3 Advanced TDD

Hold on to your hats. The ride is about to get fast and bumpy. To quote Dr. Morbius as he led a tour of the Krell machine: “Prepare your minds for a new scale of scientific values.”
Sort 1
The last two examples in Chapter 2, “Test-Driven Development,” begged an interesting question. Where does the algorithm that we derive using test-driven development (TDD) come from? Clearly it comes from our brain, but not in the way we are used to. Somehow, the sequence of failing tests coaxes the algorithm out of our brain without the need to think it all through beforehand.
This raises the possibility that TDD may be a step-by-step, incremental procedure for deriving any algorithm for any problem. Think of it like solving a mathematical or geometric proof. You start from basic postulates—the degenerate failing tests. Then, one step at a time, you build up the solution to the problem.
At each step, the tests get more and more constraining and specific, but the production code gets more and more generic. This process continues until the production code is so general that you can’t think of any more tests that will fail. That solves the entire problem.
Let’s try this out. Let’s use the approach to derive an algorithm for sorting an array of integers.
If you can watch the video, this would be a good time, but in any case, please continue on to read the text that follows.
Watch related video: SORT 1
Access video by registering at informit.com/register
We begin, as usual, with a test that does nothing:
public class SortTest {
@Test
public void nothing() throws Exception {
}
}
The first failing test will be the degenerate case of an empty array:
public class SortTest {
@Test
public void sorted() throws Exception {
assertEquals(asList(), sort(asList()));
}
private List<Integer> sort(List<Integer> list) {
return null;
}
}
This obviously fails, but it is easy to make it pass:
private List<Integer> sort(List<Integer> list) {
return new ArrayList<>();
}
Stepping up one level in degeneracy, we try a list with one integer in it:
assertEquals(asList(1), sort(asList(1)));
This clearly fails, but we can make it pass by making the production code a bit more general:
private List<Integer> sort(List<Integer> list) {
return list;
}
Cute, right? And we saw that trick before, in the prime factors example in Chapter 2. It seems relatively common that the first two tests in a given problem are solved by returning the most degenerate answer, followed by the input argument.
The next test is trivial because it already passes: two elements in order. It could be argued that we shouldn’t even have written it because it’s not a failing test. But it’s nice to see these tests pass.
assertEquals(asList(1, 2), sort(asList(1, 2)));
If we reverse the order of the input array, the test will fail: two elements out of order.
assertEquals(asList(1, 2), sort(asList(2, 1)));
To make this pass, we’re going to have to do something marginally intelligent. If the input array has more than one element in it and the first two elements of the array are out of order, then we should swap them:
private List<Integer> sort(List<Integer> list) {
if (list.size() > 1) {
if (list.get(0) > list.get(1)) {
int first = list.get(0);
int second = list.get(1);
list.set(0, second);
list.set(1, first);
}
}
return list;
}
Maybe you can see where this is headed. If so, don’t spoil the surprise for everyone else. Also, remember this moment—we’ll be returning to it in the next section.
The next two tests pass already. In the first test, the input array is already in order. In the second test, the first two elements are out of order, and our current solution swaps them.
assertEquals(asList(1, 2, 3), sort(asList(1, 2, 3))); assertEquals(asList(1, 2, 3), sort(asList(2, 1, 3)));
The next failing test is three elements with the second two out of order:
assertEquals(asList(1, 2, 3), sort(asList(2, 3, 1)));
We get this one to pass by putting our compare and swap algorithm into a loop that walks down the length of the list:
private List<Integer> sort(List<Integer> list) {
if (list.size() > 1) {
for (int firstIndex=0; firstIndex < list.size()-1; firstIndex++) {
int secondIndex = firstIndex + 1;
if (list.get(firstIndex) > list.get(secondIndex)) {
int first = list.get(firstIndex);
int second = list.get(secondIndex);
list.set(firstIndex, second);
list.set(secondIndex, first);
}
}
}
return list;
}
Can you tell where this is going yet? Most of you likely do. Anyway, the next failing test case is three elements in reverse order:
assertEquals(asList(1, 2, 3), sort(asList(3, 2, 1)));
The failure results are telling. The sort function returns [2, 1, 3]. Note that the 3 got moved all the way to the end of the list. That’s good! But the first two elements are still out of order. It’s not hard to see why. The 3 got swapped with the 2, and then the 3 got swapped with the 1. But that left the 2 and 1 still out of order. They need to be swapped again.
So, the way to get this test to pass is to put the compare and swap loop into another loop that incrementally reduces the length of the comparing and swapping. Maybe that’s easier to read in code:
private List<Integer> sort(List<Integer> list) {
if (list.size() > 1) {
for (int limit = list.size() - 1; limit > 0; limit--) {
for (int firstIndex = 0; firstIndex < limit; firstIndex++) {
int secondIndex = firstIndex + 1;
if (list.get(firstIndex) > list.get(secondIndex)) {
int first = list.get(firstIndex);
int second = list.get(secondIndex);
list.set(firstIndex, second);
list.set(secondIndex, first);
}
}
}
}
return list;
}
To finish this off, let’s do a larger-scale test:
assertEquals(
asList(1, 1, 2, 3, 3, 3, 4, 5, 5, 5, 6, 7, 8, 9, 9, 9),
sort(asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 9,
3)));
This passes, so our sort algorithm appears to be complete.
Where did this algorithm come from? We did not design it up front. It just came from the set of small decisions we made in order to get each failing test to pass. It was an incremental derivation. Voila!
And what algorithm is this? Bubble sort, of course—one of the worst possible sorting algorithms.
So maybe TDD is a really good way to incrementally derive really bad algorithms.
Sort 2
Let’s try this again. This time we’ll choose a slightly different pathway. And again, view the video if possible, but then continue reading from this point.
Watch related video: SORT 2
Access video by registering at informit.com/register
We begin as we did before with the most degenerate tests possible and the code that makes them pass:
public class SortTest {
@Test
public void testSort() throws Exception {
assertEquals(asList(), sort(asList()));
assertEquals(asList(1), sort(asList(1)));
assertEquals(asList(1, 2), sort(asList(1, 2)));
}
private List<Integer> sort(List<Integer> list) {
return list;
}
}
As before, we then pose two items out of order:
assertEquals(asList(1, 2), sort(asList(2, 1)));
But now, instead of comparing and swapping them within the input list, we compare and create an entirely new list with the elements in the right order:
private List<Integer> sort(List<Integer> list) {
if (list.size() <= 1)
return list;
else {
int first = list.get(0);
int second = list.get(1);
if (first > second)
return asList(second, first);
else
return asList(first, second);
}
}
This is a good moment to pause and reflect. When we faced this test in the previous section, we blithely wrote the compare and swap solution as though it were the only possible way to pass the test. But we were wrong. In this example, we see another way.
This tells us that from time to time we may encounter failing tests that have more than one possible solution. Think of these as forks in the road. Which fork should we take?
Let’s watch how this fork proceeds.
The obvious next test is, as it was before, three elements in order:
assertEquals(asList(1, 2, 3), sort(asList(1, 2, 3)));
But unlike in the previous example, this test fails. It fails because none of the pathways through the code can return a list with more than two elements. However, making it pass is trivial:
private List<Integer> sort(List<Integer> list) {
if (list.size() <= 1)
return list;
else if (list.size() == 2){
int first = list.get(0);
int second = list.get(1);
if (first > second)
return asList(second, first);
else
return asList(first, second);
}
else {
return list;
}
}
Of course, this is silly, but the next test—three elements with the first two out of order—eliminates the silliness. This obviously fails:
assertEquals(asList(1, 2, 3), sort(asList(2, 1, 3)));
How the devil are we going to get this to pass? There are only two possibilities for a list with two elements, and our solution exhausts both of those possibilities. But with three elements, there are six possibilities. Are we really going to decode and construct all six possible combinations?
No, that would be absurd. We need a simpler approach. What if we use the law of trichotomy?
The law of trichotomy says that given two numbers A and B, there are only three possible relationships between them: A < B, A = B, or A > B. Okay, so let’s arbitrarily pick one of the elements of the list and then decide which of those relationships it has with the others.
The relevant code looks like this:
else {
int first = list.get(0);
int middle = list.get(1);
int last = list.get(2);
List<Integer> lessers = new ArrayList<>();
List<Integer> greaters = new ArrayList<>();
if (first < middle)
lessers.add(first);
if (last < middle)
lessers.add(last);
if (first > middle)
greaters.add(first);
if (last > middle)
greaters.add(last);
List<Integer> result = new ArrayList<>();
result.addAll(lessers);
result.add(middle);
result.addAll(greaters);
return result;
}
Now, don’t freak out. Let’s walk through this together.
First, we extract the three values into the three named variables: first, middle, and last. We do this for convenience because we don’t want a bunch of list.get(x) calls littering up the code.
Next, we create a new list for the elements that are less than the middle and another for the elements that are greater than the middle. Note that we are assuming the middle is unique in the list.
Then, in the four subsequent if statements, we place the first and last elements into the appropriate lists.
Finally, we construct the result list by placing the lessers, the middle, and then the greaters into it.
Now you may not like this code. I don’t much care for it either. But it works. The tests pass.
And the next two tests pass as well:
assertEquals(asList(1, 2, 3), sort(asList(1, 3, 2))); assertEquals(asList(1, 2, 3), sort(asList(3, 2, 1)));
So far, we’ve tried four of the six possible cases for a list of three unique elements. If we had tried the other two, [2,3,1] and [3,1,2], as we should have, both of them would have failed.
But due either to impatience or oversight, we move on to test a lists with four elements:
assertEquals(asList(1, 2, 3, 4), sort(asList(1, 2, 3, 4)));
This fails, of course, because the current solution assumes that the list has no more than three elements. And, of course, our simplification of first, middle, and last breaks down with four elements. This may make you wonder why we chose the middle as element 1. Why couldn’t it be element 0?
So, let’s comment out that last test and change middle to element 0:
int first = list.get(1); int middle = list.get(0); int last = list.get(2);
Surprise—the [1,3,2] test fails. Can you see why? If middle is 1, then the 3 and 2 get added to the greaters list in the wrong order.
Now, it just so happens that our solution already knows how to sort a list with two elements in it. And greaters is such a list, so we can make this pass by calling sort on the greaters list:
List<Integer> result = new ArrayList<>(); result.addAll(lessers); result.add(middle); result.addAll(sort(greaters)); return result;
That caused the [1,3,2] test to pass but failed the [3,2,1] test because the lessers list was out of order. But that’s a pretty easy fix:
List<Integer> result = new ArrayList<>(); result.addAll(sort(lessers)); result.add(middle); result.addAll(sort(greaters)); return result;
So, yeah, we should have tried the two remaining cases of three elements before going on to the four-element list.
Rule 7: Exhaust the current simpler case before testing the next more complex case.
Anyway, now we need to get that four-element list to pass. So, we uncommented the test and saw it fail (not shown).
The algorithm we currently have for sorting the three-element list can be generalized, especially now that the middle variable is the first element of the list. All we have to do to build the lessers and greaters lists is apply filters:
else {
int middle = list.get(0);
List<Integer> lessers =
list.stream().filter(x -> x<middle).collect(toList());
List<Integer> greaters =
list.stream().filter(x -> x>middle).collect(toList());
List<Integer> result = new ArrayList<>();
result.addAll(sort(lessers));
result.add(middle);
result.addAll(sort(greaters));
return result;
}
It should come as no surprise that this passes and also passes the next two tests:
assertEquals(asList(1, 2, 3, 4), sort(asList(2, 1, 3, 4))); assertEquals(asList(1, 2, 3, 4), sort(asList(4, 3, 2, 1)));
But now you may be wondering about that middle. What if the middle element was not unique in the list? Let’s try that:
assertEquals(asList(1, 1, 2, 3), sort(asList(1, 3, 1, 2)));
Yeah, that fails. That just means we should stop treating the middle as something special:
else {
int middle = list.get(0);
List<Integer> middles =
list.stream().filter(x -> x == middle).collect(toList());
List<Integer> lessers =
list.stream().filter(x -> x<middle).collect(toList());
List<Integer> greaters =
list.stream().filter(x -> x>middle).collect(toList());
List<Integer> result = new ArrayList<>();
result.addAll(sort(lessers));
result.addAll(middles);
result.addAll(sort(greaters));
return result;
}
This passes. However, look up at that else. Remember what’s above it? Here, I’ll show you:
if (list.size() <= 1)
return list;
else if (list.size() == 2){
int first = list.get(0);
int second = list.get(1);
if (first > second)
return asList(second, first);
else
return asList(first, second);
}
Is that ==2 case really necessary anymore? No. Removing it still passes all tests.
Okay, so what about that first if statement? Is that still necessary? Actually, it can be changed to something better. And, in fact, let me just show you the final algorithm:
private List<Integer> sort(List<Integer> list) {
List<Integer> result = new ArrayList<>();
if (list.size() == 0)
return result;
else {
int middle = list.get(0);
List<Integer> middles =
list.stream().filter(x -> x == middle).collect(toList());
List<Integer> lessers =
list.stream().filter(x -> x < middle).collect(toList());
List<Integer> greaters =
list.stream().filter(x -> x > middle).collect(toList());
result.addAll(sort(lessers));
result.addAll(middles);
result.addAll(sort(greaters));
return result;
}
}
This algorithm has a name. It’s called quick sort. It is one of the best sorting algorithms known.
How much better it is? This algorithm, on my laptop, can sort an array of 1 million random integers between zero and a million in 1.5 seconds. The bubble sort from the previous section will sort the same list in about six months. So … better.
And this leads us to a disturbing observation. There were two different solutions to sorting a list with two elements out of order. One solution led us directly to a bubble sort, the other solution led us directly to a quick sort.
This means that identifying forks in the road, and choosing the right path, can sometimes be pretty important. In this case, one path led us to a pretty poor algorithm, and the other led us to a very good algorithm.
Can we identify these forks and determine which path to choose? Perhaps. But that’s a topic for a more advanced chapter.
Getting Stuck
At this point, I think you’ve seen enough videos to get a good idea about the rhythm of TDD. From now on, we’ll forego the videos and just rely on the text of the chapter.
It often happens, to TDD novices, that they find themselves in a pickle. They write a perfectly good test and then discover that the only way to make that test pass is to implement the entire algorithm at once. I call this “getting stuck.”
The solution to getting stuck is to delete the last test you wrote and find a simpler test to pass.
Rule 8: If you must implement too much to get the current test to pass, delete that test and write a simpler test that you can more easily pass.
I often use the following exercise in my classroom sessions to get people stuck. It’s pretty reliable. Well over half the people who try it find themselves stuck and also find it difficult to back out.
The problem is the good-old word-wrap problem: Given a string of text without any line breaks, insert appropriate line breaks so that the text will fit in a column N characters wide. Break at words if at all possible.
Students are supposed to write the following function:
Wrapper.wrap(String s, int w);
Let’s suppose that the input string is the Gettysburg Address:
"Four score and seven years ago our fathers brought forth upon this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equal"
Now, if the desired width is 30, then the output should be
====:====:====:====:====:====: Four score and seven years ago Our fathers brought forth upon This continent a new nation Conceived in liberty and Dedicated to the proposition That all men are created equal ====:====:====:====:====:====:
How would you write this algorithm test-first? We might begin as usual with this failing test:
public class WrapTest {
@Test
public void testWrap() throws Exception {
assertEquals("Four", wrap("Four", 7));
}
private String wrap(String s, int w) {
return null;
}
}
How many TDD rules did we break with this test? Can you name them? Let’s proceed anyway. It’s easy to make this test pass:
private String wrap(String s, int w) {
return "Four";
}
The next test seems pretty obvious:
assertEquals("Four\nscore", wrap("Four score", 7));
And the code that makes that pass is pretty obvious too:
private String wrap(String s, int w) {
return s.replace(" ", "\n");
}
Just replace all spaces with line ends. Perfect. Before we continue, let’s clean this up a bit:
private void assertWrapped(String s, int width, String expected) {
assertEquals(expected, wrap(s, width));
}
@Test
public void testWrap() throws Exception {
assertWrapped("Four", 7, "Four");
assertWrapped("Four score", 7, "Four\nscore");
}
That’s better. Now, the next failing test. If we simply follow the Gettysburg Address along, the next failure would be
assertWrapped("Four score and seven years ago our", 7,
"Four\nscore\nand\nseven\nyears\nago our");
That does, in fact, fail. We can tighten that failure up a bit like so:
assertWrapped("ago our", 7, "ago our");
Okay, now how do we make that pass? It looks like we need to not replace all spaces with line ends. So, which ones do we replace? Or, should we go ahead and replace all spaces with line ends, and then figure out which line ends to put back?
I’ll let you ponder this for a while. I don’t think you’ll find an easy solution. And that means we’re stuck. The only way to get this test to pass is to invent a very large part of the word-wrap algorithm at once.
The solution to being stuck is to delete one or more tests and replace them with simpler tests that you can pass incrementally. Let’s try that:
@Test
public void testWrap() throws Exception {
assertWrapped("", 1, "");
}
private String wrap(String s, int w) {
return "";
}
Ah, yes, that’s a truly degenerate test, isn’t it? That’s one of the rules we forgot earlier.
Okay, what’s the next most degenerate test? How about this?
assertWrapped("x", 1, "x");
That’s pretty degenerate. It’s also really easy to pass:
private String wrap(String s, int w) {
return s;
}
There’s that pattern again. We get the first test to pass by returning the degenerate constant. We get the second test to pass by returning the input. Interesting. Okay, so what’s the next most degenerate test?
assertWrapped("xx", 1, "x\nx");
That fails because it returns "xx". It’s not hard to get it to pass, though:
private String wrap(String s, int w) {
if (w >= s.length())
return s;
else
return s.substring(0, w) + "\n" + s.substring(w);
}
That was easy. So, what’s the next most degenerate test?
assertWrapped("xx", 2, "xx");
That already passes. Nice. So, the next test would be
assertWrapped("xxx", 1, "x\nx\nx");
This fails. And it implies some kind of a loop. But wait. There’s an easier way:
private String wrap(String s, int w) {
if (w >= s.length())
return s;
else
return s.substring(0, w) + "\n" + wrap(s.substring(w), w);
}
We don’t often think of recursion, do we? Perhaps we should think about it more often.
We’ve got a nice little pattern cooking in our tests, don’t we? No words, not even any spaces yet. Just a string of x’s with counts walking from 1 to the size of the string. So, the next test will be
assertWrapped("xxx", 2, "xx\nx");
And that one already passes. So does the next one:
assertWrapped("xxx", 3, "xxx");
There’s probably no point in continuing with this pattern. It’s time for some spaces:
assertWrapped("x x", 1, "x\nx");
This one fails because it returns "x\n \nx". We can fix that by eliminating any prefix spaces before we do the recursive call to wrap.
return s.substring(0, w) + "\n" + wrap(s.substring(w).trim(), w);
This passes. And now we have a new test pattern to follow. So, the next test is
assertWrapped("x x", 2, "x\nx");
This fails because the first substring has a trailing space. We can get rid of that with another call to trim:
return s.substring(0, w).trim() + "\n" + wrap(s.substring(w).trim(), w);
And this passes. The next test in the sequence passes too:
assertWrapped("x x", 3, "x x");
What’s next? We could try these:
assertWrapped("x x x", 1, "x\nx\nx");
assertWrapped("x x x", 2, "x\nx\nx");
assertWrapped("x x x", 3, "x x\nx");
assertWrapped("x x x", 4, "x x\nx");
assertWrapped("x x x", 5, "x x x");
They all pass. There’s probably not much point in adding the fourth x.
Let’s try this:
assertWrapped("xx xx", 1, "x\nx\nx\nx");
That one passes. And so do the next two tests in the sequence:
assertWrapped("xx xx", 2, "xx\nxx");
assertWrapped("xx xx", 3, "xx\nxx");
But the next test fails:
assertWrapped("xx xx", 4, "xx\nxx");
It fails because it returns "xx x\nx". And that’s because it did not break on the space between the two “words.” Where is that space? It’s before the wth character. So, we need to search backwards from w for a space:
private String wrap(String s, int w) {
if (w >= s.length())
return s;
else {
int br = s.lastIndexOf(" ", w);
if (br == -1)
br = w;
return s.substring(0, br).trim() + "\n" +
wrap(s.substring(br).trim(), w);
}
}
This passes. I have a feeling that we are done. But let’s try a few more test cases:
assertWrapped("xx xx", 5, "xx xx");
assertWrapped("xx xx xx", 1, "x\nx\nx\nx\nx\nx");
assertWrapped("xx xx xx", 2, "xx\nxx\nxx");
assertWrapped("xx xx xx", 3, "xx\nxx\nxx");
assertWrapped("xx xx xx", 4, "xx\nxx\nxx");
assertWrapped("xx xx xx", 5, "xx xx\nxx");
assertWrapped("xx xx xx", 6, "xx xx\nxx");
assertWrapped("xx xx xx", 7, "xx xx\nxx");
assertWrapped("xx xx xx", 8, "xx xx xx");
They all pass. I think we’re done. Let’s try the Gettysburg Address, with a length of 15:
Four score and seven years ago our fathers brought forth upon this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equal
That looks right.
So, what did we learn? First, if you get stuck, back out of the tests that got you stuck, and start writing simpler tests. But second, when writing tests, try to apply
Rule 9: Follow a deliberate and incremental pattern that covers the test space.
Arrange, Act, Assert
And now for something completely different.
Many years ago, Bill Wake identified the fundamental pattern for all tests. He called it the 3A pattern, or AAA. It stands for Arrange/Act/Assert.
The first thing you do when writing a test is arrange the data to be tested. This is typically done in a Setup method, or at the very beginning of the test function. The purpose is to put the system into the state necessary to run the test.
The next thing the test does is act. This is when the test calls the function, or performs the action, or otherwise invokes the procedure that is the target of the test.
The last thing the test does is assert. This usually entails looking at the output of the act to ensure that the system is in the new desired state.
As a simple example of this pattern consider this test from the bowling game in Chapter 2:
@Test
public void gutterGame() throws Exception {
rollMany(20, 0);
assertEquals(0, g.score());
}
The arrange portion of this test is the creation of the Game in the Setup function and the rollMany(20, 0) to set up the scoring of a gutter game.
The act portion of the test is the call to g.score().
The assert portion of the test is the assertEquals.
In the two and a half decades since I started practicing TDD, I have never found a test that did not follow this pattern.
Enter BDD
In 2003, while practicing and teaching TDD, Dan North, in collaboration with Chris Stevenson and Chris Matz, made the same discovery that Bill Wake had made. However, they used a different vocabulary: Given-When-Then (GWT).
This was the beginning of behavior-driven development (BDD).
At first, BDD was viewed as an improved way of writing tests. Dan and other proponents liked the vocabulary better and affixed that vocabulary into testing tools such as JBehave, and RSpec.
As an example, I can rephrase the gutterGame test in BDD terms as follows:
Given that the player rolled a game of 20 gutter balls, When I request the score of that game, Then the score will be zero.
It should be clear that some parsing would have to take place in order to translate that statement into an executable test. JBehave and RSpec provided affordances for that kind of parsing. It also ought to be clear that the TDD test and the BDD test are synonymous.
Over time, the vocabulary of BDD drew it away from testing and toward the problem of system specification. BDD proponents realized that even if the GWT statements were never executed as tests, they remained valuable as specifications of behavior.
In 2013, Liz Keogh said of BDD:
It’s using examples to talk through how an application behaves. … And having conversations about those examples.
Still, it is hard to separate BDD entirely from testing if only because the vocabulary of GWT and AAA are so obviously synonymous. If you have any doubts about that, consider the following:
Given that the test data has been Arranged
When I execute the tested Act
Then the expected result is Asserted
Finite State Machines
The reason I made such a big deal out of the synonymity of GWT and AAA is that there is another famous triplet that we frequently encounter in software: the transition of a finite state machine.
Consider the state/transition diagram of a simple subway turnstile (Figure 3.1).
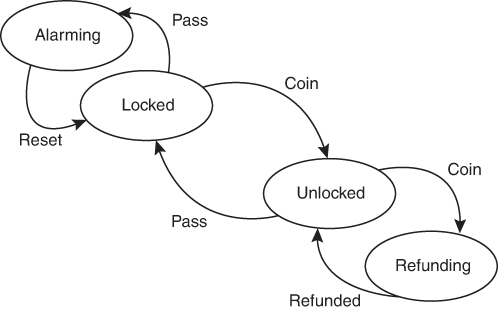
Figure 3.1 Transition/state diagram for a subway turnstile
The turnstile starts in the locked state. A coin will send it to the unlocked state. When someone passes through, the turnstile returns to the locked state. If someone passes without paying, the turnstile alarms. If someone drops two coins, the extra coin is refunded.
This diagram can be turned into a state transition table as follows:
Current State |
Event |
Next State |
|---|---|---|
Locked |
Coin |
Unlocked |
Locked |
Pass |
Alarming |
Unlocked |
Coin |
Refunding |
Unlocked |
Pass |
Locked |
Refunding |
Refunded |
Unlocked |
Alarming |
Reset |
Locked |
Each row in the table is a transition from the current state to the next state triggered by the event. Each row is a triplet, just like GWT or AAA. More important, each one of those transition triplets is synonymous with a corresponding GWT or AAA triplet, as follows:
Given it is in the Locked state When it gets a Coin event Then it transitions to the Unlocked state.
What we can deduce from this is that every test you write is a transition of the finite state machine that describes the behavior of the system.
Repeat that to yourself several times. Every test is a transition of the finite state machine you are trying to create in your program.
Did you know that the program you are writing is a finite state machine? Of course it is. Every program is a finite state machine. That’s because computers are nothing more than finite state machine processors. The computer itself transitions from one finite state to the next with every instruction it executes.
Thus, the tests you write when practicing TDD and the behaviors you describe while practicing BDD are simply transitions of the finite state machine that you are attempting to create. Your test suite, if it is complete, is that finite state machine.
The obvious question, therefore, is how do you ensure that all the transitions you desire your state machine to handle are encoded as tests? How do you ensure that the state machine that your tests are describing is the complete state machine that your program should be implementing?
What better way than to write the transitions first, as tests, and then write the production code that implements those transitions?
BDD Again
And don’t you think it’s fascinating, and perhaps even a little ironic, that the BDD folks, perhaps without realizing it, have come to the conclusion that the best way to describe the behavior of a system is by specifying it as a finite state machine?
Test Doubles
In 2000, Steve Freeman, Tim McKinnon, and Philip Craig presented a paper1 called “Endo-Testing: Unit Testing with Mock Objects.” The influence this paper had on the software community is evidenced by the pervasiveness of the term they coined: mock. The term has since become a verb. Nowadays, we use mocking frameworks to mock things out.
1. Steve Freeman, Tim McKinnon, and Philip Craig, “Endo-Testing: Unit Testing with Mock Objects,” paper presented at eXtreme Programming and Flexible Processes in Software Engineering (XP2000), https://www2.ccs.neu.edu/research/demeter/related-work/extreme-programming/MockObjectsFinal.PDF.
In those early days, the notion of TDD was just beginning to permeate the software community. Most of us had never applied object-oriented design to test code. Most of us had never applied any kind of design at all to test code. This led to all kinds of problems for test authors.
Oh, we could test the simple things like the examples you saw in the previous chapters. But there was another class of problems that we just didn’t know how to test. For example, how do you test the code that reacts to an input/output (IO) failure? You can’t really force an IO device to fail in a unit test. Or how do you test the code that interacts with an external service? Do you have to have the external service connected for your tests? And how do you test the code that handles external service failure?
The original TDDers were Smalltalk programmers. For them, objects were what the universe was made of. So, although they were almost certainly using mock objects, they likely thought nothing of it. Indeed, when I presented the idea of a mock object in Java to one expert Smalltalker and TDDer in 1999, his response to me was: “Too much mechanism.”
Nevertheless, the technique caught hold and has become a mainstay of TDD practitioners.
But before we delve too much further into the technique itself, we need to clear up a vocabulary issue. Almost all of us use the term mock object incorrectly—at least in a formal sense. The mock objects we talk about nowadays are very different from the mock objects that were presented in the endo-testing paper back in 2000. So different, in fact, that a different vocabulary has been adopted to clarify the separate meanings.
In 2007, Gerard Meszaros published xUnit Test Patterns: Refactoring Test Code.2 In it, he adopted the formal vocabulary that we use today. Informally, we still talk about mocks and mocking, but when we want to be precise, we use Meszaros’s formal vocabulary.
2. Gerard Meszaros, xUnit Test Patterns: Refactoring Test Code (Addison-Wesley, 2007).
Meszaros identified five kinds of objects that fall under the informal mock category: dummies, stubs, spies, mocks, and fakes. He called them all test doubles.
That’s actually a very good name. In the movies, a stunt double stands in for an actor, and a hand double stands in for closeups of an actor’s hands. A body double stands in for shots when the body, and not the face, of the actor is on screen. And that’s just what a test double does. A test double stands in for another object while a test is being run.
Test doubles form a type hierarchy of sorts (Figure 3.2). Dummies are the simplest. Stubs are dummies, spies are stubs, and mocks are spies. Fakes stand alone.
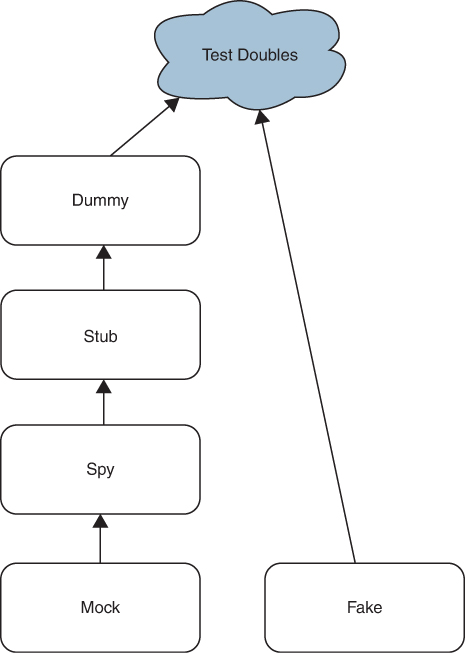
Figure 3.2 Test doubles
The mechanism that all test doubles use (and which my Smalltalker friend thought was “too much”) is simply polymorphism. For example, if you want to test the code that manages an external service, then you isolate that external service behind a polymorphic interface, and then you create an implementation of that interface that stands in for the service. That implementation is the test double.
But perhaps the best way to explain all this is to demonstrate it.
Dummy
Test doubles generally start with an interface—an abstract class with no implemented methods. For example, we could start with the Authenticator interface:
public interface Authenticator {
public Boolean authenticate(String username, String password);
}
The intent of this interface is to provide our application with a way to authenticate users by using usernames and passwords. The authenticate function returns true if the user is authentic and false if not.
Now let’s suppose that we want to test that a LoginDialog can be cancelled by clicking the close icon before the user enters a username and password. That test might look like this:
@Test
public void whenClosed_loginIsCancelled() throws Exception {
Authenticator authenticator = new ???;
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.sendEvent(Event.CLOSE);
assertTrue(success);
}
Notice that the LoginDialog class must be constructed with an Authenticator. But that Authenticator will never be called by this test, so what should we pass to the LoginDialog?
Let’s further assume that the RealAuthenticator is an expensive object to create because it requires a DatabaseConnection passed in to its constructor. And let’s say that the DatabaseConnection class has a constructor that requires valid UIDs for a databaseUser and databaseAuthCode. (I’m sure you’ve seen situations like this.)
public class RealAuthenticator implements Authenticator {
public RealAuthenticator(DatabaseConnection connection) {
//…
}
//…
}
public class DatabaseConnection {
public DatabaseConnection(UID databaseUser, UID databaseAuthCode) {
//…
}
}
To use the RealAuthenticator in our test, we’d have to do something horrible, like this:
@Test
public void whenClosed_loginIsCancelled() throws Exception {
UID dbUser = SecretCodes.databaseUserUID;
UID dbAuth = SecretCodes.databaseAuthCode;
DatabaseConnection connection =
new DatabaseConnection(dbUser, dbAuth);
Authenticator authenticator = new RealAuthenticator(connection);
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.sendEvent(Event.CLOSE);
assertTrue(success);
}
That’s a terrible load of cruft to put into our test just so that we can create an Authenticator that will never be used. It also adds two dependencies to our test, which the test does not need. Those dependencies could break our test at either compile or load time. We don’t need the mess or the headache.
Rule 10: Don’t include things in your tests that your tests don’t need.
So, what we do instead is use a dummy (Figure 3.3).
Figure 3.3 Dummy
A dummy is an implementation that does nothing. Every method of the interface is implemented to do nothing. If a method returns a value, then the value returned by the dummy will be as close as possible to null or zero.
In our example, the AuthenticatorDummy would look like this:
public class AuthenticatorDummy implements Authenticator {
public Boolean authenticate(String username, String password) {
return null;
}
}
In fact, this is the precise implementation that my IDE creates when I invoke the Implement Interface command.
Now the test can be written without all that cruft and all those nasty dependencies:
@Test
public void whenClosed_loginIsCancelled() throws Exception {
Authenticator authenticator = new AuthenticatorDummy();
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.sendEvent(Event.CLOSE);
assertTrue(success);
}
So, a dummy is a test double that implements an interface to do nothing. It is used when the function being tested takes an object as an argument, but the logic of the test does not require that object to be present.
I don’t use dummies very often for two reasons. First, I don’t like having functions with code pathways that don’t use the arguments of that function. Second, I don’t like objects that have chains of dependencies such as LoginDialog->Authenticator->DatabaseConnection->UID. Chains like that always cause trouble down the road.
Still, there are times when these problems cannot be avoided, and in those situations, I much prefer to use a dummy rather than fight with complicated objects from the application.
Stub
As Figure 3.4 shows, a stub is a dummy; it is implemented to do nothing. However, instead of returning zero or null, the functions of a stub return values that drive the function being tested through the pathways that the test wants executed.
Figure 3.4 Stub
Let’s imagine the following test that ensures that a login attempt will fail if the Authenticator rejects the username and password:
public void whenAuthorizerRejects_loginFails() throws Exception {
Authenticator authenticator = new ?;
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.submit("bad username", "bad password");
assertFalse(success);
}
If we were to use the RealAuthenticator here, we would still have the problem of initializing it with all the cruft of the DatabaseConnection and the UIDs. But we’d also have another problem. What username and password should we use?
If we know the contents of the authorization database, then we could select a username and password that we know is not present. But that’s a horrible thing to do because it creates a data dependency between our tests and production data. If that production data ever changes, it could break our test.
Rule 11: Don’t use production data in your tests.
What we do instead is create a stub. For this test, we need a RejectingAuthenticator that simply returns false from the authorize method:
public class RejectingAuthenticator implements Authenticator {
public Boolean authenticate(String username, String password) {
return false;
}
}
And now we can simply use that stub in our test:
public void whenAuthorizerRejects_loginFails() throws Exception {
Authenticator authenticator = new RejectingAuthenticator();
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.submit("bad username", "bad password");
assertFalse(success);
}
We expect that the submit method of the LoginDialog will call the authorize function, and we know that the authorize function will return false, so we know what pathway the code in the LoginDialog.submit method will take; and that is precisely the path we are testing.
If we want to test that login succeeds when the authorizer accepts the username and password, we can play the same game with a different stub:
public class PromiscuousAuthenticator implements Authenticator {
public Boolean authenticate(String username, String password) {
return true;
}
}
@Test
public void whenAuthorizerAccepts_loginSucceeds() throws Exception {
Authenticator authenticator = new PromiscuousAuthenticator();
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.submit("good username", "good password");
assertTrue(success);
}
So, a stub is a dummy that returns test-specific values in order to drive the system under test through the pathways being tested.
Spy
A spy (Figure 3.5) is a stub. It returns test-specific values in order to drive the system under test through desired pathways. However, a spy remembers what was done to it and allows the test to ask about it.
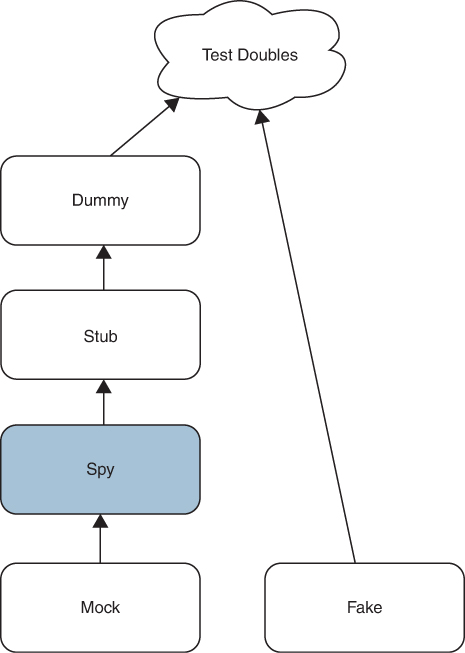
Figure 3.5 Spy
The best way to explain that is with an example:
public class AuthenticatorSpy implements Authenticator {
private int count = 0;
private boolean result = false;
private String lastUsername = "";
private String lastPassword = "";
public Boolean authenticate(String username, String password) {
count++;
lastPassword = password;
lastUsername = username;
return result;
}
public void setResult(boolean result) {this.result = result;}
public int getCount() {return count;}
public String getLastUsername() {return lastUsername;}
public String getLastPassword() {return lastPassword;}
}
Note that the authenticate method keeps track of the number of times it was called and the last username and password that it was called with. Notice also that it provides accessors for these values. It is that behavior and those accessors that make this class a spy.
Notice also that the authenticate method returns result, which can be set by the setResult method. That makes this spy a programmable stub.
Here’s a test that might use that spy:
@Test
public void loginDialog_correctlyInvokesAuthenticator() throws
Exception {
AuthenticatorSpy spy = new AuthenticatorSpy();
LoginDialog dialog = new LoginDialog(spy);
spy.setResult(true);
dialog.show();
boolean success = dialog.submit("user", "pw");
assertTrue(success);
assertEquals(1, spy.getCount());
assertEquals("user", spy.getLastUsername());
assertEquals("pw", spy.getLastPassword());
}
The name of the test tells us a lot. This test makes sure that the LoginDialog correctly invokes the Authenticator. It does this by making sure that the authenticate method is called only once and that the arguments were the arguments that were passed into submit.
A spy can be as simple as a single Boolean that is set when a particular method is called. Or a spy can be a relatively complex object that maintains a history of every call and every argument passed to every call.
Spies are useful as a way to ensure that the algorithm being tested behaves correctly. Spies are dangerous because they couple the tests to the implementation of the function being tested. We’ll have more to say about this later.
Mock
Now, at last, we come to the true mock object (Figure 3.6). This is the mock that Mackinnon, Freeman, and Craig described in their endo-testing paper.
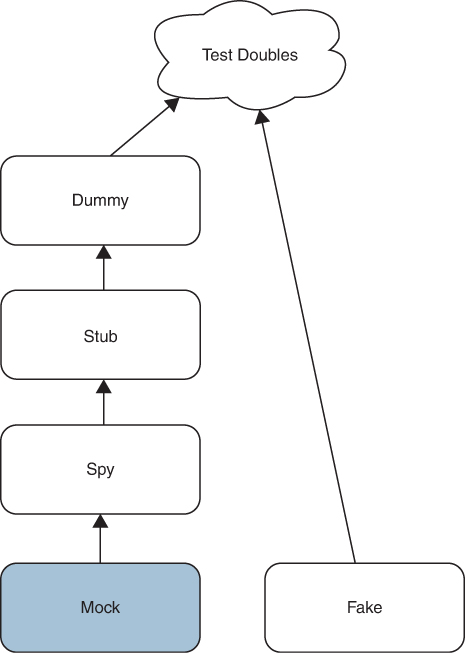
Figure 3.6 The mock object
A mock is a spy. It returns test-specific values in order to drive the system under test through desired pathways, and it remembers what was done to it. However, a mock also knows what to expect and will pass or fail the test on the basis of those expectations.
In other words, the test assertions are written into the mock.
Again, an explanation in code is worth all the words I can write about this, so let’s build an AuthenticatorMock:
public class AuthenticatorMock extends AuthenticatorSpy{
private String expectedUsername;
private String expectedPassword;
private int expectedCount;
public AuthenticatorMock(String username, String password,
int count) {
expectedUsername = username;
expectedPassword = password;
expectedCount = count;
}
public boolean validate() {
return getCount() == expectedCount &&
getLastPassword().equals(expectedPassword) &&
getLastPassword().equals(expectedUsername);
}
}
As you can see, the mock has three expectation fields that are set by the constructor. This makes this mock a programmable mock. Notice also that the AuthenticatorMock derives from the AuthenticatorSpy. We reuse all that spy code in the mock.
The validate function of the mock does the final comparison. If the count, lastPassword, and lastUsername collected by the spy match the expectations set into the mock, then validate returns true.
Now the test that uses this mock should make perfect sense:
@Test
public void loginDialogCallToAuthenticator_validated() throws
Exception {
AuthenticatorMock mock = new AuthenticatorMock("Bob", "xyzzy", 1);
LoginDialog dialog = new LoginDialog(mock);
mock.setResult(true);
dialog.show();
boolean success = dialog.submit("Bob", "xyzzy");
assertTrue(success);
assertTrue(mock.validate());
}
We create the mock with the appropriate expectations. The username should be "Bob", the password should be "xyzzy", and the number of times the authenticate method is called should be 1.
Next, we create the LoginDialog with the mock, which is also an Authenticator. We set the mock to return success. We show the dialog. We submit the login request with "Bob" and "xyzzy". We ensure that the login succeeded. And then we assert the mock’s expectations were met.
That’s a mock object. You can imagine that mock objects can get very complicated. For example, you might expect function f to be called three times with three different sets of arguments, returning three different values. You might also expect function g to be called once between the first two calls to f. Would you even dare to write that mock without unit tests for the mock itself?
I don’t much care for mocks. They couple the spy behavior to the test assertions. That bothers me. I think a test should be very straightforward about what it asserts and should not defer those assertions to some other, deeper mechanism. But that’s just me.
Fake
Finally, we can deal with the last of the test doubles: the fake (Figure 3.7). A fake is not a dummy, not a stub, not a spy, and not a mock. A fake is a different kind of test double entirely. A fake is a simulator.
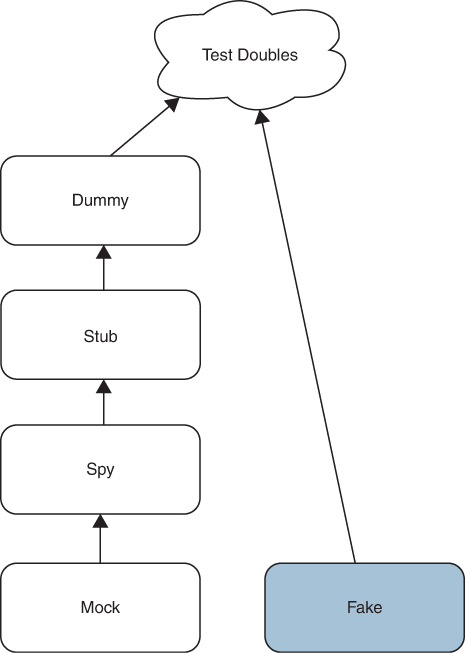
Figure 3.7 The fake
Long ago, in the late 1970s, I worked for a company that built a system that was installed into telephone company facilities. This system tested telephone lines. There was a central computer at the service center that communicated over modem links to computers we installed in the switching offices. The computer in the service center was called the SAC (service area computer), and the computer in the switching office was called the COLT (central office line tester).
The COLT interfaced to the switching hardware and could create an electrical connection between any of the phone lines emanating from that switching office and the measurement hardware that it controlled. The COLT would then measure the electronic characteristics of the phone line and report the raw results back to the SAC.
The SAC did all the analysis on those raw results in order to determine whether there was a fault and, if so, where that fault was located.
How did we test that system?
We built a fake. The fake we built was a COLT whose switching interface was replaced with a simulator. That simulator would pretend to dial up phone lines and pretend to measure them. Then it would report back canned raw results based on the phone number it was asked to test.
The fake allowed us to test the SAC communication, control, and analysis software without having to install an actual COLT in a real telephone company switching office or even having to install real switching hardware and “real” phone lines.
Today, a fake is a test double that implements some kind of rudimentary business rules so that the tests that use that fake can select how the fake behaves. But perhaps an example would be the best explanation:
@Test
public void badPasswordAttempt_loginFails() throws Exception {
Authenticator authenticator = new FakeAuthenticator();
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.submit("user", "bad password");
assertFalse(success);
}
@Test
public void goodPasswordAttempt_loginSucceeds() throws Exception {
Authenticator authenticator = new FakeAuthenticator();
LoginDialog dialog = new LoginDialog(authenticator);
dialog.show();
boolean success = dialog.submit("user", "good password");
assertTrue(success);
}
These two tests use the same FakeAuthorizer but pass it a different password. The tests expect that bad password will fail the login attempt and that good password will succeed.
The code for FakeAuthenticator should be easy to envision:
public class FakeAuthenticator implements Authenticator {
public Boolean authenticate(String username, String password)
{
return (username.equals("user") &&
password.equals("good password"));
}
}
The problem with fakes is that as the application grows, there will always be more conditions to test. Consequently, the fakes tend to grow with each new tested condition. Eventually, they can get so large and complex that they need tests of their own.
I seldom write fakes because I don’t trust them not to grow.
The TDD Uncertainty Principle
To mock or not to mock, that is the question. Actually, no. The question really is when to mock.
There are two schools of thought about this: the London school and the Chicago school, which are addressed at the end of this chapter. But before we get into that, we need to define why this is an issue in the first place. It is an issue because of the TDD uncertainty principle.
To help us understand this, I want you to indulge me in a playful bit of “going to extremes.” What follows is not something you would ever really do, but it illustrates quite nicely the point I’m trying to make.
Imagine that we want to use TDD to write a function that calculates the trigonometric sine of an angle represented in radians. What’s the first test?
Remember, we like to start with the most degenerate case. Let’s test that we can calculate the sine of zero:
public class SineTest {
private static final double EPSILON = 0.0001;
@Test
public void sines() throws Exception {
assertEquals(0, sin(0), EPSILON);
}
double sin(double radians) {
return 0.0;
}
}
Now, if you are thinking ahead, this should already bother you. This test does not constrain anything other than the value of sin(0).
What do I mean by that? I mean that most of the functions we write using TDD are so constrained by the growing set of tests that there comes a point where the function will pass any other test we can pose. We saw that in the prime factors example and the bowling game example. Each test narrowed the possible solution until finally the solution was known.
But here, the sin(r) function does not look to behave that way. The test for sin(0) == 0 is correct, but it does not appear to constrain the solution beyond that one point.
This becomes much more evident when we try the next test. What should that test be? Why not try sin(π)?
public class SineTest {
private static final double EPSILON = 0.0001;
@Test
public void sines() throws Exception {
assertEquals(0, sin(0), EPSILON);
assertEquals(0, sin(Math.PI), EPSILON);
}
double sin(double radians) {
return 0.0;
}
}
Once again, we have that feeling of being unconstrained. This test doesn’t seem to add anything to the solution. It gives us no hint of how to solve the problem, so let’s try π/2:
public class SineTest {
private static final double EPSILON = 0.0001;
@Test
public void sines() throws Exception {
assertEquals(0, sin(0), EPSILON);
assertEquals(0, sin(Math.PI), EPSILON);
assertEquals(1, sin(Math.PI/2), EPSILON);
}
double sin(double radians) {
return 0.0;
}
}
This fails. How can we make it pass? Again, the test gives us no hint about how to pass it. We could try to put some horrible if statement in, but that will just lead to more and more if statements.
At this point, you might think that the best approach would be to look up the Taylor series for sine and just implement that.
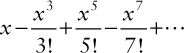
That shouldn’t be too hard:
public class SineTest {
private static final double EPSILON = 0.0001;
@Test
public void sines() throws Exception {
assertEquals(0, sin(0), EPSILON);
assertEquals(0, sin(Math.PI), EPSILON);
assertEquals(1, sin(Math.PI/2), EPSILON);
}
double sin(double radians) {
double r2 = radians * radians;
double r3 = r2*radians;
double r5 = r3 * r2;
double r7 = r5 * r2;
double r9 = r7 * r2;
double r11 = r9 * r2;
double r13 = r11 * r2;
return (radians - r3/6 + r5/120 - r7/5040 + r9/362880 -
r11/39916800.0 + r13/6227020800.0);
}
}
This passes, but it’s pretty ugly. Still, we ought to be able to calculate a few other sines this way:
public void sines() throws Exception {
assertEquals(0, sin(0), EPSILON);
assertEquals(0, sin(Math.PI), EPSILON);
assertEquals(1, sin(Math.PI/2), EPSILON);
assertEquals(0.8660, sin(Math.PI/3), EPSILON);
assertEquals(0.7071, sin(Math.PI/4), EPSILON);
assertEquals(0.5877, sin(Math.PI/5), EPSILON);
}
Yes, this passes. But this solution is ugly because it is limited in precision. We should take the Taylor series out to enough terms that it converges to the limit of our precision. (Note the change to the ESPILON constant.)
public class SineTest {
private static final double EPSILON = 0.000000001;
@Test
public void sines() throws Exception {
assertEquals(0, sin(0), EPSILON);
assertEquals(0, sin(Math.PI), EPSILON);
assertEquals(1, sin(Math.PI/2), EPSILON);
assertEquals(0.8660254038, sin(Math.PI/3), EPSILON);
assertEquals(0.7071067812, sin(Math.PI/4), EPSILON);
assertEquals(0.5877852523, sin(Math.PI/5), EPSILON);
}
double sin(double radians) {
double result = radians;
double lastResult = 2;
double m1 = -1;
double sign = 1;
double power = radians;
double fac = 1;
double r2 = radians * radians;
int n = 1;
while (!close(result, lastResult)) {
lastResult = result;
power *= r2;
fac *= (n+1) * (n+2);
n += 2;
sign *= m1;
double term = sign * power / fac;
result += term;
}
return result;
}
boolean close(double a, double b) {
return Math.abs(a - b) < .0000001;
}
}
Okay, now we’re cooking with gas. But wait? What happened to the TDD? And how do we know that this algorithm is really working right? I mean, that’s a lot of code. How can we tell if that code is right?
I suppose we could test a few more values. And, yikes, these tests are getting unwieldy. Let’s refactor a bit too:
private void checkSin(double radians, double sin) {
assertEquals(sin, sin(radians), EPSILON);
}
@Test
public void sines() throws Exception {
checkSin(0, 0);
checkSin(PI, 0);
checkSin(PI/2, 1);
checkSin(PI/3, 0.8660254038);
checkSin(PI/4, 0.7071067812);
checkSin(PI/5, 0.5877852523);
checkSin(3* PI/2, -1);
}
Okay, that passes. Let’s try a couple more:
checkSin(2*PI, 0); checkSin(3*PI, 0);
Ah, 2π works, but 3π does not. It’s close, though: 4.6130E-9. We could probably fix that by bumping up the limit of our comparison in the close() function, but that seems like cheating and probably wouldn’t work for 100π or 1,000π. A better solution would be to reduce the angle to keep it between 0 and 2π.
double sin(double radians) {
radians %= 2*PI;
double result = radians;
Yup. That works. Now what about negative numbers?
checkSin(-PI, 0); checkSin(-PI/2, -1); checkSin(-3*PI/2, 1); checkSin(-1000*PI, 0);
Yeah, they all work. Okay, what about big numbers that aren’t perfect multiples of 2π?
checkSin(1000*PI + PI/3, sin(PI/3));
Sigh. That works too. Is there anything else to try? Are there any values that might fail?
Ouch! I don’t know.
The TDD Uncertainty Principle
Welcome to the first half of the TDD uncertainty principle. No matter how many values we try, we’re going to be left with this nagging uncertainty that we missed something—that some input value will not produce the right output value.
Most functions don’t leave you hanging like this. Most functions have the nice quality that when you’ve written the last test, you know they work. But then there are these annoying functions that leave you wondering whether there is some value that will fail.
The only way to solve that problem with the kinds of tests we’ve written is to try every single possible value. And since double numbers have 64 bits, that means we’d need to write just under 2 × 1019 tests. That’s more than I’d like to write.
So, what do we trust about this function? Do we trust that the Taylor series calculates the sine of a given angle in radians? Yes, we saw the mathematical proof for that, so we’re quite certain that the Taylor series will converge on the right value.
How can we turn the trust in the Taylor series into a set of tests that will prove we are executing that Taylor series correctly?
I suppose we could inspect each of the terms of the Taylor expansion. For example, when calculating sin(π), the terms of the Taylor series are 3.141592653589793, –2.0261201264601763, 0.5240439134171688, –0.07522061590362306, 0.006925270707505149, –4.4516023820919976E-4, 2.114256755841263E-5, –7.727858894175775E-7, 2.2419510729973346E-8.
I don’t see why that kind of test is any better than the tests we already have. Those values apply to only one particular test, and they tell us nothing about whether those terms would be correct for any other value.
No, we want something different. We want something dispositive. Something that proves that the algorithm we are using does, in fact, execute the Taylor series appropriately.
Okay, so what is that Taylor series? It is the infinite and alternating sum of the odd powers of x divided by the odd factorials:
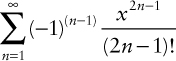
Or, in other words,
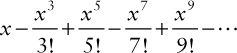
How does this help us? Well, what if we had a spy that told us how the terms of the Taylor series were being calculated, it would let us write a test like this:
@Test
public void taylorTerms() throws Exception {
SineTaylorCalculatorSpy c = new SineTaylorCalculatorSpy();
double r = Math.random() * PI;
for (int n = 1; n <= 10; n++) {
c.calculateTerm(r, n);
assertEquals(n - 1, c.getSignPower());
assertEquals(r, c.getR(), EPSILON);
assertEquals(2 * n - 1, c.getRPower());
assertEquals(2 * n - 1, c.getFac());
}
}
Using a random number for r and all reasonable values for n allows us to avoid specific values. Our interest here is that given some r and some n, the right numbers are fed into the right functions. If this test passes, we will know that the sign, the power, and the factorial calculators have been given the right inputs.
We can make this pass with the following simple code:
public class SineTaylorCalculator {
public double calculateTerm(double r, int n) {
int sign = calcSign(n-1);
double power = calcPower(r, 2*n-1);
double factorial = calcFactorial(2*n-1);
return sign*power/factorial;
}
protected double calcFactorial(int n) {
double fac = 1;
for (int i=1; i<=n; i++)
fac *= i;
return fac;
}
protected double calcPower(double r, int n) {
double power = 1;
for (int i=0; i<n; i++)
power *= r;
return power;
}
protected int calcSign(int n) {
int sign = 1;
for (int i=0; i<n; i++)
sign *= -1;
return sign;
}
}
Note that we are not testing the actual calculation functions. They are pretty simple and probably don’t need testing. This is especially true in light of the other tests we are about to write.
Here’s the spy:
package London_sine;
public class SineTaylorCalculatorSpy extends SineTaylorCalculator { private int fac_n; private double power_r; private int power_n; private int sign_n; public double getR() { return power_r; }
public int getRPower() { return power_n; }
public int getFac() { return fac_n; }
public int getSignPower() { return sign_n; }
protected double calcFactorial(int n) { fac_n = n; return super.calcFactorial(n); }
protected double calcPower(double r, int n) { power_r = r; power_n = n; return super.calcPower(r, n); }
protected int calcSign(int n) { sign_n = n; return super.calcSign(n); }
public double calculateTerm(double r, int n) { return super.calculateTerm(r, n); } }
Given that the test passes, how hard is it to write the summing algorithm?
public double sin(double r) {
double sin=0;
for (int n=1; n<10; n++)
sin += calculateTerm(r, n);
return sin;
}
You can complain about the efficiency of the whole thing, but do you believe that it works? Does the calculateTerm function properly calculate the right Taylor term? Does the sin function properly add them together? Are 10 iterations enough? How can we test this without falling back on all those original value tests?
Here’s an interesting test. All values of sin(r) should be between –1 and 1 (open).
@Test
public void testSineInRange() throws Exception {
SineTaylorCalculator c = new SineTaylorCalculator();
for (int i=0; i<100; i++) {
double r = (Math.random() * 4 * PI) - (2 * PI) ;
double sinr = c.sin(r);
assertTrue(sinr < 1 && sinr > -1);
}
}
That passed. How about this? Given this identity,
public double cos(double r) {
return (sin(r+PI/2));
}
let’s test the Pythagorean identity: sin2 + cos2 = 1.
@Test
public void PythagoreanIdentity() throws Exception {
SineTaylorCalculator c = new SineTaylorCalculator();
for (int i=0; i<100; i++) {
double r = (Math.random() * 4 * PI) - (2 * PI) ;
double sinr = c.sin(r);
double cosr = c.cos(r);
assertEquals(1.0, sinr * sinr + cosr * cosr, 0.00001);
}
}
Hmmm. That actually failed until we raised the number of terms to 20, which is, of course, an absurdly high number. But, like I said, this is an extreme exercise.
Given these tests, how confident are we that we are calculating the sine properly? I don’t know about you, but I’m pretty confident. I know the terms are being fed the right numbers. I can eyeball the simple calculators, and the sin function seems to have the properties of a sine.
Oh, bother, let’s just do some value tests for the hell of it:
@Test
public void sineValues() throws Exception {
checkSin(0, 0);
checkSin(PI, 0);
checkSin(PI/2, 1);
checkSin(PI/3, 0.8660254038);
checkSin(PI/4, 0.7071067812);
checkSin(PI/5, 0.5877852523);
}
Yeah, it all works. Great. I’ve solved my confidence problem. I am no longer uncertain that we’re properly calculating sines. Thank goodness for that spy!
The TDD Uncertainty Principle (Again)
But wait. Did you know that there is a better algorithm for calculating sines? It’s called CORDIC. No, I’m not going to describe it to you here. It’s way beyond the scope of this chapter. But let’s just say that we wanted to change our function to use that CORDIC algorithm.
Our spy tests would break!
In fact, just look back at how much code we invested in that Taylor series algorithm. We’ve got two whole classes, the SineTaylorCalculator and the SineTaylorCalculatorSpy, dedicated to our old algorithm. All that code would have to go away, and a whole new testing strategy would have to be employed.
The spy tests are fragile. Any change to the algorithm breaks virtually all those tests, forcing us to fix or even rewrite them.
On the other hand, if we’d stayed with our original value tests, then they would continue to pass with the new CORDIC algorithm. No rewriting of tests would be necessary.
Welcome to the second half of the TDD uncertainty principle. If you demand certainty from your tests, you will inevitably couple your tests to the implementation, and that will make the tests fragile.
The TDD uncertainty principle: To the extent you demand certainty, your tests will be inflexible. To the extent you demand flexible tests, you will have diminished certainty.
London versus Chicago
The TDD uncertainty principle might make it seem that testing is a lost cause, but that’s not the case at all. The principle just puts some constraints on how beneficial our tests can be.
On the one hand, we don’t want rigid, fragile tests. On the other hand, we want as much certainty as we can afford. As engineers, we have to strike the right trade-off between these two issues.
The Fragile Test Problem
Newcomers to TDD often experience the problem of fragile tests because they are not careful to design their tests well. They treat the tests as second-class citizens and break all the coupling and cohesion rules. This leads to the situation where small changes to the production code, even just a minor refactoring, cause many tests to fail and force sweeping changes in the test code.
Failed tests that necessitate significant rewriting of test code can result in initial disappointment and premature rejection of the discipline. Many young, new TDDers have walked away from the discipline simply because they failed to realize that tests have to be designed just as well as the production code.
The more you couple the tests to the production code, the more fragile your tests become; and few testing artifacts couple more tightly than spies. Spies look deep into the heart of algorithms and inextricably couple the tests to those algorithms. And since mocks are spies, this applies to mocks as well.
This is one of the reasons that I don’t like mocking tools. Mocking tools often lead you to write mocks and spies, and that leads to fragile tests.
The Certainty Problem
If you avoid writing spies, as I do, then you are left with value and property testing. Value tests are like the sine value tests we did earlier in this chapter. They are just the pairing of input values to output values.
Property tests are like the testSineInRange and PythagoreanIdentity tests we used earlier. They run through many appropriate input values checking for invariants. These tests can be convincing, but you are still often left with a nagging doubt.
On the other hand, these tests are so decoupled from the algorithm being employed that changing that algorithm, or even just refactoring that algorithm, cannot affect the tests.
If you are the kind of person who values certainty over flexibility, you’ll likely use a lot of spies in your tests and you’ll tolerate the inevitable fragility.
If, however, you are the kind of person who values flexibility over certainty, you’ll be more like me. You’ll prefer value and property tests over spies, and you’ll tolerate the nagging uncertainty.
These two mindsets have led to two schools of TDD thought and have had a profound influence on our industry. It turns out that whether you prefer flexibility or certainty causes a dramatic change to the process of the design of the production code—if not to the actual design itself.
London
The London school of TDD gets its name from Steve Freeman and Nat Pryce, who live in London and who wrote the book3 on the topic. This is the school that prefers certainty over flexibility.
3. Steve Freeman and Nat Pryce, Growing Object-Oriented Software, Guided by Tests (Addison-Wesley, 2010).
Note the use of the term over. London schoolers do not abandon flexibility. Indeed, they still value it highly. It’s just that they are willing to tolerate a certain level of rigidity in order to gain more certainty.
Therefore, if you look over the tests written by London schoolers, you’ll see a consistent, and relatively unconstrained, use of mocks and spies.
This attitude focuses more on algorithm than on results. To a Londoner, the results are important, but the way in which the results are obtained is more important. This leads to a fascinating design approach. Londoners practice outside-in design.
Programmers who follow the outside-in design approach start at the user interface and design their way toward the business rules, one use case at a time. They use mocks and spies at every boundary in order to prove that the algorithm they are using to communicate inward is working. Eventually, they get to a business rule, implement it, connect it to the database, and then turn around and test their way, with mocks and spies, back out to the user interface.
Again, this full outside-in round trip is done one use case at a time.
This is an extremely disciplined and orderly approach that can work very well indeed.
Chicago
The Chicago school of TDD gets its name from ThoughtWorks, which was, at the time, based in Chicago. Martin Fowler was (and at the time of this writing still is) the chief scientist there. Actually, the name Chicago is a bit more mysterious than that. At one time, this school was called the Detroit school.
The Chicago school focuses on flexibility over certainty. Again, note the word over. Chicagoans know the value of certainty but, given the choice, prefer to make their tests more flexible. Consequently, they focus much more on results than on interactions and algorithms.
This, of course, leads to a very different design philosophy. Chicagoans tend to start with business rules and then move outward towards the user interface. This approach is often called inside-out design.
The Chicago design process is just as disciplined as the London process but attacks the problem in a very different order. A Chicagoan will not drive an entire use case from end to end before starting on the next. Rather, a Chicagoan might use value and property tests to implement several business rules without any user interface at all. The user interface, and the layers between it and the business rules, are implemented as and when necessary.
Chicagoans may not take the business rules all the way out to the database right away either. Rather than the one-use-case-at-a-time round trip, they are looking for synergies and duplications within the layers. Rather than sewing a thread from the inputs of a use case all the way to the output of that use case, they work in broader stripes, within the layers, starting with the business rules and moving gradually out to the user interface and database. As they explore each layer, they are hunting for design patterns and opportunities for abstraction and generality.
This approach is a less ordered than that of the London school, but it is more holistic. It tends to keep the big picture more clearly in view—in my humble opinion.
Synthesis
Although these two schools of thought exist, and although there are practitioners who tend toward one side or the other, London versus Chicago is not a war. It’s not really even much of a disagreement. It is a minor point of emphasis, and little more.
Indeed, all practitioners, whether Chicagoans or Londoners, use both techniques in their work. It’s just that some do a little more of one, and some do a little more of the other.
Which is right? Neither, of course. I tend more toward the Chicago side, but you may look at the London school and decide you are more comfortable there. I have no disagreement with you. Indeed, I will happily pair program with you to create a lovely synthesis.
That synthesis becomes very important when we start to consider architecture.
Architecture
The trade-off I make between the London and Chicago strategies is architectural. If you read Clean Architecture,4 you know that I like to partition systems into components. I call the divisions between those components boundaries. My rule for boundaries is that source code dependencies must always cross a boundary pointing toward high-level policy.
4. Robert C. Martin, Clean Architecture: A Craftsman’s Guide to Software Structure and Design (Addison-Wesley, 2018).
This means that components that contain low-level details, like graphical user interfaces (GUIs) and databases, depend on higher-level components like business rules. High-level components do not depend on lower-level components. This is an example of the dependency inversion principle, which is the D in SOLID.
When writing the lowest-level programmer tests, I will use spies (and rarely mocks) when testing across an architectural boundary. Or, to say that a different way, when testing a component, I use spies to mock out any collaborating components and to ensure that the component I am testing invokes the collaborators correctly. So, if my test crosses an architectural boundary, I’m a Londoner.
However, when a test does not cross such a boundary, I tend to be a Chicagoan. Within a component, I depend much more on state and property testing in order to keep the coupling, and therefore the fragility, of my tests as low as possible.
Let’s look at an example. The UML diagram in Figure 3.8 shows a set of classes and the four components that contain them.
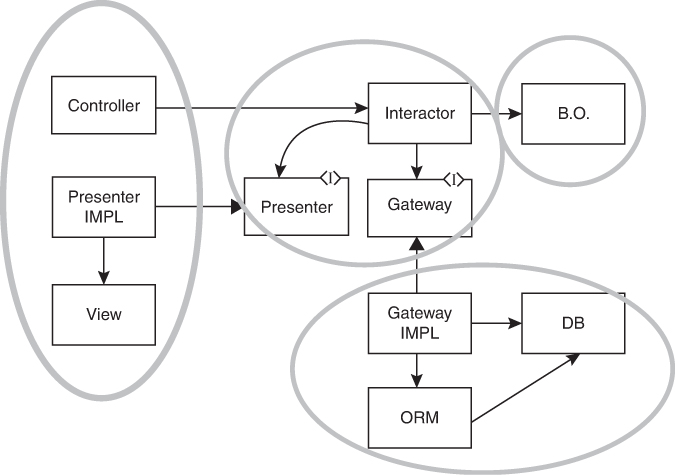
Figure 3.8 A set of classes and the four components that contain them
Note that the arrows all point from lower-level components to higher-level components. This is the Dependency Rule that is discussed in Clean Architecture. The highest-level component contains the business objects. The next level down contains the interactors and the communications interfaces. At the lowest level is the GUI and the database.
We might use some stubs when testing the business objects, but we won’t need any spies or mocks because the business objects don’t know about any other components.
The interactors, on the other hand, manipulate the business objects, the database, and the GUI. Our tests will likely use spies to make sure that the database and GUI are being manipulated properly. However, we will probably not use as many spies, or even stubs, between the interactors and the business objects because the functions of the business objects are probably not expensive.
When testing the controller, we will almost certainly use a spy to represent the interactor because we don’t want the calls to propagate to the database or presenter.
The presenter is interesting. We think of it as part of the GUI component, but in fact we’re going to need a spy to test it. We don’t want to test it with the real view, so we probably need a fifth component to hold the view apart from the controller and presenter.
That last little complication is common. We often modify our component boundaries because the tests demand it.
Conclusion
In this chapter, we looked at some of the more advanced aspects of TDD: from the incremental development of algorithms, to the problem of getting stuck, from the finite state machine nature of tests to test doubles and the TDD uncertainty principle. But we’re not done. There’s more. So, get a nice hot cup of tea and turn the improbability generator up to infinity.