2 Test-Driven Development

Our discussion of test-driven development (TDD) spans two chapters. We first cover the basics of TDD in a very technical and detailed manner. In this chapter, you will learn about the discipline in a step-by-step fashion. The chapter provides a great deal of code to read and several videos to watch as well.
In Chapter 3, “Advanced TDD,” we cover many of the traps and conundrums that novice TDDers face, such as databases and graphical user interfaces. We also explore the design principles that drive good test design and the design patterns of testing. Finally, we investigate some interesting and profound theoretical possibilities.
Overview
Zero. It’s an important number. It’s the number of balance. When the two sides of a scale are in balance, the pointer on the scale reads zero. A neutral atom, with equal numbers of electrons and protons, has a charge of zero. The sum of forces on a bridge balances to zero. Zero is the number of balance.
Did you ever wonder why the amount of money in your checking account is called its balance? That’s because the balance in your account is the sum of all the transactions that have either deposited or withdrawn money from that account. But transactions always have two sides because transactions move money between accounts.
The near side of a transaction affects your account. The far side affects some other account. Every transaction whose near side deposits money into your account has a far side that withdraws that amount from some other account. Every time you write a check, the near side of the transaction withdraws money from your account, and the far side deposits that money into some other account. So, the balance in your account is the sum of the near sides of the transactions. The sum of the far sides should be equal and opposite to the balance of your account. The sum of all the near and far sides should be zero.
Two thousand years ago, Gaius Plinius Secundus, known as Pliny the Elder, realized this law of accounting and invented the discipline of double-entry bookkeeping. Over the centuries, this discipline was refined by the bankers in Cairo and then by the merchants of Venice. In 1494, Luca Pacioli, a Franciscan friar and friend of Leonardo DaVinci, wrote the first definitive description of the discipline. It was published in book form on the newly invented printing press, and the technique spread.
In 1772, as the industrial revolution gained momentum, Josiah Wedgwood was struggling with success. He was the founder of a pottery factory, and his product was in such high demand that he was nearly bankrupting himself trying to meet that demand. He adopted double-entry bookkeeping and was thereby able to see how money was flowing in and out of his business with a resolution that had previously escaped him. And by tuning those flows, he staved off the looming bankruptcy and built a business that exists to this day.
Wedgwood was not alone. Industrialization drove the vast growth of the economies of Europe and America. In order to manage all the money flows resulting from that growth, increasing numbers of firms adopted the discipline.
In 1795, Johann Wolfgang von Goethe wrote the following in Wilhelm Meister’s Apprenticeship. Pay close attention, for we will return to this quote soon.
“Away with it, to the fire with it!” cried Werner. “The invention does not deserve the smallest praise: that affair has plagued me enough already, and drawn upon yourself your father’s wrath. The verses may be altogether beautiful; but the meaning of them is fundamentally false. I still recollect your Commerce personified; a shrivelled, wretched-looking sibyl she was. I suppose you picked up the image of her from some miserable huckster’s shop. At that time, you had no true idea at all of trade; whilst I could not think of any man whose spirit was, or needed to be, more enlarged than the spirit of a genuine merchant. What a thing it is to see the order which prevails throughout his business! By means of this he can at any time survey the general whole, without needing to perplex himself in the details. What advantages does he derive from the system of book-keeping by double entry! It is among the finest inventions of the human mind; every prudent master of a house should introduce it into his economy.”
Today, double-entry bookkeeping carries the force of law in almost every country on the planet. To a large degree, the discipline defines the accounting profession.
But let’s return to Goethe’s quote. Note the words that Goethe used to describe the means of “Commerce” that he so detested:
A shrivelled, wretched-looking sibyl she was. I suppose you picked up the image of her from some miserable huckster’s shop.
Have you seen any code that matches that description? I’m sure you have. So have I. Indeed, if you are like me, then you have seen far, far too much of it. If you are like me, you have written far, far too much of it.
Now, one last look at Goethe’s words:
What a thing it is to see the order which prevails throughout his business! By means of this he can at any time survey the general whole, without needing to perplex himself in the details.
It is significant that Goethe ascribes this powerful benefit to the simple discipline of double-entry bookkeeping.
Software
The maintenance of proper accounts is utterly essential for running a modern business, and the discipline of double-entry bookkeeping is essential for the maintenance of proper accounts. But is the proper maintenance of software any less essential to the running of a business? By no means! In the twenty-first century, software is at the heart of every business.
What, then, can software developers use as a discipline that gives them the control and vision over their software that double-entry bookkeeping gives to accountants and managers? Perhaps you think that software and accounting are such different concepts that no correspondence is required or even possible. I beg to differ.
Consider that accounting is something of a mage’s art. Those of us not versed in its rituals and arcanities understand but little of the depth of the accounting profession. And what is the work product of that profession? It is a set of documents that are organized in a complex and, for the layperson, bewildering fashion. Upon those documents is strewn a set of symbols that few but the accountants themselves can truly understand. And yet if even one of those symbols were to be in error, terrible consequences could ensue. Businesses could founder and executives could be jailed.
Now consider how similar accounting is to software development. Software is a mage’s art indeed. Those not versed in the rituals and arcanities of software development have no true idea of what goes on under the surface. And the product? Again, a set of documents: the source code—documents organized in a deeply complex and bewildering manner, littered with symbols that only the programmers themselves can divine. And if even one of those symbols is in error, terrible consequences may ensue.
The two professions are deeply similar. They both concern themselves with the intense and fastidious management of intricate detail. They both require significant training and experience to do well. They both are engaged in the production of complex documents whose accuracy, at the level of individual symbols, is critical.
Accountants and programmers may not want to admit it, but they are of a kind. And the discipline of the older profession should be well observed by the younger.
As you will see in what follows, TDD is double-entry bookkeeping. It is the same discipline, executed for the same purpose, and delivering the same results. Everything is said twice, in complementary accounts that must be kept in balance by keeping the tests passing.
The Three Laws of TDD
Before we get to the three laws, we have some preliminaries to cover.
The essence of TDD entails the discipline to do the following:
Create a test suite that enables refactoring and is trusted to the extent that passage implies deployability. That is, if the test suite passes, the system can be deployed.
Create production code that is decoupled enough to be testable and refactorable.
Create an extremely short-cycle feedback loop that maintains the task of writing programs with a stable rhythm and productivity.
Create tests and production code that are sufficiently decoupled from each other so as to allow convenient maintenance of both, without the impediment of replicating changes between the two.
The discipline of TDD is embodied within three entirely arbitrary laws. The proof that these laws are arbitrary is that the essence can be achieved by very different means. In particular, Kent Beck’s test && commit || revert (TCR) discipline. Although TCR is entirely different from TDD, it achieves precisely the same essential goals.
The three laws of TDD are the basic foundation of the discipline. Following them is very hard, especially at first. Following them also requires some skill and knowledge that is hard to come by. If you try to follow these laws without that skill and knowledge, you will almost certainly become frustrated and abandon the discipline. We address that skill and knowledge in subsequent chapters. For the moment, be warned. Following these laws without proper preparation will be very difficult.
The First Law
Write no production code until you have first written a test that fails due to the lack of that production code.
If you are a programmer of any years’ experience, this law may seem foolish. You might wonder what test you are supposed to write if there’s no code to test. This question comes from the common expectation that tests are written after code. But if you think about it, you’ll realize that if you can write the production code, you can also write the code that tests the production code. It may seem out of order, but there’s no lack of information preventing you from writing the test first.
The Second Law
Write no more of a test than is sufficient to fail or fail to compile. Resolve the failure by writing some production code.
Again, if you are an experienced programmer, then you likely realize that the very first line of the test will fail to compile because that first line will be written to interact with code that does not yet exist. And that means, of course, that you will not be able to write more than one line of a test before having to switch over to writing production code.
The Third Law
Write no more production code than will resolve the currently failing test. Once the test passes, write more test code.
And now the cycle is complete. It should be obvious to you that these three laws lock you into a cycle that is just a few seconds long. It looks like this:
You write a line of test code, but it doesn’t compile (of course).
You write a line of production code that makes the test compile.
You write another line of test code that doesn’t compile.
You write another line or two of production code that makes the test compile.
You write another line or two of test code that compiles but fails an assertion.
You write another line or two of production code that passes the assertion.
And this is going to be your life from now on.
Once again, the experienced programmer will likely consider this to be absurd. The three laws lock you into a cycle that is just a few seconds long. Each time around that cycle, you are switching between test code and production code. You’ll never be able to just write an if statement or a while loop. You’ll never be able to just write a function. You will be forever trapped in this tiny little loop of switching contexts between test code and production code.
You may think that this will be tedious, boring, and slow. You might think that it will impede your progress and interrupt your chain of thought. You might even think that it’s just plain silly. You may think that this approach will lead you to produce spaghetti code or code with little or no design—a haphazard conglomeration of tests and the code that makes those tests pass.
Hold all those thoughts and consider what follows.
Losing the Debug-foo
I want you to imagine a room full of people following these three laws—a team of developers all working toward the deployment of a major system. Pick any one of those programmers you like, at any time you like. Everything that programmer is working on executed and passed all its tests within the last minute or so. And this is always true. It doesn’t matter who you pick. It doesn’t matter when you pick them. Everything worked a minute or so ago.
What would your life be like if everything worked a minute or so ago? How much debugging do you think you would do? The fact is that there’s not likely much to debug if everything worked a minute or so ago.
Are you good at the debugger? Do you have the debug-foo in your fingers? Do you have all the hot keys primed and ready to go? Is it second nature for you to efficiently set breakpoints and watchpoints and to dive headlong into a deep debugging session?
This is not a skill to be desired!
You don’t want to be good at the debugger. The only way you get good at the debugger is by spending a lot of time debugging. And I don’t want you spending a lot of time debugging. You shouldn’t want that either. I want you spending as much time as possible writing code that works and as little time as possible fixing code that doesn’t.
I want your use of the debugger to be so infrequent that you forget the hot keys and lose the debug-foo in your fingers. I want you puzzling over the obscure step-into and step-over icons. I want you to be so unpracticed at the debugger that the debugger feels awkward and slow. And you should want that too. The more comfortable you feel with a debugger, the more you know you are doing something wrong.
Now, I can’t promise you that these three laws will eliminate the need for the debugger. You will still have to debug from time to time. This is still software, and it’s still hard. But the frequency and duration of your debugging sessions will undergo a drastic decline. You will spend far more time writing code that works and far less time fixing code that doesn’t.
Documentation
If you’ve ever integrated a third-party package, you know that included in the bundle of software you receive is a PDF written by a tech writer. This document purports to describe how to integrate the third-party package. At the end of this document is almost always an ugly appendix that contains all the code examples for integrating the package.
Of course, that appendix is the first place you look. You don’t want to read what a tech writer wrote about the code; you want to read the code. And that code will tell you much more than the words written by the tech writer. If you are lucky, you might even be able to use copy/paste to move the code into your application where you can fiddle it into working.
When you follow the three laws, you are writing the code examples for the whole system. Those tests you are writing explain every little detail about how the system works. If you want to know how to create a certain business object, there are tests that show you how to create it every way that it can be created. If you want to know how to call a certain API function, there are tests that demonstrate that API function and all its potential error conditions and exceptions. There are tests in the test suite that will tell you anything you want to know about the details of the system.
Those tests are documents that describe the entire system at its lowest level. These documents are written in a language you intimately understand. They are utterly unambiguous. They are so formal that they execute. And they cannot get out of sync with the system.
As documents go, they are almost perfect.
I don’t want to oversell this. The tests are not particularly good at describing the motivation for a system. They are not high-level documents. But at the lowest level, they are better than any other kind of document that could be written. They are code. And code is something you know will tell you the truth.
You might be concerned that the tests will be as hard to understand as the system as a whole. But this is not the case. Each test is a small snippet of code that is focused on one very narrow part of the system as a whole. The tests do not form a system by themselves. The tests do not know about each other, and so there is no rat’s nest of dependency in the tests. Each test stands alone. Each test is understandable on its own. Each test tells you exactly what you need to understand within a very narrow part of the system.
Again, I don’t want to oversell this point. It is possible to write opaque and complex tests that are hard to read and understand, but it is not necessary. Indeed, it is one of the goals of this book to teach you how to write tests that are clear and clean documents that describe the underlying system.
Holes in the Design
Have you ever written tests after the fact? Most of us have. Writing tests after writing code is the most common way that tests are written. But it’s not a lot of fun, is it?
It’s not fun because by the time we start writing after-the-fact tests, we already know the system works. We’ve tested it manually. We are only writing the tests out of some sense of obligation or guilt or, perhaps, because our management has mandated some level of test coverage. So, we begrudgingly bend into the grind of writing one test after another, knowing that each test we write will pass. Boring, boring, boring.
Inevitably, we come to the test that’s hard to write. It is hard to write because we did not design the code to be testable; we were focused instead on making it work. Now, in order to test the code, we’re going to have to change the design.
But that’s a pain. It’s going to take a lot of time. It might break something else. And we already know the code works because we tested it manually. Consequently, we walk away from that test, leaving a hole in the test suite. Don’t tell me you’ve never done this. You know you have.
You also know that if you’ve left a hole in the test suite, everybody else on the team has too, so you know that the test suite is full of holes.
The number of holes in the test suite can be determined by measuring the volume and duration of the laughter of the programmers when the test suite passes. If the programmers laugh a lot, then the test suite has a lot of holes in it.
A test suite that inspires laughter when it passes is not a particularly useful test suite. It may tell you when certain things break, but there is no decision you can make when it passes. When it passes, all you know is that some stuff works.
A good test suite has no holes. A good test suite allows you to make a decision when it passes. That decision is to deploy.
If the test suite passes, you should feel confident in recommending that the system be deployed. If your test suite doesn’t inspire that level of confidence, of what use is it?
Fun
When you follow the three laws, something very different happens. First of all, it’s fun. One more time, I don’t want to oversell this. TDD is not as much fun as winning the jackpot in Vegas. It’s not as much fun as going to a party or even playing Chutes and Ladders with your four-year-old. Indeed, fun might not be the perfect word to use.
Do you remember when you got your very first program to work? Remember that feeling? Perhaps it was in a local department store that had a TRS-80 or a Commodore 64. Perhaps you wrote a silly little infinite loop that printed your name on the screen forever and ever. Perhaps you walked away from that screen with a little smile on your face, knowing that you were the master of the universe and that all computers would bow down to you forever.
A tiny echo of that feeling is what you get every time you go around the TDD loop. Every test that fails just the way you expected it to fail makes you nod and smile just a little bit. Every time you write the code that makes that failing test pass, you remember that once you were master of the universe and that you still have the power.
Every time around the TDD loop, there’s a tiny little shot of endorphins released into your reptile brain, making you feel just a little more competent and confident and ready to meet the next challenge. And though that feeling is small, it is nonetheless kinda fun.
Design
But never mind the fun. Something much more important happens when you write the tests first. It turns out that you cannot write code that’s hard to test if you write the tests first. The act of writing the test first forces you to design the code to be easy to test. There’s no escape from this. If you follow the three laws, your code will be easy to test.
What makes code hard to test? Coupling and dependencies. Code that is easy to test does not have those couplings and dependencies. Code that is easy to test is decoupled!
Following the three laws forces you to write decoupled code. Again, there is no escape from this. If you write the tests first, the code that passes those tests will be decoupled in ways that you’d never have imagined.
And that’s a very good thing.
The Pretty Little Bow on Top
It turns out that applying the three laws of TDD has the following set of benefits:
You will spend more time writing code that works and less time debugging code that doesn’t.
You will produce a set of nearly perfect low-level documentation.
It is fun—or at least motivating.
You will produce a test suite that will give you the confidence to deploy.
You will create less-coupled designs.
These reasons might convince you that TDD is a good thing. They might be enough to get you to ignore your initial reaction, even repulsion. Maybe.
But there is a far more overriding reason why the discipline of TDD is important.
Fear
Programming is hard. It may be the most difficult thing that humans have attempted to master. Our civilization now depends upon hundreds of thousands of interconnected software applications, each of which involves hundreds of thousands if not tens of millions of lines of code. There is no other apparatus constructed by humans that has so many moving parts.
Each of those applications is supported by teams of developers who are scared to death of change. This is ironic because the whole reason software exists is to allow us to easily change the behavior of our machines.
But software developers know that every change introduces the risk of breakage and that breakage can be devilishly hard to detect and repair.
Imagine that you are looking at your screen and you see some nasty tangled code there. You probably don’t have to work very hard to conjure that image because, for most of us, this is an everyday experience.
Now let’s say that as you glance at that code, for one very brief moment, the thought occurs to you that you ought to clean it up a bit. But your very next thought slams down like Thor’s hammer: “I’M NOT TOUCHING IT!” Because you know that if you touch it, you will break it; and if you break it, it becomes yours forever.
This is a fear reaction. You fear the code you maintain. You fear the consequences of breaking it.
The result of this fear is that the code must rot. No one will clean it. No one will improve it. When forced to make changes, those changes will be made in the manner that is safest for the programmer, not best for the system. The design will degrade, and the code will rot, and the productivity of the team will decline, and that decline will continue until productivity is near zero.
Ask yourself if you have ever been significantly slowed down by the bad code in your system. Of course you have. And now you know why that bad code exists. It exists because nobody has the courage to do the one thing that could improve it. No one dares risk cleaning it.
Courage
But what if you had a suite of tests that you trusted so much that you were confident in recommending deployment every time that suite of tests passed? And what if that suite of tests executed in seconds? How much would you then fear to engage in a gentle cleaning of the system?
Imagine that code on your screen again. Imagine the stray thought that you might clean it up a little. What would stop you? You have the tests. Those tests will tell you the instant you break something.
With that suite of tests, you can safely clean the code. With that suite of tests, you can safely clean the code. With that suite of tests, you can safely clean the code.
No, that wasn’t a typo. I wanted to drive the point home very, very hard. With that suite of tests, you can safely clean the code!
And if you can safely clean the code, you will clean the code. And so will everyone else on the team. Because nobody likes a mess.
The Boy Scout Rule
If you have that suite of tests that you trust with your professional life, then you can safely follow this simple guideline:
Check the code in cleaner than you checked it out.
Imagine if everyone did that. Before checking the code in, they made one small act of kindness to the code. They cleaned up one little bit.
Imagine if every check-in made the code cleaner. Imagine that nobody ever checked the code in worse than it was but always better than it was.
What would it be like to maintain such a system? What would happen to estimates and schedules if the system got cleaner and cleaner with time? How long would your bug lists be? Would you need an automated database to maintain those bug lists?
That’s the Reason
Keeping the code clean. Continuously cleaning the code. That’s why we practice TDD. We practice TDD so that we can be proud of the work we do. So that we can look at the code and know it is clean. So that we know that every time we touch that code, it gets better than it was before. And so that we go home at night and look in the mirror and smile, knowing we did a good job today.
The Fourth Law
I will have much more to say about refactoring in later chapters. For now, I want to assert that refactoring is the fourth law of TDD.
From the first three laws, it is easy to see that the TDD cycle involves writing a very small amount of test code that fails, and then writing a very small amount of production code that passes the failing test. We could imagine a traffic light that alternates between red and green every few seconds.
But if we were to allow that cycle to continue in that form, then the test code and the production code would rapidly degrade. Why? Because humans are not good at doing two things at once. If we focus on writing a failing test, it’s not likely to be a well-written test. If we focus on writing production code that passes the test, it is not likely to be good production code. If we focus on the behavior we want, we will not be focusing on the structure we want.
Don’t fool yourself. You cannot do both at once. It is hard enough to get code to behave the way you want it to. It is too hard to write it to behave and have the right structure. Thus, we follow Kent Beck’s advice:
First make it work. Then make it right.
Therefore, we add a new law to the three laws of TDD: the law of refactoring. First you write a small amount of failing test code. Then you write a small amount of passing production code. Then you clean up the mess you just made.
The traffic light gets a new color: red → green → refactor (Figure 2.1).
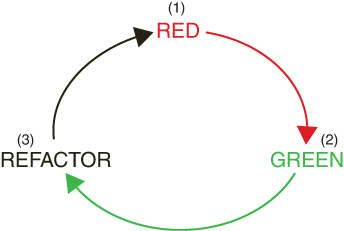
Figure 2.1 Red → green → refactor
You’ve likely heard of refactoring, and as I said earlier, we’ll be spending a great deal of time on it in coming chapters. For now, let me dispel a few myths and misconceptions:
Refactoring is a constant activity. Every time around the TDD cycle, you clean things up.
Refactoring does not change behavior. You only refactor when the tests are passing, and the tests continue to pass while you refactor.
Refactoring never appears on a schedule or a plan. You do not reserve time for refactoring. You do not ask permission to refactor. You simply refactor all the time.
Think of refactoring as the equivalent of washing your hands after using the restroom. It’s just something you always do as a matter of common decency.
The Basics
It is very hard to create effective examples of TDD in text. The rhythm of TDD just doesn’t come through very well. In the pages that follow, I try to convey that rhythm with appropriate timestamps and callouts. But to actually understand the true frequency of this rhythm, you just have to see it.
Therefore, each of the examples to follow has a corresponding online video that will help you see the rhythm first hand. Please watch each video in its entirety, and then make sure you go back to the text and read the explanation with the timestamps. If you don’t have access to the videos, then pay special attention to the timestamps in the examples so you can infer the rhythm.
Simple Examples
As you review these examples, you are likely to discount them because they are all small and simple problems. You might conclude that TDD may be effective for such “toy examples” but cannot possibly work for complex systems. This would be a grave mistake.
The primary goal of any good software designer is to break down large and complex systems into a set of small, simple problems. The job of a programmer is to break those systems down into individual lines of code. Thus, the examples that follow are absolutely representative of TDD regardless of the size of the project.
This is something I can personally affirm. I have worked on large systems that were built with TDD, and I can tell you from experience that the rhythm and techniques of TDD are independent of scope. Size does not matter.
Or, rather, size does not matter to the procedure and the rhythm. However, size has a profound effect on the speed and coupling of the tests. But those are topics for the advanced chapters.
Stack
Watch related video: Stack
Access video by registering at informit.com/register
We start with a very simple problem: create a stack of integers. As we walk through this problem, note that the tests will answer any questions you have about the behavior of the stack. This is an example of the documentation value of tests. Note also that we appear to cheat by making the tests pass by plugging in absolute values. This is a common strategy in TDD and has a very important function. I’ll describe that as we proceed.
We begin:
// T: 00:00 StackTest.java package stack;
import org.junit.Test;
public class StackTest { @Test public void nothing() throws Exception { } }
It’s good practice to always start with a test that does nothing, and make sure that test passes. Doing so helps ensure that the execution environment is all working.
Next, we face the problem of what to test. There’s no code yet, so what is there to test?
The answer to that question is simple. Assume we already know the code we want to write: public class stack. But we can’t write it because we don’t have a test that fails due to its absence. So, following the first law, we write the test that forces us to write the code that we already know we want to write.
Rule 1: Write the test that forces you to write the code you already know you want to write.
This is the first of many rules to come. These “rules” are more like heuristics. They are bits of advice that I’ll be throwing out, from time to time, as we progress through the examples.
Rule 1 isn’t rocket science. If you can write a line of code, then you can write a test that tests that line of code, and you can write it first. Therefore,
// T:00:44 StackTest.java
public class StackTest {
@Test
public void canCreateStack() throws Exception {
MyStack stack = new MyStack();
}
}
I use boldface to show code that has been changed or added and highlight to depict code that does not compile. I chose MyStack for our example because the name Stack is known to the Java environment already.
Notice that in the code snippet, we changed the name of the test to communicate our intent. We can create a stack.
Now, because MyStack doesn’t compile, we’d better follow the second law and create it, but by the third law, we’d better not write more than we need:
// T: 00:54 Stack.java package stack;
public class MyStack { }
Ten seconds have passed, and the test compiles and passes. When I initially wrote this example, most of that 10 seconds was taken up by rearranging my screen so that I can see both files at the same time. My screen now looks like Figure 2.2. The tests are on the left, and the production code is on the right. This is my typical arrangement. It’s nice to have screen real estate.
Figure 2.2 Rearranged screen
MyStack isn’t a great name, but it avoided the name collision. Now that MyStack is declared in the stack package, let’s change it back to Stack. That took 15 seconds. The tests still pass.
// T:01:09 StackTest.java
public class StackTest {
@Test
public void canCreateStack() throws Exception {
Stack stack = new Stack();
}
}
// T: 01:09 Stack.java
package stack;
public class Stack {
}
Here we see another rule: red → green → refactor. Never miss an opportunity to clean things up.
Rule 2: Make it fail. Make it pass. Clean it up.
Writing code that works is hard enough. Writing code that works and is clean is even harder. Fortunately, we can break the effort up into two steps. We can write bad code that works. Then, if we have tests, we can easily clean up the bad code while keeping it working.
Thus, every circuit around the TDD loop, we take the opportunity to clean up any little messes we might have made.
You may have noticed that our test does not actually assert any behavior. It compiles and passes but asserts nothing at all about the newly created stack. We can fix that in 15 seconds:
// T: 01:24 StackTest.java
public class StackTest {
@Test
public void canCreateStack() throws Exception {
Stack stack = new Stack();
assertTrue(stack.isEmpty());
}
}
The second law kicks in here, so we’d better get this to compile:
// T: 01:49 import static junit.framework.TestCase.assertTrue;
public class StackTest { @Test public void canCreateStack() throws Exception { Stack stack = new Stack(); assertTrue(stack.isEmpty()); } }
// T: 01:49 Stack.java public class Stack { public boolean isEmpty() { return false; } }
Twenty-five seconds later, it compiles but fails. The failure is intentional: isEmpty is specifically coded to return false because the first law says that the test must fail—but why does the first law demand this? Because now we can see that our test fails when it ought to fail. We have tested our test. Or rather, we have tested one half of it. We can test the other half by changing isEmpty to return true:
// T: 01:58 Stack.java
public class Stack {
public boolean isEmpty() {
return true;
}
}
Nine seconds later, the test passes. It has taken 9 seconds to ensure that the test both passes and fails.
When programmers first see that false and then that true, they often laugh because it looks so foolish. It looks like cheating. But it’s not cheating, and it’s not at all foolish. It has taken mere seconds to ensure that the test both passes and fails as it should. Why in the world would we not do this?
What’s the next test? Well, we know we need to write the push function. So, by Rule 1, we write the test that forces us to write the push function:
// T 02:24 StackTest.java
@Test
public void canPush() throws Exception {
Stack stack = new Stack();
stack.push(0);
}
This doesn’t compile. By the second law, then, we must write the production code that will make it compile:
// T: 02:31 Stack.java
public void push(int element) {
}
This compiles, of course, but now we have another test without an assertion. The obvious thing to assert is that, after one push, the stack is not empty:
// T: 02:54 StackTest.java
@Test
public void canPush() throws Exception {
Stack stack = new Stack();
stack.push(0);
assertFalse(stack.isEmpty());
}
This fails, of course, because isEmpty returns true, so we need to do something a bit more intelligent—like create a Boolean flag to track emptiness:
// T: 03:46 Stack.java
public class Stack {
private boolean empty = true;
public boolean isEmpty() {
return empty;
}
public void push(int element) {
empty=false;
}
}
This passes. It has been 2 minutes since the last test passed. Now, by Rule 2, we need to clean this up. The duplication of the stack creation bothers me, so let’s extract the stack into a field of the class and initialize it:
// T: 04:24 StackTest.java
public class StackTest {
private Stack stack = new Stack();
@Test
public void canCreateStack() throws Exception {
assertTrue(stack.isEmpty());
}
@Test
public void canPush() throws Exception {
stack.push(0);
assertFalse(stack.isEmpty());
}
}
This requires 30 seconds, and the tests still pass.
The name canPush is a pretty bad name for this test.
// T: 04:50 StackTest.java
@Test
public void afterOnePush_isNotEmpty() throws Exception {
stack.push(0);
assertFalse(stack.isEmpty());
}
That’s better. And, of course, it still passes.
Okay, back to the first law. If we push once and pop once, the stack should be empty again:
// T: 05:17 StackTest.java
@Test
public void afterOnePushAndOnePop_isEmpty() throws Exception {
stack.push(0);
stack.pop()
}
The second law kicks in because pop doesn’t compile, so
// T: 05:31 Stack.java
public int pop() {
return -1;
}
And then the third law allows us to finish the test:
// T: 05:51
@Test
public void afterOnePushAndOnePop_isEmpty() throws Exception {
stack.push(0);
stack.pop();
assertTrue(stack.isEmpty());
}
This fails because nothing sets the empty flag back to true, so
// T: 06:06 Stack.java
public int pop() {
empty=true;
return -1;
}
And, of course, this passes. It has been 76 seconds since the last test passed.
Nothing to clean up, so back to the first law. The size of the stack should be 2 after two pushes.
// T: 06:48 StackTest.java
@Test
public void afterTwoPushes_sizeIsTwo() throws Exception {
stack.push(0);
stack.push(0);
assertEquals(2, stack.getSize());
}
The second law kicks in because of the compile errors, but they are easy to fix. We add the necessary import to the test and the following function to the production code:
// T: 07:23 Stack.java
public int getSize() {
return 0;
}
And now everything compiles, but the tests fail.
Of course, getting the test to pass is trivial:
// T: 07:32 Stack.java
public int getSize() {
return 2;
}
This looks dumb, but we have now seen the test fail and pass properly, and it took only 11 seconds. So, again, why wouldn’t we do this?
But this solution is clearly naive, so by Rule 1, we modify a previous test in a manner that will force us to write a better solution. And, of course, we screw it up (you can blame me):
// T: 08:06 StackTest.java
@Test
public void afterOnePushAndOnePop_isEmpty() throws Exception {
stack.push(0);
stack.pop();
assertTrue(stack.isEmpty());
assertEquals(1, stack.getSize());
}
Okay, that was really stupid. But programmers make dumb mistakes from time to time, and I am no exception. I didn’t spot this mistake right away when I first wrote the example because the test failed just the way I expected it to.
So, now, secure in the assumption that our tests are good, let’s make the changes that we believe will make those tests pass:
// T: 08:56
public class Stack {
private boolean empty = true;
private int size = 0;
public boolean isEmpty() {
return size == 0;
}
public void push(int element) {
size++;
}
public int pop() {
--size;
return -1;
}
public int getSize() {
return size;
}
}
I was surprised to see this fail. But after composing myself, I quickly found my error and repaired the test. Let’s do this:
// T: 09:28 StackTest.java
@Test
public void afterOnePushAndOnePop_isEmpty() throws Exception {
stack.push(0);
stack.pop();
assertTrue(stack.isEmpty());
assertEquals(0, stack.getSize());
}
And the tests all pass. It has been 3 minutes and 22 seconds since the tests last passed.
For the sake of completeness, let’s add the size check to another test:
// T: 09:51 StackTest.java
@Test
public void afterOnePush_isNotEmpty() throws Exception {
stack.push(0);
assertFalse(stack.isEmpty());
assertEquals(1, stack.getSize());
}
And, of course, that passes.
Back to the first law. What should happen if we pop an empty stack? We should expect an underflow exception:
// T: 10:27 StackTest.java
@Test(expected = Stack.Underflow.class)
public void poppingEmptyStack_throwsUnderflow() {
}
The second law forces us to add that exception:
// T: 10:36 Stack.java
public class Underflow extends RuntimeException {
}
And then we can complete the test:
// T: 10:50 StackTest.java
@Test(expected = Stack.Underflow.class)
public void poppingEmptyStack_throwsUnderflow() {
stack.pop();
}
This fails, of course, but it is easy to make it pass:
// T: 11:18 Stack.java
public int pop() {
if (size == 0)
throw new Underflow();
--size;
return -1;
}
That passes. It has been 1 minute and 27 seconds since the tests last passed.
Back to the first law. The stack should remember what was pushed. Let’s try the simplest case:
// T: 11:49 StackTest.java
@Test public void afterPushingX_willPopX() throws Exception { stack.push(99); assertEquals(99, stack.pop()); }
This fails because pop is currently returning -1. We make it pass by returning 99:
// T: 11:57 Stack.java
public int pop() {
if (size == 0)
throw new Underflow();
--size;
return 99;
}
This is obviously insufficient, so by Rule 1, we add enough to the test to force us to be a bit smarter:
// T: 12:18 StackTest.java
@Test
public void afterPushingX_willPopX() throws Exception {
stack.push(99);
assertEquals(99, stack.pop());
stack.push(88);
assertEquals(88, stack.pop());
}
This fails because we’re returning 99. We make it pass by adding a field to record the last push:
// T: 12:50 Stack.java
public class Stack {
private int size = 0;
private int element;
public void push(int element) {
size++;
this.element = element;
}
public int pop() {
if (size == 0)
throw new Underflow();
--size;
return element;
}
}
This passes. It has been 92 seconds since the tests last passed.
At this point, you are probably pretty frustrated with me. You might even be shouting at these pages, demanding that I stop messing around and just write the damned stack. But actually, I’ve been following Rule 3.
Rule 3: Don’t go for the gold.
When you first start TDD, the temptation is overwhelming to tackle the hard or interesting things first. Someone writing a stack would be tempted to test first-in-last-out (FILO) behavior first. This is called “going for the gold.” By now, you have noticed that I have purposely avoided testing anything stack-like. I’ve been focusing on all the ancillary stuff around the outside of the stack, things like emptiness and size.
Why haven’t I been going for the gold? Why does Rule 3 exist? Because when you go for the gold too early, you tend to miss all the details around the outside. Also, as you will soon see, you tend to miss the simplifying opportunities that those ancillary details provide.
Anyway, the first law has just kicked in. We need to write a failing test. And the most obvious test to write is FILO behavior:
// T: 13:36 StackTest.java
@Test
public void afterPushingXandY_willPopYthenX() {
stack.push(99);
stack.push(88);
assertEquals(88, stack.pop());
assertEquals(99, stack.pop());
}
This fails. Getting it to pass will require that we remember more than one value, so we should probably use an array. Let’s rename the field to elements and turn it into an array:
// T: 13:51 Stack.java
public class Stack {
private int size = 0;
private int[] elements = new int[2];
public void push(int element) {
size++;
this.elements = element;
}
public int pop() {
if (size == 0)
throw new Underflow();
--size;
return elements;
}
}
Ah, but there are compile errors. Let’s tackle them one by one. The elements variable in push needs brackets:
// T: 14:01 Stack.java
public void push(int element) {
size++;
this.elements[] = element;
}
We need something to put into those braces. Hmmm. There’s that size++ from the previous snippets:
// T: 14:07 Stack.java
public void push(int element) {
this.elements[size++] = element;
}
There’s the elements variable in pop too. It needs braces:
// T: 14:13
public int pop() {
if (size == 0)
throw new Underflow();
--size;
return elements[];
}
Oh look! There’s that nice --size we could put in there:
// T: 14:24
public int pop() {
if (size == 0)
throw new Underflow();
return elements[--size];
}
And now the tests pass again. It has been 94 seconds since the tests last passed.
And we’re done. Oh, there’s more we could do. The stack holds only two elements and does not deal with overflows, but there’s nothing left that I want to demonstrate in this example. So, consider those improvements an exercise for you, my reader.
It has taken 14 minutes and 24 seconds to write an integer stack from scratch. The rhythm you saw here was real and is typical. This is how TDD feels, regardless of the scope of the project.
Exercise
Implement a first-in-first-out queue of integers using the technique shown previously. Use a fixed-sized array to hold the integers. You will likely need two pointers to keep track of where the elements are to be added and removed. When you are done, you may find that you have implemented a circular buffer.
Prime Factors
Watch related video: Prime Factors
Access video by registering at informit.com/register
The next example has a story and a lesson. The story begins in 2002 or thereabouts. I had been using TDD for a couple of years by that time and was learning Ruby. My son, Justin, came home from school and asked me for help with a homework problem. The homework was to find the prime factors of a set of integers.
I told Justin to try to work the problem by himself and that I would write a little program for him that would check his work. He retired to his room, and I set my laptop up on the kitchen table and started to ponder how to code the algorithm to find prime factors.
I settled on the obvious approach of using the sieve of Eratosthenes to generate a list of prime numbers and then dividing those primes into the candidate number. I was about to code it when a thought occurred to me: What if I just start writing tests and see what happens?
I began writing tests and making them pass, following the TDD cycle. And this is what happened.
First watch the video if you can. It will show you a lot of the nuances that I can’t show in text. In the text that follows, I avoid the tedium of all the timestamps, compile-time errors, and so on. I just show you the incremental progress of the tests and the code.
We begin with the most obvious and degenerate case. Indeed, that follows a rule:
Rule 4: Write the simplest, most specific, most degenerate2 test that will fail.
2. The word degenerate is used here to mean the most absurdly simple starting point.
The most degenerate case is the prime factors of 1. The most degenerate failing solution is to simply return a null.
public class PrimeFactorsTest {
@Test
public void factors() throws Exception {
assertThat(factorsOf(1), is(empty()));
}
private List<Integer> factorsOf(int n) {
return null;
}
}
Note that I am including the function being tested within the test class. This is not typical but is convenient for this example. It allows me to avoid bouncing back and forth between two source files.
Now this test fails, but it is easy to make it pass. We simply return an empty list:
private List<Integer> factorsOf(int n) {
return new ArrayList<>();
}
Of course, this passes. The next most degenerate test is 2.
assertThat(factorsOf(2), contains(2));
This fails; but again, it’s easy to make it pass. That’s one of the reasons we choose degenerate tests: they are almost always easy to make pass.
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n>1)
factors.add(2);
return factors;
}
If you watched the video, you saw that this was done in two steps. The first step was to extract the new ArrayList<>() as a variable named factors. The second step was to add the if statement.
I emphasize these two steps because the first follows Rule 5.
Rule 5: Generalize where possible.
The original constant, new ArrayList<>(), is very specific. It can be generalized by putting it into a variable that can be manipulated. It’s a small generalization, but small generalizations often are all that are necessary.
And so, the tests pass again. The next most degenerate test elicits a fascinating result:
assertThat(factorsOf(3), contains(3));
This fails. Following Rule 5, we need to generalize. There is a very simple generalization that makes this test pass. It might surprise you. You’ll have to look closely; otherwise you’ll miss it.
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n>1)
factors.add(n);
return factors;
}
I sat at my kitchen table and marveled that a simple one-character change that replaced a constant with a variable, a simple generalization, made the new test pass and kept all previous tests passing.
I’d say we were on a roll, but the next test is going to be disappointing. The test itself is obvious:
assertThat(factorsOf(4), contains(2, 2));
But how do we solve that by generalizing? I can’t think of a way. The only solution I can think of is to test whether n is divisible by 2, and that just isn’t very general. Nevertheless,
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n>1) {
if (n%2 == 0) {
factors.add(2);
n /= 2;
}
factors.add(n);
}
return factors;
}
Not only is this not very general; it also fails a previous test. It fails the test for the prime factors of 2. The reason should be clear. When we reduce n by a factor of 2, it becomes 1, which then gets put into the list.
We can fix that with some even less general code:
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n > 1) {
if (n % 2 == 0) {
factors.add(2);
n /= 2;
}
if (n > 1)
factors.add(n);
}
return factors;
}
At this point, you might fairly accuse me of just tossing in various if statements to make the tests pass. That’s not far from the truth. You might also accuse me of violating Rule 5, because none of this recent code is particularly general. On the other hand, I don’t see any options.
But there’s a hint of a generalization to come. Notice that the two if statements have identical predicates. It’s almost as if they were part of an unwound loop. Indeed, there’s no reason that second if statement needs to be inside the first.
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n > 1) {
if (n % 2 == 0) {
factors.add(2);
n /= 2;
}
}
if (n > 1)
factors.add(n);
return factors;
}
This passes and looks very much like an unwound loop.
The next three tests pass without any changes:
assertThat(factorsOf(5), contains(5)); assertThat(factorsOf(6), contains(2,3)); assertThat(factorsOf(7), contains(7));
That’s a pretty good indication that we are on the right track, and it makes me feel better about those ugly if statements.
The next most degenerate test is 8, and it must fail because our solution code simply cannot put three things into the list:
assertThat(factorsOf(8), contains(2, 2, 2));
The way to make this pass is another surprise—and a powerful application of Rule 5. We change an if to a while:
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n > 1) {
while (n % 2 == 0) {
factors.add(2);
n /= 2;
}
}
if (n > 1)
factors.add(n);
return factors;
}
I sat at my kitchen table and once again I marveled. It seemed to me that something profound had happened here. At that time, I didn’t know what it was. I do now. It was Rule 5. It turns out the while is a general form of if, and if is the degenerate form of while.
The next test, 9, must also fail because nothing in our solution factors out 3:
assertThat(factorsOf(9), contains(3, 3));
To solve it, we need to factor out 3s. We could do that as follows:
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n > 1) {
while (n % 2 == 0) {
factors.add(2);
n /= 2;
}
while (n % 3 == 0) {
factors.add(3);
n /= 3;
}
}
if (n > 1)
factors.add(n);
return factors;
}
But this is horrific. Not only is it a gross violation of Rule 5, but it’s also a huge duplication of code. I’m not sure which rule violation is worse!
And this is where the generalization mantra kicks in:
As the tests get more specific, the code gets more generic.
Every new test we write makes the test suite more specific. Every time we invoke Rule 5, the solution code gets more generic. We’ll come back to this mantra later. It turns out to be critically important for test design and for the prevention of fragile tests.
We can eliminate the violation of duplication, and Rule 5, by putting the original factoring code into a loop:
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
int divisor = 2;
while (n > 1) {
while (n % divisor == 0) {
factors.add(divisor);
n /= divisor;
}
divisor++;
}
if (n > 1)
factors.add(n);
return factors;
}
Once again, if you watch the video, you will see that this was done in several steps. The first step was to extract the three 2s into the divisor variable. The next step was to introduce the divisor++ statement. Then the initialization of the divisor variable was moved above the if statement. Finally, the if was changed into a while.
There it is again: that transition from if->while. Did you notice that the predicate of the original if statement turned out to be the predicate for the outer while loop? I found this to be startling. There’s something genetic about it. It’s as though the creature that I’ve been trying to create started from a simple seed and gradually evolved through a sequence of tiny mutations.
Notice that the if statement at the bottom has become superfluous. The only way the loop can terminate is if n is 1. That if statement really was the terminating condition of an unwound loop!
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
int divisor = 2;
while (n > 1) {
while (n % divisor == 0) {
factors.add(divisor);
n /= divisor;
}
divisor++;
}
return factors;
}
Just a little bit of refactoring, and we get this:
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
for (int divisor = 2; n > 1; divisor++)
for (; n % divisor == 0; n /= divisor)
factors.add(divisor);
return factors;
}
And we’re done. If you watch the video, you’ll see that I added one more test, which proves that this algorithm is sufficient.
Sitting at my kitchen table, I saw those three salient lines and I had two questions. Where did this algorithm come from, and how does it work?
Clearly, it came from my brain. It was my fingers on the keyboard after all. But this was certainly not the algorithm I had planned on creating at the start. Where was the sieve of Eratosthenes? Where was the list of prime numbers? None of it was there!
Worse, why does this algorithm work? I was astounded that I could create a working algorithm and yet not understand how it functioned. I had to study it for a while to figure it out. My dilemma was the divisor++ incrementer of the outer loop, which guarantees that every integer will be checked as a factor, including composite factors! Given the integer 12, that incrementer will check whether 4 is a factor. Why doesn’t it put 4 in the list?
The answer is in the order of the execution, of course. By the time the incrementer gets to 4, all the 2s have been removed from n. And if you think about that for a bit, you’ll realize that it is the sieve of Eratosthenes—but in a very different form than usual.
The bottom line here is that I derived this algorithm one test case at a time. I did not think it through up front. I didn’t even know what this algorithm was going to look like when I started. The algorithm seemed to almost put itself together before my eyes. Again, it was like an embryo evolving one small step at a time into an ever-more-complex organism.
Even now, if you look at those three lines, you can see the humble beginnings. You can see the remnants of that initial if statement and fragments of all the other changes. The breadcrumbs are all there.
And we are left with a disturbing possibility. Perhaps TDD is a general technique for incrementally deriving algorithms. Perhaps, given a properly ordered suite of tests, we can use TDD to derive any computer program in a step-by-step, determinative, manner.
In 1936, Alan Turing and Alonzo Church separately proved that there was no general procedure for determining if there was a program for any given problem.3 In so doing, they separately, and respectively, invented procedural and functional programming. Now TDD looks like it might be a general procedure for deriving the algorithms that solve the problems that can be solved.
3. This was Hilbert’s “decidability problem.” He asked whether there was a generalized way to prove that any given Diophantine equation was solvable. A Diophantine equation is a mathematical function with integer inputs and outputs. A computer program is also a mathematical function with integer inputs and outputs. Therefore, Hilbert’s question can be described as pertaining to computer programs.
The Bowling Game
In 1999, Bob Koss and I were together at a C++ conference. We had some time to kill, so we decided to practice this new idea of TDD. We chose the simple problem of computing the score of a game of bowling.
A game of bowling consists of ten frames. In each frame, the player is given two attempts to roll a ball toward ten wooden pins in order to knock them down. The number of pins knocked down by a ball is the score for that ball. If all ten pins are knocked down by the first ball, it is called a strike. If knocking all ten pins down requires both balls, then it is called a spare. The dreaded gutter ball (Figure 2.3) yields no points at all.
Figure 2.3 The infamous gutter ball
The scoring rules can be stated succinctly as follows:
If the frame is a strike, the score is 10 plus the next two balls.
If the frame is a spare, the score is 10 plus the next ball.
Otherwise, the score is the two balls in the frame.
The score sheet in Figure 2.4 is a typical (if rather erratic) game.

Figure 2.4 Score sheet of a typical game
On the player’s first attempt, he knocked down one pin. On his second attempt, he knocked down four more, for a total of 5 points.
In the second frame, he rolled a 4 followed by a 5, giving him a 9 for the frame and a total of 14.
In the third frame, he rolled a 6 followed by a 4 (a spare). The total for that frame cannot be computed until the player begins the next frame.
In the fourth frame, the player rolls a 5. Now the score can be computed for the previous frame, which is 15, for a total of 29 in the third frame.
The spare in the fourth frame must wait until the fifth frame, for which the player rolls a strike. The fourth frame is therefore 20 points for a total of 49.
The strike in the fifth frame cannot be scored until the player rolls the next two balls for the sixth frame. Unfortunately, he rolls a 0 and a 1, giving him only 11 points for the fifth frame and a total of 60.
And on it goes until the tenth and final frame. Here the player rolls a spare and is thus allowed to roll one extra ball to finish out that spare.
Now, you are a programmer, a good object-oriented programmer. What are the classes and relationships you would use to represent the problem of computing the score of a game of bowling? Can you draw it in UML?4
4. The Unified Modeling Language. If you don’t know UML, don’t worry—it’s just arrows and rectangles. You’ll work it out from the description in the text.
Perhaps you might come up with something like what is shown in Figure 2.5.
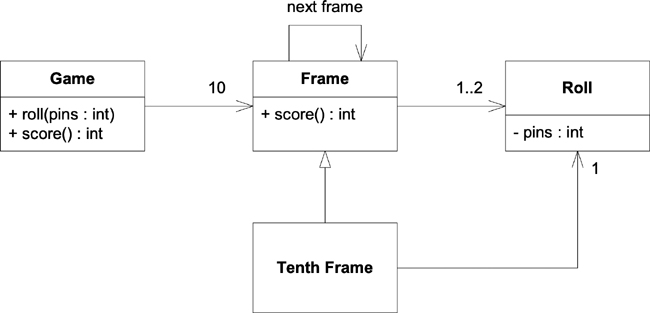
Figure 2.5 A UML diagram of the scoring of bowling
The Game has ten Frames. Each Frame has one or two Rolls, except the TenthFrame subclass, which inherits the 1..2 and adds one more roll to make it 2..3. Each Frame object points to the next Frame so that the score function can look ahead in case it has to score a spare or a strike.
The Game has two functions. The roll function is called every time the player rolls a ball, and it is passed the number of pins the player knocked down. The score function is called once all the balls are rolled, and it returns the score for the entire game.
That’s a nice, simple object-oriented model. It ought to be pretty easy to code. Indeed, given a team of four people, we could divide the work into the four classes and then meet a day or so later to integrate them and get them working.
Or, we could use TDD. If you can watch the video, you should do that now. In any case, please read through the text that follows.
Watch related video: Bowling Game
Access video by registering at informit.com/register
We begin, as always, with a test that does nothing, just to prove we can compile and execute. Once this test runs, we delete it:
public class BowlingTest {
@Test
public void nothing() throws Exception {
}
}
Next, we assert that we can create an instance of the Game class:
@Test
public void canCreateGame() throws Exception {
Game g = new Game();
}
Then we make that compile and pass by directing our IDE to create the missing class:
public class Game {
}
Next, we see if we can roll one ball:
@Test
public void canRoll() throws Exception {
Game g = new Game();
g.roll(0);
}
And then we make that compile and pass by directing the IDE to create the roll function, and we give the argument a reasonable name:
public class Game {
public void roll(int pins) {
}
}
You’re probably already bored. This should be nothing new to you by now. But bear with me—it’s about to get interesting. There’s a bit of duplication in the tests already. We should get rid of it, so we factor out the creating of the game into the setup function:
public class BowlingTest {
private Game g;
@Before
public void setUp() throws Exception {
g = new Game();
}
}
This makes the first test completely empty, so we delete it. The second test is also pretty useless because it doesn’t assert anything. We delete it as well. Those tests served their purpose. They were stairstep tests.
Stairstep tests: Some tests are written just to force us to create classes or functions or other structures that we’re going to need. Sometimes these tests are so degenerate that they assert nothing. Other times they assert something very naive. Often these tests are superseded by more comprehensive tests later and can be safely deleted. We call these kinds of tests stairstep tests because they are like stairs that allow us to incrementally increase the complexity to the appropriate level.
Next, we want to assert that we can score a game. But to do that, we need to roll a complete game. Remember that the score function can be called only after all the balls in a game are rolled.
We fall back on Rule 4 and roll the simplest, most degenerate game we can think of:
@Test
public void gutterGame() throws Exception {
for (int i=0; i<20; i++)
g.roll(0);
assertEquals(0, g.score());
}
Making this pass is trivial. We just need to return zero from score. But first we return -1 (not shown) just to see it fail. Then we return zero to see it pass:
public class Game {
public void roll(int pins) {
}
public int score() {
return 0;
}
}
Okay, I said this was about to get interesting, and it is. Just one more little setup. The next test is another example of Rule 4. The next most degenerate test I can think of is all ones. We can write this test with a simple copy paste from the last test:
@Test
public void allOnes() throws Exception {
for (int i=0; i<20; i++)
g.roll(1);
assertEquals(20, g.score());
}
This creates some duplicate code. The last two tests are virtually identical. When we refactor, we’ll have to fix that. But first, we need to make this test pass, and that’s really easy. All we need to do is add up all the rolls:
public class Game {
private int score;
public void roll(int pins) {
score += pins;
}
public int score() {
return score;
}
}
Of course, this is not the right algorithm for scoring bowling. Indeed, it is hard to see how this algorithm could ever evolve into becoming the rules for scoring bowling. So, I’m suspicious—I expect squalls in the coming tests. But for now, we must refactor.
The duplication in the tests can be eliminated by extracting a function called rollMany. The IDE’s Extract Method refactoring helps immensely with this and even detects and replaces both instances of the duplication:
public class BowlingTest {
private Game g;
@Before
public void setUp() throws Exception {
g = new Game();
}
private void rollMany(int n, int pins) {
for (int i = 0; i < n; i++) {
g.roll(pins);
}
}
@Test
public void gutterGame() throws Exception {
rollMany(20, 0);
assertEquals(0, g.score());
}
@Test
public void allOnes() throws Exception {
rollMany(20, 1);
assertEquals(20, g.score());
}
}
Okay, next test. It’s hard to think of something degenerate at this point, so we might as well try for a spare. We’ll keep it simple though: one spare, with one extra bonus ball, and all the rest gutter balls.
@Test
public void oneSpare() throws Exception {
rollMany(2, 5); // spare
g.roll(7);
rollMany(17, 0);
assertEquals(24, g.score());
}
Let’s check my logic: This game has two balls in each frame. The first two balls are the spare. The next ball is the ball after the spare, and the 17 gutter balls complete the game.
The score in the first frame is 17, which is 10 plus the 7 rolled in the next frame. The score for the whole game, therefore, is 24 because the 7 is counted twice. Convince yourself that this is correct.
This test fails, of course. So how do we get it to pass? Let’s look at the code:
public class Game {
private int score;
public void roll(int pins) {
score += pins;
}
public int score() {
return score;
}
}
The score is being calculated in the roll function, so we need to modify that function to account for the spare. But that will force us to do something really ugly, like this:
public void roll(int pins) {
if (pins + lastPins == 10) { // horrors!
//God knows what…
}
score += pins;
}
That lastPins variable must be a field of the Game class that remembers what the last roll was. And if the last roll and this roll add up to 10, then that’s a spare. Right? Ew!
You should feel your sphincter muscles tightening. You should feel your gorge rise and a tension headache beginning to build. The angst of the software craftsman should be raising your blood pressure.
This is just wrong!
We’ve all had that feeling before, haven’t we? The question is, what do you do about it?
Whenever you get that feeling that something is wrong, trust it! So, what is it that’s wrong?
There’s a design flaw. You might rightly wonder how there could be a design flaw in two executable lines of code. But the design flaw is there; it’s blatant, and it’s deeply harmful. As soon as I tell you what it is you’ll recognize it and agree with me. Can you find it?
Jeopardy song interlude.
I told you what the design flaw was at the very start. Which of the two functions in this class claims, by its name, to calculate the score? The score function, of course. Which function actually does calculate the score? The roll function. That’s misplaced responsibility.
Misplaced responsibility: A design flaw in which the function that claims to perform a computation does not actually perform the computation. The computation is performed elsewhere.
How many times have you gone to the function that claims to do some task, only to find that function does not do that task? And now you have no idea where, in the system, that task is actually done. Why does this happen?
Clever programmers. Or rather, programmers who think they are clever.
It was very clever of us to sum up the pins in the roll function, wasn’t it? We knew that function was going to be called once per roll, and we knew that all we had to do was sum up the rolls, so we just put that addition right there. Clever, clever, clever. And that cleverness leads us to Rule 6.
Rule 6: When the code feels wrong, fix the design before proceeding.
So how do we fix this design flaw? The calculation of the score is in the wrong place, so we’re going to have to move it. By moving it, perhaps we’ll be able to figure out how to pass the spare test.
Moving the calculation means that the roll function is going to have to remember all the rolls in something like an array. Then the score function can sum up the array.
public class Game {
private int rolls[] = new int[21];
private int currentRoll = 0;
public void roll(int pins) {
rolls[currentRoll++] = pins;
}
public int score() {
int score = 0;
for (int i = 0; i < rolls.length; i++) {
score += rolls[i];
}
return score;
}
}
This fails the spare test, but it passes the other two tests. What’s more, the spare test fails for the same reason as before. So, although we’ve completely changed the structure of the code, the behavior remains unchanged. By the way, that is the definition of refactoring.
Refactoring: A change to the structure of the code that has no effect upon the behavior.5
5. Martin Fowler, Refactoring: Improving the Design of Existing Code, 2nd ed. (Addison-Wesley, 2019).
Can we pass the spare case now? Well, maybe, but it’s still icky:
public int score() {
int score = 0;
for (int i = 0; i < rolls.length; i++) {
if (rolls[i] + rolls[i+1] == 10) { // icky
// What now?
}
score += rolls[i];
}
return score;
}
Is that right? No, it’s wrong, isn’t it? It only works if i is even. To make that if statement actually detect a spare, it would have to look like this:
if (rolls[i] + rolls[i+1] == 10 && i%2 == 0) { // icky
So, we’re back to Rule 6—there’s another design problem. What could it be?
Look back to the UML diagram earlier in this chapter. That diagram shows that the Game class should have ten Frame instances. Is there any wisdom in that? Look at our loop. At the moment, it’s going to loop 21 times! Does that make any sense?
Let me put it this way. If you were about to review the code for scoring bowling—code that you’d never seen before—what number would you expect to see in that code? Would it be 21? Or would it be 10?
I hope you said 10, because there are 10 frames in a game of bowling. Where is the number 10 in our scoring algorithm? Nowhere!
How can we get the number 10 into our algorithm? We need to loop through the array one frame at a time. How do we do that?
Well, we could loop through the array two balls at a time, couldn’t we? I mean like this:
public int score() {
int score = 0;
int i = 0;
for (int frame = 0; frame<10; frame++) {
score += rolls[i] + rolls[i+1];
i += 2;
}
return score;
}
Once again, this passes the first two tests and fails the spare test for the same reason as before. So, no behavior was changed. This was a true refactoring.
You might be ready to tear this book up now because you know that looping through the array two balls at a time is just plain wrong. Strikes have only one ball in their frame, and the tenth frame could have three.
True enough. However, so far none of our tests has used a strike, or the tenth frame. So, for the moment, two balls per frame works fine.
Can we pass the spare case now? Yes. It’s trivial:
public int score() {
int score = 0;
int i = 0;
for (int frame = 0; frame < 10; frame++) {
if (rolls[i] + rolls[i + 1] == 10) { // spare
score += 10 + rolls[i + 2];
i += 2;
} else {
score += rolls[i] + rolls[i + 1];
i += 2;
}
}
return score;
}
This passes the spare test. Nice. But the code is pretty ugly. We can rename i to frameIndex and get rid of that ugly comment by extracting a nice little method:
public int score() {
int score = 0;
int frameIndex = 0;
for (int frame = 0; frame < 10; frame++) {
if (isSpare(frameIndex)) {
score += 10 + rolls[frameIndex + 2];
frameIndex += 2;
} else {
score += rolls[frameIndex] + rolls[frameIndex + 1];
frameIndex += 2;
}
}
return score;
}
private boolean isSpare(int frameIndex) {
return rolls[frameIndex] + rolls[frameIndex + 1] == 10;
}
That’s better. We can also clean up the ugly comment in the spare test by doing the same:
private void rollSpare() {
rollMany(2, 5);
}
@Test
public void oneSpare() throws Exception {
rollSpare();
g.roll(7);
rollMany(17, 0);
assertEquals(24, g.score());
}
Replacing comments with pleasant little functions like this is almost always a good idea. The folks who read your code later will thank you.
So, what’s the next test? I suppose we should try a strike:
@Test
public void oneStrike() throws Exception {
g.roll(10); // strike
g.roll(2);
g.roll(3);
rollMany(16, 0);
assertEquals(20, g.score());
}
Convince yourself that this is correct. There’s the strike, the 2 bonus balls, and 16 gutter balls to fill up the remaining eight frames. The score is 15 in the first frame and 5 in the second. All the rest are 0 for a total of 20.
This test fails, of course. What do we have to do to make it pass?
public int score() {
int score = 0;
int frameIndex = 0;
for (int frame = 0; frame < 10; frame++) {
if (rolls[frameIndex] == 10) { // strike
score += 10 + rolls[frameIndex+1] +
rolls[frameIndex+2];
frameIndex++;
}
else if (isSpare(frameIndex)) {
score += 10 + rolls[frameIndex + 2];
frameIndex += 2;
} else {
score += rolls[frameIndex] + rolls[frameIndex + 1];
frameIndex += 2;
}
}
return score;
}
This passes. Note that we increment frameIndex only by one. That’s because a strike has only one ball in a frame—and you were so worried about that, weren’t you?
This is a very good example of what happens when you get the design right. The rest of the code just starts trivially falling into place. Pay special attention to Rule 6, boys and girls, and get the design right early. It will save you immense amounts of time.
We can clean this up quite a bit. That ugly comment can be fixed by extracting an isStrike method. We can extract some of that ugly math into some pleasantly named functions too. When we’re done, it looks like this:
public int score() {
int score = 0;
int frameIndex = 0;
for (int frame = 0; frame < 10; frame++) {
if (isStrike(frameIndex)) {
score += 10 + strikeBonus(frameIndex);
frameIndex++;
} else if (isSpare(frameIndex)) {
score += 10 + spareBonus(frameIndex);
frameIndex += 2;
} else {
score += twoBallsInFrame(frameIndex);
frameIndex += 2;
}
}
return score;
}
We can also clean up the ugly comment in the test by extracting a rollStrike method:
@Test
public void oneStrike() throws Exception {
rollStrike();
g.roll(2);
g.roll(3);
rollMany(16, 0);
assertEquals(20, g.score());
}
What’s the next test? We haven’t tested the tenth frame yet. But I’m starting to feel pretty good about this code. I think it’s time to break Rule 3 and go for the gold. Let’s test a perfect game!
@Test
public void perfectGame() throws Exception {
rollMany(12, 10);
assertEquals(300, g.score());
}
We roll a strike in the first nine frames, and then a strike and two 10s in the tenth frame. The score, of course, is 300—everybody knows that.
What’s going to happen when I run this test? It should fail, right? But, no! It passes! It passes because we are done! The score function is the solution. You can prove that to yourself by reading it. Here, you follow along while I read it to you:
For each of the ten frames
If that frame is a strike,
Then the score is 10 plus the strike bonus
(the next two balls).
If that frame is a spare,
Then the score is 10 plus the spare bonus
(the next ball).
Otherwise,
The score is the two balls in the frame.
The code reads like the rules for scoring bowling. Go to the beginning of this chapter and read those rules again. Compare them to the code. And then ask yourself if you’ve ever seen requirements and code that are so closely aligned.
Some of you may be confused about why this works. You look at the tenth frame on that scorecard and you see that it doesn’t look like any of the other frames; and yet there is no code in our solution that makes the tenth frame a special case. How can that be?
The answer is that the tenth frame is not special at all. It is drawn differently on the score card, but it is not scored differently. There is no special case for the tenth frame.
And we were going to make a subclass out of it!
Look back at that UML diagram. We could have divvied out the tasks to three or four programmers and integrated a day or two later. And the tragedy is that we’d have gotten it working. We would have celebrated the 4006 lines of working code, never knowing that the algorithm was a for loop and two if statements that fits into 14 lines of code.
6. I know it’s 400 lines of code because I’ve written it.
Did you see the solution early? Did you see the for loop and two if statements? Or did you expect one of the tests to eventually force me to write the Frame class? Were you holding out for the tenth frame? Is that where you thought all the complexity would be found?
Did you know we were done before we ran the tenth frame test? Or did you think there was a lot more to do? Isn’t it fascinating that we can write a test fully expecting more work ahead, only to find, to our surprise, that we are done?
Some folks have complained that if we’d followed the UML diagram shown earlier, we’d have wound up with code that was easier to change and maintain. That’s pure bollocks! What would you rather maintain, 400 lines of code in four classes or 14 lines with a for loop and two if statements?
Conclusion
In this chapter, we studied the motivations and basics of TDD. If you’ve gotten this far, your head may be spinning. We covered a lot of ground. But not nearly enough. The next chapter goes significantly deeper into the topic of TDD, so you may wish to take a little rest before turning the page.