Fast, Reliable Tests
AUDIENCE
Programmers
Our tests don’t get in our way.
Teams who embrace test-driven development accumulate thousands of tests. The more tests you have, the more important speed and reliability become. With TDD, you run the tests as often as one or two times every minute. They must be fast, and they must produce the same answer every time. If they don’t, you won’t be able to get feedback within 1-5 seconds, and that’s crucial for the TDD loop to work effectively. You’ll stop running the tests as frequently, which means you won’t catch errors as quickly, which will slow you down.
You can work around the problem by programming your watch script to run only a subset of tests, but eventually, slow tests will start causing problems during integration, too. Instead of getting feedback within five minutes, it will take tens of minutes, or even hours. To add insult to injury, the tests will often fail randomly, requiring you to start the long process all over again, adding friction and causing people to ignore genuine failures.
Fast, reliable tests are a game changer. They take practice and good design, but once you know their secrets, they’re easier and faster to write than slow, flaky tests. Here’s how.
Rely on Narrow Unit Tests
Broad tests are written to cover large parts of your software: for example, they might launch a web browser, navigate to a URL, click buttons and enter data, then check that the browser shows the expected result. They’re sometimes called “end-to-end tests,” although technically, end-to-end tests are just one type of broad test.
Although broad tests seem like a good way to get test coverage, they’re a trap. Broad tests are slow and unreliable. You need your build to run hundreds or thousands of tests per second, and to do so with perfect reliability. The way to do so is narrow tests.
A narrow test is focused on a small amount of code. Usually a method or function, or several, in a particular class or module. Sometimes, a narrow test will focus on a small cross-cutting behavior that involves several modules.
The best types of narrow tests are called unit tests in the Agile community, although there’s some disagreement over the exact definition of “unit test.” The important part is that unit tests are fast and deterministic. This usually requires the test to run entirely in memory.
The vast majority of your tests should be unit tests. The size of your unit test code should be proportional to the size of your production code. The ratios vary, but it will often be close to 1:1.
Creating unit tests requires good design. If you have trouble writing them, it could be a sign of problems in your design. Look for ways to decouple your code so that each class or module can be tested independently.
Test Outside Interactions with Narrow Integration Tests
Unit tests usually test code that’s in memory, but your software doesn’t operate entirely in memory. It also has to talk to the outside world. To test code that does so, use narrow integration tests, also known as focused integration tests.
Conceptually, narrow integration tests are just like unit tests. In practice, because they involve the outside world, narrow integration tests tend to involve a lot of complicated setup and teardown. They’re much slower than unit tests: unit tests can run at a rate of hundreds or thousands per second, but narrow integration tests typically run at a rate of dozens per second.
Design your code to minimize the number of narrow integration tests you need. For example, if your code depends on a third-party service, don’t call the service directly from the code that needs it. Instead, create an infrastructure wrapper, also known as a gateway: a class or module that encapsulates the service and its network calls. Test the infrastructure wrapper with narrow integration tests, but use unit tests to test the code that uses it. The “Application Infrastructure” episode of [Shore2020b] has an example. You should end up with a relatively small number of narrow integration tests, proportional to the number of external systems your code interacts with.
Simulate Nonlocal Dependencies
Some dependencies are too difficult or expensive to run locally on your development machine. You still need to be able to run your tests locally, though, for both reproducibility and speed.
To solve this problem, start by creating an infrastructure wrapper for the dependency, as normal. Then write your narrow integration test to simulate the dependency rather than having the infrastructure wrapper call it for real. For example, if your code uses a billing service with a REST API, you would write a small HTTP server to stand in for the billing service in your tests. See the “Spy Server” pattern in [Shore2018b] for details, and the “Microservice Clients Without Mocks” episodes of [Shore2020b] for an example.
This raises the question: if you don’t test your software against its real dependencies, how do you know that it works? Because external systems can change or fail at any time, the real answer is “monitoring.” (See “Paranoiac Telemetry”.) But some teams also use contract tests [Fowler2011] to detect changes to providers’ services. These work best when the provider commits to running the tests themself.
Control Global State
Any tests that deal with global state need careful thought. That includes global variables, such as static variables and singletons; external data stores and systems, such as filesystems, databases, and services; and machine-specific state and functions, such as the system clock, locale, time zone, and random number generator.
Tests are often written to assume that global state will be set in a certain way. Most of the time, it will be. But once in a while, it isn’t, often due to a race condition, and the test fails for no apparent reason. When you run it again, the test passes. The result is a flaky test: a test that works most of the time, but occasionally fails randomly.
Flaky tests are insidious. Because re-running the test “fixes” the problem, people learn to deal with flaky tests by just running them again. Once you’ve accumulated hundreds of flaky tests, your test suite requires multiple runs before it succeeds. By that time, fixing the problem takes a lot of work.
When you encounter a flaky test, fix it the same day. Flaky tests are the result of poor design. The sooner you fix them, the fewer problems you’ll have in the future.
The design flaw at the root of flaky tests is allowing global state to pollute your code. Some global state, such as static variables and singletons, can be removed through careful design. Other sorts of global state, such as the system clock and external data, can’t be avoided, but they can be carefully controlled. Use an infrastructure wrapper to abstract it away from the rest of your codebase, and test-drive it with narrow integration tests.
For example, if your code needs to interact with the system clock—perhaps to time out a request, or get the current date—create a wrapper for the system clock and use it in the rest of your code. The “No More Flaky Clock Tests” episode of [Shore2020b] has an example.
Write Sociable Tests
Tests can be solitary or sociable.2 A solitary test is programmed so that all dependencies of the code under test are replaced with special test code called a “test double,” also known as a “mock.” (Technically, a “mock” is a specific type of test double, but the terms are often used interchangeably.)
Solitary tests allow you to test that your code under test calls its dependencies, but they don’t allow you to test that the dependencies work the way your code expects them to. The test doesn’t actually run the dependencies; it runs the test double instead. So if you ever make a change to a dependency that breaks the expectations of any code that uses it, your tests will continue to pass, and you’ll have accidentally introduced a bug.
To prevent this problem, people who write solitary tests also write broad tests to make sure that everything works together correctly. This is duplicated effort, and those broad tests are often slow and flaky.
A better approach, in my opinion—although the community is divided on this point—is to use sociable tests rather than solitary tests. A sociable test runs the code under test without replacing its dependencies. The code uses its actual dependencies when it runs, which means that the tests fail if the dependencies don’t work the way the code under test expects. Figure 13-2 illustrates the difference.
The best unit tests—again, in my opinion—are narrow, sociable tests. They’re narrow in that the test is only testing the class or module under test. They’re sociable in that the code under test still calls its real dependencies. The result is fast tests that provide full confidence that your code works as expected, without requiring the overhead and waste of additional broad tests.
This does raise the question: how do you prevent sociable tests from talking to the outside world? A big part of the answer is to design your code to separate infrastructure and logic, as I’ll explain in a moment. The other part is to program your infrastructure wrappers to be able to isolate themselves from the outside world. My “Testing Without Mocks” article [Shore2018a] catalogs design patterns for doing so, and [Shore2020b] has extensive examples.
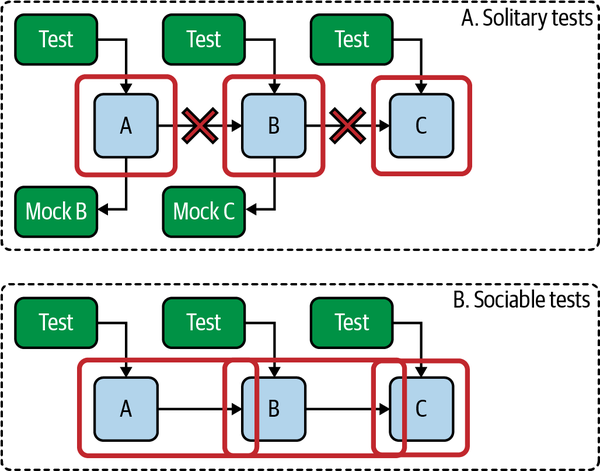
Figure 13-2. Solitary and sociable tests
Separate Infrastructure and Logic
Pure logic, with no dependencies on anything that involves the outside world, is the easiest code to test. By far. So, to make your tests faster and more reliable, separate your logic from your infrastructure. As it turns out, this is a good way to keep your design clean, too.
There are a variety of ways to keep infrastructure and logic separate. Alistair Cockburn’s “Hexagonal Architecture” [Cockburn2008], Gary Bernhard’s “Functional Core, Imperative Shell” [Bernhardt2012], and my “A-Frame Architecture” [Shore2018b] are all similar ways of tackling the problem. Generally speaking, they involve modifying your code so your logic is “pure” and doesn’t depend on infrastructure code.
In the case of A-Frame Architecture, this involves a top-level “application” layer that coordinates “logic” and “infrastructure” layers that have no awareness of each other. This is a simplified example of code you might find in the application layer:
let input = infrastructure.readData(); // infrastructure let output = logic.processInput(input); // logic infrastructure.writeData(output); // infrastructure
[Shore2018b] goes into more detail. For a full example, see [Shore2020b]. It uses A-Frame Architecture starting with episode 2.
Use Broad Tests Only as a Safety Net
If you use TDD, unit tests, narrow integration tests, and sociable tests correctly, your code should be thoroughly covered. Broad tests shouldn’t be needed.
For safety, though, it’s okay to augment your test suite with additional broad tests. I typically write a small number of smoke tests. Smoke tests are broad tests that confirm that your software doesn’t go up in flames when you run it. They’re not comprehensive—they test only your most common scenarios. Use narrow tests for comprehensive testing.
Broad tests tend to be very slow, often requiring seconds per test, and are difficult to make reliable. You should need only a handful of them.
If you didn’t build your software with TDD from the beginning, or if you’re not confident in your ability to use TDD correctly, it’s okay to have more broad tests for safety. But do treat them only as a safety net. If they ever catch an error that your narrow tests don’t, it’s a sign of a problem with your testing strategy. Figure out what went wrong, fix the missing test, and change your testing approach to prevent further gaps. Eventually, you’ll have confidence in your test suite and can reduce the number of broad tests.
Adding Tests to Existing Code
Sometimes you have to add tests to existing code. Either the code won’t have any tests at all, or it will have broad, flaky tests that need to be replaced.
There’s a chicken-and-egg problem with adding tests to code. Narrow tests need to poke into your code to set up dependencies and validate state. Unless your code was written with testability in mind—and non-TDD’d code almost never is—you won’t be able to write good tests.
So you need to refactor. The problem is, in a complex codebase, refactoring is dangerous. Side effects lurk behind every function. Twists of logic wait to trip you up. In short, if you refactor, you’re likely to break something without realizing it.
So you need tests. But to test, you need to refactor. But to refactor, you need tests. Etc., etc., argh.
To break the chicken-and-egg dilemma, you need to be confident your refactorings are safe: that they won’t change the behavior of the code. Luckily, modern IDEs have automated refactorings, and, depending on your language and IDE, they might be guaranteed to be safe. According to Arlo Belshee, the core six safe refactorings you need are Rename, Inline, Extract Method/Function, Introduce Local Variable, Introduce Parameter, and Introduce Field. His article “The Core 6 Refactorings” [Belshee2016b] is well worth reading.
If you don’t have guaranteed-safe refactorings, you can use characterization tests instead. They’re also known as pinning tests or approval tests. Characterization tests are temporary, broad tests that are designed to exhaustively test every behavior of the code you’re changing. Llewellyn Falco’s “Approvals” testing framework, available on GitHub at https://github.com/approvals, is a powerful tool for creating these tests. Emily Bache’s video demonstration of the “Gilded Rose” kata [Bache2018] is an excellent example of how to use approval tests to refactor unfamiliar code.
When you have the ability to refactor safely, you can change the code to make it cleaner. Work in very small steps, focusing on Arlo Belshee’s core six refactorings, and run your tests after each step. Simplify and refine the code until one part of it is testable, then add narrow tests to that part. You may need to write solitary tests rather than sociable tests to begin with.
Continue refining, improving, and testing until all the code you’re working on is covered by high-quality narrow tests. Once it is, you can delete the characterization tests and any other broad tests of that code.
Prerequisites
If you write tests, you can write fast, reliable tests. However, adding tests to existing code will take some time. Introducing slack will help.
Indicators
When you write fast, reliable tests:
-
You don’t “fix” flaky tests by running the test suite again.
-
Your narrow integration tests are proportional to the number of external services and components your code uses.
-
You have only a small number of broad tests.
-
Your test suite averages at least 100 tests per second.
Alternatives and Experiments
There are two schools of thought about how to create good tests in the Agile community: the “classicist” approach and the “mockist” approach. I’ve emphasized the classicist approach in this book, but the mockist approach, spearheaded by Steve Freeman and Nat Pryce, also deserves investigation. Their excellent book, Growing Object-Oriented Software, Guided by Tests, is the best introduction to the approach. [Freeman2010]
Another school of thought gives up on narrow tests entirely and just uses broad tests. It’s quick and easy, at first, but it breaks down as your software grows. You’ll end up spending more time on your tests than they save.
Further Reading
My article, “Testing Without Mocks: A Pattern Language” [Shore2018b], goes into much more detail on how to create fast, reliable tests. The accompanying video series [Shore2020b] demonstrates how to put the ideas into practice.
Although it emphasizes solitary tests more than I prefer, Jay Fields’ Working Effectively with Unit Tests [Fields2015] is chock full of useful advice for creating maintainable tests.
Working Effectively with Legacy Code [Feathers2004] is a must-read for anybody working with legacy code.
2 The terms “sociable” and “solitary” come from Jay Fields. [Fields2015]