.
One thing that might catch your attention is the arrow function passed to flatMap. Because we’re not interested in knowing which object is currently passing all checks, only that it did, we throw away the input argument. Validation is doing the heavy lifting of keeping track of the error details for us. If it detects an error, the underlying type internally switches from Success to Failure, records the error, and sidesteps the rest of the operations (flat-mapping failures on top of failures).
The downside of listing 5.23 is that it creates an array in memory at each branch of the blockchain. This code will not scale for real-world blockchains with billions of objects, however. In chapter 9, we’ll address this problem with a programming model that allows us to process infinite amounts of data.
Remember from chapter 3 that Blockchain, Block, and Transaction all implemented this mixin. Now you know how it works. Here’s the snippet of code that attaches this mixin to each of the main classes of our domain:
Object.assign( Blockchain.prototype, HasValidation() ); Object.assign( Block.prototype, HasHash(['index', 'timestamp', 'previousHash', 'data']), HasValidation() ); Object.assign( Transaction.prototype, HasHash(['timestamp', 'sender', 'recipient', 'funds', 'description']), HasSignature(['sender', 'recipient', 'funds']), HasValidation() );
Now that you understand how monads work, you’ve gained a universal vocabulary that allows you to easily integrate with any other code that understands it, including third-party code, and compose like-shaped code
If all the APIs we use spoke the same protocol, our job as developers would be much easier. Luckily, the universal functor and monad interfaces are well established and known, and are already ubiquitous in functional JavaScript libraries, but this is not the case for all aspects of software. In this chapter, I briefly mentioned Ramda and Crocks as being good functional libraries to use. You may have also seen, heard about, or even used Underscore.js or Lodash. These libraries are among the most-downloaded NPM libraries.
Ramda, for example, speaks the language of functors and monads by also following the fantasy-land definitions. The following listing shows how Validation integrates seamlessly with Ramda.
Listing 5.24 Integrating a custom Validation object with FP library Ramda
const R = require('ramda');
const { chain: flatMap, map } = R; ❶
const notZero = num => (num !== 0
? Success.of(num)
: Failure.of('Number zero not allowed')
);
const notNaN = num => (!Number.isNaN(num)
? Success.of(num)
: Failure.of('NaN')
);
const divideBy = curry((denominator, numerator) =>
numerator / denominator
);
const safeDivideBy = denominator =>
compose(
map(divideBy(denominator)),
flatMap(notZero),
flatMap(notNaN), ❷
Success.of
);
const halve = safeDivideBy(2);
halve(16); // Success(8)
halve(0); // 'Failure(Number zero not allowed)'
halve(0).getOrElse(0); // 0 ❸
❶ chain is an alias for flatMap. Ramda calls it chain.
❷ Ramda delegates to the functor’s flatMap, if present.
❸ Shows the default value feature of Validation
The function versions of map and flatMap imported from Ramda will delegate to the object’s map and flatMap, if present. This integration is possible because we’re abiding by the universal contracts that both require.
Under the hood, the version of map used here is implemented slightly differently from our implementation of map in the Functor mixin shown in listing 5.8:
const Functor = {
map(f = identity) {
return this.constructor.of(f(this.get()));
}
}
General-purpose third-party libraries such as Ramda expose curried, standalone functions that order arguments to facilitate composition. Those functions have a signature like function map(fn, F), where the functor F is the object being composed and chained with compose. We decided to use a mixin object, so in our case, F is implied and becomes this.
Alternatively, we could use JavaScript’s dynamic context binding capabilities to create our own extracted forms so that we can arrive at a similar experience as with a standalone implementation.
So far, we’ve made our objects functors and monads by assigning them the proper mixins. This isn’t the only way to use the Functor pattern. In this section, you’ll learn how you can extract a map method as a function that you can apply to any type of functor using dynamic binding.
You’re already aware that JavaScript makes it simple to change the environment or context that a function is bound to by using prototype methods bind, call, or apply. Given the Functor mixin, we can extract the map method with a simple destructuring assignment:
const { map } = Functor;
Using Function#call, we can call it on any functor like so:
map.call(Success.of(2), x => x * 2); // Success(4)
This example is close to a generalized function implementation of map like the one that ships with Ramda, except with reversed arguments. Calling methods this way can be a bit verbose, especially if you want to compose them together. Suppose that you want to combine Success.of(2) with a function that squares its value. Let’s follow this simple example:
map.call(map.call(Success.of(2), x => x * 2), x => x ** 2); // Success(16)
This style of writing code won’t scale, because as our logic gets more complicated, the code gets harder to parse. Let’s try to smooth it with a simple abstraction:
const apply = curry((fn, F) => map.call(F, fn));
This higher-order function both solves the argument order and uses currying to make composition better, which matches closely what you’d get from an external library:
apply(x => x * 2)(Success.of(2)); // Success.of(4)
Now we can compose functors without needing composeM:
compose( apply(x => x ** 2), apply(x => x * 2) )(Success.of(2)); // Success(16)
NOTE With regard to apply, another extension to monads, known as applicative monads, builds on functors to provide an interface to apply a function directly to a container, similar to what we did here. The method name usually is ap or apply. Applicatives are beyond the scope of this book, but you can learn more about them at http://mng.bz/OE9o.
These improvements are good ones, but it would be nice to be able to process ADTs fluently directly with our extracted map function without needing anything extra. A solution to this problem is in the works, and in the spirit of having fun with JavaScript, I will introduce you to the newly proposed bind operator (https://gitub.com/tc39/ proposal-bind-operator).
This proposal introduces the :: native operator, which performs a this binding (as the Function#{bind,call,apply} API would) in combination with method extraction. It comes in two flavors: binary and unary.
In binary form (obj :: method), the bound object is specified before the method:
Success.of(2)::map(x => x * 2); // Success(4)
Much as we do with the pipeline operator, we can now easily call a sequence of functor/ monadic transformations on an ADT:
Success.of(2)::map(x => x * 2)::map(x => x ** 2); // Success(16)
Here’s a refactored version of the Ramda code snippet from section 5.5.8 that removes the dependency on this library:
const { flatMap } = Monad;
const safeDivideBy = denominator => numerator =>
Success.of(numerator)
:: flatMap(notNaN)
:: flatMap(notZero)
:: map(divideBy(denominator));
const halve = safeDivideBy(2);
halve(16); // Success(8)
You may also find the bind operator in unary form (::obj.method). Suppose that you want to pass a properly bound console.log method as a callback function. You could use ::console.log, as in
Success.of(numerator)::map(::console.log);
const MyLogger = {
defaultLogger: ::console.log
};
class SafeIncrementor {
constructor(by) {
this.by = by;
}
inc(val) {
if (val <= (Number.MAX_SAFE_INTEGER - this.by)) {
return val + this.by;
}
return Number.MAX_SAFE_INTEGER;
}
}
SafeIncrementor is used to safely add to an integer without risking overflow or misrepresentation. If you wanted to run this operation over an array of numbers, you would have to set the proper bind context so that the incrementor remembers what this.by refers to using Function#bind:
const incrementor = new SafeIncrementor(2); [1, 2, 3].map(incrementor.inc.bind(incrementor)); // [3, 4, 5]
With the bind operator in unary form, this code reduces to
[1, 2, 3].map(::incrementor.inc); // [3, 4, 5]
Both options work in much the same way. The bind operator creates a bound function to the object on the left or the right side of the operator. See appendix A for details on enabling this feature with Babel.
In this chapter, we explored the functor and monad patterns by writing our own ADT. Validation is not the only ADT; many others exist. In fact, Haskell programs execute completely wrapped in the context of an I/O monad so that you can do simple things such as write to standard out in a side-effect-free way. ADTs are simple yet powerful tools. They allow you to represent everyday common tasks in a composable manner. After reading this chapter, you know to never use your data naked. When you want to apply functions in a more robust way, try wrapping them inside a container.
In this chapter, we implemented Validation from scratch, but many ADTs are widely used in practice. They are becoming so widespread that you can find them all as userland libraries and frameworks. Some have even evolved into new additions to a language. JavaScript will meet both of these cases with Promise (first a library, now a native API) and then Observable (chapter 9). Although Promises do not abide by the same universal interface, they behave like one, as you’ll learn in chapter 8.
By understanding the basic concepts of ADTs, you have a stronger grasp of how these APIs work. Composable software doesn’t involve code alone; it also involves the platform. JavaScript’s revamped module system is the Holy Grail of composition and the subject of chapter 6.
Wrapping bare data inside a mappable container provides good encapsulation and immutability.
JavaScript provides an object-like façade for its primitive data types that preserves their immutability.
Array#{flat, flatMap} are two new APIs that allow you to work with multidimensional arrays in a fluent, composable manner.
An ADT can be classified by how many values it can support (record or choice) and by the level of composability (functor or monad).
Functors are objects that implement the map interface. Monads are objects that implement the flatMap interface. Both support a set of mathematically inspired protocols that must be followed.
Validation is a composite choice ADT modeling Success and Failure conditions.
Whereas compose is used for regular function composition, composeM is used for monadic, higher-kinded composition.
By implementing the universal protocols of Functor and Monad, you can integrate your code easily and seamlessly with third-party FP libraries.
Use the newly proposed pipeline operator to run sequences of monadic transformations in a fluent manner.