In the last few chapters, we covered techniques for thinking about code, such as creating visualizations, using frameworks to support the working memory, and using mental models to help solve code problems. No matter how helpful the techniques are that we use to support our brains, we will sometimes make mistakes in thinking about code.
The focus of this chapter is bugs. Sometimes bugs are the result of sloppiness, for example, when you forget to close a file or make a typo in a filename. More often, though, bugs are the result of a mistake in thinking. You might not know that a file needs to be closed after use, or you might assume that the programming language closes the file for you automatically.
In this chapter, we will first explore the topic of learning multiple programming languages. There are many possible sources of erroneous assumptions when you learn a new language, one being that different programming languages have different conventions for various concepts. Python, for example, will close a file after a block starting with open () without requiring an explicit file.close () statement, but in C you always have to use (). In the first part of this chapter, I’ll show you how to best use your existing knowledge to learn new programming languages, as well as how to avoid frustrations and errors resulting from differences between languages.
The second part of the chapter teaches you about erroneous assumptions about code. We’ll cover various programming-specific misconceptions, and we will dive into the origins of misconceptions. Being aware of what misconceptions you may hold about code will help you catch errors earlier and even prevent some.
In the previous chapters, you learned that keywords and mental models stored in your LTM can help you comprehend code. Sometimes when you’ve learned something, that knowledge is also useful in another domain. This is called transfer. Transfer happens when information you already know helps you do new things. For example, if you already know how to play checkers, it will be easier to learn chess because some of the rules are similar. Likewise, if you already know Java, learning Python is easier because you already know the basic programming concepts, such as variables, loops, classes, and methods. Also, some of the skills you picked up while programming, such as using a debugger or a profiler, might come in handy when you’re learning the second programming language.
There are two ways programming knowledge stored in your LTM can support learning new programming concepts. First, if you already know a lot about programming (or any other subject), learning more about it is easier. Information stored in your LTM helps you learn new things; this is known as transfer during learning.
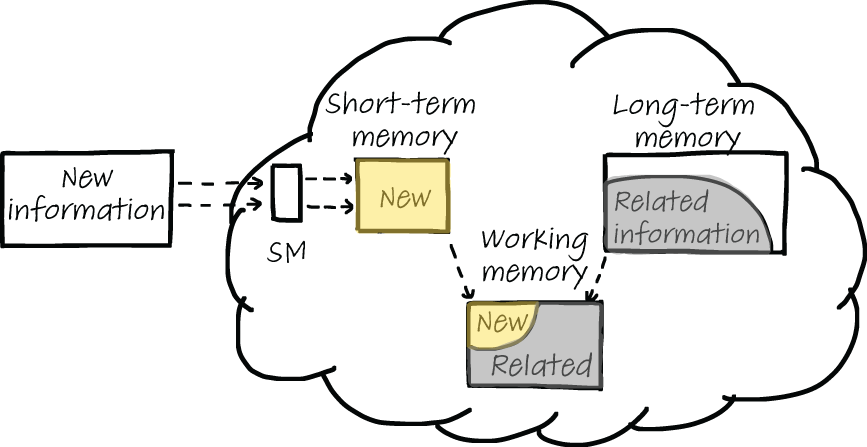
You learned in chapter 2 that when you encounter new information, it travels from the sensory memory to the STM, and it enters the working memory when it is being processed. This process is illustrated in figure 7.1. When you activate your working memory by thinking about a new programming concept, the LTM is also activated and starts a search for relevant information.
As shown in figure 7.1, when your LTM is searched, information related to the newly learned information might be found. If information exists that is related to the new information, it’s relayed to the working memory. This information might include procedural memories, schemas, plans, or episodic memories.
Figure 7.1 When you learn new information, it is processed first by the sensory memory (SM) and then by the STM. The new information is subsequently sent to the working memory, where you can think about it. At the same time, the LTM is searched for related information. If related information is found, it too is sent to the working memory to support thinking about the new information.
For example, when you already know Java and are learning about methods in Python, you might be reminded of methods in Java. That will help you to learn the Python methods more quickly even though they work a bit differently than methods in Java.
In chapter 3, we talked about the use of elaboration when learning a new concept. Elaboration is the practice of explicitly relating new information to things you already know. The reason elaboration works well is that explicitly searching your LTM for related information increases the chances of relevant information being found that can help you perform the task at hand. Therefore, elaboration can help increase transfer during learning.
EXERCISE 7.1 Think of a new programming concept or library you learned recently. What concepts that you already knew helped you learn the new concept?
The second way knowledge stored in your LTM can support learning is called transfer of learning. Transfer of learning happens when you can apply things you already know in entirely unfamiliar situations. When people are talking about cognitive science and use the term “transfer,” they almost always mean transfer of learning.
Sometimes transfer of learning happens without you thinking about it at all. For example, when you buy a new pair of pants, you don’t have to think about how to close its button. You just know how to do it, even though these particular pants and its button are unfamiliar to you. Similarly, when you buy a new laptop, you know how its keyboard works without thinking about it, even if you have never operated this specific type of laptop before. Transfer of learning can also happen consciously, like when you learn a new programming language. If you are learning JavaScript and already know Python, you might explicitly think, “I know I need to indent the body of a loop in Python; would that be true for JavaScript too?”
Transfer of learning is similar to transfer during learning because in both situations the brain searches the LTM looking for relevant strategies to apply.
As a professional programmer, I am sure you have been in situations where knowledge could have transferred but didn’t. Maybe you were confused about how some function in a certain library worked, and it later turned out to be exactly the same as in a library you already knew. Sadly, not all knowledge that is useful will automatically transfer to new situations.
The amount of learning you can transfer from one task to another can vary widely and is influenced by many factors. Factors that can influence how much transfer takes place include the following:
Mastery—How well you’ve mastered the task for which knowledge is already stored in your LTM. The better you know a task, the more likely it is you’ll be able to apply it in another domain. For example, an expert Java programmer will likely benefit more from their prior knowledge when learning Python than a novice Java programmer. As we’ve seen in previous chapters, an expert programmer has a larger arsenal of strategies, chunks, and mental models that can be applied to problems in any different programming language.
Similarity—Commonalities between the two tasks. For example, if you are implementing an algorithm you already know in an unfamiliar programming language, that will be easier than implementing a new algorithm in a new programming language.
Context—How similar the environments are. It’s not only the similarity between the tasks that matters, but also the context in which you are executing them. For example, transfer between two programming languages is more likely if you program those different languages in the same IDE, which is a strong argument for using one IDE for multiple languages. Context extends beyond the computer, though; it can also matter whether you are sitting in the same office with the same people. The more similarities there are, the more likely it is that knowledge will transfer.
Critical attributes—How clear it is to you what knowledge may be beneficial. If someone points out that knowing JavaScript might be beneficial in learning Python, you will be more likely to actively look for similarities. It can therefore be important to actively search for commonalities and to reflect on them before learning a new programming language or framework. What existing knowledge could help with the new task?
Association—How strongly you feel that the tasks are similar. For example, Java and JavaScript sound similar, even though conceptually the languages are not all that alike. Therefore, a stronger association might exist in your LTM between Java and JavaScript than between Python and Scala. Your episodic memory, which stores memories of things you have experienced, can also play a role. For example, if you learned Java and C# in the same lecture hall, you might connect them more strongly than if you’d learned them in different settings.
Emotions—How you feel about the task. Your emotions can also play a role in the likeliness of transfer. For example, if you find working with binary trees pleasurable and a new task reminds you of it, you might try to apply similar strategies to the new task more actively.
There are several different ways we can look at transfer. If you have a vocabulary for the different forms of transfer, you can set more realistic expectations of transfer between programming languages. Programmers sometimes assume that the syntax of programming languages is irrelevant and that if you know one language, you can pick up a second one with ease, and a third one with no effort at all. Certainly, knowing one language can make learning a new one easier, but it doesn’t always help. Understanding different forms of transfer will prepare you to learn a new language or framework more effectively.
Transfer of automatized skills is different from transfer of skills you mastered consciously. Transfer of automatized skills is called low-road transfer. In programming, low-road transfer might occur if you use Ctrl-C and Ctrl-V in a new editor without thinking about it. Transfer of more complex tasks is called high-road transfer. When high-road transfer occurs, you are often aware that it is happening. For example, you might assume that you need to declare a variable in a new programming language because you know that is the case in most languages.
Earlier, you learned that if two domains are more similar, that impacts the amount of transfer. Looking at the distance between the domains is another way we can divide different forms of transfer. Near transfer happens when knowledge transfers from domains that are seen as close to each other, like calculus and algebra or C# and Java. We speak of far transfer when skills transfer between very different domains, like Latin and logic, or Java and Prolog. Because similarity is a factor that influences transfer, far transfer is far less likely to happen than near transfer.
Exercise 7.2 Think of a few situations in which you experienced transfer. What form of transfer occurred? Fill in the following table to guide your thinking.
In addition to high- and low-road and near and far transfer, there are two more main categories of transfer. The type of transfer we’ve been looking at so far, where knowing something supports learning a new thing or performing a new task, is called positive transfer.
When positive transfer occurs, you don’t have to create a fresh, new mental model from scratch; instead, your brain gets help in constructing a mental model of a new situation by basing it on mental models the LTM already holds for other domains. For example, when you know Java, you already have a mental model of a loop and know that a loop has a counter variable, a body, and a stop condition. In almost any new programming language you encounter, loops will also have these aspects, so you know what to look for. This helps you create a new mental model. However, as you might have experienced, transfer is not always positive. When existing knowledge prevents you from learning something new, we call this negative transfer. Edsger W. Dijkstra, Dutch computer science professor and creator of Dijkstra’s algorithm, famously said that teaching BASIC should be forbidden because “it cripples the mind.”
While I do not believe at all that brains can be ruined forever by learning a certain programming language, there is some truth in this saying because mistakes can be caused by wrong assumptions about code. Wrong assumptions can in turn be caused by negative transfer. For example, in Java, variables cannot be used without initialization. An experienced Java programmer might assume that in Python too, all variables must be initialized and that the compiler will warn them if they forget. This can cause confusion and lead to bugs.
Even in very similar languages, like Java and C#, there are risks of negative transfer because the mental models of both languages are similar but not identical. For example, Java has a concept called checked exceptions, which are exceptions checked at compile time. If you don’t wrap these exceptions in a try-catch block, the code will fail to compile. Checked exceptions are a Java-specific language feature, so people coming from C# might not realize they are different from what they are used to. Not only do they have the wrong mental model, but they think they have the right one!
Forgetting to initialize a variable or mishandling an exception are relatively small errors that can be easily fixed. But there are examples of negative transfer that run deeper. For example, many people have a hard time learning a functional language like F# when they are already familiar with object-oriented languages because functions exist in both paradigms but work differently.
EXERCISE 7.3 Think of a situation where you made an incorrect assumption about a language concept in a programming language. Could that be attributed to negative transfer from one language to another?
In the previous section you saw that transfer of knowledge can be both negative and positive and that positive transfer is not a given. Situations need to be similar enough to each other to make transfer more likely. Far transfer, in which knowledge from one domain “hops over” to a domain that is not very similar to the original domain, is unlikely to happen spontaneously.
Sadly, research shows that transfer indeed is hard and does not come automatically to most people. Chess is often named as a candidate source for transfer—many people believe that chess knowledge will improve general intelligence as well as logical reasoning skills and memory. However, scientific studies have not been able to support these assumptions. In chapter 2 we discussed the work of Adriaan de Groot, whose experiments showed that the memory of experienced chess players was no better than that of novices when the setups were random. Other studies have confirmed this and shown that proficient chess players are not necessarily any better at remembering numbers or visual shapes. Chess skills don’t appear to transfer to other logical games either, like the Tower of London (a puzzle similar to Towers of Hanoi).
What is true for chess seems to be true for programming too. Many programmers argue that by learning to program you will gain skills in logical reasoning, or even increase your general intelligence. However, the small number of studies that have researched the cognitive effects of programming show a pattern similar to that found with chess. An overview study done in 1987 by Gavriel Salomon of the University of Tel Aviv revealed that most studies of the impact of programming education show little effect. Many of the studies examined by Salomon do show that children are successful in acquiring certain programming skills, but those skills do not appear to transfer to other cognitive domains.
The takeaway here is that the fact that you’ve already mastered one programming language will not always help you learn a new one. This might be frustrating because you already see yourself as an expert, and the slow pace of a beginner and corresponding learning activities, like using flashcards to learn syntax, might feel unnecessary. A related piece of advice to consider is that if you set out to learn a new language to expand your way of thinking, it’s important to pick a language that is fundamentally different from the ones you’ve already mastered—that is, you should avoid a false broadening of your tastes from “country music” to “Western music.”
However, this section has shown that far transfer, say, from something like SQL to JavaScript, is not all that likely, and that you will probably need to learn a lot of new syntax as well as new strategies to regain your expert level in a new programming language. Practices might differ too; for example, much of what you know about reuse and abstraction in JavaScript has to be considered rather differently in SQL.
Paying deliberate attention to similarities and differences will ease the task of learning a new language.
EXERCISE 7.4 Consider a programming language you are learning or one you want to learn. Compare it to language(s) you already know. What is similar and what is different?
Filling out the following table can help streamline your thinking and show where you can expect transfer and where you will need to pay specific attention while learning.
In the first part of this chapter, we focused on how knowledge transfers from one situation to another. When stored information interferes with us performing a new task, we call this negative transfer. In this section, we’ll explore the consequences of negative transfer.
Think about a situation in which you created a bug, for example by forgetting to initialize an instance in the right way, by calling the wrong function, or with an off-by-one error in a list. Situations where bugs occur can be caused by a simple slip of the mind where you accidentally forgot some code, selected the wrong method, or made a mistake in calculating a boundary value.
However, bugs can also have a deeper underlying reason, where you made a faulty assumption about the code at hand. Maybe you counted on the fact that the instance would be initialized elsewhere in the code, or maybe you were sure this was the right method or assumed that data structure would prevent you from accessing elements out of its bounds. When you are sure your code will work, but it still fails, chances are that you are suffering from a misconception.
In regular conversation, the word “misconception” is often used as a synonym for a mistake or for being confused, but the formal definition is slightly different. For a belief to be a misconception, it must
There are many common misconceptions. For example, many people think that the seeds of chili peppers are the spiciest part. The seeds of chilies are not spicy at all! This is an example of a misconception because
If people believe the seeds of one kind of chili are spicy, they will believe the seeds of all kinds of chilies are spicy, and
They believe it to be true and act on it, for example by removing the seeds of chili peppers before cooking them.
The “seeds of chilies are spicy” misconception is the result of an urban legend people have simply repeated to each other, but negative transfer often plays a role in the creation of misconceptions. For example, many people believe that searing meat will “seal in the juices” because the outer surfaces of other forms of food, like eggs, solidify when heated. These people assume that heat always creates a solid “shield,” which will be impenetrable by the moisture trapped inside. Knowledge from one type of food is incorrectly transferred to another type of food, leading to a misconception—in fact, searing meat leads to a greater net loss of moisture.
Misconceptions commonly occur in programming too. New programmers sometimes assume that a variable, like temperature, can only hold one value that cannot be changed. While that assumption might sound absurd to an experienced programmer, there are reasons why assuming that a variable can only hold one value is sensible. For example, this assumption might be transferred from prior knowledge of mathematics, where variables indeed do not change within the scope of a mathematical proof or exercise.
Another source of this misconception lies within the realm of programming itself. I have seen students with prior exposure to files and filesystems incorrectly transfer beliefs about files to variables. Because operating systems typically allow you to only create one file with a certain name (in a folder), students might incorrectly assume that the variable temperature is already in use and cannot hold a second value, just like a file name can only be used for one file.
Misconceptions are faulty ways of thinking held with great confidence. Because misconceptions are held with such high confidence, it can be hard to change someone’s mind about them. Often, it is not enough to point out the flaw in their thinking. Instead, to change a misconception, the faulty way of thinking needs to be replaced with a new way of thinking. That is, it’s not enough to tell a novice programmer that a variable can be changed; they need to get a new understanding of the variable as a concept.
The process of replacing a misconception based on a programming language you already know with the right mental model for the new language you are learning is called conceptual change. In this paradigm, an existing conception is fundamentally changed, replaced, or assimilated by the new knowledge. It is this change in knowledge, rather than the addition of new knowledge to an already existing schema, that distinguishes conceptual change from other types of learning.
The fact that knowledge you have already learned needs to be changed in your LTM makes conceptual change learning harder than regular learning. That is why misconceptions can linger for a very long time; simply being presented with information on why your thinking is wrong often does not help or does not help enough.
Therefore, you will have to spend a lot of energy when you learn a new programming language “unlearning” existing knowledge about prior programming languages. For example, if you’re learning Python when you already know Java, you will have to unlearn some syntax, like that you must always define the types of variables. You’ll also have to unlearn some practices, like relying on the types of variables to make decisions in code. Even though it is not hard to remember the simple fact that Python is dynamically typed, learning to think about types while you are programming might take longer because it requires conceptual change.
Remember when we considered dressing a snowman in a sweater and I asked you to decide if the snowman would melt faster or slower than when he is “naked?” Your first thought likely was that he would melt quicker—after all, putting on a sweater makes one warmer, right? Well, not for a snowman. When wearing a sweater, the snowman is insulated, trapping in the cold and slowing the melting process.
What likely happened is that your brain instantly activated an existing conception: sweaters make you warmer. This conception, which is correct in (warm-blooded) people, was then wrongly transferred to the situation of the snowman. This is not because you are not a smart person!
It was long assumed that when people learn how things work, old, incorrect notions are deleted from their memories for good and replaced by better, more correct notions. Knowing what we know about the brain, that is unlikely. Memories are now assumed not to be forgotten or replaced; rather, our retrieval of them lessens over time. However, the old memories of wrong ways of thinking are still there, and paths to them might be triggered, even if we would prefer that they weren’t.
Research has shown that people often fall back on old notions, even if they can also successfully work with the correct ones. The work of Igal Galili and Varda Bar of the Hebrew University of Jerusalem showed that students could work well with mechanics in familiar exercises but regressed to more basic but wrong reasoning for more complicated questions.1 This illustrates that multiple notions can be present in the memory at the same time, like in the snowman example: we can have the idea that a sweater means warmth in our brains, as well as the notion that a sweater insulates and thus keeps in the cold. These ideas compete with each other when we have to decide whether a sweater makes a snowman warm, so we have to actively suppress the older idea that sweater equals warmth to come to the right conclusion. That likely happened when you thought about the puzzle and you experienced a “wait a minute” moment when you reasoned rather than reacted intuitively.
We do not know exactly how the brain decides which of the stored concepts to use, but we know that inhibition plays a role. We typically associate inhibition with a feeling of self-consciousness, holding back, or feeling shy. However, recent research has started to indicate that when inhibitory control mechanisms are active, an incorrect conception can lose the competition with a correct conception.
EXERCISE 7.5 Think of a situation where you were you held a misconception about a concept in a particular programming language. For example, I assumed for an embarrassingly long time that all functional languages used lazy evaluation and that all lazy languages must be functional because I only knew one language that was lazy and functional: Haskell. What misconception did you hold for a long time, and what was its origin?
Extensive research has been done into misconceptions in the domain of programming, especially the misconceptions that novice programmers hold. Juha Sorva, now a senior university lecturer at Aalto University in Finland, wrote a PhD dissertation in 2012 that contains a list of 162 different misconceptions novices can hold.2 All these misconceptions are rooted in research. While the full list is very interesting, and I recommend reading it, some of the misconceptions in Sorva’s thesis are especially worth noting:
Misconception 15: Primitive assignment stores equations or unresolved expressions. This misconception indicates that sometimes people assume variable assignments store relationships. A person who suffers from this misconception assumes that if we write total = maximum + 12 it somehow links the value of total with the value of maximum.
That leads to the belief that were maximum to be changed later in the code, total would change along with it. The interesting thing about this misconception is that it is very sensible. You can imagine a programming language in which the relationships between variables could be expressed like a system of equations. There are even programming languages that work this way to a certain extent, such as Prolog.
This misconception often occurs in people with prior mathematical knowledge. A related misconception we covered earlier in the chapter is the idea that a variable can only hold one value. This is true in mathematics too.
Misconception 33: While loops terminate as soon as condition changes to false. This misconception expresses confusion about when the stop condition of a while loop is evaluated. When suffering from this misconception, people assume the loop condition is checked at each line and that it stops immediately when the condition is false and does not finish executing. This misconception is likely to have a relationship with the meaning assigned to the keyword while . When we hear someone say, “I will sit here and read my book while it is raining,” we assume the speaker of this sentence regularly monitors the weather, leaves when it stops raining, and does not first finish the whole book. Here, too, the misconception is not a sign of a person being utterly confused and having no concept of how programming works. It’s quite a reasonable assumption to think that code so similar to English would behave similarly.
This misconception is an example of where the meaning of English (key)words interfere with programming understanding. Also, you could again imagine a programming language in which the stop condition of a while loop is evaluated continuously and the loop halts immediately when the condition becomes false.
A related misconception is assuming that the name of the variable influences what value it can hold—for example, thinking that a variable called minimum can never hold a large value (this is misconception 17 on Sorva’s list).
Misconception 46: Parameter passing requires different variable names in call and signature. People with this misconception tend to assume that a variable name can only be used once, including inside functions. When you are learning to program, you learn that variable names can only be used once. If a new variable is needed, you need to define a new name too. The limitation on one use of variables, however, is no longer true when we talk about methods or functions and their invocations. Suddenly, it is allowed to use the same name both inside a function and outside of it. In fact, it’s more than allowed; using the same names for different variables in and outside of functions is common practice. This is often shown in introductory examples of functions. For example, code like this is quite common when teaching functions:
def square(number): return number * number number = 12 print(square(number))
Such code also occurs in real life. For example, when you use the extract method functionality in an IDE, most IDEs will replicate the variable name both in defining and calling the function. Hence, real code is filled with this pattern too, which might be why educators use it. This misconception is an interesting example of a misconception that transfers within a programming language rather than being influenced by prior knowledge of math or English. Sometimes when we understand a specific concept of a programming language, the knowledge we acquire about that part does not transfer even to other concepts within the same language.
There’s not a lot we can do about misconceptions. When learning a new programming language or system, inevitably you will be confronted with negative transfer. However, there are some strategies that can be helpful.
First, it is important to be aware that even if you’re sure you’ve gotten something right, you could still be wrong. Keeping an open mind is key.
Second, you can deliberately study common misconceptions to prevent yourself from falling prey to them. It can be hard to know when you are making erroneous assumptions and what assumptions are valid. Therefore, it can be helpful to use a checklist of common misconceptions. Exercise 7.5 can help you get a first sense of potential areas where you might hold misconceptions, and Sorva’s list can be used when learning a new programming language as a guideline for determining what misconceptions you should watch out for. Use the list to identify misconceptions that could apply to the programming language you are learning.
A final tip is to ask the advice of programmers who also learned the same programming languages in the same order. Every pair of programming languages has its own interactions that can create misconceptions, so there are too many to list here. Asking for advice from people who might have encountered the same traps can be tremendously helpful.
In this section, we have talked mainly about misconceptions in programming languages in general, which can be caused by prior knowledge that negatively transfers to a new programming language.
Similarly, you can have misconceptions about the codebase you are working on. Whenever you make assumptions about code based on prior experience with a programming language, framework, or library, or about the domain of the code, the meanings of variable or other names, or the intentions of other programmers, there is a risk of misconception.
One way to detect misconceptions is to program in pairs or in a larger group. If you expose yourself to the ideas and assumptions of others, it will soon be clear that there are conflicts and that one person has a misconception.
Especially for expert programmers (or experts in anything), it can be hard to realize that the error is yours, so always verify assumptions you make about code by running it or making use of a test suite. If you are sure a certain value can never be below zero, why not add a test to verify it? That test can not only help you detect whether your assumption is wrong, but also serves as documentation of the fact that the value indeed will always be positive. The test can communicate this information to you in the future, which is important because, as we’ve seen, misconceptions rarely go away and can always resurface, even when we have learned the correct model.
As this suggests, documentation is a third way of battling misconceptions about a certain method, function, or data structure within a codebase. If you’ve discovered a misconception, in addition to adding a test, you might also want to add documentation in relevant places to prevent yourself and other people from falling into the same trap.
Knowledge you already have stored in your LTM can be transferred to new situations. Sometimes existing knowledge helps you learn faster or perform new tasks better. This is called positive transfer.
Transfer of knowledge from one domain to another can also be negative, which happens when existing knowledge interferes with learning new things or executing new tasks.
You can use positive transfer to learn new things more effectively by actively searching for related information in your LTM (for example, by elaboration, as covered earlier in the book).
You may hold misconceptions, which occur when you are sure you are right but are actually wrong.
Misconceptions are not always addressed by simply realizing or being told you are wrong. For misconceptions to be fixed, you need a new mental model to replace the old, wrong model.
Even if you have learned a correct model, there is always the risk you will fall back to using the misconception.
Use tests and documentation within a codebase to help prevent misconceptions.
1. See “Motion Implies Force: Where to Expect Vestiges of the Misconception?” by Igal Gaili and Varda Bar, 1992, https://www.tandfonline.com/doi/abs/10.1080/0950069920140107.
2. See table A-1 (pp. 3593-68) of “Visual Program Simulation in Introductory Programming Education,” http://lib.tkk.fi/Diss/2012/isbn9789526046266/isbn9789526046266.pdf.