
In the previous chapters, you learned about different cognitive processes active in the brain when programming. We explored how information is stored briefly in the STM while reading code and how information is retrieved from the LTM when it needs to be applied. We also discussed the working memory, which is active when we think about code. Then, in chapter 5, we discussed strategies for deeply engaging with unfamiliar code.
The focus of this chapter is how we solve problems. As a professional programmer, you will often weigh different solutions to problems. Will you model all the customers of a company as a simple list or as a tree, organized by their default branch? Will you use an architecture based on microservices or should all the logic be in one place?
When you’re considering different solutions to problems, you’ll often find that different alternatives all have value. Deciding which solution to use can be hard because there are so many factors to take into account. For example, will you prioritize ease of use or performance? Will you consider potential changes you expect to the code in the future or will you just look at the current task?
This chapter presents two frameworks that can help you gain more insight into how to make decisions about different software designs. We will first study the mental representations that the brain creates while problem solving and programming. Being aware of the representations you use to think about code will enable you to solve more types of problems and to reason about code and solve problems more effectively. This chapter covers two techniques involving models that will help you strengthen your LTM and support your working memory to achieve these goals.
Second, we will look at how we think about computers when solving problems. When programming, we don’t always consider all aspects of the machines we’re working on. Sometimes we can abstract many of the details—for example, when you’re creating a user interface, most of the specifics of the operating system are not that relevant. However, when implementing a machine learning model or when creating a phone app, the specifications of the machine that the code will run on matter. The second framework that we will look at in this chapter helps you think about problems at the right level of abstraction.
When people solve problems, they almost always create models. Models are simplified representations of reality, and the main goal of a model is to support you in thinking about a problem and ultimately solving it. Models can have various shapes and levels of formality. A rough calculation on the back of a beer mat is a model, but an entity-relationship diagram of a software system is also a model.
In previous chapters, we created various types of models that supported thinking about code. For example, we created a state diagram to show the values of variables, as shown in figure 6.1. We also created a dependency graph, which is another kind of model of code.
Figure 6.1 A BASIC program that converts the number N into a binary representation. You can use a memory aid like the partial state table shown here to help you understand how the program works.
Using explicit models of code when you solve a problem has two benefits. First, models can help communicate information about programs to others. If I have created a state diagram, I can show someone else all the intermediate values of the variables to help them understand how the code works. This is especially helpful with larger systems. For example, if we look at an architectural diagram of code together, I can point out classes and the relationships between them and objects that would otherwise be invisible or hidden in code.
A second benefit of models is that they can help you solve problems. When you are close to the limit of items you can process at once, making a model can be a useful way to lower cognitive load. Just as a child might add 3+5 using a number line (a kind of model) rather than doing the calculation in their head, programmers might map out the architecture of a system on a whiteboard because it is too hard to hold all the elements of a large codebase in the working memory.
Models can be a big help in solving problems because they help the LTM identify relevant memories. Often models have constraints; for example, a state diagram only shows the values of variables and an entity relationship diagram only shows classes and their relationships. Focusing on a certain part of a problem can support your thinking about a solution, and these constraints force you to do just that. Thinking of the number line while adding helps to put the focus on the activity of counting, and an entity relationship diagram forces you to think about what entities or classes your system will consist of and how they relate to each other.
Not all models are equally helpful
Not all models that we can use to think about problems are equal, however. As programmers, we know the importance of representation and its effects on solving problems. For example, dividing a number by two is trivial when we have converted the number to a binary representation—we simply need to shift the bits right by one. While this is a relatively simple example, there are numerous problems where the representation influences the solution strategy.
The importance of representation can be nicely illustrated in more depth by the following problem concerning a bird and two trains. A bird is sitting on a train about to leave Cambridge, England, heading to London. Just as that train departs, a second train departs from London, 50 miles away. The bird takes off and flies toward the second train at a speed of 75 miles per hour. Both trains are traveling at 50 miles per hour. When the bird gets to the second train, it turns around and flies back toward the first one, and it keeps doing this until the two trains meet. How far has the bird flown when the trains meet?
Many people’s first intuition is to think of the trains and how the bird moves between them (figure 6.2).
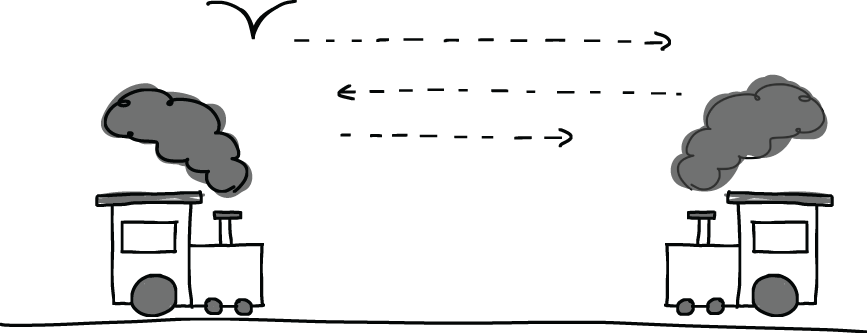
Figure 6.2 Modeling the distance a bird travels between two moving trains, from the view of the bird. This leads to a correct but very complex solution involving calculating the locations of both trains.
Modeling the trajectory of the bird is a correct solution, but it involves a complicated set of equations that most people would prefer to avoid. An easier solution focuses on the bird itself and goes as follows. The trains will meet in the middle between London and Cambridge after 30 minutes. At that point, both trains have traveled 25 miles. Since the bird flies at a speed of 75 miles per hour, after half an hour, the bird has flown 37.5 miles. This is a nice illustration of the fact that the way in which you think about a problem can heavily impact how you solve it and the effort it takes to do so.
In programming, we also work with different representations of problems. Some programming languages limit the number of possible representations, which can be both helpful and harmful in solving problems. For example, a language like APL is perfect for modeling solutions that involve matrices but can be hard to use for problems that need a different representation. Java, on the other hand, has the option of creating classes to represent all sorts of problems, so you can use Java for problems involving matrices, but you’ll need to do the extra work of creating a matrix class. In Java, it is more likely that you would reach for a solution involving two nested for-loops instead, because these are built in and commonly used.
So far we’ve worked with models that are explicitly created outside our brains. State tables, dependency graphs, and entity relationship diagrams are models that are constructed on paper or a whiteboard. You can choose to make such a model when you need to communicate with others or think more deeply about a problem. But there are also models you can use when thinking about a problem that are not made explicit outside of your brain. These are called mental models.
In the previous section you saw that the representation you use to solve a problem influences how you think about the problem. The same is true for mental models: some support thinking better than others. In this section we’ll explore what mental models are and how you can use them explicitly when solving problems.
An example of a mental model we use for code is thinking about traversing a tree. In the code and the computer, of course, there isn’t a real tree that we traverse; there are just values in memory that we think of as a tree structure. This model helps us reason about the code. It is easier to think about “the children of that node” than it is to think about “the elements that that element refers to.”
Mental models were initially described by Scottish philosopher Kenneth Craik in his 1943 book The Nature of Explanation. Craik described mental models as mental “scale models” of phenomena in nature. According to Craik, people use mental models to predict, reason about, and explain the world around them.
The definition of a mental model that I like best is this one: a mental model creates an abstraction in your working memory that you can use to reason about the problem at hand.
While interacting with computers, we create many types of mental models. For example, when thinking of a filesystem, you might think of a group of files in a folder together. Of course, when you think about it a bit more deeply, you know that there are not really files or folders on your hard drive; a hard drive only contains zeros and ones. But when we think about those zeros and ones, we think of them as being organized into those structures.
We also use mental models when thinking about code. An example of a mental model we use when thinking about programming is the idea that a specific line of code is being executed. Even for compiled languages that is the way we reason about programs, while of course what’s executed is not the line of Java or C itself, but the generated bytecode corresponding to that line. Even though the execution of lines of code is not a correct or complete representation of how program execution works, it can be a helpful model to use when reasoning about programs.
Models can also fail us, though—for example, when you step through highly optimized code in a debugger and find that the compiler’s optimizer transformed the code underneath enough that the debugger moves in ways that seem unrelated to how you think the source code will be executed.
EXERCISE 6.1 Consider a piece of code you used in the last few days. What mental models of that code did you use while programming? Did those mental models concern the computer or code execution or other aspects of programming?
Mental models share an important characteristic with models expressed outside the brain: the model adequately represents the problem but is simpler and more abstract than reality. Mental models also have other important characteristics, which are outlined in table 6.1.
Table 6.1 Key characteristics of mental models, paired with examples in programming
|
Mental models are incomplete. A mental model does not have to be a complete model of the target system, much like a scale model simplifies the physical object it models in some ways. An incomplete mental model can be useful for its holder if it abstracts the irrelevant details. |
Thinking of a variable as a box that holds a value does not adequately support thinking about reassignment. Will the second value fit in the box with the first value? Or will the first value be pushed out? |
|
Mental models are unstable. Mental models do not have to stay the same forever; in fact, they very often change over the period that they are in use. For example, if you create a mental model of electricity as the flow of water, you might picture it as a straight river initially, but as a widening and narrowing river when you learn more about how electricity flows. Holders of a mental model might also forget parts of the model when they do not engage with it enough. |
When we learn to program, thinking of a variable like a box that holds a value is helpful. However, after a while, we realize that a variable cannot hold more than one value, so a name tag becomes a better analogy. |
|
Multiple mental models can coexist, even if they are inconsistent with each other. Novices in particular often have “locally coherent but globally inconsistent” mental models, which tend to be closely tied to the details of the particular case they’re considering.1 |
You can think of a variable like a box holding a value. Alternatively, you might think of a variable like a name tag you attach to a value. Both mental models can exist at the same time and might have benefits in different situations. |
|
Mental models can be “weird” and even feel like superstitions. Often people believe things that do not really make sense. |
Have you ever asked a computer to do something, like “Please work this time?” Even though you know a computer is not a sentient being and cannot listen to you, you might still hold a mental model of a computer as an entity that can decide to act in your favor. |
|
People are frugal when using mental models. Because the brain consumes lots of energy, people will typically prefer to do extra physical work if that saves mental effort. |
For example, when debugging, many programmers prefer to make small changes to their code (tweaks) and run it again to see if the bug is fixed rather than spending the energy to create a good mental model of the problem. |
As is shown in table 6.1, people can hold different, competing mental models in their minds at the same time. You can superficially think of a file as being “in” a folder, while also knowing that, in fact, a file is a reference to a location on the hard drive where information is stored.
When learning to program, people often learn new mental models gradually. For example, initially you might think of a document on the hard drive as an actual physical sheet of paper with words on it that’s stored somewhere, while later you learn that the hard drive can only store zeros and ones. Or you might first think of a variable and its value as a name and telephone number in an address book, then update that model when you learn more about how the computer’s memory works. You might think that when you learn how something works in more depth, the old, “wrong” mental model is removed from your brain and replaced by a better one. However, in previous chapters we have seen that it is not likely that that information disappears completely from the LTM. That means there is always a risk that you will fall back on incorrect or incomplete mental models you learned previously. Multiple mental models can remain active simultaneously, and the boundaries between the models are not always clear. So, especially in a situation of high cognitive load, you might suddenly use an old model.
As an example of competing mental models, consider this riddle: What happens to a snowman if you dress it in a nice, warm sweater? Will it melt faster or slower than it would without a sweater?
Your first thought might be that the snowman will melt faster, since your brain immediately fetches the mental model of a sweater being a thing that provides warmth. But upon further consideration, you will conclude that a sweater does not give warmth but rather helps keep our body warmth in. Because the sweater insulates, it will keep the cold that the snowman loses in, so the snowman will actually melt slower, not faster.
Similarly, you might fall back on simple mental models when reading complex code. For example, when reading code that heavily uses pointers, you might confuse values and memory addresses, mixing mental models of variables and pointers. Or, when debugging complex code making use of asynchronous calls, you might use an old, incomplete mental model of synchronous code.
EXERCISE 6.2 Think of two mental models that you know for a single programming concept, such as variables, loops, file storage, or memory management. What are the similarities and differences between the two mental models?
In previous chapters, we discussed different cognitive processes in the brain. We talked about the LTM, where not only memories about life events but also abstract representations of knowledge, called schemata, are stored. We’ve also covered the working memory, which is where thinking happens.
You might wonder what cognitive process mental models are associated with. Are these models stored in the LTM and retrieved when needed? Or does the working memory form them when thinking about code? Understanding how mental models are processed is important because that knowledge can help us improve our use of these models. If they are mainly located in the LTM, we can train ourselves to remember them with flashcards, while if they are created in the working memory, we might want to use visualizations to support that cognitive process in its use of mental models.
Curiously enough, after Kenneth Craik’s initial book on mental models, the topic was not studied further for almost 40 years. Then, in 1983, two books, both called Mental Models, were published by different authors. The authors of these books held different views on how mental models are processed in the brain, as you’ll see in the following sections.
Mental models in working memory
The first book on mental models that came out in 1983 was by Philip Johnson-Laird, a professor of psychology at Princeton. Johnson-Laird argued that mental models are used while reasoning and thus live in the working memory. In his book, he describes a study where he and a colleague investigated the use of these models. Participants were given sets of sentences describing a table setting: for example, “The spoon is to the right of the fork” and “The plate is to the right of the knife.” After hearing the descriptions, the participants were asked to do some unrelated tasks. They were then given four descriptions of table settings and asked which of the descriptions was most similar to the one they had been given.
Of the descriptions participants were allowed to choose from, two were completely bogus, one was the real one they had heard, and one was a description that could be inferred from the layout. For example, from “The knife is to the left of the fork” and “The fork is to the left of the plate” one can infer that the plate is to the right of the knife without explicitly being told. Participants were then asked to rank the four descriptions, starting with the one best representing the description they’d been given.
They generally ranked both the real and the inferred descriptions higher than the two bogus ones, from which the researchers concluded that participants had made a model in their minds of the table setting, which they used to select the right answer.
What we can learn from Johnson-Laird’s work to improve thinking about programming is that having an abstract model of code is helpful: it allows you to reason about the model itself rather than relying on referring back to the code, which would be less efficient.
Later in this chapter we will explore how to deliberately create mental models when reasoning about code. But first we need to discuss one aspect of Johnson-Laird’s study we have not covered yet. His experiment had an interesting twist!
Participants received different types of descriptions. In some cases, the original descriptions they were given matched only one table setting. However, sometimes the original descriptions could match different realistic arrangements. For example, in figure 6.3 the statements “The fork is to the left of the spoon” and “The spoon is to the right of the fork” fit both table settings. On the other hand, the statement “The plate is between the spoon and the fork” only fits the left table setting in figure 6.3.
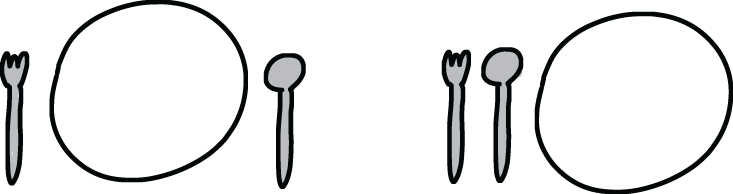
Figure 6.3 Example table settings that participants were asked to match with the provided descriptions. Here, “The fork is to the left of the spoon” fits both table settings.
When Johnson-Laird compared the performance of participants on both types of descriptions—determinate and indeterminate—he found that those who had been given determinate descriptions selected the correct answers more often than those who had been given descriptions that could match multiple table settings. The difference was large: 88% correct answers for the first group versus 58% for the second. These results indicate that creating a more concrete model of a situation strongly supports reasoning.
Bringing these results back to programming indicates that the more details a mental model has, the easier it is to reason about the system at hand and to answer questions about the system correctly.
Creating mental models of source code in the working memory
We have seen in this chapter that mental models, when they are correct and concrete, can support thinking about complex systems. That leads to the question of how to create such mental models. When code is simple, you might be able to create a mental model without a lot of effort. However, when code is more complex, or you have less knowledge about the codebase or the domain, creating an accurate mental model will take more work. It’s worth it, though, because that model can be a great asset.
Following these steps can help you form a mental model of complex code in your working memory:
Begin by creating local models.
In earlier chapters, you learned about using hand-drawn models to support your working memory, such as creating state tables and dependency graphs. While these methods are local, representing only a small part of a codebase, they can help you create a mental model of a larger piece of code too, in two ways. First, by supporting the working memory, these local models lower cognitive load, so you can focus on creating a larger mental model with more ease. Second, these smaller models can be the building blocks for a larger mental model. For example, a dependency graph can point to a few strongly connected lines of code that might play an important role in the formation of a mental model.
List all relevant objects in the codebase and the relationships between objects.
When forming a mental model of code, you want to be able to reason about elements in it. A mental model of a program that creates invoices, for example, might include the constraint that a person can have multiple invoices but an invoice just belongs to one person. To understand the interactions between the different elements in the code, first list the elements using a whiteboard or digital tool, then map out the relationships. This will help give you a clearer picture of the overall system.
Answer questions about the system and use the answers to refine your model.
You can now try to answer questions about the system you’re working with using the mental model you constructed in steps 1 and 2 and verify them in code. What the right questions are depends on the system at hand, but a few generic questions that often work are the following:
So far in this section we’ve talked about using mental models for reasoning, which Johnson-Laird described as situated in the working memory. However, there is a different view on mental models, which describes them as being stored in the LTM.
The second book on mental models that appeared in 1983 was written by Dedre Gentner and Albert Stevens, researchers at the R&D firm Bolt, Beranek, and Newman Inc. (BBN). Unlike Johnson-Laird, they argued that generic mental models are stored in the LTM and can be recalled when needed.
For example, a person might store a mental model of how liquids flow, which is used when pouring milk into a glass. Because the model is generic, people will know that when pouring pancake batter into a bowl, the liquid might behave a bit differently from milk, because it’s thicker, but will still fit the mental model of how liquid flows.
How does this apply to programming? In programming, you might store an abstract representation of how tree traversal works: there is a root at which you start, and then you can either explore breadth first, by looking at all the children of a given node, or depth first, where you choose one child and explore its children until you cannot proceed any further. When you encounter a program that works with trees, you can invoke the generic mental model of trees.
Gentner and Stevens’s description of mental models is somewhat similar to schemata in the LTM: mental models stored in the LTM help you organize data and can be used when you encounter new situations similar to ones you have seen before. For example, you can probably understand tree traversal in a programming language you have never seen before using your previously stored mental model.
Creating mental models of source code in the LTM
Thinking of mental models in this way would lead to a different way of improving your use of mental models. Rather than creating concrete instances of mental models when reading complex source code, Gentner and Steven’s view would indicate that to make better use of them you need to build up a larger vocabulary of potential mental models. In earlier chapters, you learned about ways of expanding the information stored in LTM too.
One way that we covered of expanding the knowledge stored in your LTM is the use of flashcards. The flashcards we discussed in chapter 3 had a programming concept on one side and corresponding code on the other. If you want to store more mental models to use when reasoning about code, you can also use flashcards. However, they will contain different information now. The goal of this second form of flashcards is not to extend your knowledge of syntactic concepts but to extend your vocabulary of mental models, or ways to think about code. Place the name of a mental model on one side of the card (the prompt) and a brief explanation or visualization of the mental model on the other side.
What mental models you will use to think about code partly depends on the domain, the programming language, and the architecture of the code. However, some things are generally worth using:
Data structures, such as directed and undirected graphs and different forms of lists
Diagrams, such as entity relationship diagrams or sequence diagrams
There are two ways you can use a set of flashcards of mental models. You can use them to test your knowledge, in the same way as the syntax flash cards: read a prompt and then verify that you know the corresponding explanation. As explained previously, whenever you encounter a pattern you are not familiar with, you can add a card to your deck of mental models.
A second way to use the deck is when reading code you are struggling with. Go through your deck of mental models and decide for each one whether it might apply to the code at hand.
For example, if you pick a card about trees, ask yourself, “Can I think of this code in the form of a tree?” If that pattern might apply, you can start to create an initial model based on this card. For a tree, that will mean deciding what nodes, leaves, and edges would be present in the model and what they might represent.
EXERCISE 6.3 Create an initial deck of flashcards with mental models that might be useful for code you are working on. Write the name of the mental model on one side as a prompt and an explanation of the model on the other side. Append the explanation with questions to ask when applying this mental model. For example, for a tree you will model nodes, leaves, and edges, so a starting question could be “What pieces of code can be represented as leaves?” Similarly, to use the mental model of a state table you will need to create a list of variables, so a starter question could be “What are the variables?”
You can do this exercise together as a team too and learn from each other’s models. Having a shared vocabulary of mental models can greatly ease communication about code.
Mental models live both in the LTM and in the working memory
Both views of mental models—that they are used in the working memory and that they are stored in LTM—are still commonly held. While the two competing opinions on mental models might seem contradictory, as we have seen in this chapter, both theories have their value, and in fact they complement each other nicely. In the 1990s studies showed that both are true to a certain extent: mental models stored in LTM can influence the construction of mental models in the working memory.2
In the previous section we discussed mental models, representations that we form in our brains when reasoning about problems. Mental models are generic and found in all domains. However, research on programming languages also uses the concept of a notional machine. While a mental model can be a model of anything in the world in general, a notional machine is a model we use when reasoning about how a computer executes code. To be more precise, a notional machine is an abstract representation of the computer we use to think about what it’s doing.
When attempting to understand how a program or programming language works, most of the time we are not interested in all the details about how the physical computer works. We don’t care about how bits are stored using electricity. Instead, we care about the effect of the programming language at a higher conceptual level, such as swapping two values or finding the largest element in a list. To indicate the difference between the real physical machine and what the machine does at a more abstract level, we use the term “notional machine.”
For example, a notional machine for Java or Python might include the concept of references but can omit memory addresses. Memory addresses can be considered an implementation detail you do not need to be aware of when programming in Java or Python.
A notional machine is a consistent and correct abstraction of the execution of a programming language, even though it might be incomplete, as we just saw. Notional machines, therefore, differ from a programmer’s mental models, which can be wrong or inconsistent.
The clearest way I have found to understand the difference between a notional machine and a mental model is that a notional machine is an explanation of how a computer works. When you have internalized the notional machine and can use it with ease, the notional machine becomes your mental model. The more you learn about a programming language, the closer your mental model gets to the notional machine.
The term is a bit cryptic, so before we look at examples of notional machines and how we use them in programming, I want to unpack the term itself. The first point to make is that a notional machine represents a machine, something that can be interacted with at will. That is an important difference from the mental models we form about, for example, physics or chemistry. While we can certainly use scientific experiments to build an understanding of the world around us, there are also many things we cannot experiment with, or at least not safely. For example, when we are forming mental models of the behavior of electrons or radioactivity, it is hard to have an experimental setup at home or work that we can safely learn from. In programming, we have a machine we can interact with at any time. Notional machines are designed to build a correct understanding of a machine that executes code.
The other part of the term is notional, which according to the Oxford dictionary means “existing as or based on a suggestion, estimate, or theory; not existing in reality.” When we are considering how a computer does what it does, we are not interested in all the details. We are mostly interested in a hypothesized, idealized version of how a computer works. For example, when we think of a variable x getting a value 12, in most of the cases we do not care about the memory address where the value is stored and the pointer that connects x to that memory address. It is enough to think of x as an entity with a current value that lives somewhere. A notional machine is the abstraction we use to reason about the computer’s functioning at the level of abstraction needed at a given time.
The idea of the notional machine was conceived by Ben du Boulay, a professor at the University of Sussex, while he was working on Logo in the 1970s. Logo was an educational programming language designed by Seymour Papert and Cynthia Solomon. It was the first language to introduce the turtle : an entity that can draw lines and be controlled by code. The name comes from the Greek word logos, meaning word or thought.
du Boulay first used the term “notional machine” to describe his strategy for teaching Logo to children and teachers. He described it as “the idealized model of the computer implied by the constructs of the programming language.” du Boulay’s explanations included handmade visualizations, but mainly used analogies.
For example, du Boulay used a factory worker as an analogy for the language execution model. The worker is capable of executing commands and functions, and it has ears with which it can hear parameter values, a mouth that speaks outputs, and hands that carry out the actions described by the code. This representation of programming concepts started simple but was gradually built up to explain the entirety of the Logo language, including built-in commands, user-defined procedures and functions, subprocedure calls, and recursion.
As you have seen, notional machines are designed to explain the workings of a machine executing code, and therefore they also share some characteristics with machines. For example, like a physical machine, a notional machine has the notion of “state.” When we think of a variable as a box, this virtual, notional box can be empty or have a value “in” it.
There are also other forms of notional machines that are not as tied to hardware. You likely use abstract representations of the machine that executes when you read and write code. For example, when thinking about how calculations work in programming languages, we often analogize the working of the computer to that of a mathematician. Consider this expression in Java as an example:
double celsius = 10; double fahrenheit = (9.0/5.0) * celsius + 32;
When you have to predict the value of fahrenheit, you will likely use a form of substitution: you replace the variable celsius on the second line by its value, 10. As a next step, you might mentally add brackets to indicate operator precedence:
double fahrenheit = ((9.0/5.0) * 10) + 32;
Performing a mental calculation based on transformation is a perfect model of what will be calculated, but it does not represent the calculation that a machine performs. What happens in the actual computer is quite different, of course. The machine most likely uses a stack for evaluation. It will transform the expression to reverse Polish notation and push the result of 9.0/5.0 onto the stack, before popping it off to multiply it by 10 and pushing the results back for further calculation. This is a perfect example of a notional machine that is partly wrong but useful. We could call this the “substitution notional machine,” and it’s likely closer to the mental model of most programmers than the stack-based model.
You’ve seen a few examples of notional machines now. Some operate at the level of the programming language and abstract all the details of the underlying machine, such as the substitution notional machine.
Other notional machines, such as representing a stack as a physical stack of papers, are more representative of how the physical machine executes the program. In using notional machines as a way of explaining and understanding programming concepts, it can be useful to purposefully think of what details the notional machine hides and exposes. Figure 6.4 shows an overview of four different levels of abstraction at which a notional machine can operate, including an example per level. For example, “variables as boxes” plays a role at the programming language level and at the level of the compiler/interpreter but abstracts details about the compiled code and the operating system.
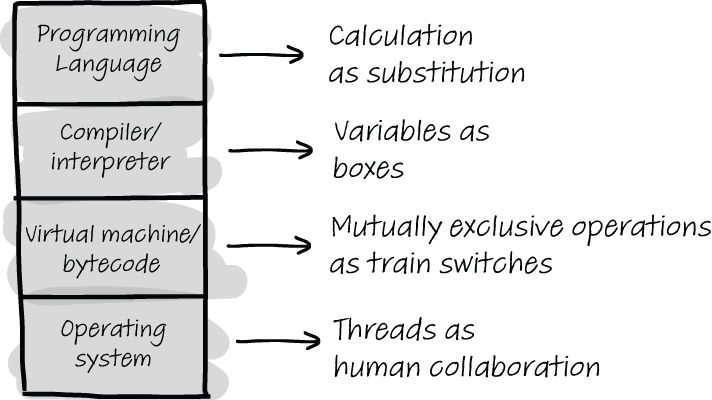
Figure 6.4 Different levels at which a notional machine can use abstractions. For example, the “calculation as substitution” notional machine we have seen abstracts everything apart from the programming language, while representing threads as human collaboration focuses on the workings of the operating system.
It can be important to realize what details you are ignoring when reasoning about code. While abstracting details is a great way to gain a higher level understanding of code, some forms of thinking about code might abstract relevant details.
EXERCISE 6.4 List three examples of notional machines and the levels at which they operate. Fill out the following table by listing notional machines and selecting their level of abstraction.
We often use notional machines not only to reason about how machines work but also to talk about code. We say, for example, that a variable “holds” a value, even though of course there is not a physical object that has a numeric value stored in it. This language indicates a mental model of a variable that is like a box containing a value.
There are many examples of language about programming that hint at underlying notional machines and lead to certain mental models. For example, we say that a file is “open” or “closed,” where we technically mean we are allowed to read the file or forbidden to do so. We use the word “pointer” and commonly say that a pointer “points” to a certain value, and we say that a function “returns” a value when it places the value on the stack so the caller (also a mental model) can use it.
Notional machines that are commonly used to explain how things work find their way into the language we use to talk about code, and even into programming languages themselves. For example, the concept of a pointer is present in many programming languages, and many IDEs allow you to see where a certain function is “called.”
EXERCISE 6.5 List three more examples of language we use about programming that indicate the use of a certain notional machine and lead to a certain mental model.
Earlier I used the term “notional machine” as if there is just one notional machine at play at any given moment. In reality, programming languages do not necessarily have just one all-encompassing notional machine but rather a set of overlapping ones. For example, when learning about simple types, you might have been told that a variable is like a box holding a value. Later in your programming career, you learned about compound types, which can be thought of as stacks of boxes each holding a simple value. These two notional machines are built on each other, as shown in figure 6.5.
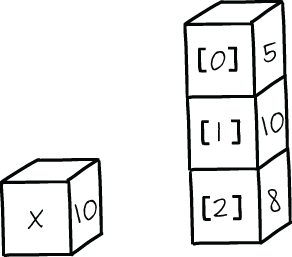
Figure 6.5 Two notional machines that are composable. On the left is a visualization of a variable as a box, and on the right an array is shown as a stack of boxes.
There are numerous other examples of expanding sets of abstractions we use to understand programming language concepts. For example, consider the notional machine used to think of parameter passing in a language that supports functions. Initially, you can think of a function without parameters as a package for several lines of code. When input parameters are added and we move from a procedure to a function, the function can be seen as a traveler that packs a set of values in its backpack and brings the values to the call location in the code. When output parameters are also considered, the traveler also brings back a value in its backpack, as illustrated in figure 6.6.
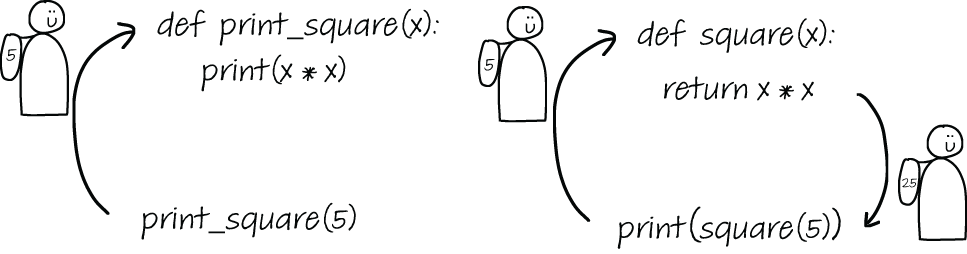
Figure 6.6 Two notional machines for functions. On the left is a machine that only supports input parameters, and on the right is an extended model that also incorporates output parameters.
In the previous section you saw that some notional machines can be composed, like the notional machine of a variable as a box, which composes with the notional machine of an array as a stack of boxes. However, notional machines can also create mental models that conflict with each other.
For example, the notional machine describing a variable as a box differs from the one where a variable is imagined as a name tag. The two notional machines cannot be combined into one consistent mental model; we either think of a variable as one or the other. Each of these notional machines has upsides and downsides. For example, the variable as a box representation implies that a variable might hold multiple values, like a box can hold multiple coins or candies. This (flawed) way of thinking is less likely if you think of a variable as a name tag or a sticker. A sticker can only be placed on one thing, so a variable then can only be used to describe one value. In 2017 my research group ran a study at the NEMO Science Museum in Amsterdam where we explored this concept.3 The 496 participants, who did not have any programming experience before the study, all received an introductory programming lesson in Scratch. Scratch is a block-based programming language developed by MIT to be welcoming and accessible to children who are learning to program. Although it’s meant for beginners taking their first steps in programming, it does support more advanced features, including defining and using variables. Creating a variable is done by pressing a button and entering the name of the variable, while setting a variable is done with the programming block depicted in figure 6.7.
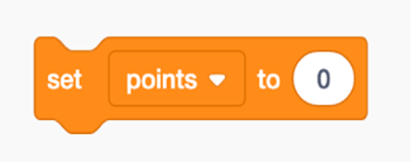
Figure 6.7 Setting the variable points to 0 in Scratch
In our study, we introduced all the participants to the concept of a variable but not in the same way. Half of the participants, the “label” group, received an introductory programming lesson in which we explained a variable as being a label, like a temperature or the age of a person. The other half, the “box” group, received a lesson in which we explained variables as being boxes, like a piggy bank or a shoebox. We consistently used the same metaphor in both lessons; for example, we used the phrase “x contains 5 ″” for the box group and “x is 5 ″” for the label group.
After this introductory lesson, the participants were tested on their understanding of programming. This included simple questions about variables with one variable, but we also included questions where one variable was set twice to investigate whether the participants had understood that a variable can only hold one value.
Our results clearly showed that both metaphors for variables have their benefits and downsides. For simple questions relating to variables with one assignment, the box group did better. We assume that thinking of a box is an easy thing to do, because people put stuff in boxes all the time. Therefore, visualizing the concept of a box for storage of a variable might help them grasp the idea. However, when we analyzed how many participants thought that a variable could hold two values, we found that people in the box group were likely to suffer from this misconception.
The important takeaway of our study is that you should be careful about describing programming concepts and the corresponding workings of the computer in terms of objects and operations in the real world. While these metaphors can be valuable, they might also create confusion, especially since old mental models can remain in the LTM and occasionally pop up in the working memory too.
EXERCISE 6.6 Think of a notional machine you commonly use when reasoning about code or when explaining code. What are some of the downsides or limitations of the mental models this notional machine creates?
While there can be downsides to using notional machines, in general they work well as a means of thinking about programming. The reason for this is related to a few topics we covered earlier in this book. Notional machines that work well relate programming concepts to everyday concepts that people have already formed strong schemata for.
Schemata are ways in which the LTM stores information. For example, the idea of a box is very likely a concept people have strong associations with. Placing something in a box, retrieving it later, and opening it just to see what’s inside are likely operations people are familiar with. As such, thinking of a variable as a box causes no extra cognitive load. If we were to say instead “A variable is like a monocycle,” that would be a lot less helpful, precisely because most people have no strong mental model of all the operations a monocycle supports.
What you can assume people will know is not fixed in time and place, of course. When explaining a concept, it is therefore important to choose a comparison that the person you are explaining it to will be familiar with. For example, when explaining a computer’s functionality to children in rural India, some educators have used elephants as computers and their trainers as the programmers since that is a principle familiar to the children.
The way I’ve defined notional machines might remind you of the definition of the semantics of a computer program. Semantics is the subfield of computer science concerned with the study of the meaning of programs rather than their appearance, which is called syntax. You might wonder whether the notional machine of a programming language simply indicates its semantics. However, semantics aim to formalize the working of a computer in mathematical equations and with mathematical precision. They do not aim to abstract details, but rather to specify the details precisely and completely. In other words, notional machines are not simply semantics.
How you represent a problem can heavily influence the way you think about it. For example, thinking of customers as a list versus as a collection can influence how you store and analyze customer objects.
Mental models are mental representations we form while thinking of problems. People can hold multiple mental models that can compete with each other.
Notional machines are abstract versions of how a real computer functions that are used when explaining programming concepts and reasoning about programming.
Notional machines help us understand programming because they enable us to apply existing schemata to programming.
Different notional machines sometimes nicely complement each other but may also create conflicting mental models.
1. Gentner, Dedre. (2002). Psychology of mental models. In N. J. Smelser & P. B. Bates (Eds.), International Encyclopedia of the Social and Behavioral Sciences (pp. 9683-9687), Elsevier.
2. For an overview, see “Toward a Unified Theory of Reasoning” by Johnson-Laird and Khemlani, https://www .sciencedirect.com/science/article/pii/B9780124071872000010.
3. “Thinking Out of the Box: Comparing Variables in Programming Education,” 2018, https://dl.acm.org/ doi/10.1145/3265757.3265765.