So far in this book, we have discussed how to best read and write code. To do so, we have examined how cognitive processes play a role when reading and writing code. For larger codebases, however, it is not just small parts of code that influence how easy it is for people to comprehend it. The way in which you organize code also greatly influences how easily other people can interact with the code. This is especially true for code in libraries, frameworks, and modules that other programmers use rather than change.
Often when we talk about libraries, frameworks, and modules, we talk about their technical aspects, like the language they are created in. However, codebases can also be viewed through a cognitive lens. In this chapter we will discuss CDN, which is a technique to examine codebases from a cognitive perspective. CDN helps you answer questions about existing large codebases, such as “Will this code be easy for people to change?” or “Will this codebase be easy for people to find information in?” Examining codebases from a cognitive rather than technical perspective can help you gain a better perspective on how people interact with your code.
Once we have discussed CDN and studied how it can support our understanding of codebases, we will dive into how to use it to improve the design of existing codebases using an adapted framework called cognitive dimensions of codebases (CDCB).
In the previous chapter we described five different programming activities. This chapter will also examine how properties of a codebase influence the different programming activities in different ways.
Often when we talk about libraries, frameworks, and modules, we talk about their technical aspects. We commonly say things like “This library is written in Python,” “This framework uses node.js,” or “This module is precompiled.”
When we discuss programming languages, we also often look at the technical domain, for example their paradigm (object-oriented, functional, or a mix of both), perhaps the existence of a type system, or whether the language is compiled to byte code or interpreted by a program in another language. You can also look at where the language, framework, or library can run; for example, does this program run in the browser or on a virtual machine? All these aspects concern the technical domain (that is, what the language can do).
However, when we discuss different libraries, frameworks, modules, or programming languages, we can also discuss what they do to your brain rather than your computer.
Exercise 12.1 Think of a codebase you recently used that you did not write yourself. This can be a library you use, of which you had to read the code to understand how to call a function, or a framework in which you fixed a bug.
What made performing your task easier (for example, the presence of documentation, good variables names, comments)?
What made performing your task harder (for example, complex code or lack of documentation)?
CDN can be used to assess the usability of existing large codebases. It was originally created by British researchers Thomas Green, Alan Blackwell, and Marian Petre and consists of a number of different dimensions, each of which represents a different way to examine the codebase at hand. The dimensions were originally created to examine visualizations such as flowcharts, and were later applied to programming languages, also, hence the name. Programming languages, like flowcharts, can be seen as notations, a way to express thoughts and ideas.
The dimensions as Green, Blackwell, and Petre describe them apply only to notations, but in this book we generalize the use of CDN to codebases rather than programming languages. We call this version cognitive dimensions of code bases (CDCB) and use it to examine a codebase to understand how it can be understood and improved. CDCB is especially useful for code written in libraries and frameworks, which other programmers often call rather than adapt.
We will first discuss each of the dimensions in isolation and then dive into how the different dimensions interact with each other and how we can use them to improve existing codebases.
The first dimension to discuss is called error proneness. In some programming languages it is easier to make a mistake than in other languages. JavaScript is currently one of the most popular languages, but it is known to have a few eccentric corner cases.
In JavaScript and other dynamically typed languages, variables are not initialized with a type when they are created. Because it is unclear what the type of an object is at runtime, programmers can become confused about the types of variables that are leading to errors. Also, unexpected coercion of a variable of one type into another type can cause errors. Languages that have strong type systems, such as Haskell, are thought of as being less error-prone because the type system will provide guidance when coding.
Codebases, rather than programming languages, can also be error-prone, for example because of inconsistent conventions, a lack of documentation, or vague names.
Sometimes, codebases inherit dimensions from the programming language that they were created in. For example, a module written in Python could be more error-prone than a very similar library written in C because Python does not have a type system as strong as C’s to catch errors.
Type systems do prevent errors You might wonder whether it is true that type systems prevent errors. In an extensive set of experiments comparing Java to Groovy, German researcher Stefan Hanenberg demonstrated that type systems can indeed help programmers locate and fix errors more quickly. In many cases in Hanenberg’s experiments, the place in the code where the compiler pointed out an error was the same as where the code would crash at runtime. Running code, of course, takes more time, and as such relying on errors at runtime is generally slower.
Hanenberg tried various methods to improve dynamically typed code to make it less error-prone, including better IDE support and documentation, but even in those situations, static-type systems outperformed dynamic ones in terms of time and accuracy of programmers finding bugs.
Another way to examine how people will interact with a programming language or codebase is consistency: How similar are similar things? Are names always structured in the same way, for example, using the same name molds we discussed in chapter 8? Is the layout of code files similar for different classes?
An example of a situation where many programming languages show consistency is in the definition of functions. Maybe you never thought of this, but built-in functions typically have the same user interface as user-defined functions. When you are looking at a function call like print() or print_customer(), you cannot see from the call who created the function, the creator of the programming language, or the code creator.
A framework or language that is inconsistent in its use of names and conventions might lead to greater cognitive load because it will take your brain more energy to understand what is what, and it might take you more time to find relevant information.
Consistency is related to error-proneness, as we saw in chapter 9. Code in which linguistic antipatterns occur (for example, names do not match the implementation of the code) are more error-prone and cause greater cognitive load.
In an earlier chapter we covered code smells, which can make code harder to read. A well-known code smell is a long method, in which a method of a function consists of a lot of code lines, making it harder to understand.
A long method can be the programmer’s fault if they added unnecessary complexity to a method or tried to fit too much functionality into one method. However, some programming languages also need more space than others for the same functionality. The dimension diffuseness covers this . Diffuseness refers to how much room or space a programming construct takes.
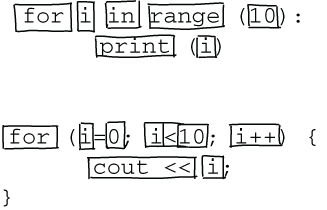
For example, a for-loop in Python looks like this:
for i in range(10):
print(i)
In C++, the same code would be
for (i=0; i<10; i++){
cout << i;
}
Simply counting the lines of code, C++ has three lines, while Python has two. However, diffuseness does not only concern the number of lines of code; you could also consider how many chunks the code consists of. If you count the individual elements, which you might chunk if you are a novice, then the Python code has seven elements, while the C++ code contains nine, as illustrated in figure 12.1.
Figure 12.1 Different chunks in a simple for loop Python (top) and C++(bottom)
This difference between the number of chunks lies in the fact that there are elements in the C++ code that are not present in the Python version (for example, i++).
We too might have more and less diffuse versions of the same code within the same programming language. We covered the example of list comprehensions in Python in earlier chapters; here again are two Python code snippets that do the same thing:
california_branches = []
for branch in branches:
if branch.zipcode[0] == '9'
california_branches.append(branch)
california_branches = [b for b in branches if b.zipcode[0] == '9']
The second version of the code is less diffuse, which might impact readability and understandability.
The hidden dependencies dimension indicates to what extent dependencies are visible to the user. An example of a system with high hidden dependencies is an HTML page with a button controlled by JavaScript, which is stored in a different file. It can be hard to see from the JavaScript file what HTML pages call the function in such a situation. Another example is requirements for files separate from code files. From the codebase it might be hard to see all libraries and frameworks that need to be installed for the code to properly run.
In general, in code the functions that are being called within another function or class are more visible than the other way around: which functions or classes call a given function. In the first case, we can always read a function text and see what functions are being called in the body.
While modern IDEs can reveal hidden dependencies, as shown in figure 12.2, finding the dependencies still requires the use of mouse clicks or shortcuts.
Figure 12.2 Option in PyCharm to find all call locations of a given function
Creators of code can compensate for hidden dependencies with more extensive documentation. Teams might consider having a policy for discussing and adopting new dependencies as well as documenting them when the adoption occurs.
The dimension of provisionality describes how easy it is to think while using the tool. As we covered in chapter 11, sometimes you are programming in an exploratory way when you are not yet sure what exactly you are creating. When you are exploring, you might use pen and paper or whiteboards. These are tools that have ultimate provisionality because you can sketch freely, write down all sorts of annotations, and write incomplete or wrong code without any issues.
When we start coding in a codebase, however, we lose some freedom. If we write code that has syntax errors, it cannot by type checked, and if it does not type check, the code cannot be run. While it is useful to have these types of checks in place, they can hamper our ability to try things and use code as a means of thought rather than an execution model.
If a codebase or programming language is very strict (for example, using types, assertions, and post conditions), it can be hard to use code to express a thought. We then say this tool has low provisionality.
Provisionality is an essential factor in learnability because expressing vague ideas and incomplete code might be needed if you are a beginner in a certain system. Thinking of a plan for your code while also thinking about types and syntax can cause too much cognitive load in beginners.
Related to provisionality is viscosity: how hard it is to make changes in a certain system. Typically, codebases written in dynamically typed languages are a bit easier to change. You can simply change code and do not have to change all corresponding type definitions. Code that is not very modular and contains large blocks of code can also be easier to change because it can be changed directly, and you do not have to make changes in multiple places to multiple functions or classes.
Whether a system is easy to change depends not only on the programming language and the codebase itself; factors surrounding the codebase also impact viscosity. For example, if it takes a long time for a codebase to compile or run tests, that adds to each change’s viscosity.
A dimension related to provisionality is progressive evaluation. The dimension of progressive evaluation describes how easy it is in a given system to check or execute partial work. As we have seen, a system with a lot of provisionality allows the user to sketch out incomplete ideas. A system with progressive evaluation allows the user to also execute incomplete or imperfect code.
Some programming systems allow programmers to do live programming: the programmer can change and then rerun code without stopping the code’s execution. An example of such a programming system is Smalltalk.
Smalltalk was the first language tool to support live programming and allowed on-the-fly inspection and code changes during execution of code. Scratch, a programming language for children heavily inspired by Smalltalk, also allows kids to change code without recompiling.
When designing a codebase or library, you can also allow users to run partial code and gain insight into it. An example of a design that allows for progressive evaluation is the use of optional parameters. When a function has optional parameters, a user of the library can first compile and run the code with the default values, and then update the parameters one by one while the system is in a working state at every step of the way. Another example is Idris’s hole system, which lets you run partial code, after which the compiler suggests valid solutions that could fit the hole. You can then iterate and refine your types, which then leads to smaller holes, and the compiler becomes a tool to explore the solution rather than a constraint that blocks the exploration.
A system with less progressive evaluation does not allow the user to run code in a less than complete or perfect state, which might inhibit provisionality.
The dimension of role expressiveness indicates how easy it is to see the role of different code parts in a program. A simple example of role expressiveness is the fact that in almost all programming languages, calls of functions without parameters are still written with two round brackets at the end; for example, file.open (). While the language designers could have decided that users are allowed to omit the brackets, the brackets now indicate that open () is a function. Brackets at the end of a function are an example of role expressiveness.
Another famous example of role expressiveness is syntax highlighting. Many IDEs color variables differently from keywords, which also helps you to see the roles different code elements play in a program.
Role expressiveness can also be achieved with syntax. For example, calling a function that returns a Boolean value is_set rather than set helps the reader to understand the role of the variable.
We saw a similar concept in chapter 9, in linguistic antipatterns. When a codebase suffers from linguistic antipatterns, constructs like functions and methods mislead the reader about their role. This means the codebase has lower role expressiveness and can be harder to understand.
The dimension closeness of mapping means how close the programming language or the code is to the domain in which problems are solved. Some programming languages have a good closeness of mapping. From chapter 1 on, we have seen the programming language APL, shown again in the next listing. While you might have thought APL was a very confusing language, it, in fact, has a great closeness of mapping to the domain of vector calculus.
Listing 12.1 Binary representation in APL
2 2 2 2 2 ⊤ n ❶
❶ Pieces of documentation like these are small print in the code’s contract.
For example, all variables are by default vectors, as we can see in listing 12.1 from the fact that T works on the list of 2s. This design is nice if you are used to thinking in vectors and if the problems you are solving can often be solved with the use of vector calculus. COBOL is also often named as a language with a good closeness of mapping to the domain of business and finance. Excel is another example of a programming language with a good closeness of mapping. The layout in rows and columns is precisely how financial calculations were done even before we had computers.
Most modern programming languages, including Java, Python, and JavaScript, do not have a good closeness of mapping; there aren’t any problems we can’t solve with these languages. Of course, that is not always a bad thing. It can be very helpful to be able to solve any given problem with Python or Java, and to not have to learn a new programming language for each new project or customers.
Codebases can also have a good closeness of mapping to their business domain. Codebases that reuse concepts and words of their target domain are typically easier to understand for customers than codebases that use more generic terms. For example, a method called executeQuery () has a lower closeness of mapping than the function findCustomers().
In our field over the last few years, we have seen a growing interest in better incorporating domain into code. For example, the domain-driven design philosophy prescribes that the structure and identifiers in code should match the business domain. This is a move toward better closeness of mapping in codebases.
Exercise 12.2 Make a list of all variable, function, and class names in your codebase. For each of the names, investigate the closeness of mapping. You can ask yourself these questions for each identifier name:
Is the variable name expressed in the language of the domain?
Is it clear what process outside the code this name refers to?
Is it clear what object outside the code this name refers to?
Some systems require a user to think very hard, to perform hard mental operations outside of the system. For example, a language like Haskell requires a user to think about types of all functions and parameters. You cannot ignore type signatures of functions or it will be close to impossible to write working code in Haskell. Similarly, C++ requires the user to use pointers in many situations and reason with them rather than objects.
Hard mental operations are, of course, not all bad. The thinking you require a user to do might pay off, for example, in fewer errors in a strict type system or in better performance or more efficient memory usage in pointers.
However, when you ask the user to perform these hard mental operations in a system you design, you have to be aware of this and consider the operations with great care.
Examples of hard mental operations people might perform within a codebase are often situations that ask a lot of the memory of users. For example, asking users to memorize a large number of parameters to call in the right order is a hard mental operation because it places a heavy demand on STM.
We saw that vague function names have poor closeness of mapping. These names also create hard mental work. Having to memorize non-informative names of functions like execute() or control () require these functions to be stored in the user’s LTM and thus can also be hard mental operations.
Finally, some operations are hard because they take a toll on the working memory, for example, if data has to be downloaded from two difference sources in two different formats and converted into a third format. The user will then have to keep track of the different streams and their corresponding types.
The secondary notation dimension indicates the possibility for the programmer to add extra meaning to code, which is not in the formal specification. The most commonly occurring example of secondary notation is the possibility to add comments to source code. Comments are not formally part of the language, at least not in the sense that they change the behavior of the program. However, comments can help readers of code understand it better. Another example of secondary notation is named parameters in Python. As shown in the next listing, arguments can be passed together with a name, and in that case, the order of the parameters may be different at the call site than in the function definition.
Listing 12.2 Keyword (named) parameters in Python
def move_arm(angle, power):
robotapi.move(angle,power)
# three different ways to call move_arm
move(90, 100) ❶
move(angle = 90, power = 100) ❶
move(power = 100, angle = 90) ❶
❶ Python program demonstrating three different ways to call a function: with the arguments in order, with names in order, or with names in any order.
Adding a named parameter to a function call in Python does not change the way the code is executed, but it does enable the IDE to express the role of each parameter when the function is called.
The abstraction dimension describes whether a user of your system can create their own abstractions that are as powerful as the built-in abstractions. An example of abstractions that most programming languages allow for is the creation of functions, objects, or classes. Programmers can create functions, which are in many ways similar to built-in functions. User-defined functions can have input and output parameters and work in the same way as regular functions. The fact that users can create functions means that users can shape the language with their own building blocks and add their own abstractions. While the power to make your own abstractions is now available in almost any language, many programmers today have never worked in prestructured programming systems like assembly, or some BASIC dialect where such abstraction mechanisms weren’t available.
Libraries and frameworks can also offer their users the option to create their own abstractions. For example, allowing a library user to create a subclass to which additional functionality can be added has more power of abstraction than a library that just allows API calls.
Visibility indicates how easy it is to see different parts of a system. In a codebase, it can be hard to see what classes the codebase consists of, especially if code is divided over different files.
Libraries or frameworks can also offer their users different levels of visibility. For example, an API that fetches data might return a string, a JSON file, or an object, which each have a different visibility. If a string is returned, it is harder to see the form of the data, and the framework offers the user lower visibility.
We have looked at different dimensions that programs can have. These differences can greatly impact how people interact with a codebase. For example, if a codebase has a high viscosity, future developers working on the codebase might be reluctant to make changes. This can lead to more complicated patches rather than deep changes to the codebase structure. If an open source codebase requires hard mental operations, people might be less likely to become maintainers. Therefore, it is important to gain a sense of how your codebase is performing on the different dimensions.
The list of cognitive dimensions can be used as a sort of a checklist for a codebase. Not all dimensions matter for all codebases, but regularly investigating each one and deciding how your codebase is doing will help you maintain useability. Ideally you analyze the dimensions of a codebase on a regular basis (for example, once a year).
EXERCISE 12.3 Fill out the following table to gain an understanding of the dimensions at play. What dimensions matter to your codebase? Which of those can be improved?
Making changes to a codebase to improve a certain dimension in a codebase is called a design maneuver. For example, adding types to a codebase is a design maneuver that improves error proneness, and changing function names to be more in line with the domain of the code is a design maneuver that improves closeness of mapping.
EXERCISE 12.4 Examine the list you created in exercise 12.3 for the dimensions that could be improved. Do you see design maneuvers you could apply? What would the effect of those maneuvers be on other dimensions?
Often a design maneuver (that is, a change to one dimension) causes changes to another dimension. How the dimensions interact precisely can depend heavily on your codebase, but there are a few dimensions that are often at odds with each other.
If you want to prevent the user of your library or framework from making errors, you will often do that by making the user enter additional information. The most well-known example of a dimension that decreases error proneness is allowing a user to add types to entities. If the compiler knows the type of an entity, that information can be used to prevent mistakes, such as accidentally adding a list to a string.
However, when everything in a system is typed, this might present the user with extra work. For example, you might need to cast variables to a different type to be allowed to use them in the way you want. When people dislike type systems, even in light of their benefit in preventing types, that is often because of the extra viscosity a type system adds.
Provisionality and progressive evaluation vs. error-proneness
A system with a lot of provisionality and progressive evaluation allows the user to sketch out and execute incomplete or imperfect code. While those dimensions might help someone think about the problem at hand, incomplete programs might not be deleted, and imperfect programs might never be improved, leading to code that is hard to understand and thus hard to debug, impacting error-proneness.
Role expressiveness vs. diffuseness
We have seen that role expressiveness can be created by adding additional syntactic elements such as names parameters. However, the extra labels cause the code to be longer. The same is true for type annotations, which also express the roles that variables play, but increase a codebase’s size.
In the previous chapter, we discussed five different programming activities: searching, comprehension, transcription, incrementation, and exploration. Each activity places different constraints on the cognitive dimensions a codebase needs to optimize for. The relationship between dimensions and activities is shown in table 12.1.
In chapter 11, we described five different activities people do when they program. In fact, these activities also stem from the original version of the CDN framework. Blackwell, Petre, and Green described these activities because the different activities interact with the dimensions. Some activities require a certain dimension to be high, while others work best if a dimension is low, as shown in table 12.1.
When searching, some dimensions play an important role. For example, hidden dependencies can harm the activity of searching, because if you do not know what code is called from where, it can be hard to decide what to read next and thus slow down the search. Diffuseness causes code to be longer, which also harms search simply because there is more code to search through.
On the other hand, secondary notation can help searching because comments and variable names can indicate where information can be found.
Some dimensions are especially important when comprehending code. For example, low visibility in a codebase can harm comprehension because it makes it harder to see, and thus understand, how classes and function relate to each other.
Role expressiveness, on the other hand, can help comprehension. If the type and role of variables and other entities is clear, comprehension can be easier.
When transcribing (that is, implementing a feature based on a predefined plan) some dimensions that are otherwise good can be harmful—for example, consistency. While a consistent codebase can be easier to comprehend, you will have to make the new code fit into the codebase when implementing a new feature, which can lead to extra mental effort. Of course, that effort might be worth it in the long run, but it is still effort that needs to be spent.
Adding new features to a codebase is mostly supported by closeness of mapping to the domain. If the codebase enables thinking about the code’s goal, rather than about programming concepts, it will be easier to add new code. Codebases with high viscosity, on the other hand, makes adding code harder.
Exploring new design ideas while in the codebase (i.e., exploring) is supported most by systems that have good provisionality and progressive evaluation.
Hard mental operations and abstractions can harm exploration because they place a high cognitive load on the programmer, limiting the load that can be spent on exploring the problem and solution space.
Table 12.1 Overview of dimensions and the activities that they support or harm
We have seen that different activities place different constraints on a system. Therefore, you must understand the most likely actions people will perform in your codebase. Relatively old and stable libraries are more likely to be searched through than incremented ones, while new apps are more likely to be incremented and transcribed. This means that over the lifetime of a codebase, design maneuvers might be needed to make the codebase more in line with most likely activities.
EXERCISE 12.5 Think of your codebase. What activities are most likely to occur? Have the activities been stable over the past few months? What dimensions play a role is these activities, and how does your codebase perform on these dimensions?
CDN is a framework that helps programmers predict the cognitive effect programming languages will have on their users.
CDCB is an extension of CDN that helps programmers understand the impact their codebases, libraries, and frameworks will have on their users.
In many cases, trade-offs between different dimensions must be made. Improving one dimension might decrease another dimension.
Improving the design of existing codebases according to the notations framework’s cognitive dimension can be done with a design maneuver.
Different activities place different demands on the dimensions a codebase optimizes for.