Any application that can be written in JavaScript, will eventually be written in JavaScript.
It’s an amazing time to be a JavaScript developer. Today, JavaScript developers can write code that runs virtually anywhere from tablets, smartphones, desktops, bots, and cloud platforms to the Internet of Things, such as toasters, refrigerators, thermostats, and even spacesuits! Also, we can program all tiers of an application stack, from the client and server, all the way down to the database. The world is at our fingertips.
Despite JavaScript’s resounding popularity, most developers—even those who use it every day—still struggle to decide how to approach writing a new application. Most of the time, you or your organization will have a prearranged framework of choice, which gives you a good starting point. But even in these situations, frameworks only get you so far; business-domain logic (done in plain JavaScript coding) will always be the most difficult and uncertain part of the equation—one that you can’t throw a library at to do. For these cases, it’s important to have a good grasp of the language’s syntax, the features it has to offer, and the paradigms it supports.
Most general-purpose programming languages typically have a recommended way of solving a certain type of problem. Java and similar languages are hard-set on classes to represent your business model, for example. With JavaScript, however, there are many more options to consider: functions, object literals, creational APIs, and even classes. Because JavaScript glues the web together, not only in browsers and mobile devices, but also increasingly in the server, it’s continuously evolving to meet the demands of diverse developer communities and rise to the new challenges imposed by these (sometimes opposite) environments. Examples of these challenges include managing asynchronous data originating from a user clicking buttons to performing lower-level file I/O and breaking complex parts of your business logic into simple, maintainable modules that can be shared and used across clients and servers. These problems are unique.
In addition, when we use JavaScript at scale, we also need to concern ourselves with how to instantiate objects from proper abstractions that match our way of reasoning, decomposing complex algorithms into simpler, reusable functions and handling potentially infinite streams of data. All these tasks require good design skills so that the code is simple to reason about and easy to maintain.
That is where The Joy of JavaScript comes in. The goal of this book is to help you identify and work with the different features of the language so that you become a well-rounded JavaScript professional who understands how expert developers are using JavaScript. The topics covered will give you enough information to allow you to focus on and master what you need to tackle today’s and tomorrow’s challenges. The book will also prepare you to use some of the new features that might be coming into the language in the coming years, including pipeline and bind operators, throw expressions, and observables. My aim is to make you a better, more productive programmer so that you can do more with less. After a few chapters—and certainly by the end of the book—you should be writing even leaner and more elegant code than you are already writing. In short, you’ll emerge from this book with a batch of new tools and techniques at your disposal for more effective and efficient programming, whether you are writing code for the frontend or the backend.
Many years ago, JavaScript development wasn’t particularly associated with “joy.” It was cumbersome to manage deep object hierarchies, for example, or to package your application into modules that would work across environments. The problem of implementing cross-platform, cross-vendor compatible code, plus the lack of tool support, made lots of developers cringe at the idea of having to write or maintain JavaScript code for a living. But that’s changed; in fact, it’s quite the opposite.
Fortunately, we’re now in the modern days of JavaScript development, which means several things:
First, we can closely monitor JavaScript’s steady evolution with a well-defined, fast-paced, task group called TC39 that pushes new language features every year, all in the open and transparently. This creates both excitement and angst, because it inevitably forces you to rethink or throw away old habits and get ready for what’s coming. Not all developers embrace change well or keep an open mind, but I hope that you do.
Second, the days of copy-paste programming are long behind us, and gone with them is the stigma of having Script in the name as somehow describing an inferior language. This sentiment was a global one many years ago, but that’s no longer the case. The JavaScript ecosystem is among the most vibrant and cutting-edge ecosystems, and today, JavaScript developers rank among the highest-paid professionals in the industry.
Finally, the misconception that a JavaScript developer is a jQuery, React, Angular, Vue, Svelte, or <name-your-framework> developer is fading. You’re a JavaScript developer—period. The decision to use any of these frameworks or libraries is yours to make. By using good practices and learning how to properly use the wide spectrum of tools that JavaScript gives you, plain-vanilla JavaScript is powerful enough to let your creativity run wild and contribute to any kind of project.
To bring you into the present and future of JavaScript programming, this book explores the language in the context of the most popular paradigms—functional, reflective, and reactive—and describes how to work with key coding elements within each paradigm. The book is organized around the four themes used in addressing most programming problems: objects, functions, code, and data. Within these themes, you’ll learn which proper object models to use to design your business domain, how to combine functions and transform these objects into the desired output, how to modularize your applications effectively, and how to manage the data that flows through your application, whether that data is synchronous or asynchronous.
As you can see from the spectrum of topics covered, this book is not for a JavaScript newcomer or beginner. This book assumes that you already have some professional experience and a strong grasp of the basics (such as variables, loops, objects, functions, scopes, and closures), and that you have gone through the exercise of implementing and configuring JavaScript programs and setting up a transpiler such as Babel or TypeScript.
Modern JavaScript development is possible only when the language has a consistent, steady evolution of features and syntax that tackle these problems.
For many years, the evolution of JavaScript was stagnant. To put matters in perspective, ECMAScript, the specification language for JavaScript, had been stuck at version 3.1 across major JavaScript engines since December 2009. This version was later renamed as the better-known ECMAScript 5, or ES5. We waited for nearly six agonizing years—since June 2015, to be exact—to see any progress made in the language. In tech years, six years is a long time; even ATM machines get updated sooner.
During this time, a standards committee known as TC39 (https://github.com/ tc39), with the help of institutions such as the OpenJS Foundation (https://openjsf .org), gave birth to ECMAScript 2015, also known as ES6. This change was the biggest leap that JavaScript had made since its inception. Among the most important features in this release (http://es6-features.org) were classes, arrow functions, promises, template literals, blocked-scoped variables, default arguments, metaprogramming support, destructuring assignment, and modules. Aside from all these most-needed language features, the most important change was that JavaScript’s evolution shifted to a yearly release cadence, allowing the language to iterate quickly and address problems and shortcomings sooner. To help you keep track of where we are, ES6 refers to ECMAScript 2015, ES7 to ECMAScript 2016, and so on. These incremental releases are much easier to adopt and manage by platform vendors than large, monolithic releases.
TC39 is composed of members of leading web companies that will also continue evolving ECMAScript, the specification language set to standardize JavaScript, known internationally as ISO/IEC 16262 or ECMA262 for short. (That’s a lot of acronyms, I know, but I hope that you got the gist.) TC39 is also a platform that gives the whole community some input into where the language is headed through participation in IRC channels and mailing lists, as well as through finding and helping to document issues in existing proposals. If you take a quick look at the language proposals on TC39’s GitHub site, you can see that each one goes through a set of stages. These stages are well documented on GitHub, so I’ll summarize them for you here:
Stage 0 (strawman) — This stage is informal, and the proposal can have any form, so anyone can contribute to the further development of the language. To add your input, you must be a member of TC39 or registered with ECMA International. If you’re interested, feel free to register at https://tc39.github.io/agreements/ contributor. When you’re registered, you can propose your ideas via the es-discuss mailing list. You can also follow the discussions at https://esdiscuss.org.
Stage 1 (proposal) — After a strawman has been made, a member of TC39 must champion your addition to advance it to the next stage. The TC39 member must explain why the addition is useful and describe how it will behave and look when it’s implemented.
Stage 2 (draft) — The proposal gets fully spec’d out and is considered to be experimental. If it reaches this stage, the committee expects the feature to make it into the language eventually.
Stage 3 (candidate) — At this stage, the solution is considered to be complete and is signed off. Changes after this stage are rare and generally are made only for critical discoveries after implementation and significant use. You can feel comfortable using features in this stage. After a suitable period of deployment, the addition is safely bumped to stage 4.
Stage 4 (finished) — Stage 4 is the final stage. If a proposal reaches this stage, it is ready to be included in the formal ECMAScript standard specification.
This healthy stream of new proposals is important so that JavaScript keeps up with the demands of today’s application development practices. Aside from discussing the cool techniques and paradigms that come alive only with JavaScript, this book introduces you to a few proposals that will forever change how we write JavaScript in the near future, some of which I’ll mention briefly in this chapter. Here they are, in the order in which they’ll appear in the rest of the book:
Private class fields (https://github.com/tc39/proposal-class-fields) allow you to define access modifiers (private, static) to a class’s properties.
The pipeline operator (https://github.com/tc39/proposal-pipeline-operator) brings the UNIX-like pipe feature of functional languages to JavaScript functions.
The bind operator (https://github.com/tc39/proposal-bind-operator) is a new language syntax that abstracts the use of Function.prototype.bind.
Throw expressions (https://github.com/tc39/proposal-throw-expressions) allow you to treat a throw statement as though it were a function or a variable.
Observables (https://github.com/tc39/proposal-observable) enable the stream-based, reactive paradigm.
For most of the remainder of this chapter, I’ll introduce you to the book’s four major themes so that you understand the big picture and see how the themes relate to one another. I’ll start with objects.
An object is nothing more than a memory reference that points (links) to other memory locations. At its core, JavaScript is an object-oriented language, and there are many ways to define objects and the association among them in JavaScript. In this book, we’ll look at many ways to define objects.
For one-time use, for example, a simple object literal is probably the best and quickest approach. An object literal comes in handy when you need to group multiple pieces of data that need to be passed to, or returned from, a function. When you need to create multiple objects with the same shape, however, it’s best to use a creational API like Object.create to act as a factory of objects. You can also use your own functions as object factories when combined with the new keyword. In the same vein, classes have become popular in recent years and behave in much the same way. But if objects are nothing more than references (links) to other objects, JavaScript also lets you mash multiple small objects into one big one by using the spread operator or even an API like Object.assign.
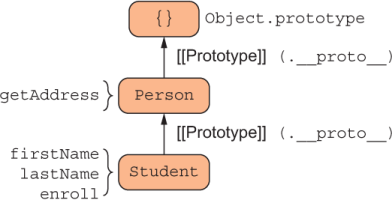
Regardless of the approach you take, you often need to share data and a set of methods to avoid duplicating code. JavaScript uses two central mechanisms: the property resolution mechanism and prototypes. These mechanisms are intertwined. JavaScript uses the object’s internal prototype reference as a path to navigate an object hierarchy during property resolution, which can happen when you query properties of an object or invoke a method. Suppose that you have the inheritance configuration shown in figure 1.1.
Figure 1.1 A simple prototype hierarchy in which objects of Student inherit from objects of Person
Here, objects constructed from Student inherit from objects constructed from Person, which means that all Student instances have at their disposal the data and methods defined in Person. This relationship goes by the name differential inheritance, because as the object graph becomes longer, every object borrows the shape of the one above it and differentiates itself (becomes more specialized) with new behavior.
From figure 1.1, calling enroll on a Student invokes the desired property right away because it’s local to the object, but calling getAddress uses JavaScript’s property lookup mechanism to traverse up the prototype hierarchy. The downside of this approach is that when your object graphs become a lot more complex, a change to a base-level object will cause a ripple effect in all derived objects, even at runtime. This situation is known as prototype pollution, and it’s a serious issue that plagues large JavaScript applications.
Because the prototype is an internal implementation detail of objects in JavaScript, from the point of view of the caller the Student API is a façade with four properties: firstName, lastName, getAddress, and enroll. Similarly, we can obtain the same shape by composing object literals describing a Person and Student. This approach is a slight twist on the configuration in figure 1.1, but an important one. Take a look at figure 1.2.
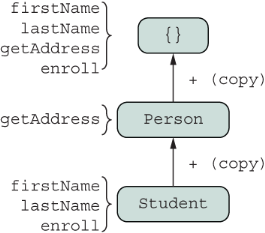
Figure 1.2 Two concrete objects (Student and Person) mesh into a brand new object with all properties assigned from the combined objects. Although no prototypal inheritance is at play here, the directions of the arrow is kept the same as in figure 1.1 to convey the similar mental model of both approaches.
With figure 1.2, the main difference is that we replaced prototype references with a copy operation to symbolize that we’re essentially taking all the properties of Student and Person and copying them (actually, assigning them) to an empty object. So instead of linking objects, we created separate objects with the same shape. From the caller’s point of view, these objects are exactly the same, and you still benefit from code reuse. In this scenario, Student and Person are not constructors or factories; they are simple mixins (pieces of an object). Although this approach saves you from unintended downstream changes and prototype pollution to some degree, the downside is that every new object you create adds a new copy of the assigned properties in memory, making the memory footprint a bit larger.
As you know, most things in computer science are trade-offs. Here, you trade the memory-efficient approach of prototypes, which JavaScript engines highly optimize, for ease of maintainability and reusability. In chapters 2 and 3, we’ll talk in detail about these and other patterns, as well as the code that implements them.
If objects are the fabric of JavaScript, functions represent the needles used to thread the pieces together. JavaScript functions are by far the strongest parts of the language, as we’ll discuss in section 1.3.
Functions implement the business logic of your application and drive its state (such as the data inside all the objects in memory) to its desired outcome. At a fundamental level, you can think about functions in two ways:
In the procedural or imperative mindset, a function is nothing more than a group of statements that execute together, used to organize and avoid duplicating similar patterns of code. The object-oriented paradigm inherits from procedural programming, so it’s also a sequence of statements or commands that modify objects. The reader is expected to be familiar with this approach.
On the other hand, you can think about functions as expressions through the lens of functional programming (FP). In this view of the world, functions represent immutable computations that are assembled like Lego bricks.
Figure 1.3 shows a flowchart of a hypothetical program of minor complexity that uses a procedural style. We’ve been trained to think like computers and map out data flows in this way. But as you’ll see over the next couple of figures (figure 1.4 and 1.5), when you use the right techniques, you can simplify even the most complex program as a streamlined sequence of expressions.
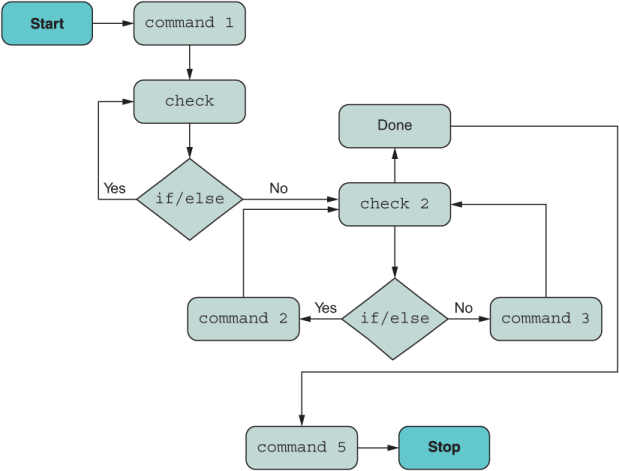
Figure 1.3 A hypothetical description of a program illustrating if/else conditions and looping
You should be writing maintainable, declarative code that your users and teammates can understand, and letting the computer parse and optimize code for its own understanding. FP can help a lot in this regard. You’ve probably heard or read that React allows you to build UIs “the functional way” or that Redux promotes immutable state management. Have you ever wondered where all these concepts come from? You can code functionally by taking advantage of higher-order functions. In JavaScript, a function is an object capable of carrying or linking to variables in its lexical scope (also known as its closure or backpack) and one that you can pass as an argument and return as a callback. This fundamental part of the language, which has existed since the birth of JavaScript, has infinite potential for designing code.
FP expresses computations and data as a combination of pure functions. Instead of changing the state of the system on every call, these functions yield a new state; they are immutable. Coding with FP will prevent a lot of bugs—ones you don’t have to bother to code around—and yield code that you can look at years later and reason about more easily. This feature isn’t part of JavaScript per se, but it complements coding with JavaScript’s higher-order functions.
Chapter 4 teaches you enough FP to significantly affect the way that you do your day-to-day coding. It goes through an exercise of decomposition (breaking complex problems into small, manageable chunks) and composition (pulling the pieces back together). Abstractly, the coding mindset is shown in figure 1.4.
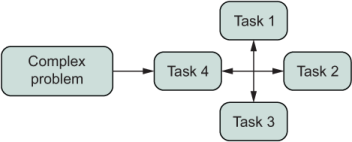
Figure 1.4 FP programs tend to decompose big problems and solve them as the composition of smaller tasks.
Inevitably, you’ll tend to create much simpler functions that work on some input and produce an output based solely on this input. When you’ve been able to disassemble a complex problem and represent it as multiple functions, you’ll use techniques such as currying and composition to string all these functions back together. You can use functions to abstract any kind of logic—such as conditional execution, loops, and even error handling—to create a pipeline of information that looks like figure 1.5.
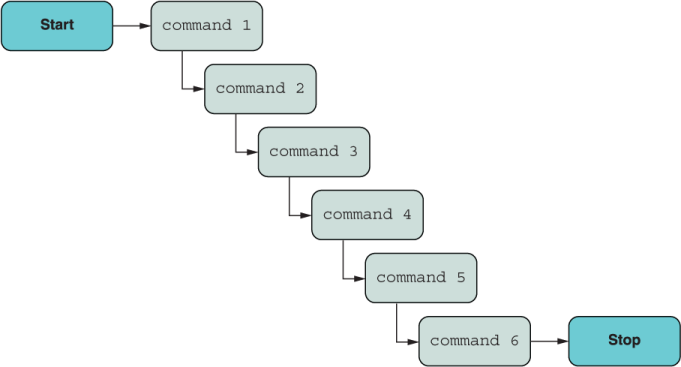
Figure 1.5 Composition allows you to build function pipelines in which the output of one function becomes the input to the next.
We’re fortunate to use a language that can give us this kind of support. In future releases of the language, figure 1.5 could be encoded directly in JavaScript with the new pipeline operator (|>) syntax, which you’ll learn about in chapter 4:
const output = [input data] |> command1 |> command2 |> ... |> command6;
Like a UNIX shell, this operator allows you to “pipe” the output of one function as the input to the next. Let’s assume that you created a split function to break apart a string by spaces into an array and a count function to return the length of the array. The following line is valid JavaScript code:
'1 2 3' |> split |> count; // 3
Furthermore, one of the most noticeable differences between figures 1.3 and 1.5 is the removal of the conditional logic (the diamond shapes). How is this possible? Chapter 5 introduces a concept known as the Algebraic Data Type (ADT). In our case, type means an object with a certain shape, not a static type, which is what it commonly refers to in other language communities. Given that there’s a lot of discussion about static type systems for JavaScript (such as TypeScript and Flow), this book does spend a little bit of time talking about static types in JavaScript in appendix B.
ADTs are commonplace nowadays in many programming languages and libraries as an elegant solution to common problems such as data validation, error handling, null checks, and I/O. In fact, JavaScript’s own optional chaining, pipeline, promises, and nullish coalesce operators, as well as Array.prototype{map, flatMap} APIs (all discussed in this book), are inspired in these algebraic types.
Earlier, we discussed composition in terms of functions. How can composition apply to custom data objects? You’ll learn that Array’s own map and flatMap methods conceptually apply to much more than arrays. They are part of a set of universally accepted interfaces that you can implement to make any object behave like a function; we’ll call this object a functor or a monad. JavaScript’s own Array has functor-like behavior, and you’ve been using this pattern all along without realizing it when transforming arrays by using map. This style of coding is important as a foundation for many of the topics covered in this book, so I’ll spend a little time here going over it.
Suppose that you’ve declared some functor F (which could be Array) and given it some input data. Functors are known by their specific implementation of map so that you can transform the data enclosed inside F. Figure 1.6 shows a step-by-step view of sequentially applying (mapping) functions to a string.
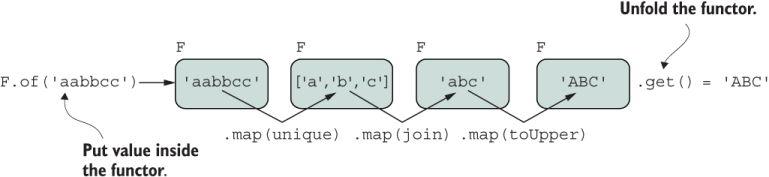
Figure 1.6 A functor object (F) uses map to transform the data contained inside it. Functors are side-effect-free, as every application of map yields a new instance of F while the original stays intact.
map is a contract that can apply to any F that meets the functor requirements. When dealing with functions that you want to apply consistently across different independent objects, you may be inclined to use Function.prototype.bind to set the target object receiving the function call. With JavaScript’s new bind operator (::) syntax, this process got easier. Here’s a contrived example:
const { map } = Functor;
(new F('aabbcc'))
:: map(unique)
:: map(join)
:: map(toUpper); // 'ABC'
There are many use cases in which functors are useful, so let’s hone in on the issue of conditional logic for validation. In chapter 5, we will implement our own ADT from scratch to abstract over if/else logic with an expression such as “If data is valid, do X; else, do Y.” The flow of data, although following the declarative recipe-like paradigm of figure 1.5, will execute proper branching logic internally, depending on the result of the validation check. In other words, if the result of a validation check is successful, the callback function is executed with the wrapped input; otherwise, it’s ignored. These two code flows are shown in figure 1.7.
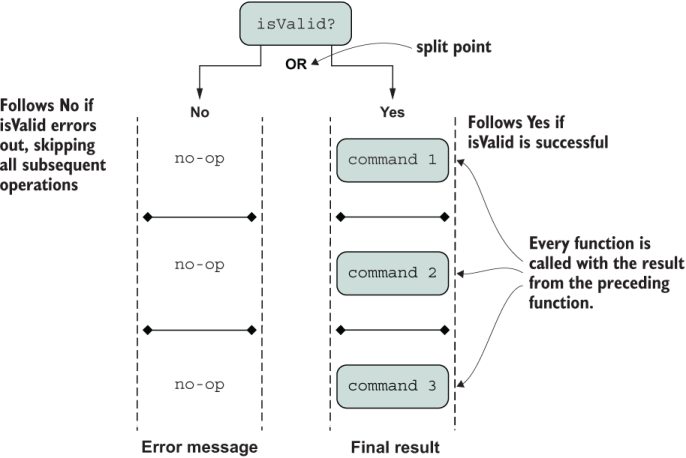
Figure 1.7 An ADT to implement conditional logic models mutually exclusive (OR) branching. On the Yes (success) side of the branch, all mapped operations are executed against the data contained inside the ADT. Otherwise, on the No (failure) side, all operations are skipped. In both cases, the data flows sequentially from beginning to end.
Learning about ADTs now will prepare you for where the language is headed. Early proposals include features such as pattern matching, which is proper for more functional alt-JS programming languages such as Elm. I don’t cover pattern matching in this book, as this proposal was in early draft form at the time of this writing.
Now that you’ve learned object-oriented and functional techniques to model your business domain, section 1.4 introduces you to JavaScript’s official module system, known as ECMAScript Modules (ESM), to help you organize and deliver your code in an optimal manner.
Chapter 6 focuses on how to import and export code across your application by using ESM. The main goal of this feature is to standardize how code is shared and used in a platform-agnostic fashion. ESM supersedes earlier attempts at a standard module system for JavaScript, such as AMD, UMD, and even CommonJS (eventually). ESM uses a static module format that build/bundler tools can use to apply a lot of code optimizations simply by analyzing the static layout of your project and its interdependencies. This format is especially useful for reducing the size of bundled code that is sent over the wire to remote servers or directly to a browser.
JavaScript can use its module system to load modules as small as a single function to as big as monolithic classes. When you use well-established, tried-and-tested keywords such as export and import, creating modular, reusable code is straightforward.
Being able to change one area of your code without affecting others is the cornerstone of modularity. Separation of concerns doesn’t apply only to the global project structure, but also to running code—the topic of chapter 7.
Chapter 7 talks about separation of concerns by taking advantage of JavaScript’s metaprogramming capabilities. Using JavaScript symbols and APIs such as Proxy and Reflect to enable reflection and introspection, you can keep your code clean and focused on the problem at hand. We’ll use these APIs to create our own method decorators to dynamically inject cross-cutting behavior (such as logging, tracing, and performance counters) that would otherwise clutter your business logic, doing so only when you need it.
As a simple example, suppose that during debugging and troubleshooting you want to turn on logging of any property access (reading the contents of a property or calling a method) on some critical objects of your application. You’d like to do this without modifying a single line of code and be able to turn it off when you’re done. With the right instrumentation in place, you can create dynamic proxies that decorate objects of your choice and intercept or trap any calls to that object to weave new functionality. This simple example is depicted in figure 1.8.
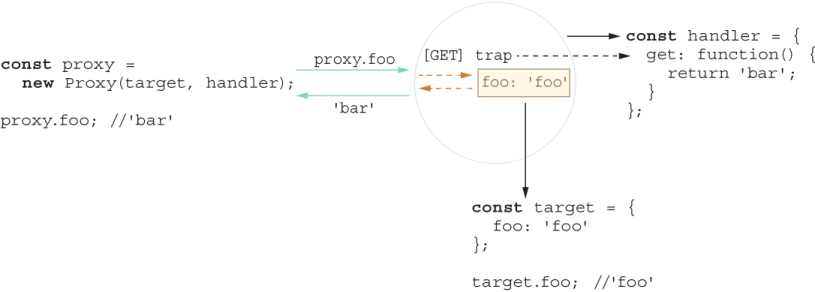
Figure 1.8 Creating a proxy object dynamically around some target object. Any property access (foo) is trapped by the proxy object, so you can inject any code you want. In this simple case, the proxy object traps the access to foo and dynamically changes its return value to 'bar'.
Now imagine replacing this simple trap with performance counters before and after areas of code that you want to optimize, or using global security policies that can mangle or obfuscate sensitive strings inside objects before printing them to the screen or a log file. These method decorators become useful in a large number of use cases. We’ll look at how to do these things in chapter 7.
Now that you have objects, functions, and your code properly organized, all that’s left to do is manage the data that flows through it.
Because JavaScript is critically positioned as the language of the web (both server and client), it needs to handle data of many shapes and sizes. Data can arrive synchronously (from local memory) or asynchronously (from anywhere else in the world). It may come in all at once (single object), in an ordered sequence (array), or in chunks (stream). JavaScript engines, at a high level, rely on an architecture featuring a callback queue with an event loop that can execute code continuously in a concurrent fashion and without halting the main thread.
Without a doubt, using promises as a pattern for abstracting time and data locality has made it simpler to reason about asynchronous code. A Promise is an object that behaves like a function representing an eventual value, with an API that bears a lot of resemblance to ADTs. In your mind, you can replace then with map/flatMap. A Promise can be in one of several states, as shown in figure 1.9, of which the most noticeable are 'fulfilled' and 'rejected'.
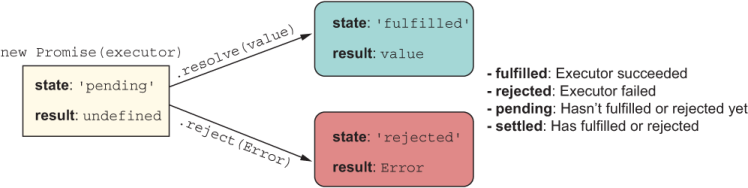
Figure 1.9 A new Promise object and all its possible states
As you can see, promises also models two branches of code. These two branches move your logic forward to execute your business logic to the desired outcome ('fulfilled') or produce some sort of error message ('rejected'). Promises are composable types, much like ADTs and functions, and you can create chains of sequential logic to attack complex problems involving asynchronous data sources and profit from proper error handling along the way (figure 1.10).
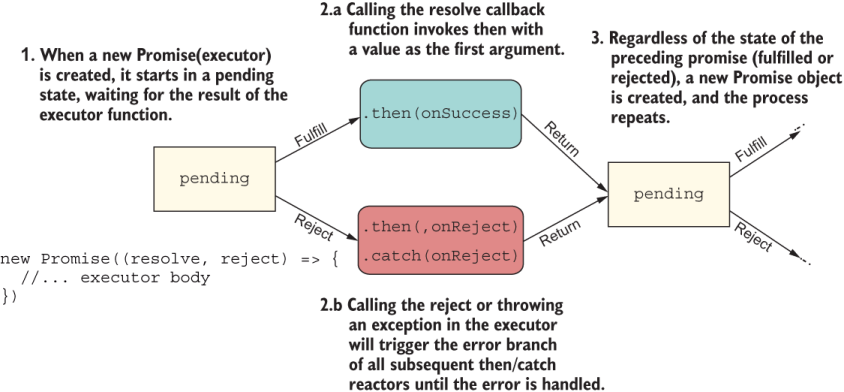
Figure 1.10 How Promise objects chain to form new Promise objects. Along the way, the same pattern repeats. Both success and rejection cases lead to a new Promise object returned.
In chapter 8, we discuss promises and the async/await syntax that appeals to developers from a more imperative or procedural background, yet shares the behavioral semantics of promises. With async/await, you have the visual advantage of writing code that looks as though it’s pausing and waiting for a command to execute (as in fetching data with an HTTP request), but behind the scenes, it’s all promises interacting with the underlying event loop architecture. In chapter 8, we also explore topics implemented on top of promises such as async iterators and async generators.
Promises model single, asynchronous values, but async generators allow you to deliver potentially infinite sequences of data over time. Async generators are a good mental model for understanding streams, which are sequences of events over some period of time, as depicted in figure 1.11.

Figure 1.11 A simple stream with three events separated by some unit of time
There are standard Stream APIs to read/write streams implemented in both browsers and Node.js. Examples are file I/O streams in Node.js and the Fetch API in browsers. Nevertheless, given the diversity of the data types we deal with on a daily basis, instead of using Promise for a single-value event and Stream for sequences of events, ideally we’d use a single API to abstract over all these data types with the same computing model. This approach is attractive to framework and library authors alike because it allows them to provide a consistent interface. Fortunately, JavaScript proposes the Observable API as the solution.
Any time you see an Observable object, you should be thinking in terms of figure 1.11. JavaScript’s inclusion of Observable built into the language seeks to standardize the amazing things you can do with libraries like RxJS. With observables, you can subscribe to events coming from any source: a simple function, an array, an event emitter (such as DOM), an HTTP request, promises, generators, or even WebSockets. The idea is that you can treat each piece of data as some event in time and use a consistent set of operators (observable functions) to process it. Like functions, promises, and ADTs, observables are composable. Do you see a pattern? This pattern isn’t a coincidence; it’s the coding pattern of modern software and one that most languages are increasingly adopting. Hence, you can also create chains or pipelines by calling a sequence of composable operators that work on or transform the data flowing through an observable object to process data synchronously or asynchronously as it propagates forward in time. Figure 1.12 shows how a source observable is transformed by some operator (maybe map?) to yield a new observable.
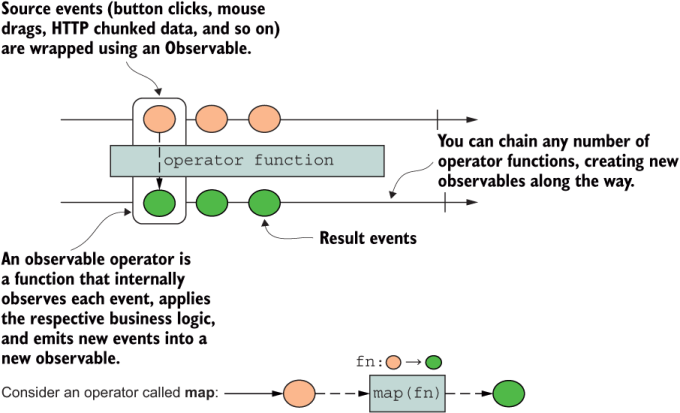
Figure 1.12 A source Observable object (first long arrow) with all its events piped into an operator function and transformed. All new values are emitted by means of a new Observable.
In chapter 9, we’ll create our own little library of operators. These pipeable operators are themselves higher-order functions, and the functions you provide to them encode your domain-specific business logic. As I said at the beginning of this chapter, and as you’ll see time and time again throughout the book, higher-order functions are by far the strongest feature of JavaScript.
I hope that this overview sounds exciting. I’ve kept the discussion at a high level for now, but each chapter after this one will dive into lots of detail and code. In this book, you’ll not only be exposed to new cutting-edge techniques, but also see them implemented in the context of a more contemporary type of application. Before we dive into all those nifty topics, let me introduce you to the sample application we’ll be building throughout this book. Section 1.6 helps set the context for all the code you’ll see.
It’s been my experience that most programming books use trivial examples, often numeric or foo/bar, to demonstrate a particular feature of a technology. Although these examples are effective because they assume zero domain knowledge, the downside is that you’re left wondering how they fit into a more complex, realistic application.
If you haven’t been living under a rock for the past few years, you’ve seen a lot of hype about blockchain and cryptocurrencies, which have taken the world by storm. Many analysts consider blockchain to be one of the most important technologies to learn in the years to come. Blockchains are so ubiquitous and prevalent nowadays that getting familiar with them will add an invaluable skill to your tool belt—not to mention the fact that blockchains are cool. Certainly, teaching this technology is not simple, but this application is deliberately kept small and simple to fit in this book. No ramp-up is needed, and no background is required. Your own passion and drive, with some JavaScript background, are the only prerequisites.
In this book, we’ll build some parts of a simple, naive blockchain protocol from scratch to illustrate how we can apply modern JavaScript techniques to a real-world problem. Because the focus is on teaching JavaScript, teaching blockchain is purely pedagogical and far from a production-ready implementation. Nevertheless, you’ll be exposed to some interesting techniques from the blockchain world, such as immutability, hashing, mining, and proof of work. For the sake of exploring the wide breadth of JavaScript features, we’ll find creative ways to plug in as many features and techniques as possible into this small, contrived sample application.
To give you some background, a blockchain is a type of database made up of a list of records (called blocks) that may store any type of data in some chronological order. Unlike traditional databases, blocks are immutable records; you can never alter the contents of a block, only add new ones.
Blocks are linked cryptographically. No pointer or reference connects one block to the next, as in a linked list. Rather, each block contains a cryptographically secure hash (such as SHA-256), and the hash of a new block depends on the hash of the block that preceded it, thereby forming a chain. Because every block is hashed from the previous block’s hash, this chain is inherently tamperproof. Manipulating even a single property of any transaction in the history of all blocks will result in a different hash value that will invalidate the entire chain. This fact is one of the main reasons why blockchain data structures are desired not only in financial software, but also in secure document-storage solutions, online voting, and other industry segments.
The process of computing block hashes daisy-chains all the way back to the first block in the chain, which is known as the genesis, or block of height 0. In real life, a blockchain is much more complex. For purposes of this book, though, it’s enough to picture it as a sequential data structure in which each block stores the most recent transactions that occurred. This simplified structure is shown in figure 1.13.
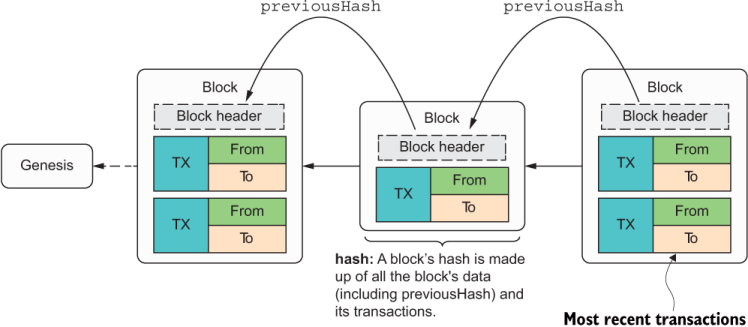
Figure 1.13 A simple representation of a blockchain, in which each block stores the previous block’s hash. This hash is used to compute the current block’s own hash, effectively connecting all these blocks in a chain.
As you can see in the figure, each block is made up of a block header, which is the metadata associated with each block. Part of this header is a field, previousHash, that stores the previous block’s hash. Aside from metadata, each block may contain a payload, which more commonly is a set of transactions. The latest block contains the most recent transactions that were pending in the chain at the moment it was created.
A transaction looks like a typical bank transaction and has the form “A transferred X amount of funds to B,” where A and B are cryptographic public keys that identify the parties involved in the transaction. Because the blockchain contains all the transactions that occurred in history, in the world of digital currencies like Bitcoin, it is known as a public ledger. Unlike your bank account, which is private, a blockchain like Bitcoin is public. You might be thinking, “My bank is in charge of validating every transaction, so who validates these transactions?” Through a process called mining, which you’ll learn about in chapter 8, you can validate all the transactions stored in a block, as well as all those stored in history. Mining is a resource-intensive process. While mining is happening, the transactions are said to be pending. All these pending transactions combine to form the next block’s data payload. When the block gets added to the blockchain, the transaction is complete.
A cryptocurrency acquires monetary value when the backing resource is scarce and expensive to find, extract, or “mine,” such as gold, diamonds, or oil. Computers can use their powerful processors or arithmetic logic units to perform high-speed math that solves a mathematical problem, which is known as proof of work. We’ll look at the implementation details of our proofOfWork function in chapter 7.
Consider an example of how a transaction is added and then secured by the blockchain protocol. Suppose that Luke buys coffee from Ana’s Café for 10 Bitcoin. Users are identified by their digital wallets. The payment process triggers logic to transfer funds in the form of a new pending transaction. The set of pending transactions is stored inside a block; then the block is mined and added to the chain for validation to occur. If all validation checks are good, the transactions are said to be complete. The incentive for a miner to run this expensive proof-of-work computation is that there’s a reward for mining. This protocol is summarized in figure 1.14.
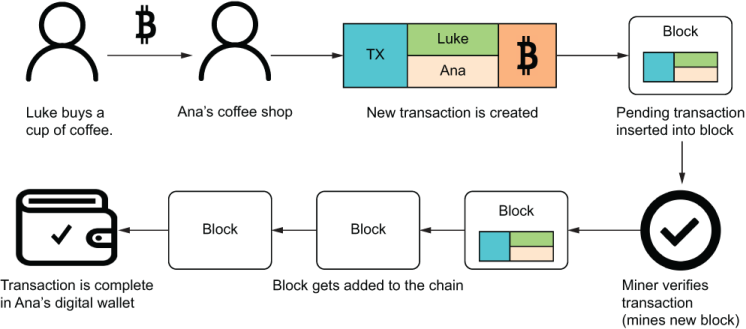
Figure 1.14 Luke buys coffee from Ana’s coffee shop, paying with his digital wallet. The payment process creates a new transaction, set to pending. After a certain period, miners compete to validate this transaction. Then all the transactions that happened, including Luke’s payment, are added as a block in the chain, and the payment is complete.
Taking these concepts into account, figure 1.15 shows a simple diagram of all the objects involved in this sequence.
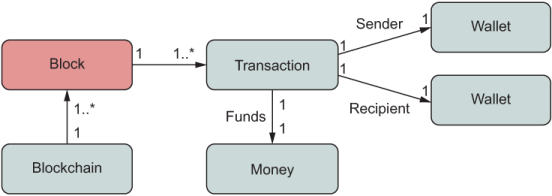
Figure 1.15 The main objects of the domain layer at play in our simple blockchain application
As we progress through the chapters, we’ll flesh out all these objects as well as the business logic that ties them together. Concretely, we’ll implement code to validate the entire chain, calculate the Bitcoin balance of a specific user (wallet account), execute a simple proof-of-work algorithm, and mine a block into a blockchain.
This 10,000-foot introduction to some of the ideas and new concepts covered in this book scratches the surface. By the end, you’ll see that JavaScript possesses all the expressive power you need to let your limitless creativity and imagination run wild while writing lean and clean code.
So welcome aboard. I trust that you will find this book fun and engaging as you embark on the journey that is the joy of JavaScript!
JavaScript has two important features that differentiate it from other languages: a prototype-based object model and higher-order functions. You can combine these features in systematic ways to craft powerful, elegant code.
TC39, ECMAScript’s standards body, has committed to releasing new features to JavaScript every year. Now we have a community-driven process to evolve JavaScript following the ECMA standard as well as to fix any shortcomings quickly. In this book. you’ll learn how to use the bind and pipeline operators, code with observables, and use many other new features, all originating from this process.
JavaScript’s dynamic object model makes it easy to use mixin composition over prototype inheritance by taking advantage of dynamic object extension.
Abstractions should make code more specific or refined by stripping ideas down to their fundamental concepts. ADTs refine code branching, error handling, null checking, and other programming tasks.
FP uses techniques such as function composition to make your code leaner and more declarative.
JavaScript is one of the few languages that has had first-class support for asynchronous programming since the beginning. It was revamped with the advent of async/await, which completely abstracts the asynchronous nature of the code.
Observables use the streams programming model to provide a consistent pane of glass over any type of data source—synchronous, asynchronous, single-value, or infinite.