If you want to see which features will be in mainstream programming languages tomorrow, then take a look at functional programming languages today
If objects are the fabric of JavaScript, functions represent the needles used to thread the pieces together. We can use functions in JavaScript to describe collections of objects (classes, constructor functions, and so on) and also to implement the business logic, the machinery that advances the state of our application. The reason why functions are so ubiquitous, versatile, and powerful in JavaScript is that they are objects too:
Function.prototype.__proto__.constructor === Object;
JavaScript has higher-order or first-class functions, which means you can pass them around as arguments to another function or as a return value. With higher-order functions, you can dramatically simplify complex patterns of software to a handful of functions, making JavaScript a lot more succinct than other mainstream languages such as Java and C#.
In chapter 3, we looked at how objects compose their structure to some extent using OLOO and more fully using mixins. Higher-order functions compose too—not structurally, but behaviorally, by being chained together and passed around as callbacks to represent sequences of computational logic. Higher-order functions are JavaScript’s most powerful features by far, and the best way to learn about them is through the functional programming (FP) paradigm.
FP is a force to be reckoned with. These days, it’s almost impossible to read about the wonders of JavaScript without seeing a shout-out to FP. I think JavaScript has continued to flourish thanks to its FP support, which is one of the things that drew me toward JavaScript many years ago. Although, theoretically, FP is an old school of thought, it’s become pervasive recently in JavaScript coding and application design. Good examples are libraries such as Underscore and Lodash for processing data, React and Hooks for building modern UIs, and Redux and RxJS for managing state. In fact, if you look at 2019’s State of JavaScript results for most-used utility libraries (https://2019.stateofjs .com/other-tools/#utilities), you will find Lodash, Underscore, RxJS, and Ramda ranking at the top. All these libraries enhance the functional capabilities of JavaScript.
Fundamentally speaking, FP promotes a different approach to problem solving from the more common structured or imperative way to which we’re all accustomed. Wrapping your head around FP requires a mastery of JavaScript’s main unit of computation, which has always been functions. Any type of object definition tries to associate the data (instance fields) with the logic (methods) that process that data. Objects compose at a coarse-grained level, as you learned about in chapter 3. Functions, on the other hand, separate data (arguments) and logic (function body) more distinctly and compose at a more fine-grained, lower level. FP programs are made up of a set of functions that receive input and produce a result with this data.
In this chapter, we’ll take two important parts of our blockchain application and improve them by using FP. The goal is not a complete redesign of the application. Rather, we’ll keep things simple and take a more lenient approach that combines the benefits of OO and FP paradigms together—aka a hybrid model. You’ll learn that although imperative and FP disagree on fundamental principles, you can benefit from their strengths when tackling different parts of your application. To help you transition to an FP way of coding, we’ll visualize how an imperative program is converted to a functional one (section 4.2).
Unless you’re an expert, I recommend that you start by slowly adopting the basics of FP covered in this chapter and then finding ways to embed FP in your application. Later, how far you want to take this paradigm in your own code is up to you. Core business logic is usually a good candidate for this way of thinking. We’ll go through the exercise of refactoring some imperative code into functional so that you can get a sense of how these two kinds compare.
It’s been a noticeable trend for a few years now that platform teams, including JavaScript, are adding more features to their programming languages to support a functional style. ECMAScript 2019 (aka ES10), for example, added Array.prototype .{flat,and flatMap}, which are integral to using data structures in a functional way. As of this writing, the road map for TC39 features a set of functional-inspired proposals moving up the ranks that will affect how you write JavaScript code in the years to come. So learning about this paradigm now will prepare you for what’s ahead. In this book, we’ll be looking at the
Pipeline operator (https://github.com/tc39/proposal-pipeline-operator)
Bind operator (https://github.com/tc39/proposal-bind-operator)
We still have a way to go before we understand why these features are so important. Understanding these features begins with understanding functional programming.
In this section, I’ll provide a suitable definition of FP. First, I’ll show you a short example and go over some of the basic qualities of functional code. Many people relate FP to the array APIs map, reduce, and filter. You’ve probably seen these APIs in action many times. Let’s start with a quick example to jog your memory: determine whether all block objects in an array are valid. For this example, you can assume that you can skip validating the genesis block and that all blocks have an isValid method. Implementing this logic by using the array APIs would look like the next listing.
Listing 4.1 Combining map, filter, and reduce
const arr = [b1, b2, b3]; arr .filter(b => !b.isGenesis()) ❶ .map(b => b.isValid()) ❷ .reduce((a, b) => a && b, true); ❸
❶ Skips the genesis block (which is always assumed to be valid)
❷ Converts the array of blocks to an array of Boolean values by calling isValid on each block
❸ Performs a logical AND of all the Boolean values together, parting from true, to obtain the final result
As you know, these array APIs were designed to be higher-order functions, which means that they either accept a callback function or return one and delegate most of the logic to the callback function you provide. You’ve probably written similar code before but never thought about it from an FP point of view. An FP-aware programmer always prefers writing code that is heavily driven by higher-order functions this way.
Aside from the tendency to use functions for almost anything, another important quality of FP programs is immutability. In listing 4.1, even though arr is being mapped over and filtered, the original arr reference is kept intact:
console.log(arr); // [b1, b2, b3]
Code that is immutable avoids bugs that arise from inadvertently changing your application’s state, especially when you deal with asynchronous functions that can run at arbitrary points in time. Did you know that methods such as reverse and sort mutate the array in place? What would happen if you passed that original array object to some other part of your program? Now the result is unpredictable.
An immutable function that always returns a predictable result, given a set of arguments, is known as pure, and with that definition, we arrive at the definition of FP:
Functional programming is the art of composing higher-order functions to advance the state of a program in a pure manner.
So far, I’ve talked a little about composition and pure code. FP takes these ideas to the practical extreme. Now I’ll unpack the key parts of the definition of FP:
As you know by now, a higher-order function is one that can receive a function as a parameter or produce another function as a return value. With FP, you use functions for pretty much anything you do, and your program becomes one big assembly of functions glued together by composition.
Pure functions compute their results based entirely on the set of input arguments received. They don’t cause side effects—that is, they don’t rely on accessing any outside or globally shared state, which makes programs more predictable and simple to reason about because you don’t have to keep track of unintended state changes.
FP developers use functions to represent any type of data.
You can use functions to represent data in the form of expressions. Expressions can be evaluated to produce a value right away or passed to other parts of your code as callbacks to be evaluated when needed. Here are a few examples:
const fortyTwo = () => 42;
As with regular constants, you can assign an expression to a variable or pass it as a function argument.
Echo the same value, also known as the identity function:
const identity = a => a;
Create new objects or implement arbitrary business logic:
const BitcoinService = ledger => { ... };
This function is known as a factory function, which always produces a new object.
Encapsulated, private data (closure):
const add => a => b => a + b;
a is stored as part of the outer function’s closure and referenced later in the internal function when the entire expression is evaluated:
add(2)(3) === 5
NOTE The arrow function notation used here is syntactically convenient to embed in fluent method chains, such as when you code with map, filter, reduce, and others or when you need an one-line expression. Although this chapter uses this notation often because of its terse design, regular function syntax is equally appropriate for all these examples.
All these expressions (except the first one) receive input and return output. The return value of a pure function is always a factor of the input it receives (unless it’s always a constant); otherwise, the implication is that you’ve somehow opened the door to side effects and impure code.
Listing 4.2 shows a simple, naïve example that illustrates combining some of these expressions, which contain computation or data, as higher-order functions. The code attempts to perform some mathematical operation only if conditions allow; otherwise, it returns a default value.
Listing 4.2 Combining higher-order functions
const notNull = a => a !== null; ❶ const square = a => a ** 2; const safeOperation = (operation, guard, recover) => ❷ input => guard(input, operation) || recover(); const onlyIf = validator => (input, operation) => ❸ validator(input) ? operation(input) : NaN; const orElse = identity; ❹ const safeSquare = safeOperation( ❺ square, onlyIf(notNull), orElse(fortyTwo) ); safeSquare(2); // 4 safeSquare(null); // 42
❶ Checks whether a value is not null
❷ Executes a safe operation; otherwise, calls a recovery function
❸ Runs operation only if the validator function returns true; otherwise, returns NaN
❹ Uses the identity function as recovery, aliased under the name orElse
❺ Computes the square of a number if the input is not null; otherwise, recovers with the value 42
If you look at the structure of safeSquare, notice that it’s made up of functions that clearly communicate the intent of the program. Some of these functions carry only data (orElse); other functions carry out a computation (square); some functions do both (onlyIf). This listing gives you a good first look at code done the functional way.
As the saying goes, less is more. The functional paradigm imposes restrictions that are meant not to diminish what you can do, but to empower you. In this section, you’ll look at a set of guidelines that help you code the functional way. In section 4.3.2, you’ll learn how to work with these guidelines to tackle any type of problem.
An FP programmer always codes with a certain set of rules in mind. These rules can take some getting used to but become second nature with practice. Learning them will be well worth your time, however, because you’ll end up with code that is more predictable and simpler to maintain.
The functional way in JavaScript involves these four simple rules:
Functions must always return a value and (with a few exceptions) declare at least one parameter.
The observable state of an application before and after a function runs does not change; it’s immutable and side-effect-free. A new state is created each time.
Everything a function needs to carry its work must be passed in via arguments or inherited from its surrounding outer function (closure), provided that the outer function abides by the same rules.
A function called with the same input must always produce the same output. This rule leads to a principle known as referential transparency, which states that an expression and its corresponding value are interchangeable without altering the code’s behavior.
With these simple rules, we can remove side effects and mutations from your code, which are one of the leading causes of bugs. When a function obeys all these rules, it is said to be pure. Sound simple enough? To rephrase, FP is the art of combining functions that play by these rules to advance the state of a program to its final outcome.
According to these rules, how is something like printing to the console pure? It’s not. Functions that reach out of their scope, to perform I/O in this case, are effectful —that is, they cause a side effect. Side effects can also include functions that read/write to variables outside their own scope, accesses the filesystem, writes to a network socket, relies on random methods such as Math.random, and so on. Anything that makes the outcome of a function unpredictable is considered bad practice in the FP world.
But how can anything useful come out of functional coding when we can’t touch all the things that mutate the state of our program? Indeed, working with immutable code requires a different mindset and, in some cases, a different approach to a problem, which is the hardest part. With FP, objects shouldn’t be manipulated and changed directly. A change to an object means that a new one is always created, similar to version control, in that every change, even in the same line, results in a new commit ID. With respect to reading files, printing to the console, or any other practical real-world task, we need to learn to deal with these cases in a practical way.
So far, we’ve been talking about FP at a high level. To make this discussion more concrete, section 4.2 compares functional and imperative code.
So that you can begin to wrap your head around this paradigm shift, it’s best to tackle a couple of problems. We’ll quickly go over the techniques needed to implement this shift throughout the chapter so that you get an end-to-end view of using FP in JavaScript.
The first problem we’re tackling in this chapter is a functional way to implement the logic behind calculating hashes. Here, we will swap the insecure algorithm for a secure implementation of the HasHash mixin logic. This implementation will be a good warmup for our second example, which involves calculating the balance of a user’s digital wallet by using only pure functions. In the latter exercise, we will see a complete refactoring of imperative code into functional. The balance calculation involves processing all the blocks from the public ledger and tallying all the transactions that refer to a specific user. If the user appears as the recipient, we add funds; otherwise, we subtract funds.
To give you a frame for comparison, the imperative version of our second problem looks something like the following:
function computeBalance(address) {
let balance = Money.zero();
for (const block of ledger) {
if (!block.isGenesis()) {
for (const tx of block.data) {
if (tx.sender === address) {
balance = balance.minus(tx.funds);
}
else {
balance = balance.plus(tx.funds);
}
}
}
}
return balance.round();
}
You’ll learn how to transition this version into a more functional style, like so:
const computeBalance = address =>
compose(
Money.round,
reduce(Money.sum, Money.zero()),
map(balanceOf(address)),
flatMap(prop('data')),
filter(
compose(
not,
prop('isGenesis')
)
),
Array.from
);
You’re probably wondering whether these two programs are the same: the first version has loops and conditionals, and the second one doesn’t. Shockingly, the programs are the same. You probably recognize some of the constructs in this code block, such as map and filter, but how this code works may not be clear, especially because the control and data flow is in the opposite direction of its imperative counterpart. The rounding instruction appears at the top rather than at the end, for example.
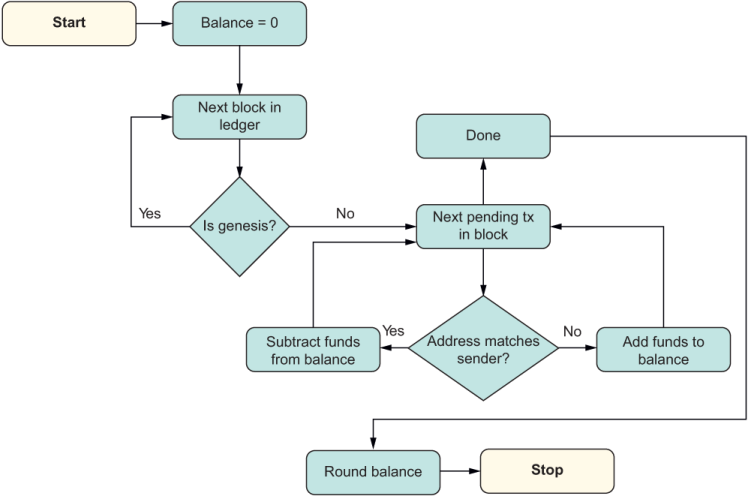
Looking at the FP style again, you may also wonder where the tallying of the total is taking place. Compare figures 4.1 and 4.2 to see the different control and data flows of the imperative and functional approaches.
Listing 4.1 Imperative flow of control for the logic in calculating a user’s total balance in a blockchain
The imperative approach (figure 4.1) describes not only the changes in state, but also how this change is produced as data flowing through all the control structures (loops, conditionals, variable assignment, and so on). The functional approach (figure 4.2), on the other hand, models a unidirectional flow of state transformations that hides the intricate control details; it shows you the steps needed to obtain the final result without all the unnecessary cruft. Also, each step is immutable, as mentioned earlier, which allows you to laser-focus on any of them without having to worry about the rest (figure 4.2).
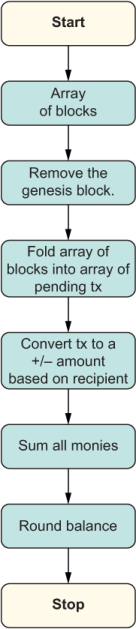
Listing 4.2 Functional flow of control for the logic in calculating a user’s total balance in a blockchain
Figure 4.2 is modeling a declarative flow. Think of this figure as being like summarizing the highlights of the imperative version in the form of a recipe. Declarative code is written to match how it will be read. Write code for your users and colleagues, not for the machine, that’s what compilers are for.
A good example of a declarative language is SQL. In SQL, the beauty of declarative programming is that it focuses on what you’re trying to accomplish rather than how, so mundane details such as code splitting, looping, and state management are tucked inside their respective steps. The hardest part about embracing FP is letting go of your old ways and your imperative bias. After you cross this line, you start to see how the structure, readability, and maintainability of your code improve, especially in JavaScript, which gives you the freedom to mutate data in many ways. We’re fortunate that JavaScript allows us to write code this way, and we should take advantage of it.
To embrace the FP mindset, you must understand function composition, discussed in the next section.
Generally speaking, composition occurs when data combines to make like-data or data of the same type; it preserves type. Objects fuse into new objects (like the mixins from chapter 3), and functions combine to create new functions (like the functions in this chapter). When mixins create new objects, this process is known as coarse-grained, structural composition. This section teaches you how to assemble code at the function level, known as fine-grained or low-level composition.
Function composition is the backbone of functional programming, and it’s the guiding principle by which you arrange and assemble your entire code. Although JavaScript doesn’t enforce any restrictions, composition is most effective when your functions play by the rules of purity mentioned in section 4.1.2.
In this section, we’ll implement the business logic of the HasHash mixin. First, you’ll learn how to convert the imperative calculateHash method we started in chapter 2 to use a more functional style. We’ll use this method to fill in the skeleton implementation we started in chapter 3. Second, you’ll learn how composition can help you work around code that has side effects. This capability is important because most of the time, you will need to mix pure code with effectful code in your daily activities.
The best way to understand how functions compose is to start small, with only two functions, because then that same logic can be extended to an arbitrary number of them. So given the functions f and g, you can order them in a such a way that the output of the first becomes the input of the second, like binary plumbing, as shown in figure 4.3.

Listing 4.3 High-level diagram of composition. The directions of the arrows are important. Composition works right to left. So in f composed with g, g receives the initial input arguments. Then g’s output is input to f. Finally, f’s result becomes the output of the entire operation.
In code, composition can be represented concisely by f(g(args)). Because JavaScript executes eagerly, it will try to evaluate any variable with a set of parentheses in front of it immediately. If you want to express the composition of two functions and assign it to a variable name, you can wrap a function around that expression. Let’s call this expression compose (see the next listing).
Listing 4.3 Composition of two functions
const compose = (...args) => f(g(...args)); ❶
❶ Using JavaScript’s spread operator to support an arbitrary number of arguments
Listing 4.3 assumes, however, that f and g are functions that exist outside the context of compose. We know that this situation is a side effect. Instead, make f and g input arguments, and use the closure around the inner function so that this code works with any two functions that you provide. Closures are important features that work amazingly well with higher-order functions; I’ll review them in section 4.4.
Let’s wrap this expression yet again with another function around compose and call it compose2:
const compose2 = (f, g) => (...args) => f(g(...args))
This code is a lot more flexible. Because compose2 accepts functions as arguments and returns a function, it’s of higher-order, of course. Also, notice that compose2 evaluates the functions right to left (f after g) to align with the mathematical definition of function composition. Here’s a more-concrete example:
const count = arr => arr.length; const split = str => str.split(/\s+/);
You could combine these functions directly:
const countWords = str => count(split(str));
When you use compose2, the same expression becomes
const countWords = str => compose2(count, split)(str);
Here’s a little pro tip. Because you can assign functions directly to a variable, any time you have the input argument repeated to the left and the right of an expression, you can cancel it and make your code more compact:
const countWords = compose2(count, split);
countWords('functional programming'); // 2
Figure 4.4 shows the flow from figure 4.3.

Listing 4.4 Sequentially executed count after split
compose2 is superior to a direct call because it’s able to separate the declaration of functions involved in the sequence from its evaluation. The concept is similar to OLOO, which allows you to instantiate a ready-to-use set of objects and initialize those objects when you need to. By capturing the functions passed in as variables (f and g), we can defer any execution until the caller supplies the input parameter. This process is called lazy evaluation. In other words, the expression
compose2(count, split);
is itself a function made from two other functions (like an object made from two mixins). Yet this function will not run until the caller evaluates it; it sits there dormant. compose2 allows you to create a complex, ready-to-use expression from a couple of simple ones and assign it a name (countWords) to use in other parts of the code, if needed. Let’s embellish this example a bit more in the next section; we’ll tackle something a bit more realistic that works in a side effect in the mix.
Exception handling, logging to a file, and making HTTP requests are some of the tasks we work on every day. All these tasks involve side effects in one way or another, and there’s no avoiding them. The way to deal with side effects in a functional-style application is to isolate and push them away from our main application logic. This way, we can keep the important business logic of our application pure and immutable, and then use composition to bring all the pieces back together.
To see how you can split pure from non-pure code, let’s tackle another task: counting the words in a text file. Assume that the file contains the words “the quick brown fox jumps over the lazy dog.” For simplicity, let’s use the synchronous version of the filesystem API built into Node.js, as shown in the next listing.
Listing 4.4 Imperative function that counts the words in a text file
function countWordsInFile(file) {
const fileBuffer = fs.readFileSync(file);
const wordsString = fileBuffer.toString();
const wordsInArray = wordsString.split(/\s+/);
return wordsInArray.length;
}
countWordsInFile('sample.txt'); // 9
Listing 4.4 is trivial but packs in a few steps. As in calculateHash, you can identify four clear tasks: reading the raw file, decoding the raw binary as a string, splitting the string into words, and counting the words. Arranging these tasks with compose should look like figure 4.5.

Listing 4.5 The logic of countWordsInFile derives from the logic of composing other single-responsibility functions such as read, decode, split, and count.
First, represent each task as its own expression. You saw count and split earlier; the next listing shows the other two tasks.
Listing 4.5 Helper functions to support countWordsInFile
const decode = buffer => buffer.toString();
const read = fs.readFileSync; ❶
❶ Creating an alias to shorten the filesystem API call
In listing 4.5, we gave each variable a specific name to make the program easy to follow. In imperative code, variable names are used to describe the output, if any, of executing a statement or series of statements, but these variable names don’t describe the process of computing them. You have to parse through the code to see that process. When you push for a more declarative style, the function names indicate what to do at each step. Let’s work our way there. A direct call would look like
const countWordsInFile = file => count(split(decode(read(file))));
You can see that all variable assignment was removed. But we can agree that this style of code can become unwieldy as complexity grows. Let’s use compose2 to fix this problem:
const countWordsInFile = compose2( compose2(count, split), compose2(decode, read) );
Each compose2 segment can be represented by its own micro module, as shown in figure 4.6.
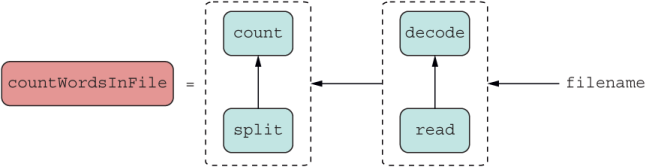
Listing 4.6 Diagram countWordsInFile improved with compose2
But wait a minute—we already have a named abstraction that handles compose2(count, split). That abstraction is called countWords. Let’s plug it in:
const countWordsInFile = compose2( countWords, compose2(decode, read) );
The reason why you can swap portions of the code in and out like Lego bricks is referential transparency. In other words, the expression is pure and doesn’t rely on any global, shared state. The outcome of either expression would be the same and, therefore, does not alter the result of the program. Plugging in this abstraction is better, but we can do even better.
For more complex logic, you’re probably thinking that grouping functions in pairs is a lot of typing. To simplify the code, it would be ideal to have a version of compose2 that can work on any number of functions or an array of functions. Let’s repurpose compose and use Array#reduce with compose2 to extend combining two functions to any number of functions. This technique is analogous to putting together clusters of Lego bricks at a time instead of assembling individual bricks.
In Array#reduce, the reducer is the callback function that accumulates or folds your data into a single value. If you’re not familiar with how reduce works, here’s a simple example. Consider a function, sum, as a reducer for adding a list of numbers:
const sum = (a,b) => a + b; [1,2,3,4,5,6].reduce(sum); // 21
The reducer takes the current accumulated result in a and adds it to the next element, b, starting with the first element in the array.
By the same token, compose2 is the reducer for compose:
const compose = (...fns) => fns.reduce(compose2);
In this case, the reducer takes two functions at a time and composes them (adds them), creating another function. That function is remembered for the next iteration and then composed with the next one and so on, resulting in a function that is the composition of all functions provided by the user. Function composition works right to left, with the rightmost function receiving the input parameter at the call site and kicking off the entire process. In that order, reduce folds all the functions in the array with the first function in the declaration as the last one to be executed, which matches nicely with the definition of function composition.
Now let’s use this technique in the next listing to peel those nested calls shown in the preceding code snippets into a much more streamlined, unidirectional flow.
Listing 4.6 countWordsInFile implemented with compose
const countWordsInFile = compose(
count,
split,
decode,
read
);
countWordsInFile('sample.txt'); // 9
This code looks like pseudocode at first, doesn’t it? If you compare listings 4.4 and 4.6, you can see that the latter is a basic outline of the former; it’s declarative! This style of coding is also known as point-free, which we’ll discuss in section 4.6.
The level of modularity used (fine-grained function level or coarse-grained modules with multiple functions) is up to you; you can compose to your heart’s content (figure 4.7).

Listing 4.7 The structure of composable software. A program is implemented by composing other subprograms, which can be as small as a function or as big as another program. Each module (consider Module N) uses composition, finally arriving at assembling individual functions.
Whether you’re composing simple functions or entire modules of code with a function interface, the simplicity of assembling composable code doesn’t change. (We’ll talk about importing and using modules in chapter 6.)
Now that you understand the composition pattern, let’s use it to decompose and simplify the hashing logic of our blockchain application.
In chapters 2 and 3, we began creating a hashing method for our transaction classes called calculateHash. This hashing algorithm, or the digest string that it generated, was insecure and prone to collisions. In the cryptocurrency world, this situation is a no-go, so let’s improve it. You’ll see how a more functional design will enable you to easily swap the insecure algorithm for a more secure one that uses Node.js’s crypto module. Here’s the last version of that code again for reference:
const HasHash = keys => ({
calculateHash() {
const data = keys.map(f => this[f]).join('');
let hash = 0, i = 0;
while (i < data.length) {
hash = ((hash << 5) - hash + data.charCodeAt(i++)) << 0;
}
return hash**2;
}
});
Using the four rules outlined earlier in section 4.1.2, is this function/method pure? Before answering this question, let’s practice a little reverse engineering. First, let’s decompose the function into its main parts; then we’ll analyze each piece individually. When we split the function apart, we’ll compose it back together by using a more functional approach. With lots of practice, you’ll get better at this process, which will become second nature.
calculateHash performs two main tasks, split into two methods:
Assembling the data from the set of keys:
function assemble(keys) {
return keys.map(f => this[f]).join('');
}
Computing the digest or cipher from this data:
function computeCipher(data) {
let hash = 0, i = 0;
while (i < data.length) {
hash = ((hash << 5) - hash + data.charCodeAt(i++)) << 0;
}
return hash**2;
}
This thought process itself is beneficial because smaller functions are much simpler to reason about than larger ones, and you can carry this thought process as deep as you deem reasonable. Now to answer the question at hand: Are these two methods pure? Believe it or not, computeCipher is pure from a practical standpoint, whereas assemble is not. The reason is that assemble makes assumptions about its context when it attempts to read properties from this—a potential downside of mixins that we highlighted in chapter 3. With a standalone function declaration, this is bound to the function, not the surrounding object. To fix this problem, we can use JavaScript’s dynamic binding:
const HasHash = keys => ({
calculateHash() {
return compose2(computeCipher, assemble.bind(this, keys))();
}
});
The call to bind will correct the this reference and point it to the surrounding object whose properties we want to read. This code is looking better, but relying on this type of binding can make it hard to follow. Also remember that making assumptions about the environment is a side effect, which we still have in calculateHash. To put it another way, a function that infers state is harder to work with because its own behavior is dependent on external factors. For that reason, you’ll never see references to external variables, including this, used in a pure FP code base. On the other hand, functions that are explicit about the data they need are self-documenting and, thus, simpler to use and maintain.
Let’s change assemble to a function that is explicit about its contract and accepts the set of keys for the properties used in the hashing process, as well as the object to hash:
function assemble(keys, obj) {
return keys.map(f => obj[f]).join('');
}
By not making any assumptions, this generic, standalone function is completely divorced from its surrounding class or object context. The fine line in the sand where OO departs to FP in a hybrid model is where we disassociate or extract the code under a class’s methods and move it into one or more pure functions. This separation or segregation from the mutable, stateful components to immutable ones will help you avoid making assumptions about your data and use FP where it makes sense.
Let’s come back to computeCipher, the heart of the hashing process. Earlier, I mentioned that in by-the-book functional programming, mutations are prohibited. In practice, though, we accept making code easier to implement as long as state changes don’t ripple out or leak from the function’s scope. In this case, all the mutations are kept locally, so the code is acceptable as is.
Nevertheless, computeCipher doesn’t capture the true functional spirit; it still feels a bit procedural. By inspecting computeCipher as its own microenvironment, you can see that its logic still depends on setting and changing variables like the loop counter i and the accumulated hash. You have room for improvement. Working with lists and arrays is simple with APIs such as map and reduce, but when you need to keep track of and reuse state in an iterative manner, recursion is the best way to achieve your goal. The next listing shows how you can refactor the while loop as a recursive function.
Listing 4.7 Refactoring computeCipher as a recursive function
function computeCipher(data, i = 0, hash = 0) {
if(i >= data.length) {
return hash ** 2;
}
return computeCipher( ❶
data,
i + 1,
((hash << 5) - hash + data.charCodeAt(i)) << 0
);
}
❶ Calls itself recursively with the updated hash at each iteration as an input argument to avoid assigning and changing data in place
This function brings us back to our four main FP rules, without any trade-offs, and here’s what we gained:
We used JavaScript’s default argument syntax to capture the initial state properly.
We created expressions in which every branch produces a return value.
Now that we have these two smaller, simpler functions, we can compose them to compute the cipher of a transaction object:
calculateHash() {
return compose2(computeCipher, assemble(keys, this))();
}
But wait a second—we have a problem. compose2 expects a function but instead got a string when assemble ran, so this code fails to run. Let’s use lazy evaluation to make a small adjustment to assemble, turning it into a higher-order function that accepts the keys and returns a function that is ready to receive the object of the call, taking advantage of closures:
function assemble(keys) {
return function(obj) {
return keys.map(f => obj[f]).join('');
}
}
This small adjustment is enough to get to our more functional approach:
const HasHash = keys => ({
calculateHash() {
return compose2(computeCipher, assemble(keys))(this);
}
});
In essence, what we did to assemble was convert a 2-arity (two-argument) function to two single-arity (single-argument) functions—the premise behind a technique called curried function evaluation.
Currying is a technique that will help you compose functions when they require multiple arguments. It relies on JavaScript’s amazing support for closures. In this section, we’ll begin with a quick review of closures and then move on to curried function application.
You are probably familiar with closures, which are central to how JavaScript works. In fact, they’re among the most compelling JavaScript features. To keep the discussion focused, I won’t cover closures in depth but will provide some detail in case you’re not familiar with them.
A closure is another form of scope or context created around functions that allows a function to reference surrounding variables. When a function is called, JavaScript retains references to variables of a function’s local and global lexical environment—that is, all variables syntactically declared around this function. In the specification, the internal reference [[Scope]] links a function to its closure. In other books and online resources, you may see the term backpack used to describe this linkage. The reason I say around and not before is because hoisted variables and functions are also part of a function’s closure. The following listing provides an example.
Listing 4.8 Basics of scope with closures
const global = 'global';
function outer() {
const outer = 'outer';
function inner() {
const inner = 'inner'
console.log(inner, outer, global); ❶
}
console.log(outer, global); ❷
inner();
}
outer();
You can visualize this example in figure 4.8.
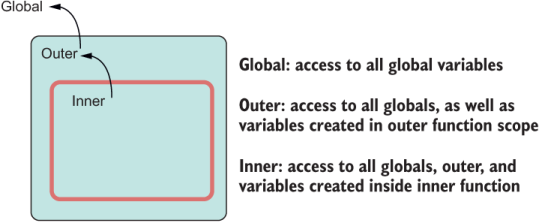
Listing 4.8 The closure mechanism in JavaScript allows any function to reference its lexical environment. The innermost function has access to all the state from its outer scopes (outer + global), and the outer scope can access everything from its surrounding global scope.
JavaScript gives you complete freedom to access a sizeable subset of application state from which a function is declared, implying the global scope as well as any outer variables that lexically appear around a function. In essence, closures make all this state implicit function arguments. Although access to these variables is certainly convenient at times, it can also lead to code that is hard to maintain. Theoretically, FP considers accessing any state surrounding a function to be a side effect; after all, we’re reaching outside. In practice, however, using closures is permissible so long as they are bounded and narrow in scope and, more important, don’t incur any observable changes beyond the surrounded function. Using closures is the way to code with JavaScript, and we should take advantage of them. Closures enable some powerful patterns in JavaScript, currying being one of them.
A function that has its argument list expanded as stepwise, single, nested functions of single arguments is said to be curried. The next listing shows a simple example of manual currying.
Listing 4.9 Evaluating add as separate single-argument functions
const add = x => y => x + y; const addThreeTo = add(3); ❶ addThreeTo(7); // 10 ❷
❶ Addition does not take place until the last variable is bound.
❷ Bind the expression, and the function executes.
Instead of add receiving x and y arguments in one shot, the code accepts them as singular functions that get called sequentially. More formally, currying is the process of converting a function of multiple arguments (or arity N) to be evaluated it as N unary (arity 1) functions. Until the entire list of arguments has been provided and all functions evaluated, a curried function always returns the next function. If you take a small step back, you can see that currying is another form of composition: you’re taking a complex function and evaluating it as multiple simple ones. Because add takes two arguments, x and y, it’s evaluated as two single-argument functions:
add(3)(7); // 10
Going back to our word-counting example, let’s use this manual currying technique to buy more flexibility in decoding the binary buffer as a result of the file IO. As decode stands right now, the toString method on buffers assumes a UTF-8 encoding:
const decode = buffer => buffer.toString();
Most of the time, this method is what you’ll want to use. But it’d be nice to have flexibility in case we ever need ASCII encoding as well. Instead of refactoring decode to accept another argument, let’s embed another function in between to capture the encoding parameter (with its own default argument):
const decode = (encoding = 'utf8') => buffer => buffer.toString(encoding);
Now we can call decode once to partially curry/set the encoding parameter and plug the resulting (remaining) function into the compose expression as such:
const countWordsInFile = compose(
count,
split,
decode('utf8'),
read
);
The declarative quality of this code is enhanced even further because you can see not only the steps that make up your solution, but also the attributes or the configuration of these functions in each step.
Let’s continue working our way toward calculating secure object hashes in a functional way. Consider a helper function called prop, again manually curried:
const prop = name => obj => obj[name] && isFunction(obj[name]) ? obj[name].call(obj) : obj[name];
const isFunction = f =>
f
&& typeof f === 'function'
&& Object.prototype.toString.call(f) === '[object Function]';
prop can access a property from any object by name. You can partially bind the name parameter to create a function with the name in its closure and then accept the object from which to extract the named property. Consider this simple example:
const transaction = {
sender: 'luis@tjoj.com',
recipient: 'luke@tjoj.com',
funds: 10.0
};
const getFunds = prop('funds');
getFunds(transaction); // 10.0
You can also create a function that extracts multiple properties into an array by mapping prop over an array of keys:
const props = (...names) => obj => names.map(n => prop(n)(obj));
const data = props('sender', 'recipient', 'funds');
data(transaction); // ['luis@tjoj.com', 'luke@tjoj.com', 10.0]
Calling prop on a single object is not as exciting as calling it on a collection of objects. Given an array of three transaction objects with funds, 10.0, 12.5, and 20.0, respectively, you can map prop over it:
[tx1, tx2, tx3].map(prop('funds')); // [10.0, 12.5, 20.0]
[tx1, tx2, tx3].map(prop('calculateHash'));
// [64284210552842720, 1340988549712360000, 64284226272528960]
In this code, the higher-order function prop('funds') did not produce a result until map used it, which is convenient. But when functions get more complex, the awkward notation used to write functions with expanded arrow syntax becomes hard to read, not to mention that multifunction evaluation—add(x)(y)--is cumbersome. You can automate the process of manually expanding into multiple functions with the curry function.
curry automates the manual currying process that we’ve been doing so far, converting a function of multiple arguments to several nested functions of a single argument. Thus, a function like add
const add = a => b => a + b;
const add = curry((a, b) => a + b);
The wonderful quality of curry is that it dynamically changes the way the function evaluates and smooths over the syntax needed to partially pass arguments. You can call add piece-wise as add(3)(7) or, preferably, at the same time as add(3,7).
NOTE In theory, currying is a much stricter form of partial application that requires that returned functions take a single parameter at a time. In partial application, a returned function can take one or several arguments.
As with compose, you can import curry from any FP library (Ramda, underscore.js, and so on), but studying the implementation is interesting; it uses a lot of modern JavaScript idioms (such as rest and spread operators) to manipulate function objects. It also uses a bit of reflection to dynamically figure out the function’s length (a topic that I’ll circle back to in chapter 7).
In keeping with the pure FP spirit of avoiding loops and reassignment of variables, you can implement curry as a recursive, arrow function quite elegantly. You may also find versions that take a more imperative, iterative approach:
const curry = fn => (...args1) =>
args1.length === fn.length
? fn(...args1)
: (...args2) => {
const args = [...args1, ...args2]
return args.length >= fn.length ? fn(...args) : curry(fn)(...args)
};
The following listing shows how to use curry to enhance prop and props.
Listing 4.10 Curried versions of prop and props
const prop = curry((name, obj) => ❶ obj[name] && isFunction(obj[name]) ? obj[name].call(obj) : obj[name] ); const props = curry((names, obj) => names.map(n => prop(n, obj))); ❷
❶ Internally, curry adds runtime support to rewrite the (name, a) pair into partially evaluated arguments name => a => ...
❷ We no longer use the varargs ...name argument, as this is allowed only as the last (or only) argument.
To reiterate, curry mandates that you satisfy all the arguments of a function before it evaluates. Until that happens, curry keeps returning the partially applied functions with the remaining arguments waiting to be passed in. This situation also prevents running functions with unsatisfied or undefined arguments. As I said earlier, add(3) returns a function to the caller, but add(3,7) evaluates to 10 immediately. There’s no way to call a function with an unsatisfied set of arguments, which is great!
With curried functions, the order of arguments is important. Normally, we don’t pay a lot of attention to order in object-oriented code. But in FP, argument order is crucial because it relies so much on partial application. In all the curried functions shown in this chapter, notice that the arguments are arranged to benefit from partial evaluation. For that reason, it’s best to place the most static, fixed arguments first and allow the last ones to be the more dynamic call-specific arguments, as in the definition for prop:
const prop = curry((name, obj) => obj[name] && isFunction(obj[name]) ? obj[name].call(obj) : obj[name] );
The last parameter, obj, is left unbounded (free) so that you can freely extract a particular field from any object as you’re mapping over an array, for example. Given the transactions tx1 and tx2, one for $10 and the other for $12.50, respectively, you can create a new function, fundsOf, with a partially bound funds property key. Now you can apply this function to any object with that key or even map this function an array of similar objects:
const fundsOf = prop('funds');
fundsOf(tx1); // 10.0
fundsOf(tx2); // 12.5
Now that you’ve learned about currying and composition, you can use them together to create a functional version of the calculateHash logic inside HasHash. Alone, curry and compose offer lots of value, but together, they are even more powerful.
One of the goals of this chapter is to generate a more secure hashing digest for calculateHash in our HasHash mixin. So far, we’re at this point in using the recursive definition of computeCipher:
const HasHash = () => ({
calculateHash() {
return compose(computeCipher, assemble)(this);
}
});
function computeCipher(data, i = 0, hash = 0) {
if(i >= data.length) {
return hash ** 2
}
return computeCipher(
data,
i + 1,
((hash << 5) - hash + data.charCodeAt(i)) << 0
);
}
const assemble = ({ sender, recipient, funds })
=> [sender, recipient, funds].join('');
HasHash is aware of its surrounding context (namely, the transaction object referenced by this), but the functions are kept pure and side-effect-free. By building these small islands of pure logic, we can put all this code aside and lessen the mental burden of having to keep track of everything that’s happening.
But we’re not done yet. Now that each function is separate, let’s improve the code a bit more to make HasHash more secure and applicable to the other blockchain domain objects. We will make two additional changes:
Integrate HasHash with any object. This change involves refactoring assemble to take an array of the parts of an object used in hashing, giving us extra flexibility when assigning HasHash to other classes. Part of this change also involves mapping a call to JSON.stringify to ensure that any object provided (primitive or otherwise) gets converted to its string representation. JSON.stringify is a good way of ensuring that we get a string out of any type of data, and it works well, provided that the objects are not incredibly long:
const assemble = (...pieces) => pieces.map(JSON.stringify).join('');
This line creates the string with the necessary object data to seed to the hashing code. Here’s an example:
const keys = ['sender', 'recipient', 'funds'];
const transaction = {
sender: 'luis@tjoj.com',
recipient: 'luke@tjoj.com',
funds: 10
};
assemble(keys.map(k => transaction[k]));
// ["luis@tjoj.com","luke@tjoj.com",10]
Implement a more secure hash. Let’s use Node.js’s crypto module. This module gives you the option to generate hashes using widely adopted algorithms, such as SHA-2, as well as different output encodings, such as hexadecimal:
const computeCipher = (options, data) =>
require('crypto')
.createHash(options.algorithm)
.update(data)
.digest(options.encoding);
The next listing shows an example that creates the SHA-256 representation of a simple object.
Listing 4.11 Computing a SHA-256 value from the contents of an object
computeCipher(
{
algorithm: 'SHA256', ❶
encoding: 'hex' ❷
},
JSON.stringify({
sender: 'luis@tjoj.com',
recipient: 'luke@tjoj.com',
funds: 10
})
); // '04a635cf3f19a6dcc30ca7b63b9a1a6a1c42a9820002788781abae9bec666902'
❶ SHA-2 is a set of secure cryptographic hash functions. The longer the bit string, the more secure it is. In this case, I’m using SHA0256, which is widely adopted in the industry
❷ Returns a hexadecimal-encoded string instead of a binary buffer, making the output more legible
Hash computation must be reliable and predictable; given the same input, it must produce the same output. If you recall from our starting guidelines, predictability conveniently points to the principle of referential transparency. All that’s left to do now is compose these two:
compose(computeCipher, assemble);
But there’s an issue here. Can you spot why this code won’t work? computeCipher is not a function of a single argument. Invoking this function as is will pass the output of assemble into the options part and undefined for data, which will break the entire flow. We can use currying to address this mismatch by partially configuring computeCipher to produce a function that gets inserted into compose. First, add curry to the function definition:
const computeCipher = curry((options, data) =>
require('crypto')
.createHash(options.algorithm)
.update(data)
.digest(options.encoding));
Then call computeCipher piecewise, as you did with add and prop:
compose(
computeCipher({
algorithm: 'SHA256',
encoding: 'hex'
}),
assemble);
The next listing puts everything together.
Listing 4.12 Final implementation of HasHash
const HasHash = (
keys,
options = {
algorithm: 'SHA256',
encoding: 'hex'
}
) => ({
calculateHash() {
return compose(
computeCipher(options),
assemble,
props(keys)
)(this); ❶
}
});
❶ Passing this works well when it’s your own code, but when you’re using third-party libraries, it’s best to send a copy of only the data needed.
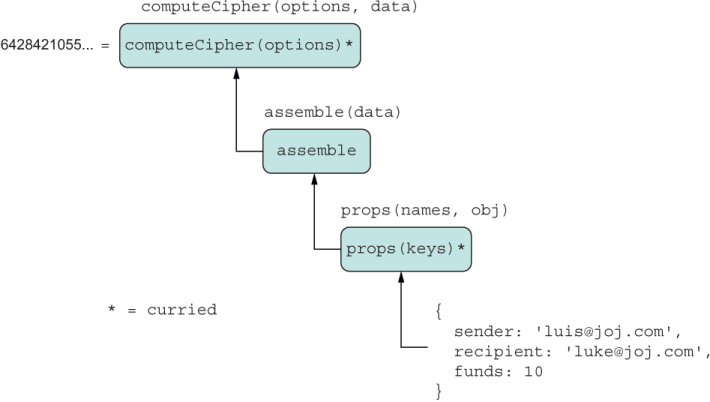
Listing 4.9 Composing with curry in the implementation of calculateHash. The label above each box shows the complete function signature. computeCipher and props are curried and have been partially applied. The far-right parameter (or the only parameter) of all functions is used to receive the input of one function in the chain.
Figure 4.9 shows the flow of data using a simple transaction object literal:
const hashTransaction = Object.assign(
{
sender: 'luis@tjoj.com',
recipient: 'luke@tjoj.com',
funds: 10
},
HasHash(['sender', 'recipient', 'funds'])
);
hashTransaction.calculateHash();
// '04a635cf3f19a6dcc30ca7b63b9a1a6a1c42a9820002788781abae9bec666902'
We used curry and compose to drive the execution of calculateHash, which are known as function combinators—functions that build up (combine) other functions. Combinators have no special logic of their own; they work on either the structure of the functions themselves or on coordinating their execution. curry manipulates the arguments so that they can be evaluated one at a time. Similarly, compose is in charge of threading through a function’s output with the next function’s input. All this control flow is abstracted from you in this snippet of code:
compose(
computeCipher(options),
assemble,
props(keys)
)(this);
The object referenced by this enters the composition chain, and on the other side, you get its hash value. Passing the original context (this) here is safe because all these functions are side-effect-free. But what happens when someone else changes them or when you’re integrating with other functions you don’t know about? In JavaScript, object values are stored by reference. When you pass an object to a function, that reference is passed by value, not the object itself (as with primitives). You can guard against any undesirable mutations and make your code more predictable by sending a copy. This situation is also a good opportunity for the input object being hashed to use only the data you need. To do so, let’s use the Object.fromEntries API. This API allows you to turn any iterable object of key/value pairs (Array, Map, and so on) into an object. HasHash already has the list of keys for the data to hash, so it’s easy to construct an object with only that data:
calculateHash() {
const objToHash = Object.fromEntries(
keys.map(k => [k, prop(k, this)])
);
return compose(
computeCipher(options),
assemble,
props(keys)
)(objToHash);
}
With this snippet, we’ve completed our HasHash mixin. As you can see, it’s not an entirely pure object, because it depends on the global this to exist, which points to the prototype of the object to which HasHash is assigned. But we can call it a hybrid because it relies on pure functions to carry out its work.
We still have to tackle the other coding example: calculating a user’s total balance from blockchain transactions. In the code snippets you’ve seen so far, we’ve always used a regular float to represent the funds amount. I did this to keep things simple. In the real world, funds always has two components: a numerical value and a currency denomination (such as $10.0 or ฿10.0). To represent currency, let’s create an object called Money, designed to be immutable.
The notion of purity extends beyond functions to objects. So far, the main entities of our blockchain application (Block, Transaction, and so on) are mutable, which means that you can easily change the properties of the object after instantiation. We made this design decision to allow these objects to recalculate their hashes on update, and also to allow the object to be dynamically extended via mixins or traditional class-based inheritance if need be. We could also have decided to make the objects immutable, and there are many good use cases for this design, one of which we’ll explore in this section.
Consider an object called Money that represents the amount of currency being transacted. Money is an object with perpetual value: ten cents will always equate to ten cents. Its identity is given by the amount and the currency name. If you change ten cents to five cents, conceptually, that’s a new Money entity. Think about what it means to change a date value. Isn’t this value a different moment in time? Changing a point in a Cartesian plane is another point. Other examples widely used in industry that lend themselves to this type of design include DateTime, Point, Line, Money, and Decimal:
const coord2_3 = Point(2, 3); coord2_3.x = 4; // No longer the same point!
Immutable objects are a well-known pattern in industry. In chapter 2, we discussed how Object.create allows you to define immutable fields by using data descriptors upon creation. Generally speaking, an immutable object is one for which you can’t set any fields. Its data descriptors have writable: false for all fields. A popular pattern based on this is called the Value Object pattern. A value object is immutable upon creation and has some fields to describe identity and comparison. Similar to the guidelines imposed by pure functions, here are some guidelines to keep in mind when deciding whether to use this pattern:
Has no global identity — There’s no way to fetch an instance of a value object by some sort of ID. Conversely, transactions are globally identified by their hash values (transactionId). Similarly, a Block is identified by index value or position in the ledger.
Closed to modification — When the object is instantiated, you may not alter any of its properties. Doing so results in the creation of a new object or an error.
Closed to extension — You may not dynamically add properties to (mixins) or remove properties from this object, and you may not derive new objects from it (inheritance).
Defines its own equality — With no unique ID, it’s beneficial to implement an equals method that knows how to compare two value objects based on their properties.
Override toString and valueOf—Value objects need seamless representation as either a string or primitive. Overriding methods such as toString and valueOf affects how an object behaves next to a mathematical symbol or when concatenated with a string.
For our blockchain, we’re going to represent the funds field of Transaction as a Money object. Before we look at the internal details, let’s see how it’s used:
Money('B|', 1.0); // represents 1 Bitcoin
Money('$', 1.0); // represents 1 US Dollar
Money.zero('$'); // bankruptcy!
Let’s implement Money by using a simple function instead of a class. Unlike class constructors, normal functions can be curried. So we can do things like
const USD = Money('$');
USD(3.0); // $ 3
USD(3.0).amount; // 3
USD(7.0).currency; // $
[USD(3.0), USD(7.0)].map(prop('amount')).reduce(add, 0); // 10
Also, Money supports a few key operations such as adding, subtracting, rounding, and (most importantly) implementing some sense of equality. Why is equality important? Without some field describing its identity, value objects are comparable only by their attributes:
USD(3.0).plus(USD(7.0)).equals(USD(10)); // true
In the case of Money, we’re not interested in using inheritance or any of the instantiation patterns of previous chapters, which are intended to build complex objects; using a simple function to return an object literal is more than enough. This pattern also goes by the name Function Factory.
To implement the “closed for modification and extension” guarantees, we can use the Object.freeze and Object.seal JavaScript built-in methods, respectively. Both methods are easy to compose. The next listing shows the implementation details of Money.
Listing 4.13 Details of the Money value object
const BTC = 'B|'; const Money = curry((currency, amount) => compose( ❶ Object.seal, Object.freeze )(Object.assign(Object.create(null), ❷ { amount, currency, equals: other => currency === other.currency && amount === other.amount, round: (precision = 2) => Money(currency, precisionRound(amount, precision)), minus: m => Money(currency, amount - m.amount), plus: m => Money(currency, amount + m.amount), times: m => Money(currency, amount * m.amount), compareTo: other => amount - other.amount, asNegative: () => Money(currency, amount * -1), valueOf: () => precisionRound(amount, 2), ❸ toString: () => `${currency}${amount}` } )) ); // Zero Money.zero = (currency = BTC) => Money(currency, 0); ❹ // Static helper functions Money.sum = (m1, m2) => m1.add(m2); Money.subtract = (m1, m2) => m1.minus(m2); Money.multiply = (m1, m2) => m1.times(m2); function precisionRound(number, precision) { const factor = Math.pow(10, precision); return Math.round(number * factor) / factor; }
❶ The new object is first frozen and then sealed.
❷ Uses Object.assign with Object.create(null) to create a value object without any prototype references, making it closer to a true value in the system
❸ Overrides Object#valueOf and Object#toString to help JavaScript’s type coercion
❹ Implemented outside the object literal definition to make static methods
The code in listing 4.13 packs in a lot of functionality because we’re trying to arrive at an object that behaves and feels like a primitive. Aside from making the object immutable and closed for extension, we’re instantiating it from a “null object” prototype Object.create(null) in a single step, using Object.assign (chapter 3). Money won’t automatically inherit any of Object.prototype’s member fields (such as toString and valueOf), in particular one that doesn’t apply in this case: Object#isPrototypeOf. The downside is that you’re responsible for implementing these properties correctly.
Hence, we’ll implement toString and valueOf to work as follows:
const five = Money('USD', 5);
console.log(five.toString()); // USD 5
valueOf is a bit more interesting. Unlike with toString, you don’t invoke valueOf directly. JavaScript automatically calls it when the object is expected to behave as a primitive, especially in a numeric context. When the object is next to a math symbol, we can downgrade (coerce) Money to Number. Then you can wrap that result back into Money with proper a currency denomination, if needed:
five * 2; // 10
five + five // 10
Money('USD', five + five).toString() // USD 10
Now let’s see the effects of applying Object.seal and Object.freeze to these objects. We used compose to apply each method sequentially. Object.freeze prevents you from changing any of its attributes (remember that we’re assuming strict mode), as shown here:
const threeDollars = USD(3.0); threeDollars.amount = 5; // TypeError: Cannot assign to read only property 'amount' of object '[object Object]' Object.isFrozen(threeDollars); // true
And Object.seal prevents clients from extending it:
threeDollars.goBankrupt = true; // TypeError: Cannot add property goBankrupt, object is not extensible delete threeDollars.plus; // TypeError: Cannot delete property 'plus' of [object Object] Object.isSealed(threeDollars); // true
Finally, notice that all the methods in Money (plus, minus, and so on) use copy-on-write semantics, returning new objects instead of changing the existing one and embracing the principles of purity we’ve discussed so far.
At this point, you’ve learned how to structure functional code by using composition and currying. Primitive data can be manipulated and mutated at will (because it’s immutable by design), whereas custom data objects need a bit more attention. In the latter case, using value objects when appropriate or passing copies of data to code can help divert lots of nasty bugs.
With all the fundamentals behind us, let’s improve the design of our code with a paradigm known as point-free coding—the last piece needed to implement the logic of calculating the balance of a user’s digital wallet.
Point-free coding is a byproduct of adopting declarative programming. You can use point-free coding without FP. But because point-free is all about improving the readability of code at a glance and making it simpler to parse, having the guarantees imposed by FP furthers this cause.
Learning the point-free style is beneficial because it allows developers to understand your code at first sight without necessarily having to dive into the internals. Point-free refers to a style in which function definitions do not explicitly identify the arguments (or the points) they receive; they are implicitly (tacitly) passed through the flow of a program, usually with the help of curry and compose. Removing this clutter usually reveals a leaner code structure that humans can parse visually with ease. By being able to see the forest for the trees, you can spot higher-level bugs that could arise from using bad logic or making bad assumptions about requirements.
Because JavaScript has curried, first-class functions, we can assign a function to a variable, use this named variable as an argument to compose, and effectively create an executable outline of our code. In this section, you’ll learn about the benefits of using a point-free style with JavaScript, such as
Improving the legibility of your code by reducing syntactical noise
Building a vocabulary describing the actions and tasks that make up your application
Before we begin learning about this style, it helps to see it in comparison with non-point-free coding. Let’s do a quick review:
function countWordsInFile(file) {
const fileBuffer = fs.readFileSync(file);
const wordsString = fileBuffer.toString();
const wordsInArray = wordsString.split(/\s+/);
return wordsInArray.length;
}
To get a high-level idea of what this function does, you’re forced to read every statement and trace the flow. Each statement in the function describes in detail how every function is called and the parameters (or points) each function receives at the call site.
On the other hand, using compose removes the unnecessary overhead and focuses on the high-level steps required to create a higher-level representation of the same logic. When we applied FP to countWordsInFile earlier, we arrived at this code:
const countWordsInFile = compose(
count,
split,
decode('utf8'),
read
);
This program is point-free. Notice that nothing in this program tells you how to invoke countWordsInFile. The only thing you see is the structure of this function or what steps are involved. Because the signature of the function (and all the embedded functions) is missing, you may feel that this style obscures the code a bit for someone who is not familiar with these functions. That point is a valid one, and I’ve seen how it can make using a debugger a bit more challenging. But for someone who is familiar with this style and knows their way around a debugger, point-free coding makes composition much cleaner and allows you to visualize the high-level steps as though they were plug-and-play components.
A common analogy for point-free code is Lego bricks. When you’re looking at a Lego structure from a distance, you can’t see the pins that hold everything together, yet you appreciate the overall structure. If you look at the imperative version of countWordsInFile once more, the “pins” in this case refer to the intermediate variable names that connect one statement to the next.
Suppose that you’re working on another task, such as counting an array of serialized block data from a JSON file. At a high level, you should be able to see that the structure of this code is similar to the preceding snippet of code. The only difference is that instead of dealing with space-separated words, you will deal with parsing an array of elements. Pure functions are easy to swap in and out because they don’t depend on any external data other than their own arguments. countBlocksInFile is implemented simply by swapping split with JSON.parse:
const countBlocksInFile = compose(
count,
JSON.parse,
decode('utf8'),
read
);
Again, this swap is evident because point-free coding cleans up the process of passing functions and arguments around, allowing you to focus on the task at hand, such as changing a red Lego brick for a green one. It should be obvious at this point that countBlocksInFile is another Lego bundle (a module) that can be composed (pinned) further. You can build entire complex applications from this fundamental idea (figure 4.10).
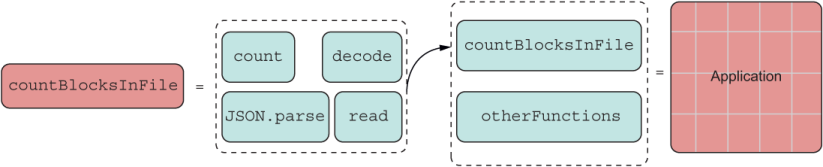
Listing 4.10 Functions composed to build entire applications
All these Lego bricks become the taxonomy, or vocabulary, if you will, of the Lego set that is your application.
Now that you understand how to structure your code by using composition and currying, let’s tackle a more complex imperative-to-functional transformation that involves computing a user’s digital-wallet balance.
In chapter 3, I looked at the skeleton of the Wallet class (listing 3.9) but deliberately omitted the balance method. Here is that snippet of code again:
class Wallet {
constructor(publicKey, privateKey) {
this.publicKey = publicKey
this.privateKey = privateKey
}
get address() {
return this.publicKey
}
balance(ledger) {
//...
}
}
Now we’re prepared to fill in the complex logic details. To compute the balance of a user, given a blockchain (ledger) object argument, we need to tally all the transactions from all the blocks that have been mined for that user since the beginning of the ledger. We can omit the genesis block because we know that it doesn’t carry any data we’re interested in.
Let’s look at this problem again with an imperative mindset and compare it with a functional one. This time, we’ll be using all the bells and whistles that we’ve learned thus far. The algorithm can look like the following listing.
Listing 4.14 Imperative algorithm for computing total balance
balance(ledger) {
let balance = Money.zero();
for (const block of ledger) { ❶
if (!block.isGenesis()) {
for (const tx of block.data) {
if (tx.sender === this.address) {
balance = balance.minus(tx.funds); ❷
}
else {
balance = balance.plus(tx.funds); ❷
}
}
}
}
return balance.round();
}
❶ ledger is a Blockchain object, and iterating over it delivers each block. You’ll learn how to make any object iterable in chapter 7. For now, you can safely assume that it’s an array of blocks.
❷ If the user is the sender of the transaction, we discount the amount in the transaction; otherwise, we add it to the running balance.
Comparing this algorithm with the FP guidelines, you can see that it involves looping over the blockchain data structure, which means that you need to keep a running count of the balance as you iterate through all blocks and then through each transaction of that block. Within each iteration, there’s a lot of branching to accommodate different conditions—an imperative “pyramid of doom,” you might say. Let’s revisit that flow in figure 4.11.
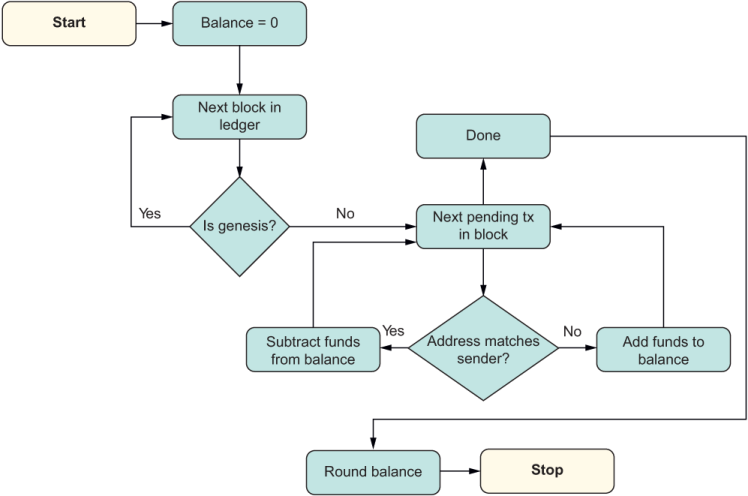
Listing 4.11 Imperative flow of control for the logic in calculating a user’s total balance in a blockchain
All the diamond-shaped boxes represent branching logic, nested within circulating arrows that represent loops. Arguably, this figure is not trivial to parse; it represents a simple piece of code.
In addition, listing 4.14 has side effects in the way it references this to access a wallet’s properties and reassigns balance at each iteration. Refactoring this code by using a hybrid (FP + OO) approach involves
Making the data explicit function arguments instead of implicitly
Transforming loops and nested conditionals to a fluent data transformation with map and filter
Removing variable reassignments with an immutable reduce operation
The best course of action is to extract the logic into its own function, free from side effects, and have balance internally delegate to it with all the initial data. We can call this new method computeBalance:
balance(ledger) {
return computeBalance(this.address, ledger);
}
It’s reasonable to start with the handy array essentials we’re familiar with: map, filter, and reduce. The following code represents the same algorithm, functionally inspired. Figure 4.12 shows what the new flow will look like.
There’s a small caveat in the functional approach shown in listing 4.15, which can be a bit confusing. Because the flow of data involves processing the array of blocks and, within each one, an array of transactions, we’re forced to deal with an array of arrays. To make things simple, when you encounter this issue, the best thing to do is flatten these structures. You’ll learn in chapter 5 that this occurrence is common in functional code. For now, we’ll use Array#flat to flatten the nested structure.
Listing 4.15 Calculating balance in Wallet with FP
function computeBalance(address, ledger) {
return Array.from(ledger) ❶
.filter(not(prop('isGenesis'))) ❷
.map(prop('data')) ❸
.flat() ❹
.map(balanceOf(address)) ❺
.reduce(Money.sum, Money.zero()) ❻
.round(); ❽
}
❶ Array.from turns any iterable into an array
❷ Uses the utility functions not and prop to call isGenesis (check code repository for implementation)
❸ Reads the collection of transactions (data) from the chain
❹ The resulting array of arrays from the previous step is flattened into a single array.
❺ Calculates this user’s balance from each transaction
❻ Uses Money.sum function as a reducer, starting from Money.zero, and tallies the total
❽ Invokes the Money.round method on the result
For the most part, you can see that this algorithm is a reincarnation of the imperative logic but takes advantage of the higher-order functions from the array that connects each piece of the transformation, radically changing the flow of data. Also, the fact that we’re performing addition through code such as reduce(Money.sum, Money .zero()) speaks to the mathematical nature that functional programs tend to exhibit.
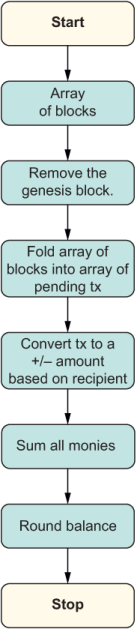
Listing 4.12 Functional flow of control for the logic in calculating a user’s total balance in a blockchain
For completeness, here’s the balanceOf function used in the functional version, now done as a lambda expression, which maps a user ID in a transaction to a positive or negative monetary value depending on whether said user is the sender or the recipient:
const balanceOf = curry((addr, tx) =>
Money.sum(
tx.recipient === addr ? tx.funds : Money.zero(),
tx.sender === addr ? tx.funds.asNegative() : Money.zero()
);
)
If you look back at listing 4.15 again, perhaps the most complex step you see is the call to flat on the array of arrays structure that is built during the flow of the data. Here’s flat with a simple example so that you can see how it peels off the nested array:
[['a'], ['b'], ['c']].flat() // ['a', 'b', 'c']
Because the algorithm performs a map operation beforehand, there’s a shortcut: using Array#flatMap method directly. We’ll revisit map and flatMap in more detail in chapter 5, but for now, we’ll go over them in order to understand how computeBalance works. As you can see, flat is intuitive, but what the heck is flatMap? The combination of map followed by flat occurs frequently in functional programs, so often that it makes sense to alias the composition of these two methods as a single method. The agreed-upon name in the functional communities is flatMap. The preceding code simplifies to the next listing.
Listing 4.16 computeBalance using map, filter, and reduce
function computeBalance(address, ledger) {
return Array.from(ledger)
.filter(not(prop('isGenesis')))
.flatMap(prop('data')) ❶
.map(balanceOf(address))
.reduce(Money.sum, Money.zero())
.round();
}
❶ Substituting flatMap for map and then flat
With these APIs, you can solve virtually any array processing task you need and probably even remove loops from your code. This capability is the future of working with collections in JavaScript.
This listing is a good stopping point, but for the joy of it, let’s go one step further. In functional programs, it’s not common to use dot notation to invoke sequences of functions (map(...).filter(...).reduce(...)), as this notation assumes the inner workings of an object chaining these operations together. Instead, use their extracted, curried function forms with the help of compose to thread through the entire flow of data, passing said object to each call (no assumptions), making it point-free!
Let’s go over this technique slowly. When extracting a method into its own function, place the instance object as the last argument, and curry the function. The following listing shows how to extract Array#map(f).
Listing 4.17 Extracting map in curried form
const map = curry((f, arr) => arr.map(f)); ❶
❶ Array arr is the last parameter.
To embed map in a chain, partially apply the first argument, the mapper function:
map(balanceOf(address));
The dynamic array (arr) argument isn’t provided directly because compose will do it for you in a point-free way. Most third-party FP libraries carry these helper functions (map, filter, reduce, and many more) in curried form. The more functional version of this code, shown in the next listing, takes advantage of fine-grained, point-free design. The point-free design requires a fixed address parameter, whereas ledger is provided at the call site.
Listing 4.18 Point-free version of computeBalance
const computeBalance = address => compose( ❶ Money.round, reduce(Money.sum, Money.zero()), ❷ map(balanceOf(address)), ❷ flatMap(prop('data')), ❷ filter( ❷ compose( ❸ not, prop('isGenesis') ) ), Array.from ); const computeBalanceForSender123 = computeBalance('sender123'); computeBalanceForSender123(ledger);
❶ With compose, the logic reads right to left.
❷ Uses the curried extracted forms of the equivalent Array#filter method
❸ Uses nested composition to make the code more modular
FP takes a little getting used to, but thinking this way puts you on the path to writing highly modular, maintainable, cleaner, and more reliable code. In fact, it saves you from potential bugs because JavaScript gives you total freedom to mutate almost anything, making your development experience a lot more enjoyable.
Fanning out to pure functions like this one is a compelling idea that will become more and more prominent as JavaScript continues to embrace more functional features and make creating function chains a native part of the language.
Now that you understand the basic functional programming concepts, you’re one step ahead in learning a new feature that could make landfall in the near future. In this chapter, you learned (among other things) how to create functional chains by using compose. One of the most noticeable qualities of this operator is that the flow of data happens in reverse, which can be quite jarring for some people. Luckily, there’s a solution: the pipe operator. A close cousin of compose, pipe takes the functions in the natural left-to-right order. The buildout of pipe is exactly the same as that of compose. The only change would be to use reduceRight instead of reduce:
const pipe = (...fns) => fns.reduceRight(compose2);
This operator is inspired by the way in which UNIX-based programs pipe data forward into one another. With pipe, you could rearrange the logic to calculate a balance like this:
pipe(
Array.from,
filter(
pipe(
prop('isGenesis')
not,
)
),
flatMap(prop('data')),
map(balanceOf(address)),
reduce(Money.sum, Money.zero()),
Money.round
);
You’ll also find pipe in most FP libraries for JavaScript, such as Ramda and Crocks. If you prefer this way of thinking, JavaScript has a nice surprise in store for you. Introducing the pipeline operator: |> (https://github.com/tc39/proposal-pipeline-operator). Inspired by functional languages such as Elixir and F#, this native operator allows you to call sequences of functions with the data flowing unidirectionally to the right without needing any special third-party libraries.
It’s important to start learning about this new feature now because when it becomes official, it will radically change the way we write code. Here’s an example:
'1 2 3' |> split |> count; // 3
You can even mix it with lambda expressions:
'1 2 3' |> split |> count |> (x => x ** 2); // 9
Now imagine that you had some of the common array methods extracted in curried, function form, as provided in these functional utility libraries. You’ll be able to write code like this:
ledger
|> Array.from
|> filter(b => (b |> prop('isGenesis') |> not))
|> flatMap(prop('data'))
|> map(balanceOf(address))
|> reduce(Money.sum, Money.zero())
|> Money.round;
This example is a terser, more idiomatic way of designing code, and it pairs extremely well with curry for a declarative, native point-free design. For details on experimenting with this operator now, see appendix A.
From now on, if anyone asks whether JavaScript is object-oriented or functional, say “Yes!” The previous chapters highlighted the object-oriented nature of JavaScript. This chapter focused on functional programming and the art of composing pure, higher-order functions. Pure functions guarantee consistent and predictable results based on their input. Their purpose is clearly depicted by their signatures or, as Eric Evans puts it in Domain-Driven Design (Addison-Wesley Professional, 2013), “A pure function is an intention-revealing interface.”
Although the functional paradigm has many benefits, it doesn’t have to be an all-or-nothing process. I deliberately used a hybrid style for the blockchain application with OO and FP concepts intertwined. You can not only take advantage of prototypal object models, but also create highly testable and portable modules of functions that encapsulate your critical business logic. Functional programming helps you write more robust and bug-free code, especially in a language such as JavaScript, where almost everything is mutable. We’ll circle back to coding with immutability in chapter 5.
JavaScript’s higher-order functions are the means by which we can achieve functional code.
Code written in a functional style is declarative, composable, lazy, and simple to reason about.
The composition of pure functions is the bread and butter of any functional codebase.
Shifting to a functional mindset requires a different approach to problem-solving based on decomposing code into fine-grained behavior.
Lazy programming allows you to defer computation, and with curry, you can create composable software by using functions of any arity (number of arguments).
Learning about FP principles will give you the competitive edge you need to begin using the new JavaScript features that will be available in the years to come.
Using the pipeline operator (|>) makes it incredibly easy and idiomatic to implement point-free function chains.